






【第9节 数据结构概述】
1 与408关联解析
1、为解决计算机主机与打印即之间速度不匹配问题,通常设置一个打印数据缓冲区,主机将要输出的数据依次写入该缓冲区,而打印机则依次从该缓冲区中取出数据。该缓冲区的逻辑结构应该是:。
A 栈 B 队列 C 树 D图
2、下列程序段的时间复杂度是:。
count = 0;
for(k = 1;k <= n;k *= 2){
for(j = 1;j <= n;j++){
count++;
A B O(n) C
D
3、下列函数的时间复杂度是:。
int func(int n){
int i = 0,sum = 0;
while(sum < n) sum += ++I;
return i;
}A B
C O(n) D
4、设n是i描述问题规模的非负整数,下列程序段的时间复杂度是:。
x = 0;
while(n>=(x+1)*(x+1))
x = x + 1;A B
C O(n) D
5、设线性表L=(a1,a2,a...,an-2,a-1,a。))采用带头结点的单链表保存,链表中结点应以如下:
typedef struct node{
int data;
struct node* next;
}NODE;请设计一个空间复杂度为O(1)且时间上尽可能高效的算法,重新排列L中的各结点,得到线性表L'=(a,an,a2,an-1,a3,an-2...)。
要求:
1)给出算法的基本设计思想
2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。
3)说明你所设计的算法的时间复杂度。
2 本节内容介绍
9.3小节主要是讲解什么是逻辑结构,逻辑结构有哪些,什么是存储结构,存储结构有哪些,逻辑结构和存储结构之间有什么关系。
9.4小节主要讲解什么是时间复杂度,时间复杂度如何计算,各种例子实战时间复杂度的计算,什么是空间复杂度。
【9.3 逻辑结构与存储结构】
1 两者对比
逻辑结构:数据元素之间的逻辑关系,抽象的
存储结构:数据结构在计算机中的表示,具体的
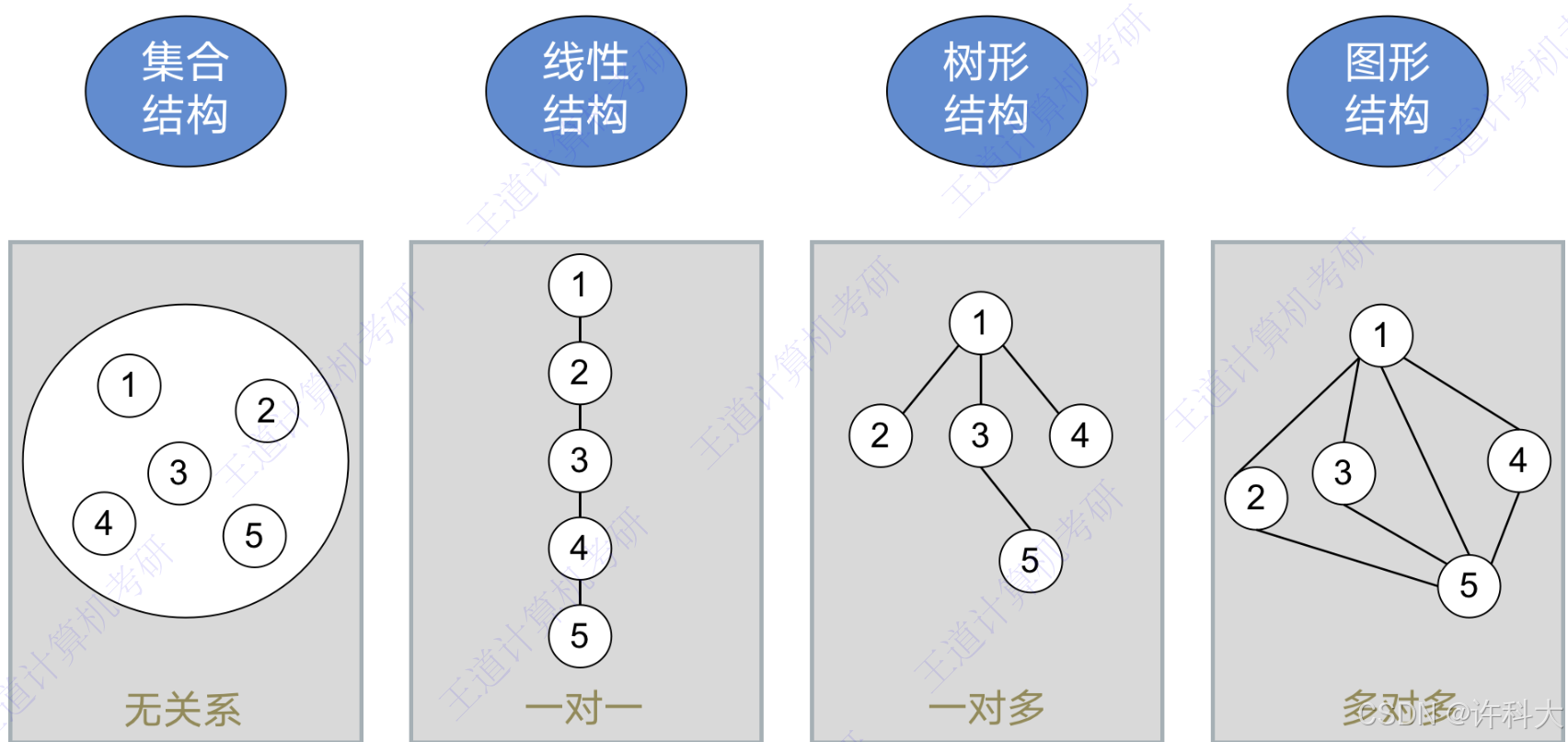
2 逻辑结构
集合结构:无关系
线性结构:一对一
树形结构:一对多
图形结构:多对多
3 存储结构
顺序存储、链式存储、索引存储、散列存储
4 顺序存储
C语言实现:
int Array[6] = {1,2,3,4,5,6}; // 定义数组并初始化
printf("%d\n",Array[3]}; // 随机访问第4个元素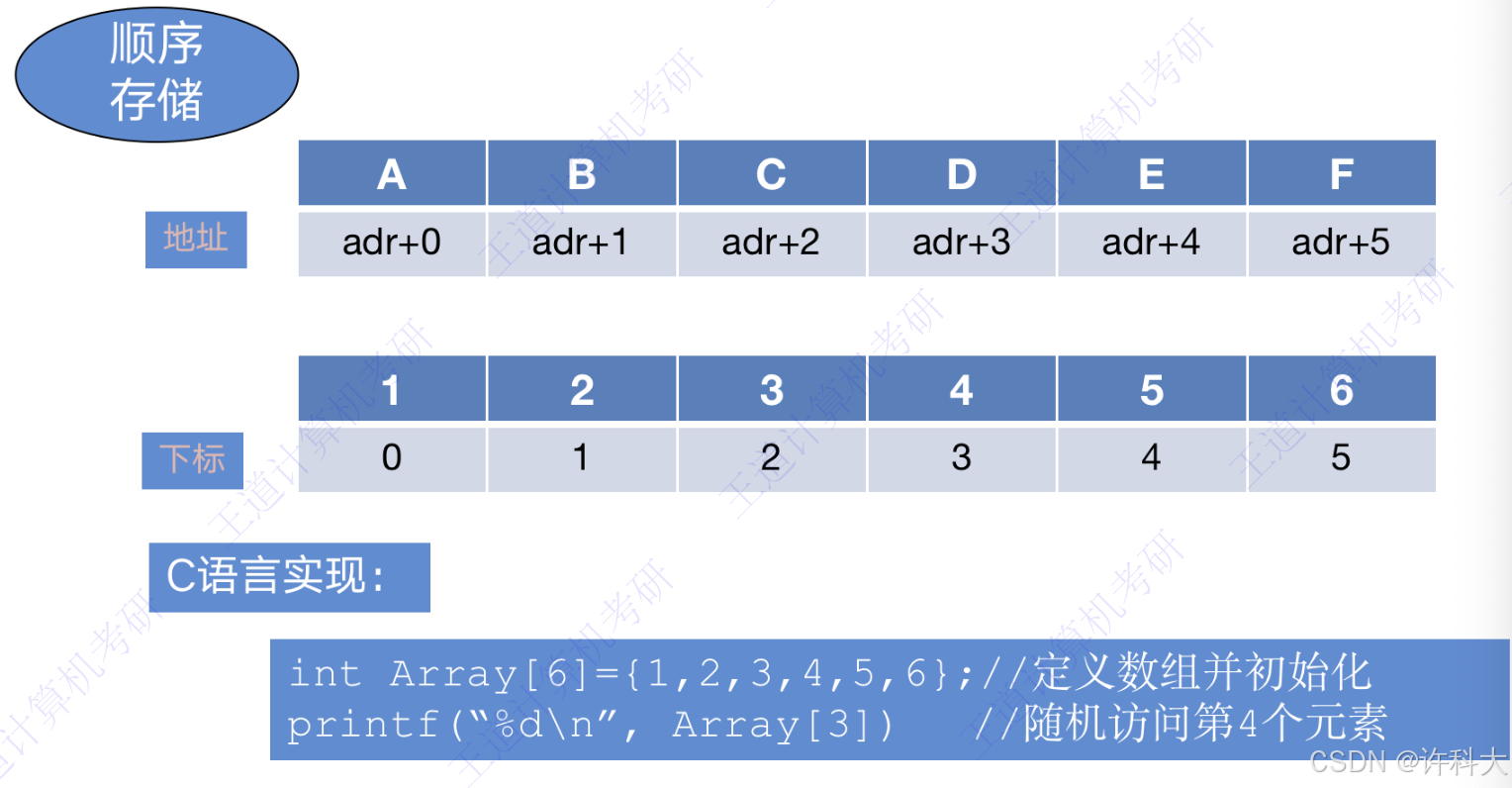
5 链式存储
C语言实现:
typedef struct lnode{
elemType data;
struct node *next;
}lone,*linklist;
node *l;
l = (linklist)malloc(sizeof(node));
a->next=b;b->next=c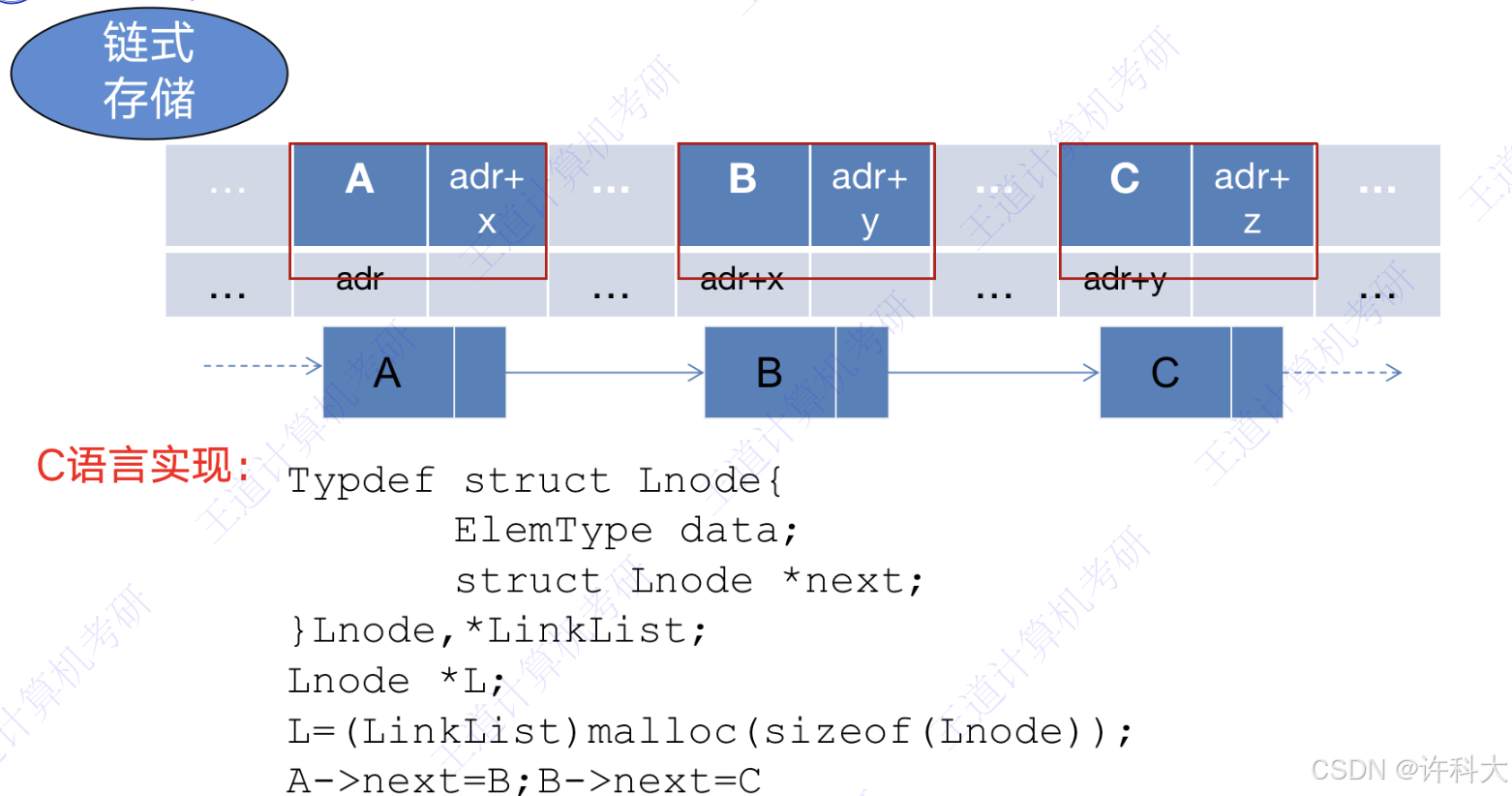
逻辑结构对人友好,存储结构对计算机友好。
6 顺序存储与链式存储分析
顺序存储优点:
1、可以实现随机存取。
2、每个元素占用最少的空间。
顺序存储缺点:
1、只能使用整块的存储单元,会产生较多的碎片。
链式存储优点:
1、充分利用所有存储单元,不会出现碎片现象。
链式存储缺点:
1、需要额外的存储空间用来存放下一结点的指针。
2、只能实现顺序存取。
【9.3 题】
1、逻辑结构是指数据元素之间的逻辑关系,抽象的,存储结构是数据结构在计算机中的表示,是具体的。
2、逻辑结构分为集合,线性结构,树形结构和图形结构。
3、存储结构主要有顺序存储、链式存储、索引存储与散列存储。
4、顺序存储可以实现随机存取,每个元素占用最少的空间,但是会产生较多的碎片,因为只能使用整块的存储单元。
5、链式存储充分利用所有存储单元,不会出现碎片现象,但是需要额外的存储空间来存放下一结点的指针,只能实现顺序存取。
【9.4 时间复杂度和空间复杂度】
算法的评价
1 算法定义
算法是对特定问题求解步骤的描述
特性:有穷、确定、可行、输入、输出
2 时间复杂度
时间复杂度是指算法中所有语句的频度(执行次数)之和。
记为:T(n)=O(f(n))
其中,n是问题的规模;f(n)是问题规模n的某个函数。
表示随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同。
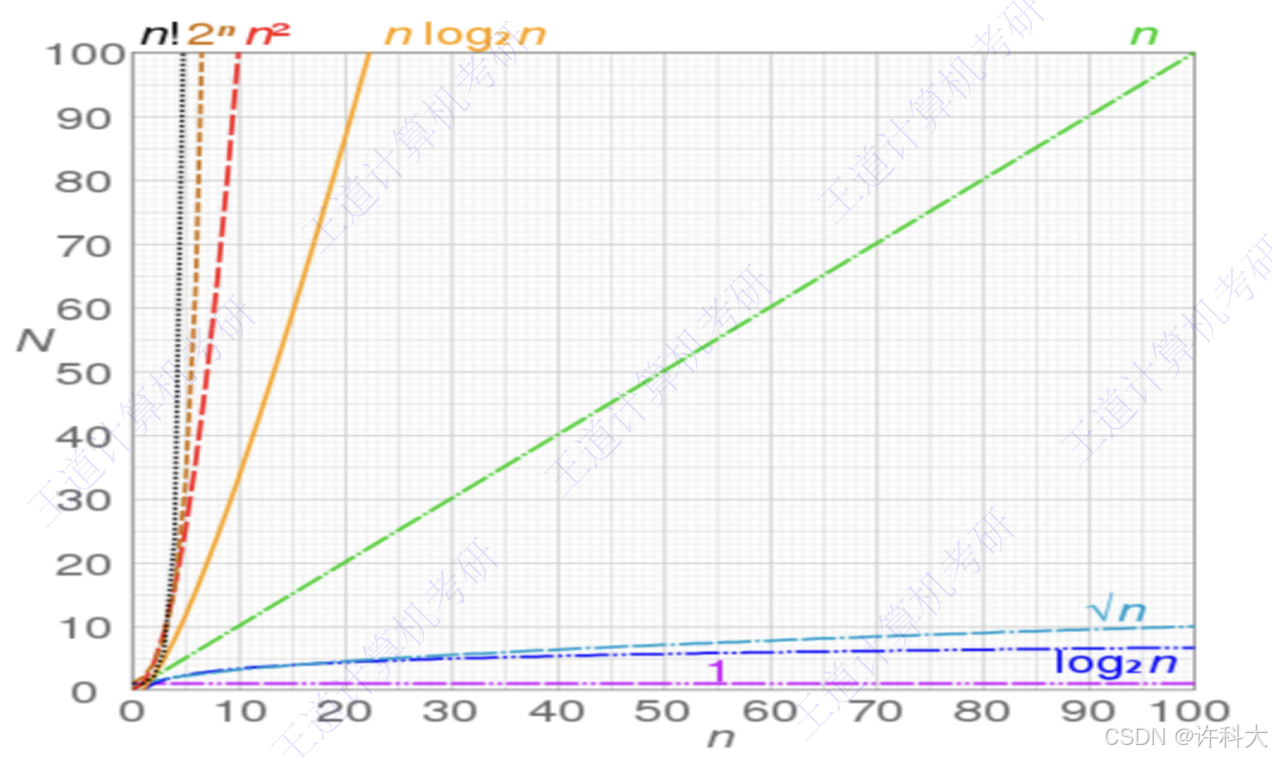
常见的时间复杂度:
O(1)<<O(n)<
<
<
<
<O(n!)
最高阶数越小,说明算法的时间性能越好。
数组拿任何一个位置元素,时间复杂度就是O(1).
示例程序1:
int sum = 0; // 执行一次
sum = n*(n+1)/2; // 执行一次
printf("%d",sum); // 执行一次算法的执行次数等于3.
时间复杂度为T(n)=O(1).
表示不会随n的增长而增长。
示例程序2:
int x = 2;
while(x<n/2)
x = 2*x;执行频率最高的语句为“x= 2*x”。
设该语句共执行了t次,则<n/2,故t=
-1=
时间复杂度T(n)=
示例程序3:
int sum = 0,i = 1;
while(i<n){
sum = sum +i;
i++;
}
printf("%d",sum);执行频率最高的语句是while循环体中的代码。
一共执行n次。
时间复杂度T(n) = O(n).
示例程序4:
int i,x=2;
for(I=0;i<n;i++){
x = 1;
while(x<n/2)
x = 2*x;
}执行频率最高的语句为“x=2*x”。
2 4 8 16
设该语句内层循环执行了次,外层执行了n次,因此总计执行次数为
次。
示例程序5:
int I,j;
for(I = 0;i < n;i++){
for(j = 0;j < m;j++)
sum = sum + 1;
}对于外层循环,相当于内部时间复杂度为O(m)的语句再循环n次。
所以时间复杂度T(n) = O(m*n)
如果m=n,则时间复杂度T(n) =
时间复杂度的乘法规则
示例程序6:
int sum1 = 0,sum2 = 0,i,j;
for(I = 0;i < n;i++)
sum1 = sum1 + I;
for(j = 0;j < m;j++)
sum2 = sum2 + j;
printf("%d,%d",sum1,sum2);两个循环没有嵌套,串行执行。
所以时间复杂度T(n)=O(n)+O(m).
取最大的,即时间复杂度T(n) = max(O(n),O(m))
时间复杂度的加法规则
思考题:如果一个算法的执行次数为,那么该算法的时间复杂度为多少?
是,因为时间复杂度计算忽略高阶项系数和低阶项。
3 空间复杂度
空间复杂度S(n)指算法运行过程中所使用的辅助空间的大小。
记为S(n) = O(f(n))
除了需要存储算法本身的指令、常数、变量和输入数据外,还需要存储对数据操作的存储单元。
若输入数据所占空间只取决于问题本身,和算法无关,这样只需分析该算法在实现时所需的辅助单元即可。
算法原地工作是指所需的辅助空间是常量,即O(1).
n个元素数组排序,不使用额外的空间(随着n的增常而增长的空间叫额外空间),空间复杂度就是O(1).
【9.4 题】
1、时间复杂度指算法中所有语句的频度(执行次数)之和。记为T(n) = O(f(n)),其中,n是问题的规模,f(n)是问题规模n的某个函数。
2、代码:
int x = 2;
while(x<n/2)
x = 2*x;的时间复杂度是。
3、时间复杂度的计算需要忽略高阶项系数和低阶项。
4、如果一个算法的执行次数为,那么该算法的时间复杂度为
.
5、代码
int I,x = 2;
for(I = 0;i<n;i++){
x =. 1;
while(x<n/2)
x = 2*x;
}的时间复杂度是.
【第10节 线性表代码实战】
【10.1 与408关联】
1、设将n(n>1)个整数存放到一维数组R中。试设计一个在时间和空间两方面都进可能高效的算法。将R中保存的序列循环左移p(0<p<n)个位置,即将R中的数据由()变换为(
)要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用C、C++或Java语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度和空间复杂度。
2、假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,则可共享相同的后缀存储空间,例如,“loading”和“being”的存储映像如下图所示。
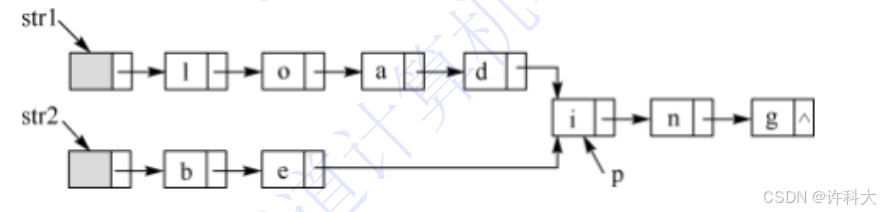
设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为 ,请设计一个时间上尽可能高效的算法,找出str1和str2所指向两个链表共同后缀的起始位置(如图中字符i所在结点的位置p)。要求:
,请设计一个时间上尽可能高效的算法,找出str1和str2所指向两个链表共同后缀的起始位置(如图中字符i所在结点的位置p)。要求:
1)给出算法的基本设计思想。
2)根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。
3)说明你所设计算法的时间复杂度。
2 本节内容介绍
本大节课为10.2小节到10.5小节
10.2小节是针对顺序表的原理进行解析
10.3小节10.4小节对顺序表的初始化、插入、删除、查找进行实战
10.5小节是针对链表的原理进行解析
【10.2 线性表的顺序表示原理解析】
1 线性表
定义:有n(n>=0)个相同类型的元素组成的有序集合。
L=()
线性表中元素个数n,称为线性表的长度。当n=0时,为空表。
是唯一的“第一个”数据元素,
是唯一的“最后一个”数据元素。
为
的直接前驱,
为
的直接后继。

线性表特点
表中元素的个数是有限的。
表中元素的数据类型都相同。意味着每一个元素占用相同大小的空间。
表中元素具有逻辑上的顺序性,在序列中各元素排列有其先后顺序。
请注意:本小节描述的是线性表的逻辑结构,是独立于存储结构的!
2 线性表的顺序表示(简称顺序表)
逻辑上相邻的两个元素在物理上也相邻。
顺序表的定义:
#define MaxSize 50 // 定义线性表的长度
typedef struct{
ElemType data[MaxSize]; // 顺序表的元素
int len; // 顺序表的当前长度
}SqList; // 顺序表的类型定义

顺序表(线性表的顺序表示)优点:
1、可以随机存取(根据表头元素地址和元素序号)表中任意一个元素。
2、存储密度高,每个结点只存储数据元素。
顺序表的缺点:
1、插入和删除操作需要移动大量元素。
2、线性表变化较大时,难以确定存储空间的容量。
3、存储分配需要一整段连续的存储空间,不够灵活。
2 插入操作
最好情况:在表尾插入元素,不需要移动元素,时间复杂度为O(1).
最坏情况:在表头插入元素,所有元素依次后移,时间复杂度为O(n).
平均情况:在插入位置概率均等的情况下,平均移动元素的次数为n/2,时间复杂度为O(n).
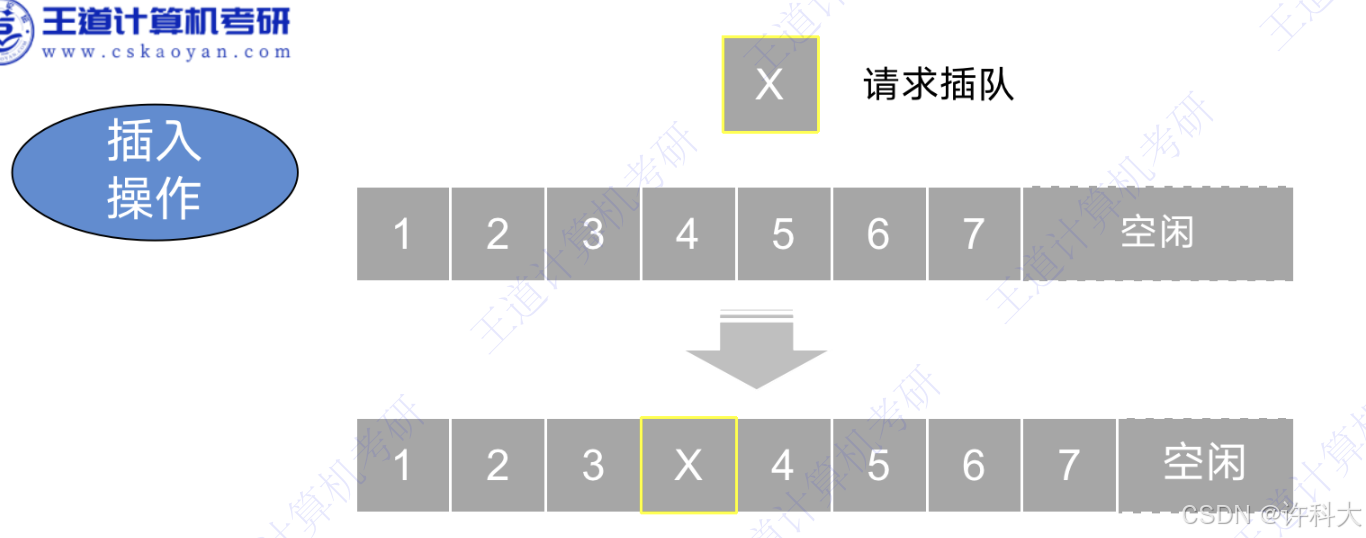
代码片段:
// 判断插入位置i是否合法(满足1<=i<=len+1)
// 判断存储空间是否已满(即插入x后是否会超出数组长度)
for(int j = L.len;j >=I;j--){ // 将最后一个元素到第I个元素依次后移一位
L.data[j] = L.data[j-1];
L.data[I-1] = x; // 空出的位置I处放入x
L.len++; // 线性表长度加1注意:线性表第一个元素的数组下标是0;
3 删除操作
最好情况:删除表尾元素,不需要移动元素,时间复杂度为O(1).
最坏情况:删除表头元素,之后的所有元素依次前移,时间复杂度为O(n).
平均情况:在删除位置概率均等的情况下,平均移动元素的次数为(n-1)/2,时间复杂度为O(n).
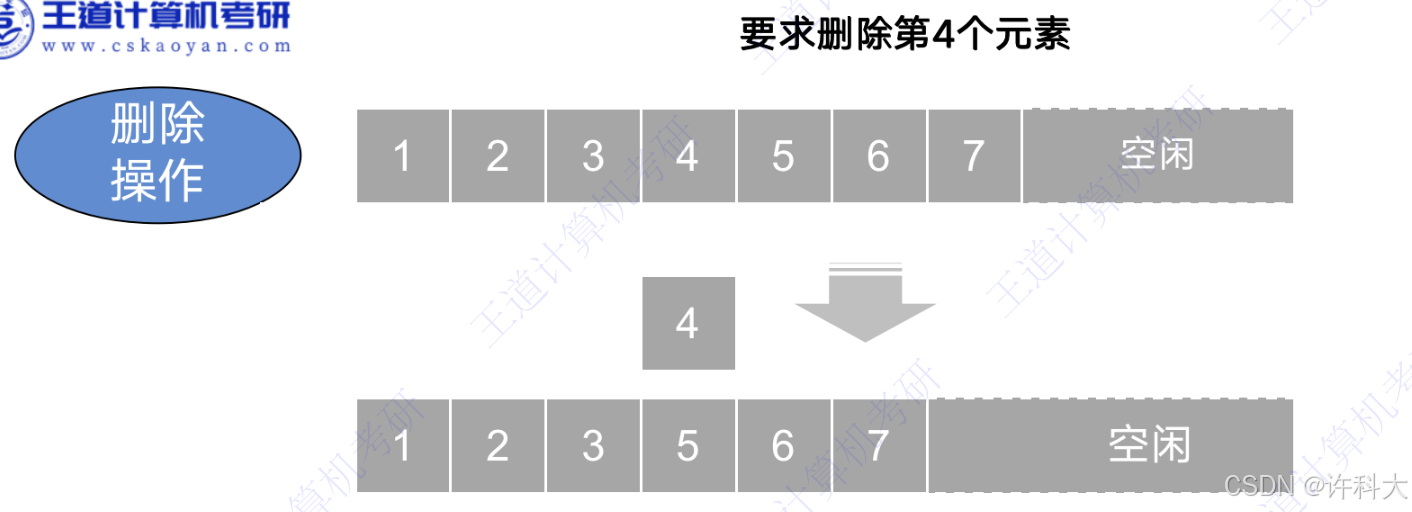
代码片段:
// 判断删除位置i是否合法(满足1<=i<=len)
e = L.data[I-1]; // 将被删除的元素赋值给e
for(int j = I;j < L.len;j++} //将删除位置后的元素依次前移
L.data[j-1] = L.data[I];
L.len--; // 线性表长度减1
插入和删除时,i的合法范围是不一样的。
请思考:动态分配的数组还属于顺序存储结构吗?
当然。
4 动态分配
#define InitSize 100 // 表长度的初始定义
typedef struct{
Element *data; // 指示动态分配数组的指针
int MaxSize,length; // 数组的最大容量和当前个数
}SeqList; // 动态分配数组顺序表的类型定义
C的初始动态分配语句为:
L.data = (ElemType*)malloc(sizeof(ElemType)*InitSize);C++的初始动态分配语句为:
L.data = new ElemType[InitSize];【10.2 题】
1、线性表是由n(n>=0)个相同类型的元素组成的有序集合,ai-1为ai的前驱,ai+1为ai的后继。
2、对于顺序表,是指逻辑上相邻的两个元素在物理位置上也相邻。顺序表采用数组来实现,因此逻辑上相邻的两个元素在物理位置上也相邻,从而能够实现随机存取。
3、顺序表有插入和删除操作需要移动大量元素,线性表变化较大时,难以确定存储空间的容量的缺点。还有一个缺点是存储分配需要一整段连续的存储空间,不够灵活。
4、顺序表增、删、按值查操作的时间复杂度是O(n),增、删存在元素的移动操作,查询要遍历。
5、顺序表删除某个元素后,其后面元素需要往前移动,后年的元素需要依次往前移动覆盖。
6、课程中在顺序表的1到7个位置,分别存储了1,2,3,4,5,6,7总计7个元素,但是由于顺序表是用数组实现的,所以第一个位置的元素1,是存在数组下标为0的位置。考研时,顺序表没有0号位置的说法,最开始的就是第一个位置,而由于数组下标从0开始,因此第一个位置的元素1,是存在数组下标为0的位置。
【10.3 顺序表的初始化及插入操作实战】
注意新建的项目是C++可执行文件。
// sequence table
#include <stdio.h>
#define MaxSize 20 // 顺序表(数组)长度
typedef int ElemType; // 定义类型,以便替换
typedef struct { // 定义结构体
ElemType data[MaxSize];
int length;
}SqList;
bool ListInsert(SqList &L,int position,ElemType e){ // 定义增加元素函数
if(L.length == MaxSize){
return false;
}
if(position < 1 || position > L.length+1){
return false;
}
for (int i = L.length; i >= position; i--) {
L.data[i] = L.data[i-1];
}
L.data[position-1] = e; // 插入数据
L.length++; //长度更新
return true;
}
// 输出顺序表
void OutputSqList(SqList L){
for (int i = 0; i < L.length; i++) { // 输出到一行上
printf("%d ",L.data[i]);
}
printf("\n"); // 随后换行
}
int main(){
SqList L;
L.data[0] = 1;
L.data[1] = 2;
L.data[2] = 3;
L.length = 3;
bool result;
result = ListInsert(L,2,2026);
if(result){
printf("insert success\n");
} else{
printf("insert failed\n");
}
OutputSqList(L);
return 0;
}
【10.3 题】
1、typedef struct{ElemType data[MaxSize];int length; //当前顺序表中有多少个元素}SqList;然后通过SqList;来定义一个顺序表
2、对于顺序表插入操作,如果插入位置i满足i<1||i>L.length+1,那么插入不合法。
3、MaxSize是数组长度,也是顺序表最大存储空间,对于顺序表插入操作,如果L.length>=MaxSize成立,那么就不能往顺序表插入元素。
【10.4 顺序表的删除及查询实战】
// sequence table
#include <stdio.h>
#define MaxSize 20 // 顺序表(数组)长度
typedef int ElemType; // 定义类型,以便替换
typedef struct { // 定义结构体
ElemType data[MaxSize];
int length;
}SqList;
bool ListInsert(SqList &L,int position,ElemType e){ // 定义增加元素函数
if(L.length == MaxSize){
return false;
}
if(position < 1 || position > L.length+1){
return false;
}
for (int i = L.length; i >= position; i--) {
L.data[i] = L.data[i-1];
}
L.data[position-1] = e; // 插入数据
L.length++; //长度更新
return true;
}
bool ListDelete(SqList &L,int position,ElemType &e){
if(position < 1 || position > L.length){
return false;
}
e = L.data[position-1];
for (int i = position; i < L.length; i++) {
L.data[i-1] = L.data[i];
}
L.length--;
return true;
}
int ListSearch(SqList L,ElemType e){
for (int i = 0; i < L.length; i++) {
if(L.data[i] == e){
return i+1;
}
}
return 0;
}
// 输出顺序表
void OutputSqList(SqList L){
for (int i = 0; i < L.length; i++) { // 输出到一行上
printf("%d ",L.data[i]);
}
printf("\n"); // 随后换行
}
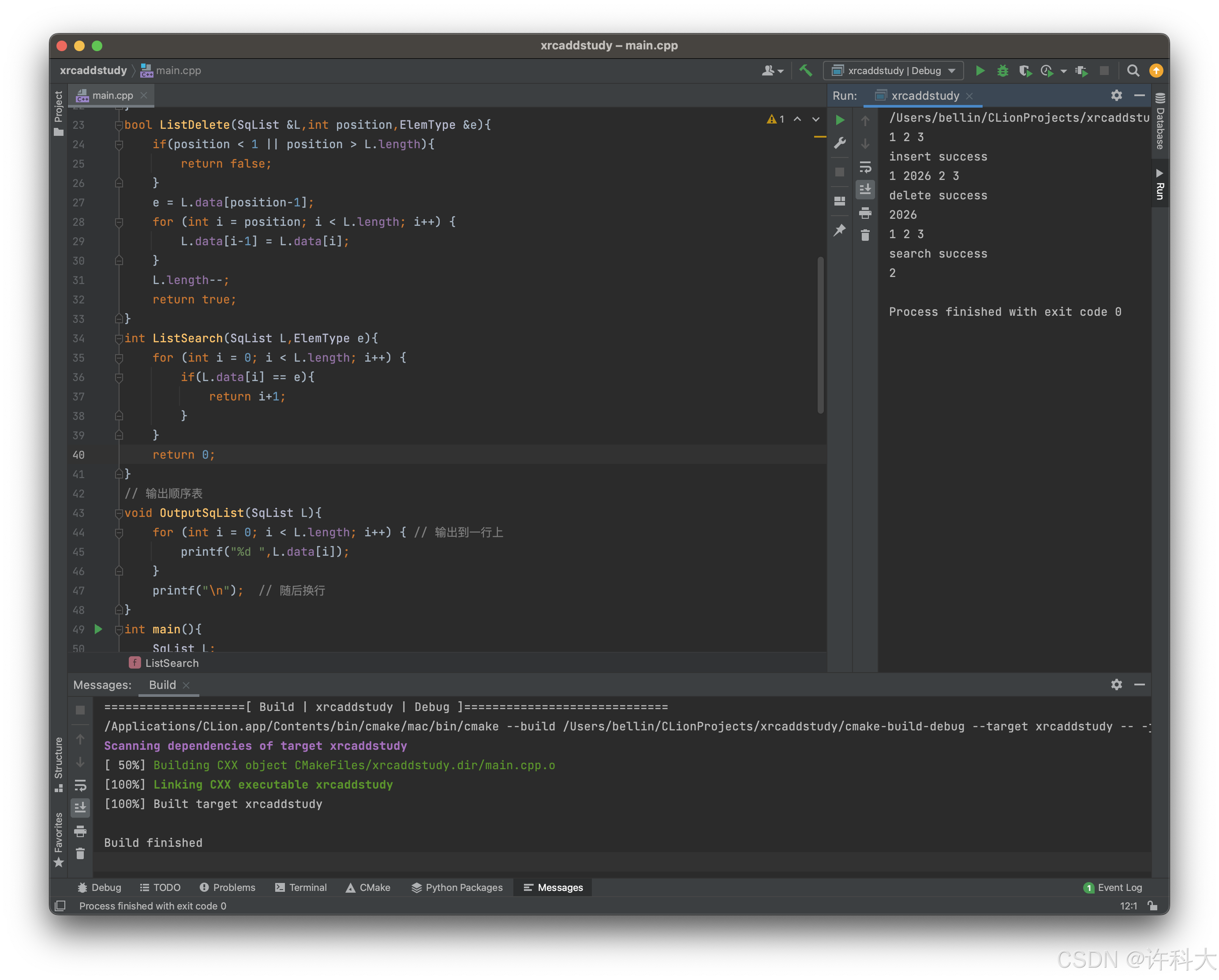
int main(){
SqList L;
L.data[0] = 1;
L.data[1] = 2;
L.data[2] = 3;
L.length = 3;
OutputSqList(L);
bool result;
result = ListInsert(L,2,2026);
if(result){
printf("insert success\n");
} else{
printf("insert failed\n");
}
OutputSqList(L);
ElemType del;
result = ListDelete(L,2,del);
if(result){
printf("delete success\n");
printf("%d\n",del);
} else{
printf("delete failed\n");
}
OutputSqList(L);
int position;
position = ListSearch(L,2);
if(position){
printf("search success\n");
printf("%d\n",position);
} else{
printf("search failed\n");
}
return 0;
}
// addition and deletion of sequencial tables
#include <stdio.h>
#define MaxSize 20
typedef int ElemType; // 让顺序表存储其他类型数据时,可以快速完成代码修改
typedef struct {
ElemType data[MaxSize];
int length; // 顺序表长度(一定要记得在初始化的时候要设置长度,否则在运行的时候会报错
}SqList;
// 查找某个元素的位置,找到了就返回对应的位置,没找到就返回0
int ListSearch(SqList L,ElemType e){
for(int i = 0;i < L.length;i++){
if(e == L.data[i]){
return i+1; // 因为i是数组的下标,加1以后才是顺序表的下标
}
}
return 0; // 循环结束没找到
}
// 删除顺序表中的元素,position是要删除的元素的位置,e是为了获取被删除的元素的值
bool ListDelete(SqList &L,int position,ElemType &e){
// 判断删除的元素的位置是否合法
if(position < 1 || position > L.length){
return false; // 一旦走到return函数就结束了
}
e = L.data[position-1]; // 首先保存要删除元素的值
for(int i = position;i < L.length;i++){ // 往前移动元素
L.data[i-1] = L.data[i];
}
L.length--; // 顺序表长度减1
return true;
}
// 顺序表的插入,因为L会改变,因此这里要用引用,position是插入的位置
bool ListInsert(SqList &L,int position,ElemType &e){
// 判断position是否合法
if(position < 1 || position > L.length + 1){
return false;
}
// 如果存储空间满了,不能插入
if(L.length == MaxSize){
return false; // 为插入返回false
}
// 把后面的元素依次往后移动,空出位置,来放要插入的元素
for (int i = L.length; i >= position; i--) {
L.data[i] = L.data[i-1];
}
L.data[position-1] = e; // 放入要插入的元素
L.length++; // 顺序表长度要加1
return true; // 插入成功返回true
}
// 打印顺序表
void ListPrint(SqList L){
for (int i = 0; i < L.length; i++) {
printf("%4d ",L.data[i]); // 为了打印到同一行
}
printf("\n");
}
// 顺序表的初始化及插入操作实战
int main(){
SqList L; // 定义一个顺序表,变量L
bool result; // 用来装函数的返回值
L.data[0] = 1; // 防止元素
L.data[1] = 2;
L.data[2] = 3;
L.length = 3; // 设置长度
ElemType e;
scanf("%d",&e);
ListPrint(L);
result = ListInsert(L,2,e);
if(result){
printf("insert sqlist success\n");
ListPrint(L); // 顺序表打印
} else{
printf("insert sqlist failed\n");
}
result = ListDelete(L,2,e);
if(result){
printf("delete sqlist success\n");
printf("delete element is %d\n",e);
ListPrint(L); // 顺序表打印
} else{
printf("delete sqlist failed\n");
}
int position;
position = ListSearch(L,3);
if(position) {
printf("search sqlist success\n");
printf("search element is in %d\n",position);
} else{
printf("search sqlist failed\n");
}
return 0;
}【10.4 题】
1、对于删除子函数bool List(SqList &,int i,ElemType &e),之所以这里使用C++引用,是因为在子函数修改了L,还有e后,主函数(调用ListDelete的函数)内对应的L和e会发生变化。
2、对于顺序表做删除操作时,需要判断删除的位置i是否合法,不可以直接操作。
3、做完删除操作后,需要L.length-=1.
4、顺序表做查找操作int ListSearch(SqList L,ElemType e)的L不加引用时因为在子函数内不修改L。
【10.5 线性表的链式存储】
线性表的链式表示简称链表
顺序表的缺点:
插入和删除操作移动大量元素。
数组的大小不好确定。
占用一大段连续的存储空间,造成很多碎片。
1 单链表
逻辑上相邻的两个元素在物理位置上不相邻
单链表结点的定义:
typedef struct LNode{ // 单链表结点类型
Element data; // 数据域
struct LNode *next; // 指针域
}LNode,*LinkList;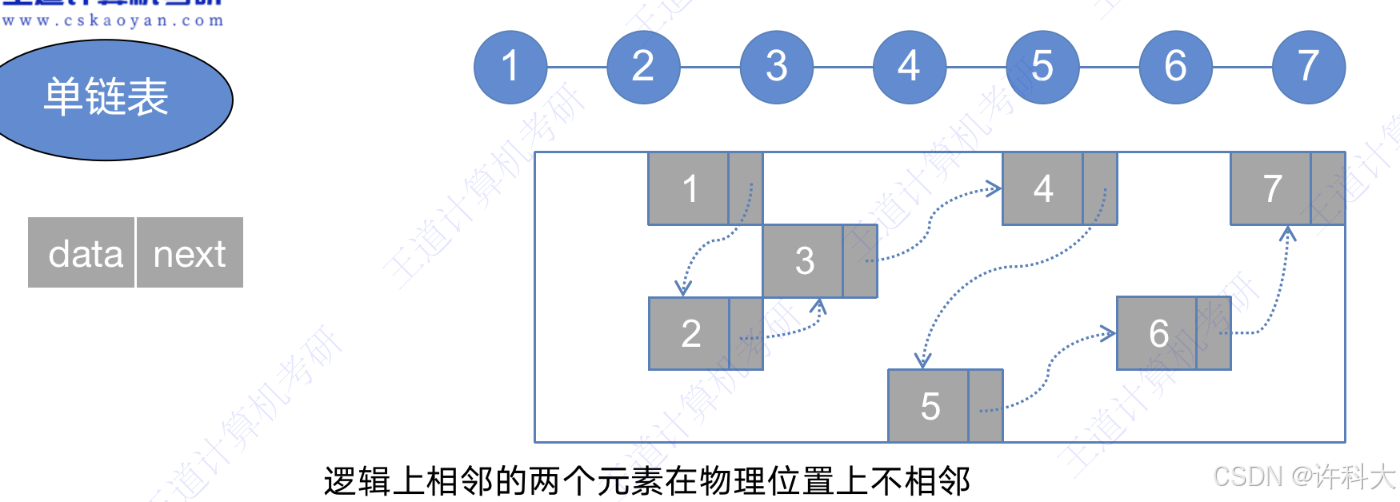
头指针:链表中第一个结点的存储位置,用来表示单链表。
头结点:在单链表第一个结点之前附加的一个结点,为了操作上的方便。
若链表有头结点,则头指针永远指向头结点,不论链表是否为空,头指针均不为空,头指针是链表的必须元素,它表示一个链表。
头结点是为了操作的方便而设立的,其数据域一般为空,或者存放链表的长度。有头结点后,对在第一结点前插入和删除第一结点的操作就统一了,不需要频繁重置头指针。但头结点不是必须的。

单链表的优点:
1、插入和删除操作不需要移动元素,只需要修改指针。
2、不需要大量的连续存储空间。
单链表的缺点:
1、单链表附加指针域,也存在浪费存储空间的缺点。
2、查找操作时需要从表头开始遍历,一次查找,不能随机存取。
2 单链表的插入操作
创建新结点代码:
q = (node*)malloc(sizeof(LNode))
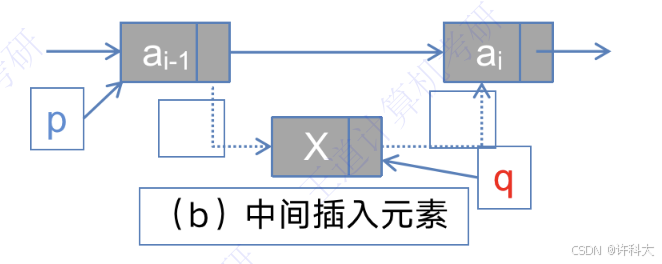
q->data = x;a(表头插入元素)、b(中间插入元素)操作的代码:
q->next = p->next;
p->next = q;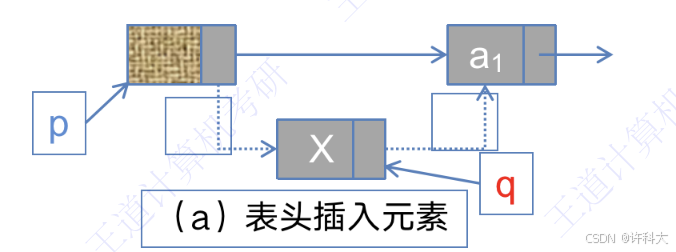
c(表尾插入元素)操作的代码:
p->next = q;
q.next = NULL;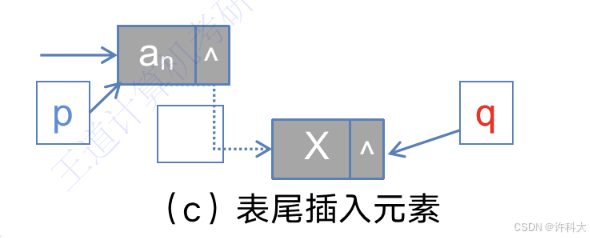
3 单链表的删除操作
a/b c操作的代码:
p = GetElem(L,i-1); // 查找删除位置的前驱结点
q = p->next;
p->next = q->next;
free(q);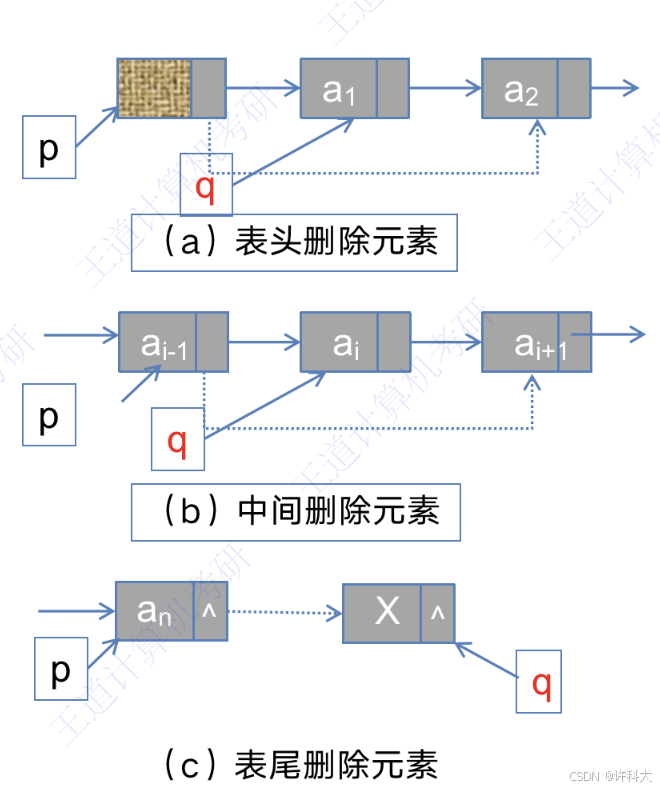
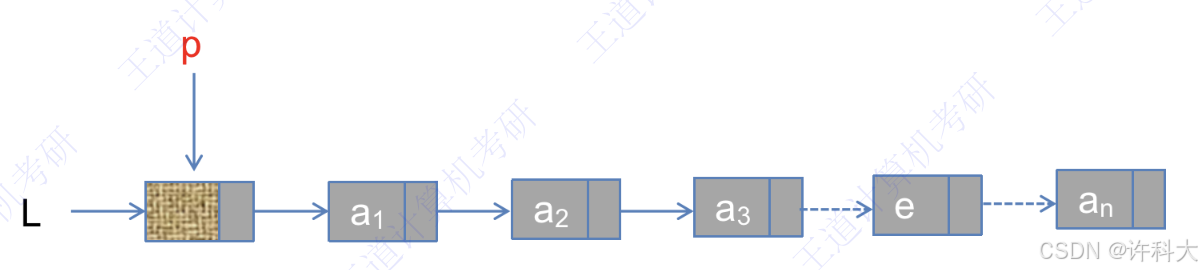
4 单链表的查找操作
L是头指针,用来指向头结点。
按序号查找结点值的算法如下:
LNode *p = L->next;
int j = 1;
while(p&&j<i){
p = p->next;
j++;
}
return p;按值查找结点的算法如下:
LNode *p = L->next;
while(p!=NULL && p->data!=e){
p = p->next;
}
return p;
【10.5 题】
1、链表插入和删除操纵不需要移动元素,只需要修改指针,不需要大量的连续存储空间。
2、链表的缺点是单链表附加指针域,也存在浪费存储空间的缺点;查找操作时间需要从表头开始遍历,一次查找,不能随机存取。
3、若链表有头结点,则头指针永远指向头结点,不论链表是否为空,头指针均不为空,头指针式链表的必须元素,它标识一个链表。头结点是为了操作的方便而设立的,链表也可以不带头结点。
4、链表删除、查找操作的时间复杂度是O(n)。
5、链表删除第i个位置结点的操作如下:
p = GetElem(L,i-1); // 查找删除位置的前驱结点
q = p->next;
如果q不为NULL
p->next = q->next;
free(q);
先获得前驱结点地址值p,然后拿到要被删除的结点q,让p->next=q->next;q就实现了断链,最后一定要记得free(q);
【10 代码题】
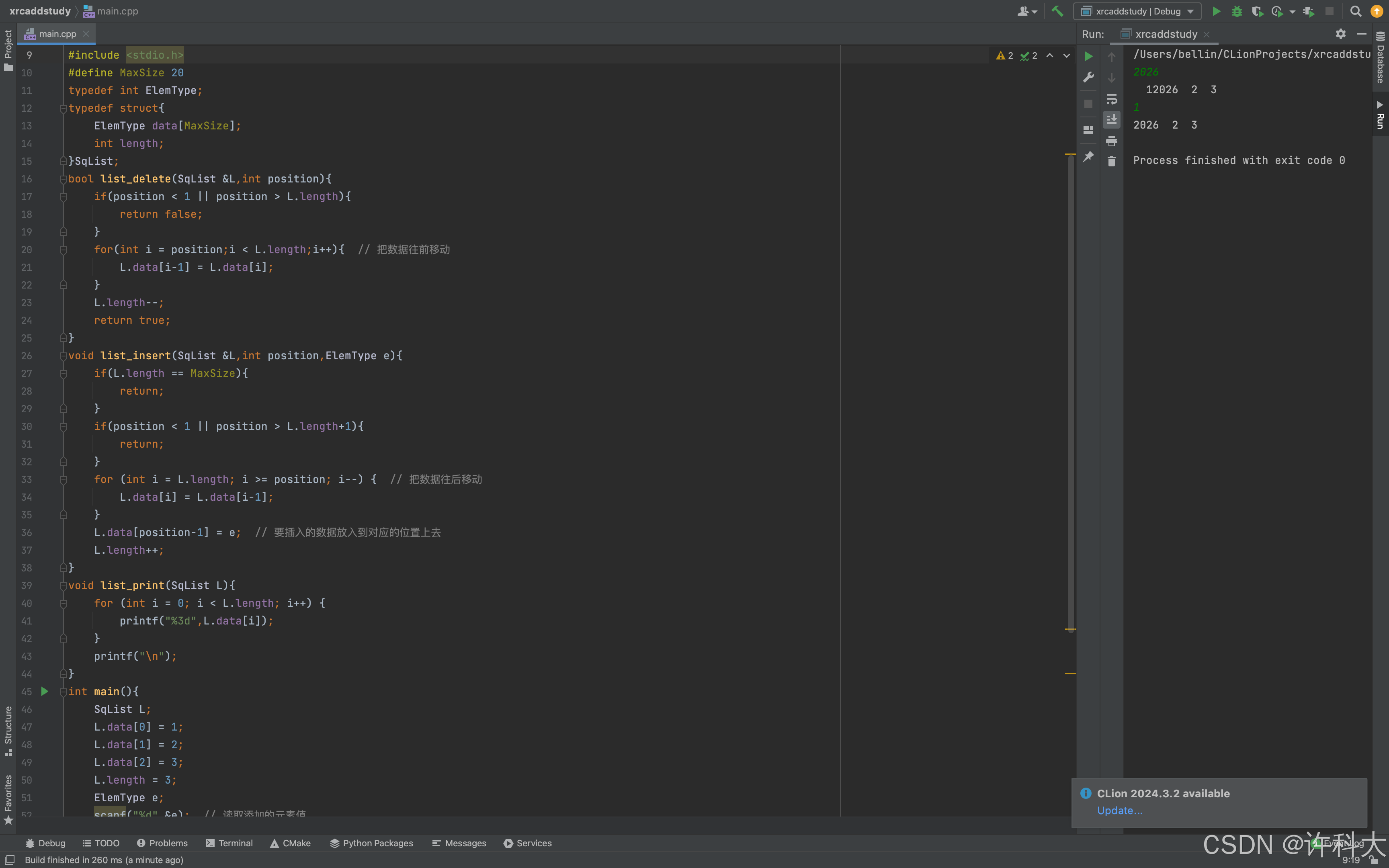
1、初始化顺序表(顺序表中元素为整型),里边的元素是1,2,3,然后通过scanf读取一个元素(假如插入的是6),插入到第2个位置,打印输出顺序表,每个元素占3个空格,格式为1 6 2 3 ,然后scanf读取一个整数,是删除的位置(假如输入为1),然后输出顺序表6 2 3,假如输入的位置不合法,输出false字符串,提醒,language一定要选为C++。
/*
* 初始化顺序表(顺序表中元素为整型),里边的元素是1,2,3,
* 然后通过scanf读取一个元素(假如插入的是6),插入到第2个位置,
* 打印输出顺序表,每个元素占3个空格,格式为1 6 2 3 ,
* 然后scanf读取一个整数,是删除的位置(假如输入为1),
* 然后输出顺序表6 2 3,假如输入的位置不合法,输出false字符串
*/
#include <stdio.h>
#define MaxSize 20
typedef int ElemType;
typedef struct{
ElemType data[MaxSize];
int length;
}SqList;
bool list_delete(SqList &L,int position){
if(position < 1 || position > L.length){
return false;
}
for(int i = position;i < L.length;i++){ // 把数据往前移动
L.data[i-1] = L.data[i];
}
L.length--;
return true;
}
void list_insert(SqList &L,int position,ElemType e){
if(L.length == MaxSize){
return;
}
if(position < 1 || position > L.length+1){
return;
}
for (int i = L.length; i >= position; i--) { // 把数据往后移动
L.data[i] = L.data[i-1];
}
L.data[position-1] = e; // 要插入的数据放入到对应的位置上去
L.length++;
}
void list_print(SqList L){
for (int i = 0; i < L.length; i++) {
printf("%3d",L.data[i]);
}
printf("\n");
}
int main(){
SqList L;
L.data[0] = 1;
L.data[1] = 2;
L.data[2] = 3;
L.length = 3;
ElemType e;
scanf("%d",&e); // 读取添加的元素值
list_insert(L,2,e); // 读取的元素固定放在第二个位置
list_print(L);
int position;
scanf("%d",&position); // 读取删除元素的位置
if(list_delete(L,position)){
list_print(L);
} else{
printf("false\n");
}
return 0;
}
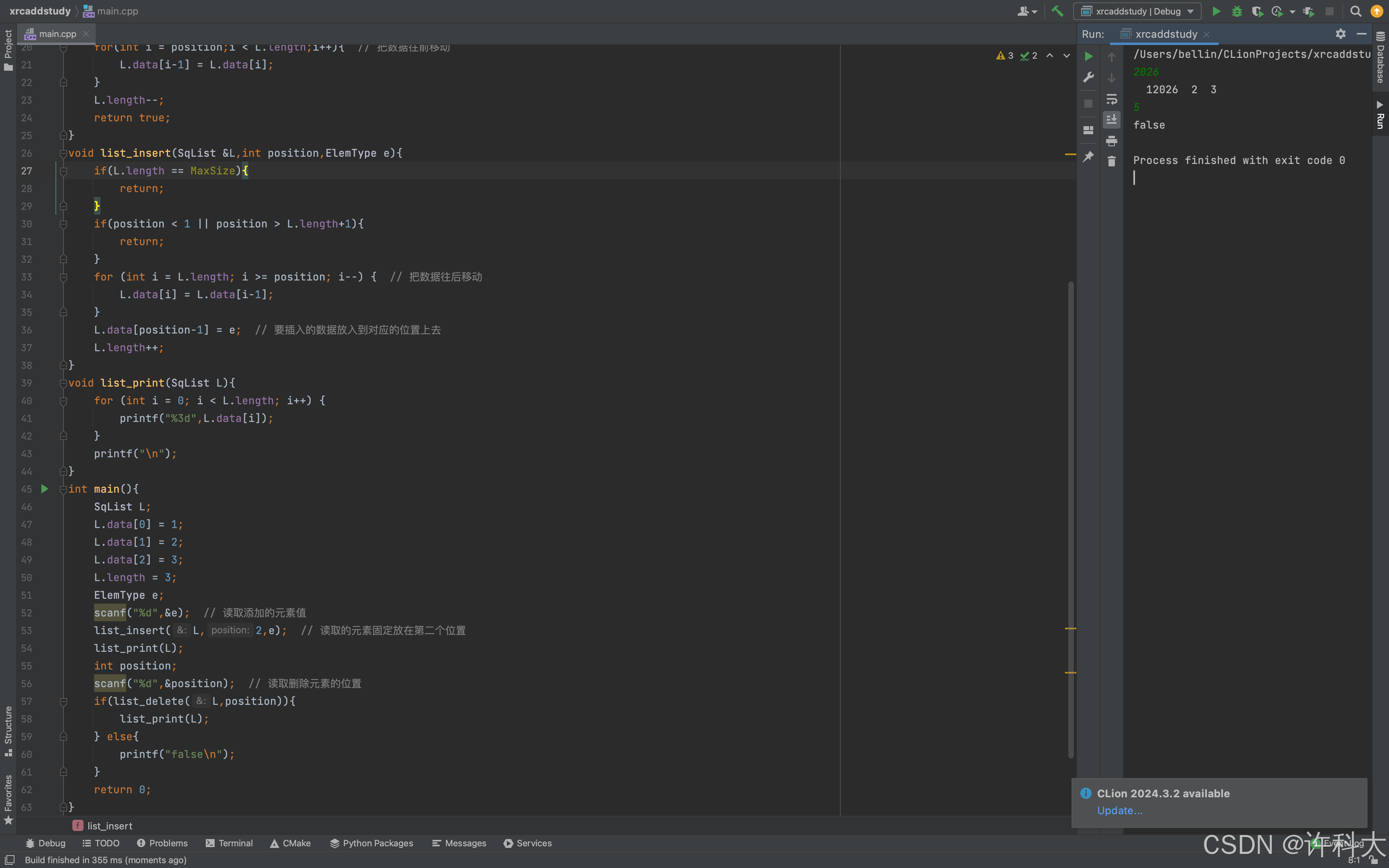
【第11节 单链表的新建与查找】
【11.2 与408关联】
1、设线性表L=(a1,a2,a3,...,an-2,an-1,an)采用带头结点的单链表保存,链表中的结点定义如下:typedef struct node{int data;struct node* next;} NODE;请设计一个空间复杂度为O(1)且时间上尽可能高效的算法,重新排列L中的各结点,得到线性表L'=(a1,an,a2,an-1,a3,an-2,...),要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或C++语言表述算法,关键之处给出注释。3)说明你所设计的算法的时间复杂度。
本节内容介绍
本大节课分为11.3小节到11.7小节,任何数据结构,主要进行的操作就是增删查改
11.3小节是针对头插法新建链表进行实战
11.4小节是针对尾插法新建链表进行实战
11.5小节是链表按位置查找及按值查找实战
11.6小节是往第i个位置插入元素实战
11.7小节是链表的调试方法解析
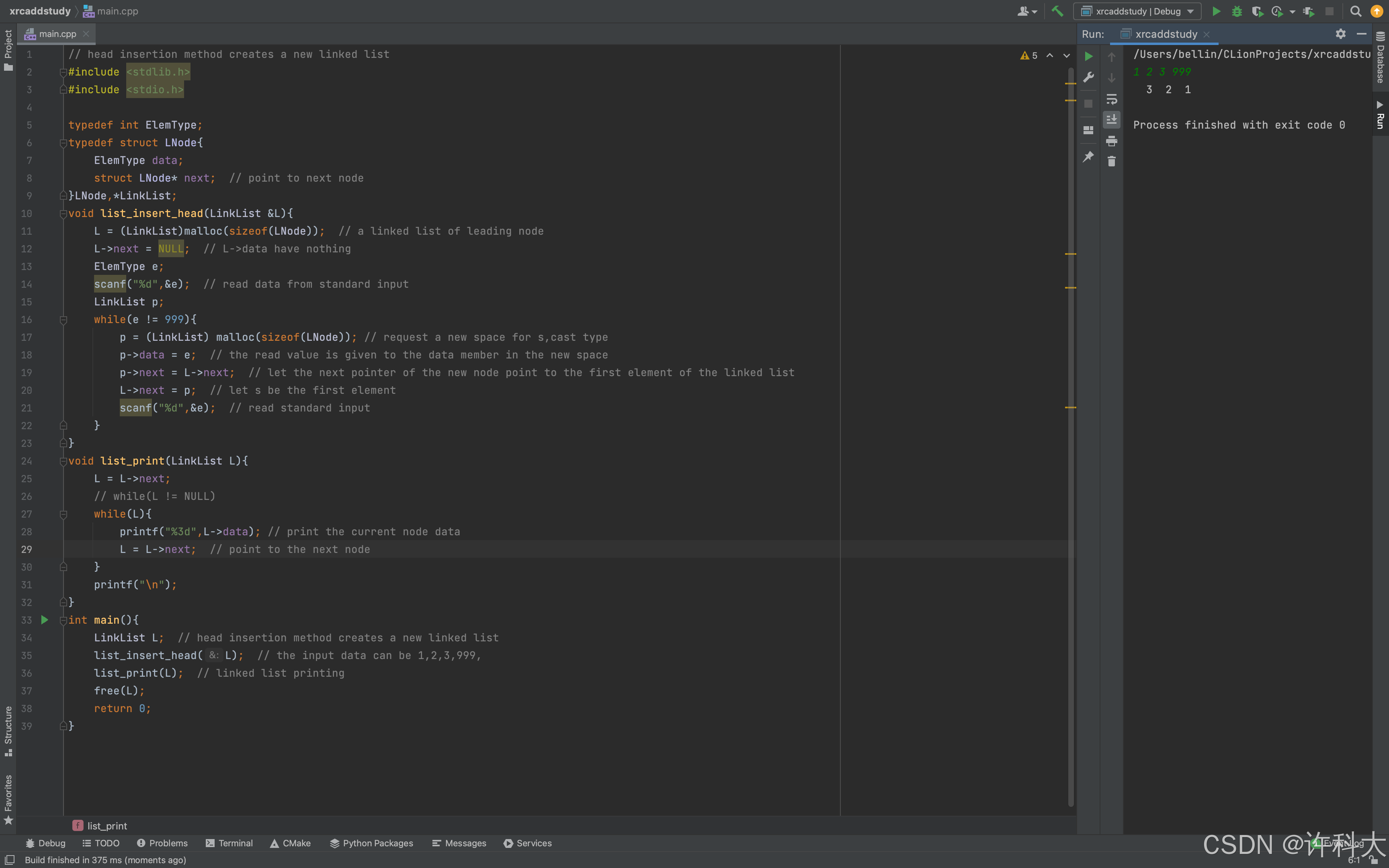
【11.3 头插法新建链表实战】
在第10.5小节已经学了链表的新增、删除、查找的原理。

// head insertion method creates a new linked list
#include <stdlib.h>
#include <stdio.h>
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // point to next node
}LNode,*LinkList;
void list_insert_head(LinkList &L){
L = (LinkList)malloc(sizeof(LNode)); // a linked list of leading node
L->next = NULL; // L->data have nothing
ElemType e;
scanf("%d",&e); // read data from standard input
LinkList p;
while(e != 999){
p = (LinkList) malloc(sizeof(LNode)); // request a new space for s,cast type
p->data = e; // the read value is given to the data member in the new space
p->next = L->next; // let the next pointer of the new node point to the first element of the linked list
L->next = p; // let s be the first element
scanf("%d",&e); // read standard input
}
}
void list_print(LinkList L){
L = L->next;
// while(L != NULL)
while(L){
printf("%3d",L->data); // print the current node data
L = L->next; // point to the next node
}
printf("\n");
}
int main(){
LinkList L; // head insertion method creates a new linked list
list_insert_head(L); // the input data can be 1,2,3,999,
list_print(L); // linked list printing
free(L);
return 0;
}
【11.3 题】
1、对于带头结点链表L,采用头插法新建链表,每次添加的新结点,是在头结点L的后面,头结点的位置是不动的,每次添加的新结点是放在第一个结点之前,并不是头结点之前,头结点后面的那个结点,称为第一个结点。
2、在list_insert_head(LinkList& L)函数中,形参带引用的原因是因为函数内会改变L的值。
3、新结点p采用这个方式为其申请空间,s=(LNode*)malloc(sizeof(LNode));
4、结构体类型为typedef struct LNode{int data;//数据域struct LNode next;//指针域}LNode;为新结点申请空间,使用s=(LNode*)malloc(sizeof(LNode));申请成功后,s中存储的只是新结点的起始内存地址,对于32位操作系统来讲,sizeof(s)的值是4,而s指向的结构体空间大小是sizeof(LNode),大小为8,编译器是如何知道指针s可以访问空间的大小,是根据s本身的类型来确定的。对于64为操作系统来讲,sizeof(s)的大小是8,这时s指向的结构体空间大小是sizeof(LNode),大小为16.malloc返回的是申请空间的起始地址,s本身没有存储任何数据域data,和指针域next,是s指向的空间中存储了data和next。
5、头插法的代码是LNode* s;int x;L=(LinkList)malloc(sizeof(LNode));//带头结点的链表L->next=NULL;//L->data这里没放东西scanf("%d",&x);//从标准输入读取数据while(x!=NULL){s=(LNode*)malloc(sizeof(LNode));//申请一个新空间给s,强制类型转换s->next=L->next;//让新结点的next指针指向链表的第一个元素(第一个放数据的元素)L->next=s;//让s作为第一个元素scanf("%d",&x);//读取标准输入}上面代码是头插法的代码,核心是s->next=L->next;和L->next=s;这两句不可以交换。先进行L->next=s;就再也拿不到原来第一个结点的地址了,在进行s->next=L->next;相当于s指向了自身。
【11.4 尾插法新建链表实战】
在第10.5小节已经学了链表的新增、删除、查找的原理。
尾插法的特点是始终让尾部指针r指向链表的尾部。
// head insertion method creates a new linked list
#include <stdlib.h>
#include <stdio.h>
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // point to next node
}LNode,*LinkList;
void list_insert_tail(LinkList &L){
L = (LinkList) malloc(sizeof(LNode)); // a linked list of leading node
LinkList t,p; // t means tail node
t = L;
ElemType e;
scanf("%d",&e);
while(e != 999){
p = (LinkList) malloc(sizeof(LNode));
p->data = e;
t->next = p; // let the tail node point to the new node
t = p; // t point to the new tail node
scanf("%d",&e);
}
t->next = NULL; // the next pointer to the tail node is assigned NULL
}
void list_insert_head(LinkList &L){
L = (LinkList)malloc(sizeof(LNode)); // a linked list of leading node
L->next = NULL; // L->data have nothing
ElemType e;
scanf("%d",&e); // read data from standard input
LinkList p;
while(e != 999){
p = (LinkList) malloc(sizeof(LNode)); // request a new space for s,cast type
p->data = e; // the read value is given to the data member in the new space
p->next = L->next; // let the next pointer of the new node point to the first element of the linked list
L->next = p; // let s be the first element
scanf("%d",&e); // read standard input
}
}
void list_print(LinkList L){
L = L->next;
// while(L != NULL)
while(L){
printf("%3d",L->data); // print the current node data
L = L->next; // point to the next node
}
printf("\n");
}
int main(){
LinkList L; // head insertion method creates a new linked list
list_insert_head(L); // the input data can be 1,2,3,999,
list_print(L); // linked list printing
list_insert_tail(L);
list_print(L);
free(L);
return 0;
}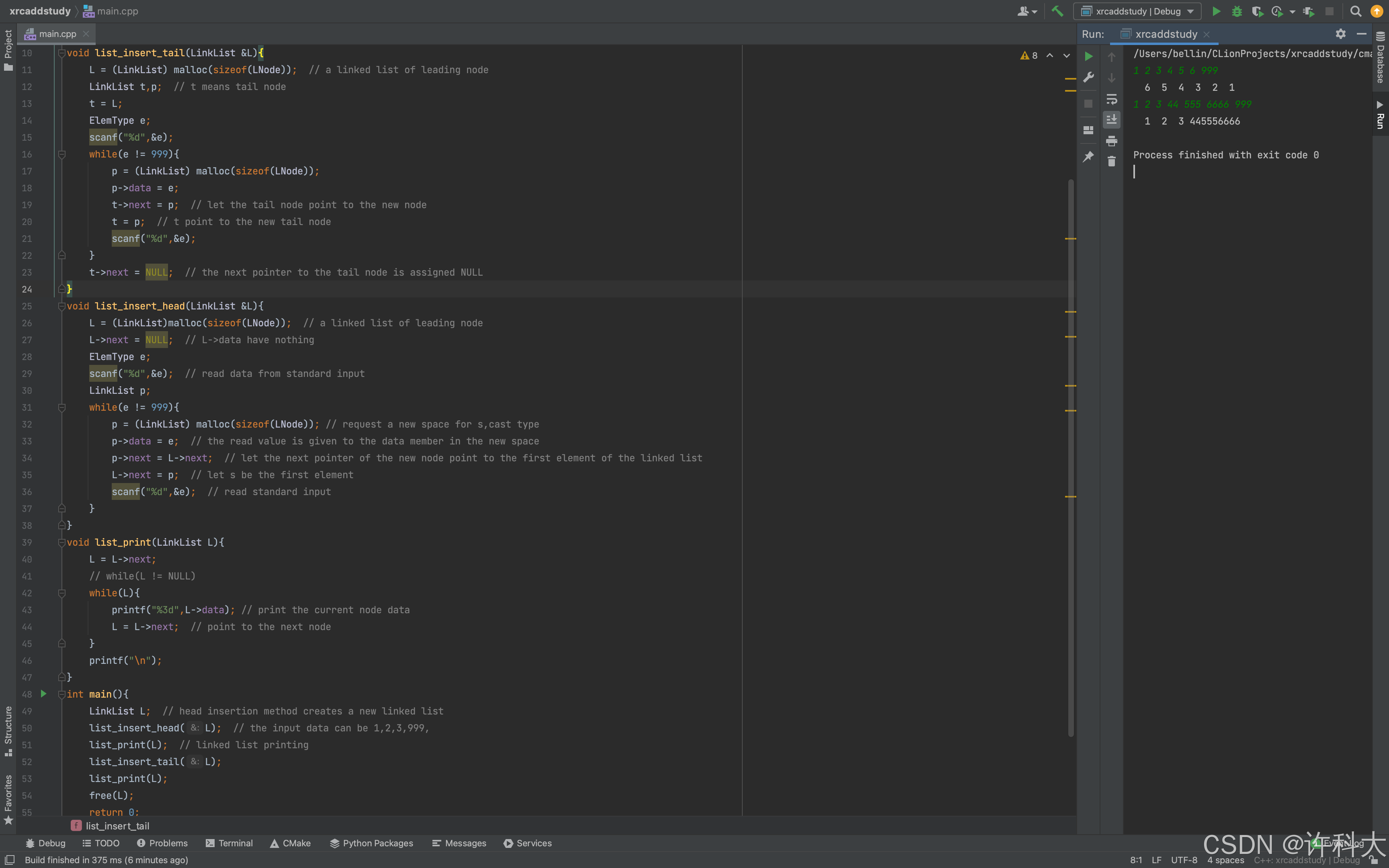
【11.4 题】
1、尾插法新建链表,需要使用一个辅助指针r,始终指向尾部,从而避免尾部都得需要从头遍历。
2、链表头插,和链表尾插的时间复杂度一样,都是O(1).因为头插、尾插都不涉及结点的遍历、挪动,所以时间复杂度是O(1).
3、尾插法新建链表,放入元素顺序是3,4,5,6,7,最终链表遍历打印结果是3,4,5,6,7.
【11.5 按位置查找及按值查找实战】
按位置查找要注意查找位置是否合法。
// head insertion method creates a new linked list
#include <stdlib.h>
#include <stdio.h>
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // point to next node
}LNode,*LinkList;
// find node value by location,NULL means the node you are looking for does not exist
LinkList list_search_position(LinkList L,int position){
if(position < 0){
return NULL;
}
if(position == 0){
return L;
}
int i = 0;
while (L && i < position){
L = L->next;
i++;
}
return L;
}
// search by value,return NULL means not found
LinkList list_search_value(LinkList L,ElemType e){
L = L->next;
while(L && L->data != e){
L = L->next;
}
return L;
}
void list_insert_tail(LinkList &L){
L = (LinkList) malloc(sizeof(LNode)); // a linked list of leading node
// L->data = 10;
LinkList t,p; // t means tail node
t = L;
ElemType e;
scanf("%d",&e);
while(e != 999){
p = (LinkList) malloc(sizeof(LNode));
p->data = e;
t->next = p; // let the tail node point to the new node
t = p; // t point to the new tail node
scanf("%d",&e);
}
t->next = NULL; // the next pointer to the tail node is assigned NULL
}
void list_insert_head(LinkList &L){
L = (LinkList)malloc(sizeof(LNode)); // a linked list of leading node
L->next = NULL; // L->data have nothing
ElemType e;
scanf("%d",&e); // read data from standard input
LinkList p;
while(e != 999){
p = (LinkList) malloc(sizeof(LNode)); // request a new space for s,cast type
p->data = e; // the read value is given to the data member in the new space
p->next = L->next; // let the next pointer of the new node point to the first element of the linked list
L->next = p; // let s be the first element
scanf("%d",&e); // read standard input
}
}
void list_print(LinkList L){
L = L->next;
// while(L != NULL)
while(L){
printf("%3d",L->data); // print the current node data
L = L->next; // point to the next node
}
printf("\n");
}
int main(){
LinkList L,p; // head insertion method creates a new linked list
list_insert_head(L); // the input data can be 1,2,3,999,
list_print(L); // linked list printing
list_insert_tail(L);
list_print(L);
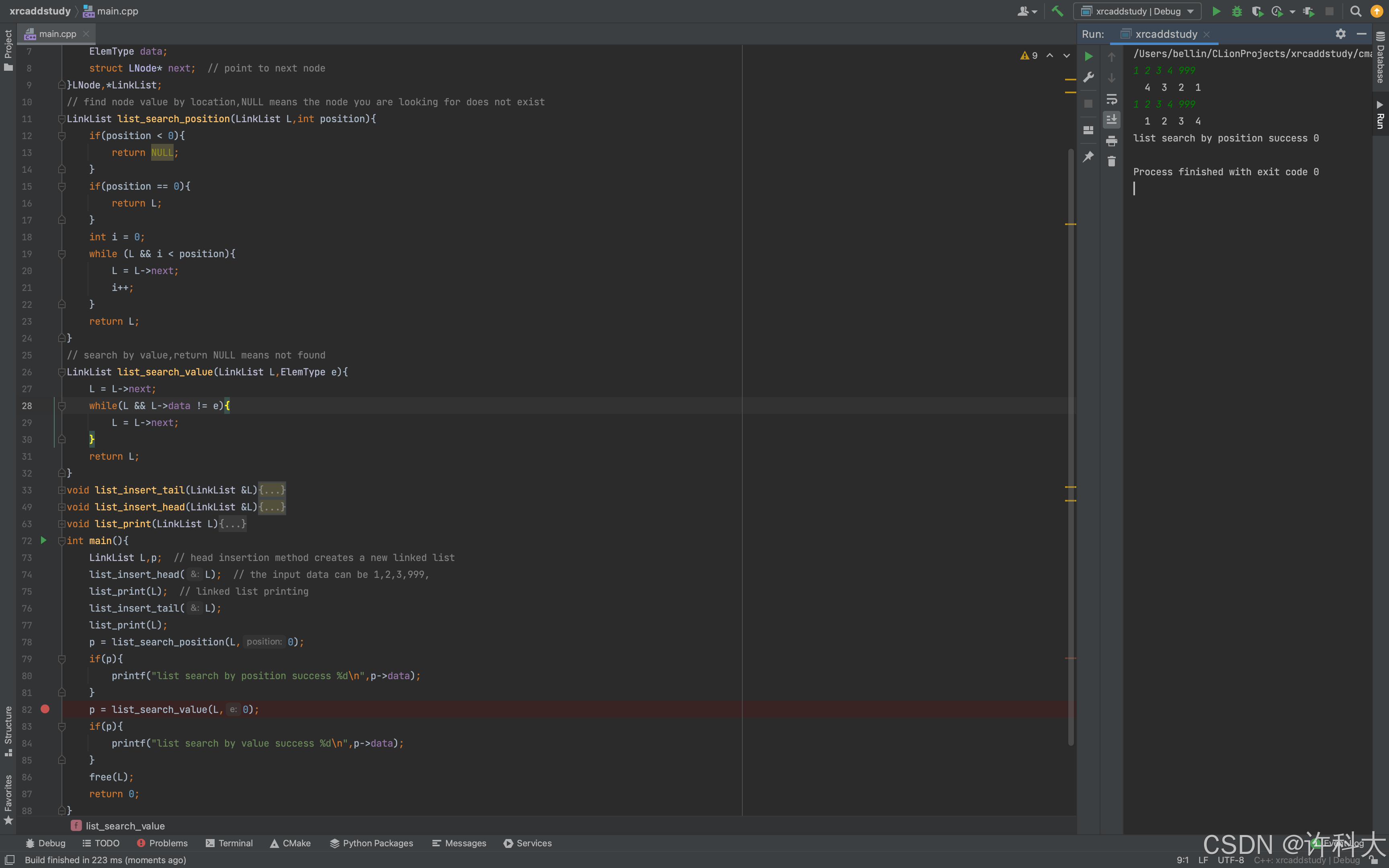
p = list_search_position(L,4);
if(p){
printf("list search by position success %d\n",p->data);
}
p = list_search_value(L,4);
if(p){
printf("list search by value success %d\n",p->data);
}
free(L);
return 0;
}
【11.5 题】
1、按位置查找时,头结点是位置0,头结点之后的结点,是第一个结点,如果链表内元素是3,4,5,6,7,那么最多只能查第5个结点。
2、因为头结点不放值,所以按值查找从第一个结点遍历,来判断是否是查找的值,如果没找到返回NULL,找到了返回对应结点的地址。
3、链表按值查找的时间复杂度是O(n),按位置查找的时间复杂度是O(n).顺序表的按位置查找获取元素时间复杂度是O(1).
【11.6 往第i个位置插入元素实战】
往第i个位置插入元素的流程图
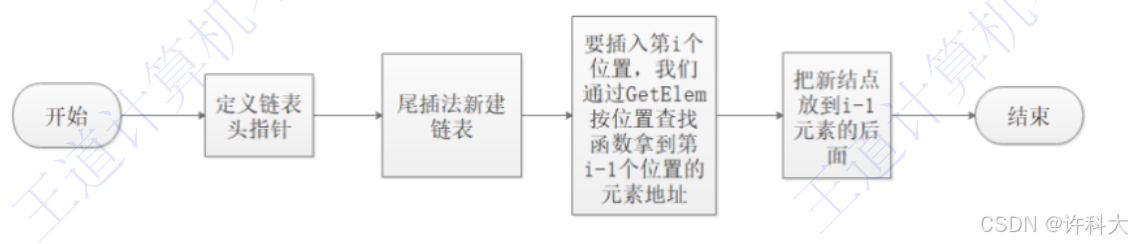
1)定义链表头指针
2)尾插法新建链表
3)要插入第i个位置,通过getelem按位置查找函数拿到第i-1个位置的元素地址
4)把新结点放到i-1元素的后面
// head insertion method creates a new linked list
#include <stdlib.h>
#include <stdio.h>
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // point to next node
}LNode,*LinkList;
LinkList list_search_position(LinkList L,int position);
bool list_insert_position(LinkList L,int position,ElemType e){
LinkList pre = list_search_position(L,position-1);
if(NULL == pre){
return false;
}
LinkList curr = (LinkList) malloc(sizeof(LNode));
curr->data = e;
curr->next = pre->next;
pre->next = curr;
return true;
}
// find node value by location,NULL means the node you are looking for does not exist
LinkList list_search_position(LinkList L,int position){
if(position < 0){
return NULL;
}
if(position == 0){
return L;
}
int i = 0;
while (L && i < position){
L = L->next;
i++;
}
return L;
}
// search by value,return NULL means not found
LinkList list_search_value(LinkList L,ElemType e){
L = L->next;
while(L && L->data != e){
L = L->next;
}
return L;
}
void list_create_insert_tail(LinkList &L){
L = (LinkList) malloc(sizeof(LNode)); // a linked list of leading node
// L->data = 10;
LinkList t,p; // t means tail node
t = L;
ElemType e;
scanf("%d",&e);
while(e != 999){
p = (LinkList) malloc(sizeof(LNode));
p->data = e;
t->next = p; // let the tail node point to the new node
t = p; // t point to the new tail node
scanf("%d",&e);
}
t->next = NULL; // the next pointer to the tail node is assigned NULL
}
void list_create_insert_head(LinkList &L){
L = (LinkList)malloc(sizeof(LNode)); // a linked list of leading node
L->next = NULL; // L->data have nothing
ElemType e;
scanf("%d",&e); // read data from standard input
LinkList p;
while(e != 999){
p = (LinkList) malloc(sizeof(LNode)); // request a new space for s,cast type
p->data = e; // the read value is given to the data member in the new space
p->next = L->next; // let the next pointer of the new node point to the first element of the linked list
L->next = p; // let s be the first element
scanf("%d",&e); // read standard input
}
}
void list_print(LinkList L){
L = L->next;
// while(L != NULL)
while(L){
printf("%3d",L->data); // print the current node data
L = L->next; // point to the next node
}
printf("\n");
}
int main(){
LinkList L,p; // head insertion method creates a new linked list
list_create_insert_head(L); // the input data can be 1,2,3,999,
list_print(L); // linked list printing
list_create_insert_tail(L);
list_print(L);
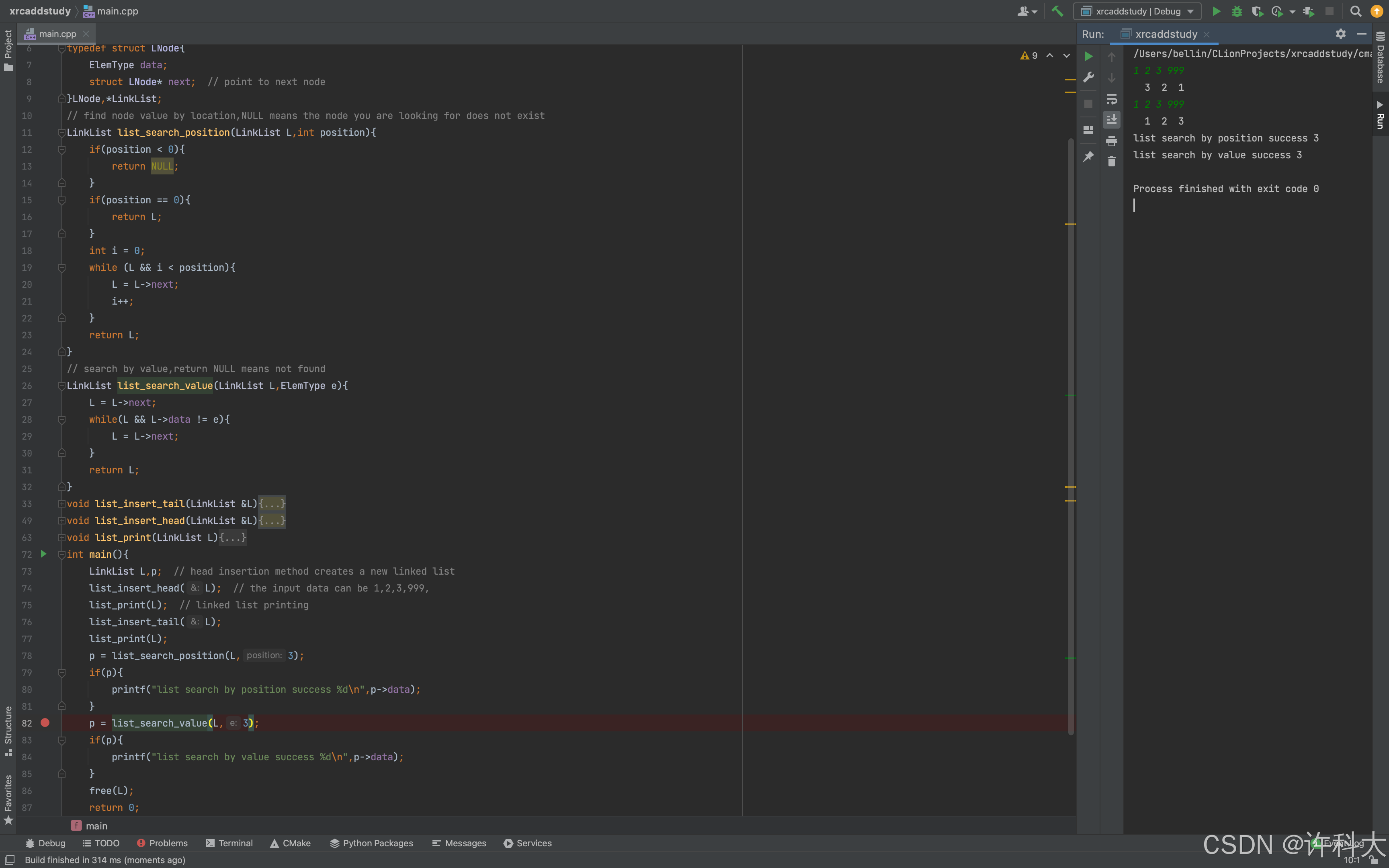
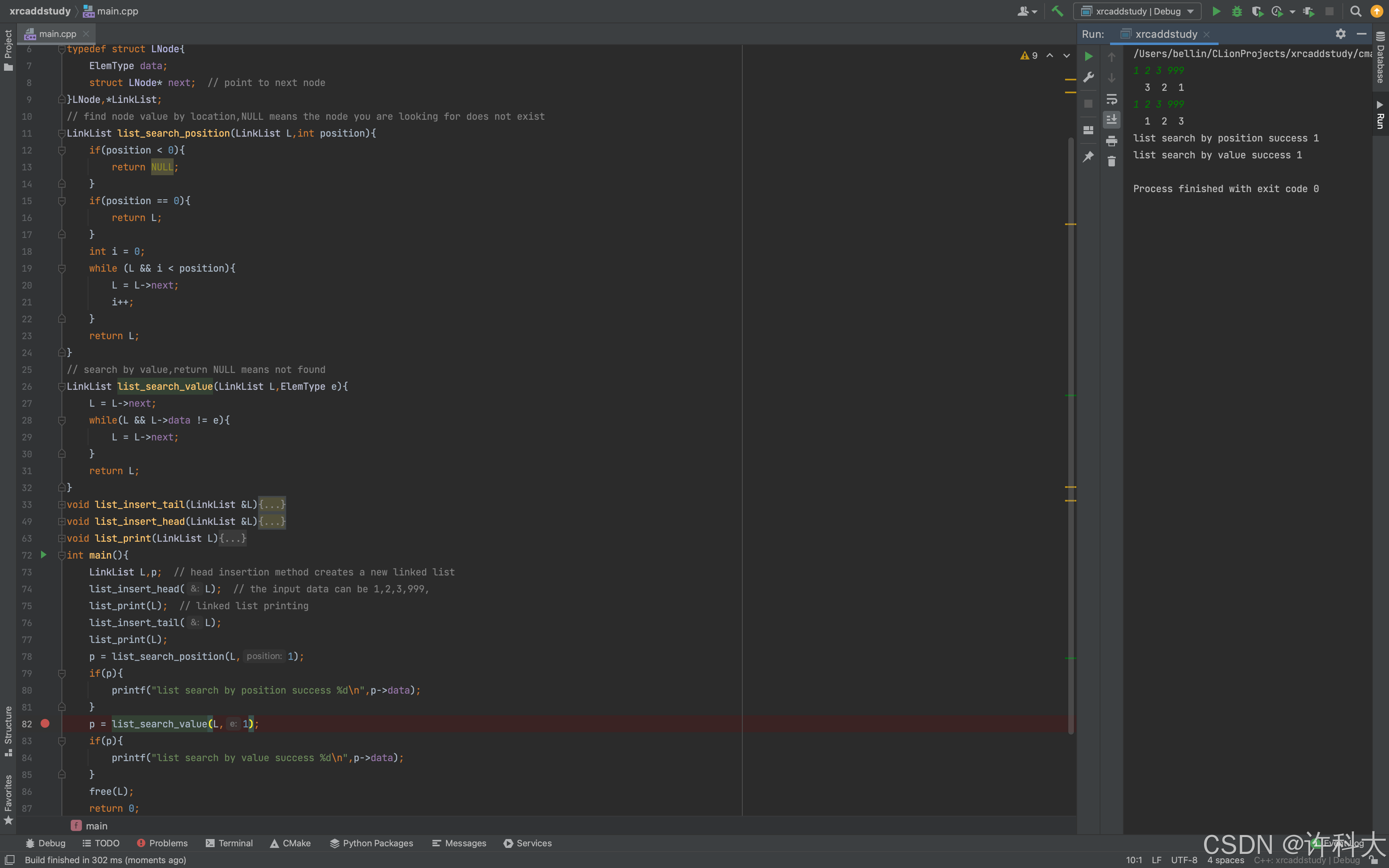
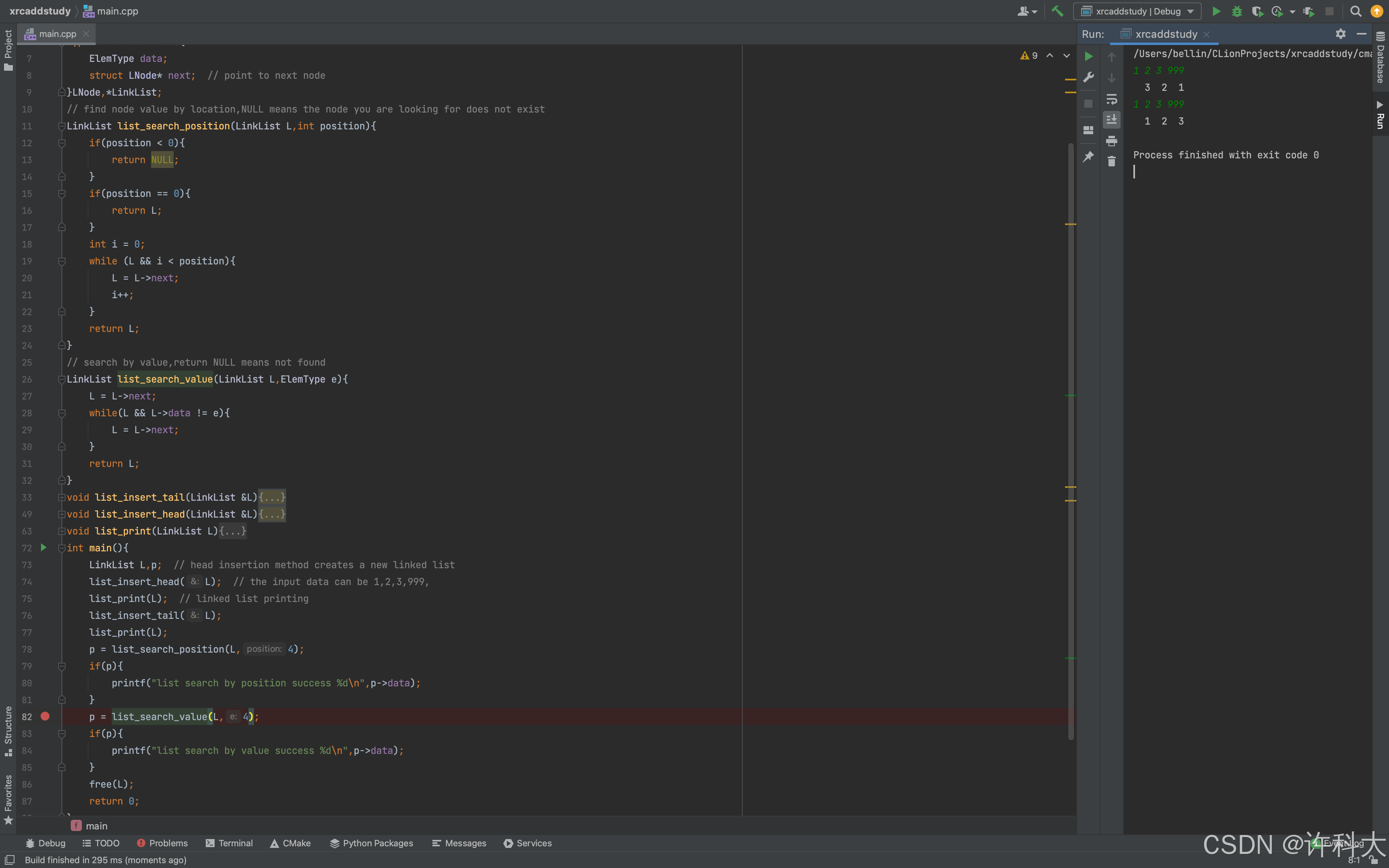
p = list_search_position(L,3);
if(p){
printf("list search by position success %d\n",p->data);
}
p = list_search_value(L,3);
if(p){
printf("list search by value success %d\n",p->data);
}
bool insert_position;
insert_position = list_insert_position(L,4,2026);
if(insert_position){
printf("linked list was successfully inserted at the specified position \n");
list_print(L);
}
free(L);
return 0;
}
【11.6 题】
1、往第i个位置插入,首先需要list_search_position函数,拿到第i-1个位置元素地址。
2、链表有5个元素,不可以插入到第10个位置,只能查到第1到第6个位置。
3、通过list_search_position函数获取第i-1个元素的地址时,如果返回的是NULL,代表插入位置i不合法,不进行插入,不会给新结点申请空间,如果插入位置合法,才给新结点申请空间,并放入链表。
【11.7 链表的调试方法】
链表因为每一个结点在内存中不是连续的,因此不适合看内存视图,通过单步调试,直接在变量窗口,把头指针L,依次点开,观察每一个结点是否符合预期。
【11.7 题】
1、链表调试时主要看变量窗口,不适合用内存视图。
2、链表调试时,通过在变量窗口对链表名字依次点开每个next结点来看链表内容是否符合预期
3、如果调试时发现一个普通单链表中有结点的地址值是一样的,有问题。除非是循环链表,双向链表等,否则指针域next的值是独一无二的,不会出现地址值相同的情况。
4、在链表代码中出现s->next=xxx时,实际是某个结点的起始地址,赋值给s的指针域。也可以说是s的next指向了xxx结点。
【11 代码题】
输入3 4 5 6 7 999一串整数,999代表结束,通过头插法新建链表,并输出,通过尾插法新建链表并输出。数之间空格隔开。
#include <stdlib.h>
#include <stdio.h>
// 输入3 4 5 6 7 999一串整数,999代表结束,通过头插法新建链表,并输出,通过尾插法新建链表并输出。
// 数之间空格隔开。
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // point to the next node
}LNode,*LinkList;
void list_create_tail(LinkList &L){
ElemType e;
scanf("%d",&e);
L = (LinkList) malloc(sizeof (LNode));
LinkList p,tail = L;
while(e != 999){
p = (LinkList) malloc(sizeof (LNode));
p->data = e;
tail->next = p;
tail = p;
scanf("%d",&e);
}
tail->next = NULL;
}
void list_create_head(LinkList &L){
ElemType e;
scanf("%d",&e); // read the standard input
L = (LinkList) malloc(sizeof(LNode)); // linked list with head node
L->next = NULL; // L.data hove nothing
while (e!=999){
LinkList p = (LinkList) malloc(sizeof(LNode));
p->data = e; // give the data member of the new space new value
p->next = L->next; // let the next point of the new node point to the first element of the linked list
L->next = p; // let p as the first element
scanf("%d",&e); // read the standard input
}
}
void list_print(LinkList L){
L = L->next;
while(L){
printf("%d",L->data);
L = L->next;
if(L!=NULL){
printf(" ");
}
}
printf("\n");
}
int main(){
LinkList L = NULL;
list_create_head(L);
list_print(L);
list_create_tail(L);
list_print(L);
free(L);
return 0;
}
【第12节 单链表的删除 考研真题实战】
【12.2 本节内容介绍】
本节分为12.3小节至12.6小节,涉及链表的删除,链表的真题解析
12.3小节是链表删除进行实战
12.4小节是针对408考研真题2019年41题进行题目解读域解题设计
12.5小节是针对408考研真题2019年41题进行实战
12.6小节是分析真题实战代码的时间复杂度
【12.3 单链表的删除操作实战】
单链表的删除流程图
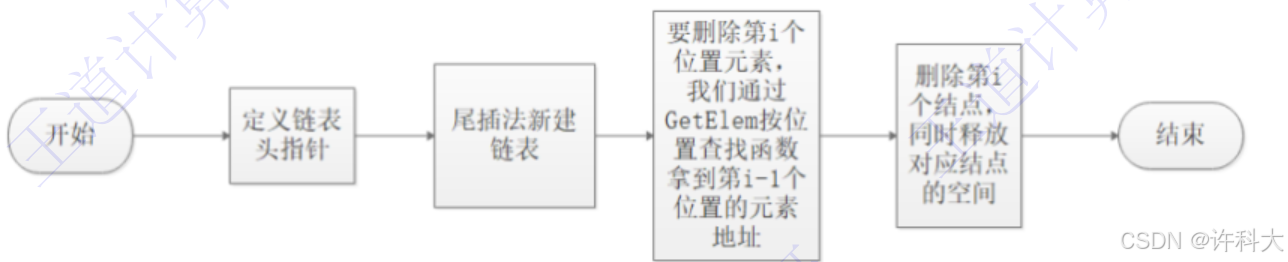
1)定义链表头指针
2)尾插法新建链表
3)要删除第i个位置元素,通过list_search_position按位置查找函数拿到第i-1个位置的元素地址
4)删除第i个结点,同时释放对应结点的空间
【例】删除链表的第i个结点
#include <stdlib.h>
#include <stdio.h>
// linked list delete
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // point to the next node
}LNode,*LinkList;
LinkList list_search_position(LinkList L,int position);
bool list_delete_position(LinkList L,int position){
LinkList pre = list_search_position(L,position-1);
if(NULL == pre){
return false;
}
LinkList del; // stores the node to be deleted
del = pre->next;
if(NULL == del){ // delete node is list length add one
return false;
}
pre->next = del->next; // break chain
free(del); // free space of delete node
return true;
}
LinkList list_search_position(LinkList L,int position){
if(position < 0){
return NULL;
}
if(position == 0){
return L;
}
int i = 0;
while (i < position){
L = L->next;
i++;
}
return L;
}
void list_create_tail(LinkList &L){
ElemType e;
scanf("%d",&e);
L = (LinkList) malloc(sizeof (LNode));
LinkList p,tail = L;
while(e != 999){
p = (LinkList) malloc(sizeof (LNode));
p->data = e;
tail->next = p;
tail = p;
scanf("%d",&e);
}
tail->next = NULL;
}
void list_create_head(LinkList &L){
ElemType e;
scanf("%d",&e); // read the standard input
L = (LinkList) malloc(sizeof(LNode)); // linked list with head node
L->next = NULL; // L.data hove nothing
while (e!=999){
LinkList p = (LinkList) malloc(sizeof(LNode));
p->data = e; // give the data member of the new space new value
p->next = L->next; // let the next point of the new node point to the first element of the linked list
L->next = p; // let p as the first element
scanf("%d",&e); // read the standard input
}
}
void list_print(LinkList L){
L = L->next;
while(L){
printf("%d",L->data);
L = L->next;
if(L!=NULL){
printf(" ");
}
}
printf("\n");
}
int main(){
LinkList search,L = NULL;
list_create_head(L);
list_print(L);
list_create_tail(L);
list_print(L);
search = list_search_position(L,2);
if(search){
printf("list search success %d\n",search->data);
}
bool del = list_delete_position(L,2);
if (del){
list_print(L);
}
free(L);
return 0;
}
【12.3 题】
1、⭐️⭐️⭐️删除链表结点时,不会改变头结点L。带头结点的链表,头结点的位置是不动的,因此删除结点时,L是不变的。
2、删除第i个位置结点时,需要先拿到第i-1个结点pre,然后del=pre->next;如果del不为NULL,pre->next=del.next;来实现断链,同时通过freee(del)来释放删除结点的空间。
3、删除第i个结点的时间复杂度为O(n).需要先找到第i-1个结点,找到第i-1个结点需要遍历。,因此时间复杂度是O(n).
【12.4 408考研真题2019年41题题目解读与解题设计】
1 题目解读
设线性表L=(a1,a2,a3,...,an-2,an-1,an)采用带头结点的单链表保存,链表中的结点定义如下:typedef struct node{int data;struct node* next;} NODE;请设计一个空间复杂度为O(1)且时间上尽可能高效的算法,重新排列L中的各结点,得到线性表L'=(a1,an,a2,an-1,a3,an-2,...),要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或C++语言表述算法,关键之处给出注释。3)说明你所设计的算法的时间复杂度。
首先空间复杂度是O(1),不能申请额外空间,然后找到链表的中间结点,前面一半是链表L,将链表的后半部分给一个新的头结点L2,然后将链表L2进行原地逆置,然后再将L和L2链表进行合并。
2 解题设计
第一阶段,找到链表的中间结点。不是遍历两遍链表,第一次拿到总长度,第二次找到中间位置。使用两个指针同步向后遍历,定义两个指针变量pcurr,ppre,让pcur每次走两步,ppre指针每次走一步,这样当pcur指针走到最后,ppre指针刚好在中间。
由于pcur每次循环都是走两步的,因此没凑一步都注意判断是否为NULL。
第二阶段,后一半链表设置为L2,让L2原地逆置。需要判断链表是否为空,如果为空,就返回。如果只有1个结点,也不需要逆置,直接返回。
第一步:链表原地逆置,需要使用3个指针,假如分别是r,s,t,指向链表的1,2,3,也就是前三个结点。
第二步:让s->next=r,这样2号结点就指向了1号结点,完成了逆置。
第三步:r=s,s=t,t=t->next,通过这个操作,r,s,t分别指向了链表的2,3,4结点,回到第二步,循环往复,当t为NULL时,结束循环。
第四步:循环结束时,t为NULL,s为最后一个结点,r是倒数第二个结点,需要再次执行一下s->next=r。
第五步:需要L2->next->next=NULL;因为原有链表头结点变成链表最后一个结点。最后一个结点的next需要为NULL,这时让L2指向s,因为s是原链表最后一个结点,完成了逆置后,就是第一个结点,因此链表头结点L2指向s,L2->next=s。
第三阶段,将L与L2链表合并,合并时轮流放入一个结点。因为空间复杂度是O(1),因此不申请新空间,但是依然需要3个指针(pcur,p,q),合并后的新链表让pcur指针始终指向新链表尾部,初始化为pcur=L->next,使用p指针始终指向链表L待放入的结点,初始化值为p->L->next,q指针始终指向L2待放入的结点,初始化值为q=L2->next.因为链表L的第一个结点不动,所以p=p->next。
开启循环while(p!=NULL&&q!=NULL),先将pcur->next=q和pcur=p.next,接着pcur->next=p,然后p=p->next和pcur=p.next,直到循环结束。循环结束后,有可能L还剩一个结点,也有可能L2还剩一个结点,但是只会有一个剩余的有结点,因此判断p不为NULL,把p放入。如果q不为NULL,把q放入即可。
【12.4 题】
1、链表找中间结点时,可以采用两个指针的方法,一个指针走两步,一个指针走一步,走两步的指针到达尾部时,走一步的指针刚好在中间位置。例如找链表的倒数第4个结点,也是双指针操纵,先让一个指针走4步,然后两个指针同时往后遍历。
2、长度为n的链表,进行链表原地逆置,时间复杂度是O(n)。链表原地逆置需要遍历一次链表,所以时间复杂度是O(n).
3、把两条链表合并为一条链表的操作,空间复杂度是O(1),因为不需要申请额外的空间.
4、把两条长度为n的链表交替合并(一个放奇数位置,一个放偶数位置)为一条链表的操作,时间复杂度是O(n)。
【12.5 真题题目代码实战】
#include <stdlib.h>
#include <stdio.h>
// back interpolation
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // 指向下一个结点
}LNode,*LinkList;
void list_create_tail(LinkList &L){
L = (LinkList)malloc(sizeof(LNode)); // 带头结点的链表
ElemType e;
scanf("%d",&e);
LinkList p,tail = L; // tail指向链表尾部
while(e!=999){
p = (LinkList) malloc(sizeof (LNode));
p->data = e;
tail->next = p; // 尾部指针指向新结点
tail = p; // 指向新的链表尾部结点
scanf("%d",&e);
}
tail->next = NULL; // 尾结点的next指针赋值为NULL
}
void list_print(LinkList L){
L = L->next;
while(L){
printf("%4d",L->data);
L = L->next;
}
printf("\n");
}
void find_middle(LinkList L,LinkList &L2){
L2 = (LinkList) malloc(sizeof (LNode)); // 带头结点的链表
LinkList fast = L->next,slow = L->next;
while(fast){
fast = fast->next;
if(fast == NULL){ // 快的走2步
break;
}
fast = fast->next;
if (fast == NULL){ // 偶数个时,slow不需要再往后移动了
break;
}
slow = slow->next; // 慢的走1步
}
L2->next = slow->next; // 让L2成为链表的后半部分
slow->next = NULL; // 断链,让L成为链表的前半部分
}
void reverse(LinkList L2){
if(L2->next == NULL || L2->next->next == NULL){ // 链表为空,或者链表只有一个结点
return;
}
LinkList a,b,c;
a = L2->next;
b = a->next;
c = b->next;
while(c){
b->next = a;
a = b;
b = c;
c = c->next;
}
b->next = a;
L2->next->next = NULL; // 链表的第一个结点的next要为NULL
L2->next = b; // L2指向原链表的尾部,将原链表的尾部作为L2链表的头部,实现原地逆转链表
}
void merge(LinkList L,LinkList L2){
if(L->next == NULL || L2->next == NULL){
return;
}
LinkList a,b,tail;
a = L->next->next;
b = L2->next;
tail = L->next;
while(a!=NULL &&b!=NULL){
tail->next = b; // b接到尾部
tail = b; // 尾部后移更新
b = b->next; // 新的待拼接
tail->next = a; // a接到尾部
tail = a; // 尾部后移更新
a = a->next; // 新的待拼接
}
if(a!=NULL){
tail->next = a;
}
if(b!=NULL){
tail->next = b;
}
}
int main(){
LinkList L,L2;
list_create_tail(L);
list_print(L);
find_middle(L,L2);
list_print(L);
list_print(L2);
reverse(L2);
list_print(L2);
merge(L,L2);
list_print(L);
free(L);
return 0;
}
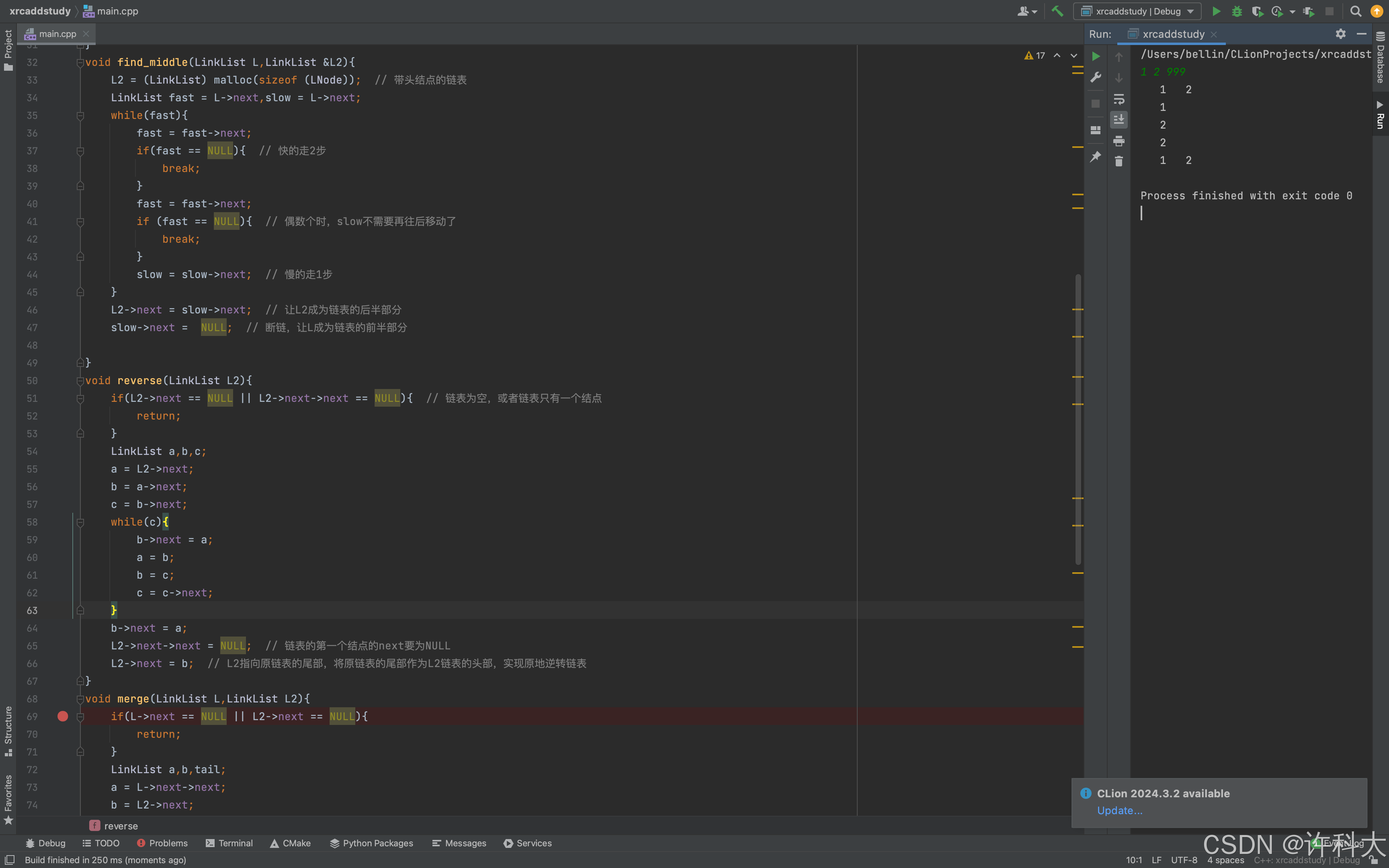
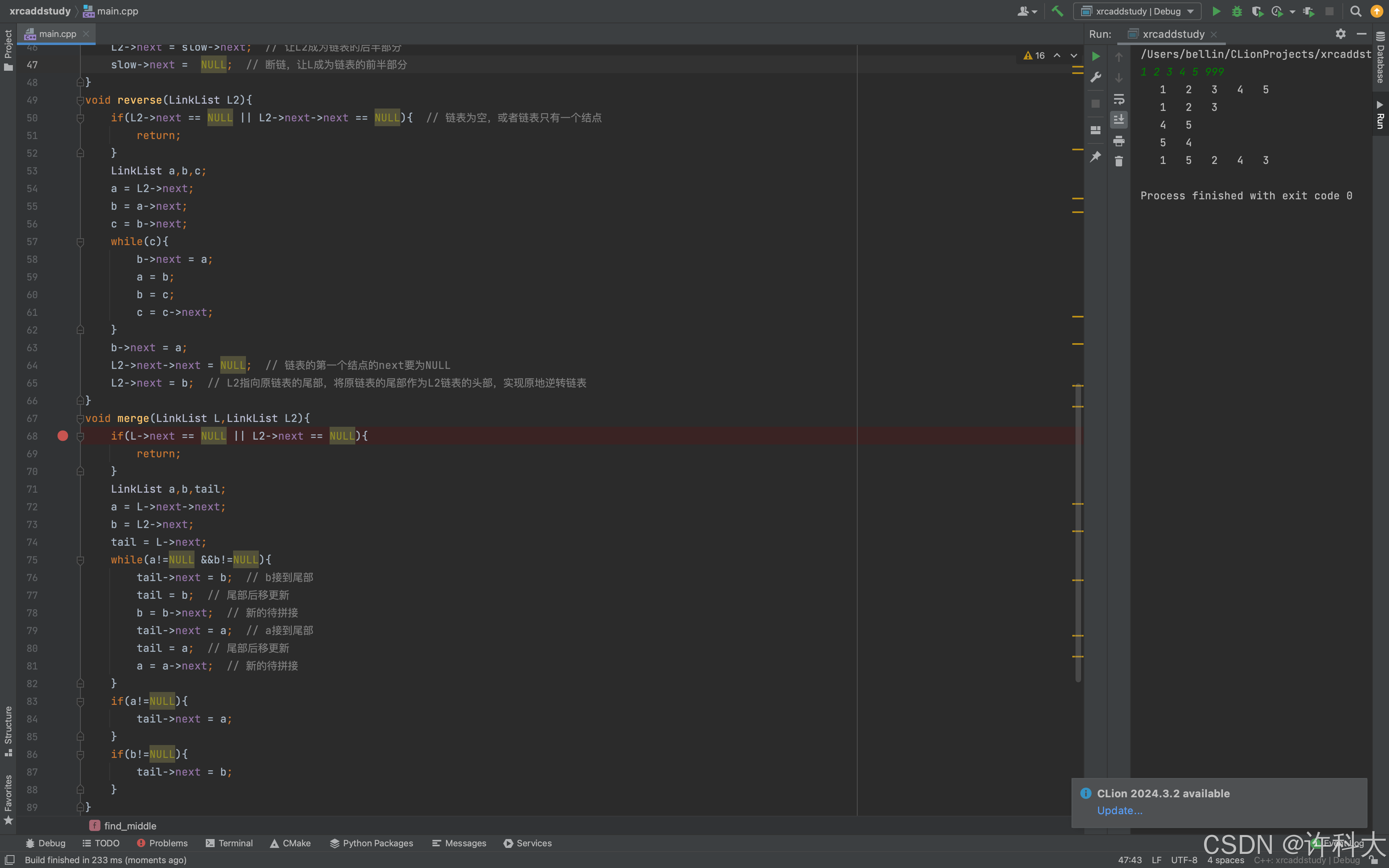
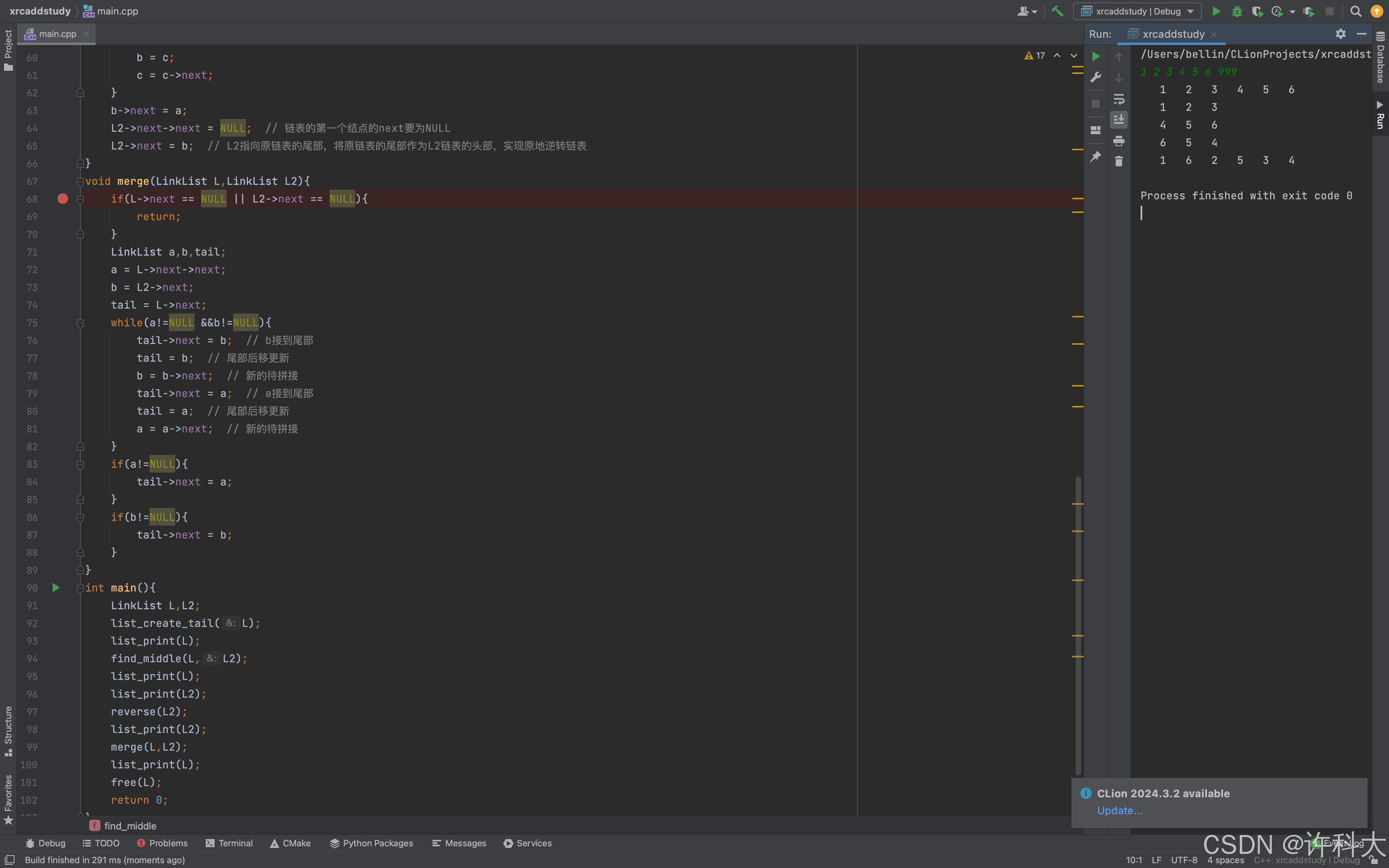
【12.6 分析真题代码的时间复杂度】
find_middle函数,有一个while循环,因为fast每次移动2个结点,所以循环次数是n/2,忽略首项系数,所以时间复杂度是O(n)。
reverse函数,因为只遍历了L2链表,遍历长度是n/2,所以时间复杂度是O(n)。
merge函数,while循环遍历次数是n/2,所以时间复杂度是O(n)。
3个函数总的运行次数是1.5n,忽略首项系数,所以时间复杂度是O(n)。
【12 代码题】
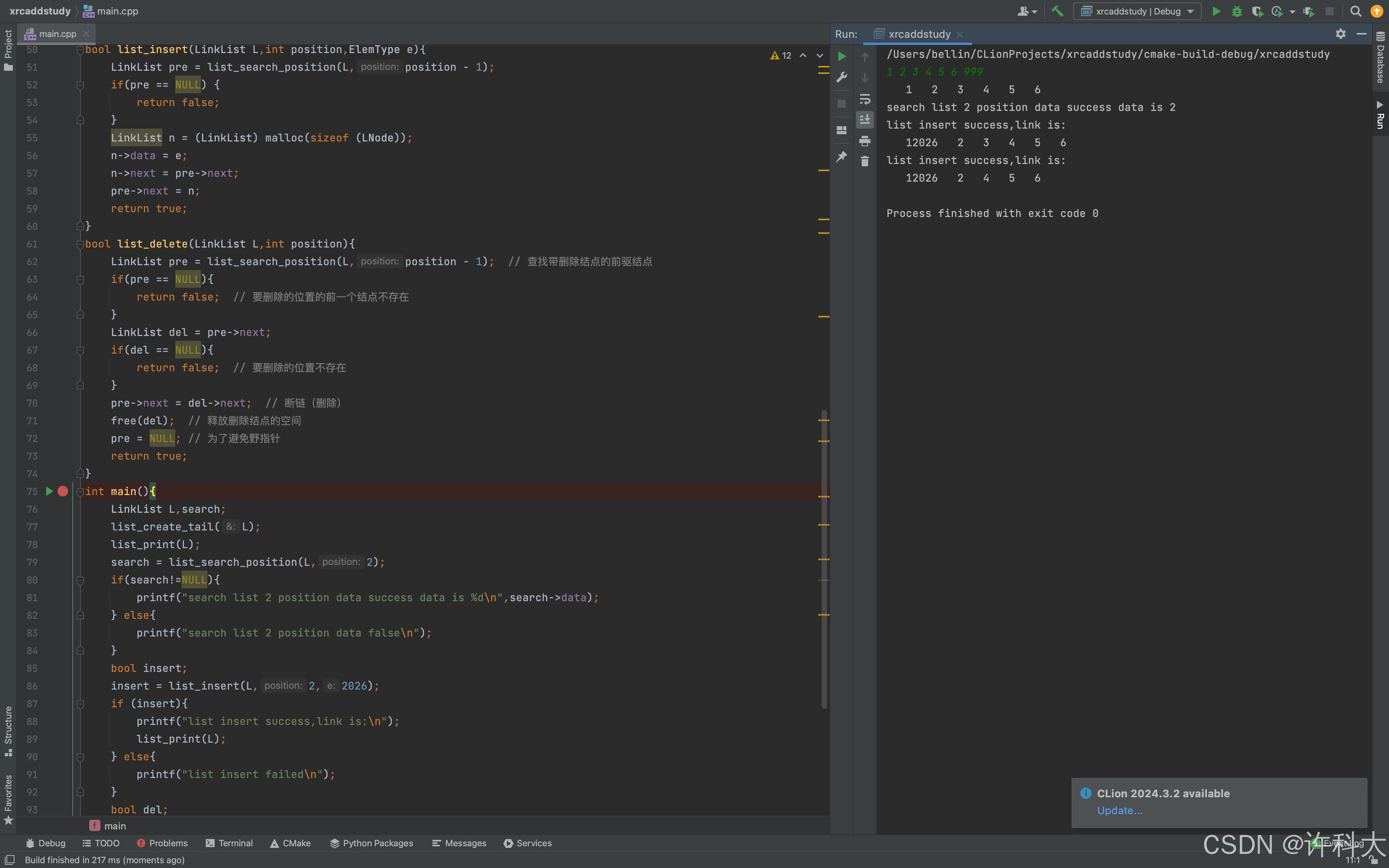
输入3 4 5 6 7 999一串整数,999代表结束,通过尾插法新建链表,查找第二个位置的值并输出,在2个位置插入99,输出2 99 4 5 6 7,删除第4个位置的值,打印输出3 99 4 6 7。
本题也可用双链表实现。
#include <stdlib.h>
#include <stdio.h>
// 输入3 4 5 6 7 999一串整数,999代表结束,通过尾插法新建链表,
// 查找第二个位置的值并输出,
// 在2个位置插入99,输出2 99 4 5 6 7,
// 删除第4个位置的值,打印输出3 99 4 6 7。
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next; // 指向下一个结点
}LNode,*LinkList;
void list_create_tail(LinkList &L){
L = (LinkList)malloc(sizeof(LNode)); // 带头结点的链表
ElemType e;
scanf("%d",&e);
LinkList p,tail = L; // tail指向链表尾部
while(e!=999){
p = (LinkList) malloc(sizeof (LNode));
p->data = e;
tail->next = p; // 尾部指针指向新结点
tail = p; // 指向新的链表尾部结点
scanf("%d",&e);
}
tail->next = NULL; // 尾结点的next指针赋值为NULL
}
void list_print(LinkList L){
L = L->next;
while(L){
printf("%4d",L->data);
L = L->next;
}
printf("\n");
}
LinkList list_search_position(LinkList L,int position){
if(position < 0){
return NULL;
}
if(position == 0){
return L;
}
int i = 1;
L = L->next;
while(L && i < position){
L = L->next;
i++;
}
return L;
}
bool list_insert(LinkList L,int position,ElemType e){
LinkList pre = list_search_position(L,position - 1);
if(pre == NULL) {
return false;
}
LinkList n = (LinkList) malloc(sizeof (LNode));
n->data = e;
n->next = pre->next;
pre->next = n;
return true;
}
bool list_delete(LinkList L,int position){
LinkList pre = list_search_position(L,position - 1); // 查找带删除结点的前驱结点
if(pre == NULL){
return false; // 要删除的位置的前一个结点不存在
}
LinkList del = pre->next;
if(del == NULL){
return false; // 要删除的位置不存在
}
pre->next = del->next; // 断链(删除)
free(del); // 释放删除结点的空间
pre = NULL; // 为了避免野指针
return true;
}
int main(){
LinkList L,search;
list_create_tail(L);
list_print(L);
search = list_search_position(L,2);
if(search!=NULL){
printf("search list 2 position data success data is %d\n",search->data);
} else{
printf("search list 2 position data false\n");
}
bool insert;
insert = list_insert(L,2,2026);
if (insert){
printf("list insert success,link is:\n");
list_print(L);
} else{
printf("list insert failed\n");
}
bool del;
del = list_delete(L,4);
if(del){
printf("list insert success,link is:\n");
list_print(L);
} else{
printf("list insert failed\n");
}
free(L);
return 0;
}
【第13节 栈与队列】
【13.2 与408关联】
请设计一个队列,要求满足:1)初始时队列为空;2)入队时,允许增加队列占用空间;3)出队后,出队元素所占用的空间课重复使用,即整个队列所占空间只增不减;4)入队操作和出队操作的时间复杂度始终保持为O(1)。请回答下列问题:1)该队列时应选择链式存储结构,还是应选择顺序存储结构?2)画出队列的初始状态,并给出判断队空和队满的条件。3)画出第一个元素入队后的队列状态。4)给出入队操作和出队操作的基本过程。
本大节课分为13.3小节到13.8小节,包含栈、队列、循环队列的原理讲解及实战
13.3小节是针对栈的原理讲解
13.4小节是针初始化栈-入栈-出栈实战
13.5小节是队列-循环队列原理解析
13.6小节是循环队列实战
13.7小节是队列的实战(通过链表的头插、头部删除实现)
13.8小节是2019年42题真题讲解
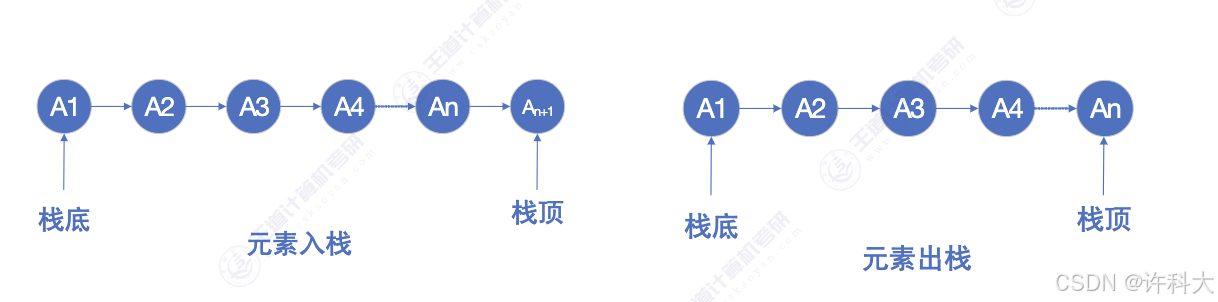
【13.3 栈的原理解析】
1 栈stack
stack: a pile of objects 一垛物品 堆栈又称为栈或堆叠,先进后出First In Fast Out LIFO
栈:只允许在一端进行插入或删除操作的线性表栈顶(Top)

2 栈的基本操作
3 顺序存储实现栈
typedef struct{
ElemType data[50];
int top;
}SqStack;
SqStack S;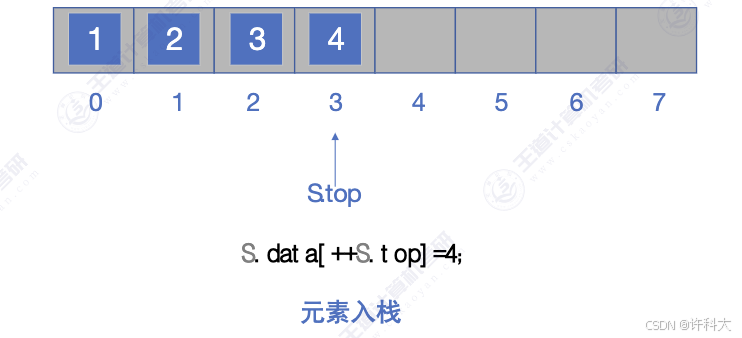

4 链式存储实现栈
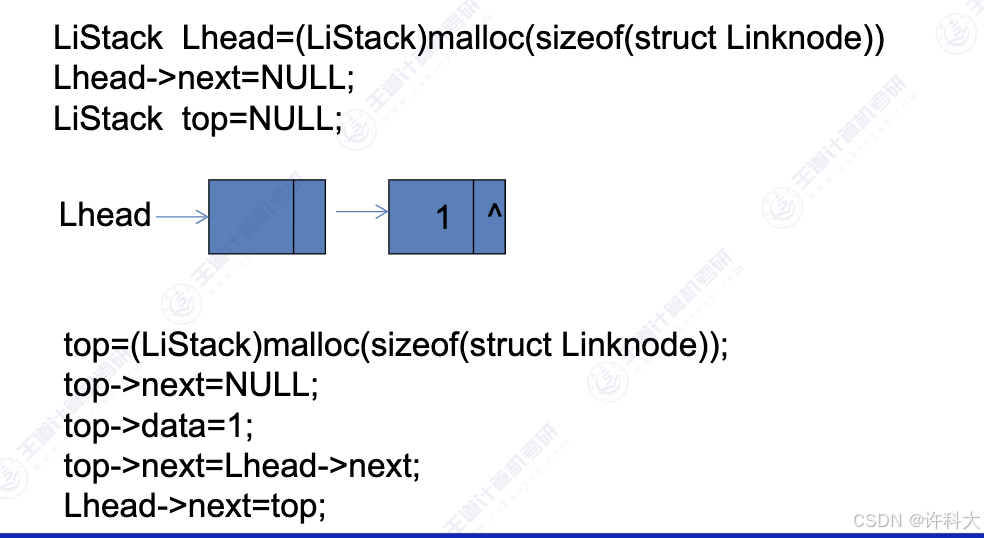
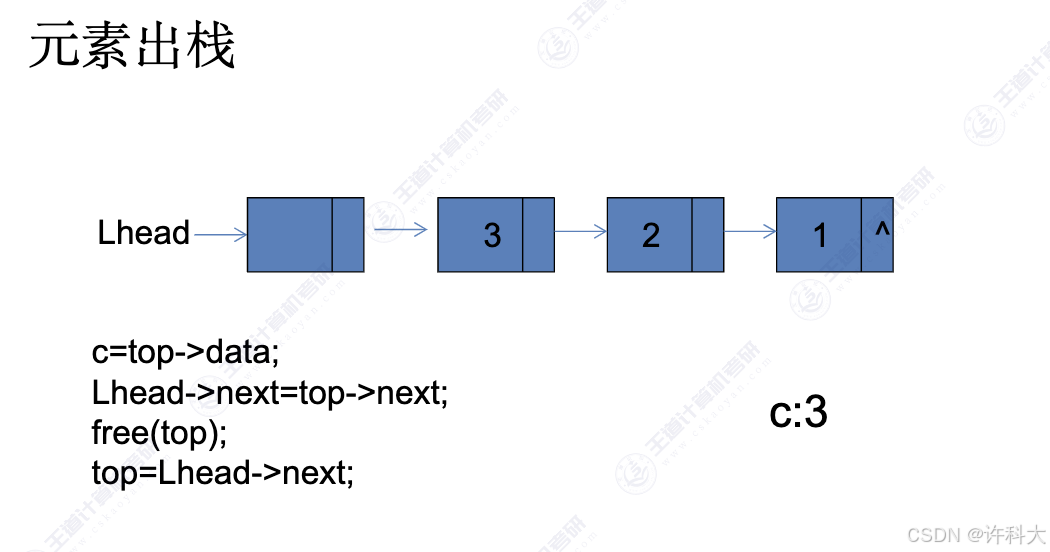

【13.3 题】
1、栈的特点是从栈顶入栈,从栈顶出栈。
2、如果数组大小是MaxSize,那么S.top等于MaxSize-1时,代表栈满。数组下标是从零开始,因此S.top等于MaxSize-1时,代表栈满。
3、可以用数组实现栈,也可以用链表实现栈,如果用单链表实现栈,实现方法是链表的头插法,入栈时从链表头部插入,出栈时从链表头部删除。
【13.4 初始化栈-入栈-出栈实战】
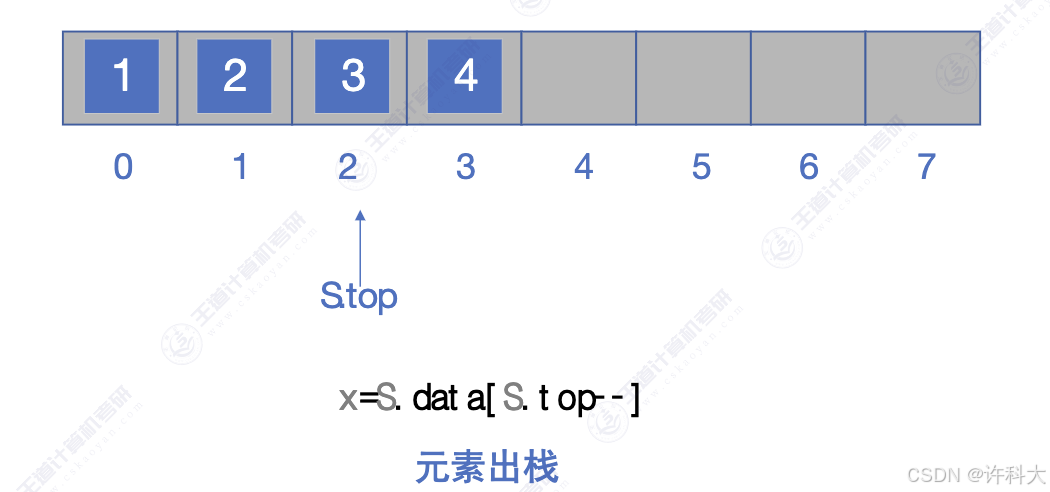
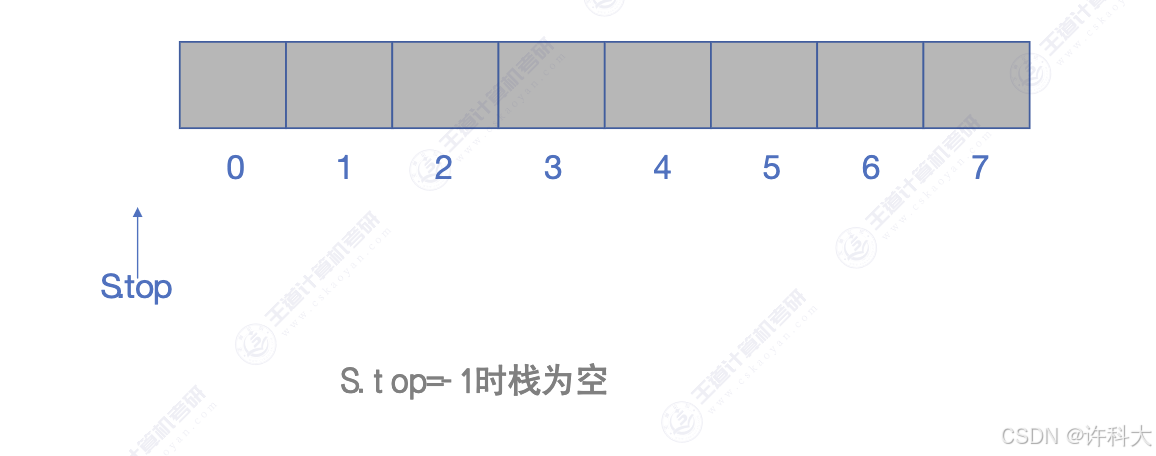
代码实战步骤依次是初始化栈,判断栈是否为空,压栈,获取栈顶元素,弹栈。S.top为-1时,代表栈为空,每次是先队S.top加1后,再次放置元素。
// stack
#include <stdio.h>
#define MaxSize 50
typedef int ElemType;
typedef struct{
ElemType data[MaxSize]; // 数组
int top;
}SqStack;
void stack_init(SqStack &S){
S.top = -1; // 代表栈为空
}
bool stack_empty(SqStack S){
if(-1==S.top){
return true;
} else{
return false;
}
}
void stack_push(SqStack &S,ElemType e){
if(MaxSize - 1 == S.top){ // 数组的大小不能改变,避免访问越界
return;
}
S.data[++S.top] = e;
}
bool stack_get(SqStack S,ElemType &e){
if(-1 == S.top){
return false;
}
e = S.data[S.top];
return true;
}
bool stack_pop(SqStack &S,ElemType &e){
if(-1 == S.top){
return false;
}
e = S.data[S.top--]; // 后减减
return true;
}
int main(){
SqStack S; // 先进后出FILO LIFO
stack_init(S);
if(stack_empty(S)){
printf("stack is empty\n");
}
stack_push(S,1);
stack_push(S,2);
stack_push(S,3);
ElemType e;
bool get;
get = stack_get(S,e);
if(get){
printf("get success,e is %d\n",e);
} else{
printf("get failed\n");
}
bool pop;
pop = stack_pop(S,e);
if(pop){
printf("pop success,e is %d\n",e);
} else{
printf("pop failed\n");
}
return 0;
}
【13.4 题】
1、栈的特点是先进后出。简称FILO,也可以称为后进先出。
2、栈可以进行压栈、弹栈,压栈操作,栈中元素变多,弹栈操作,栈中元素变少。
3、可以用数组实现栈,也可以用链表实现栈,代码中通过数组实现栈,S.top=-1时,代表栈为空。实现方法时每次先对S.top进行加1,然后再放置元素。
【13.5 队列-循环队列原理解析】
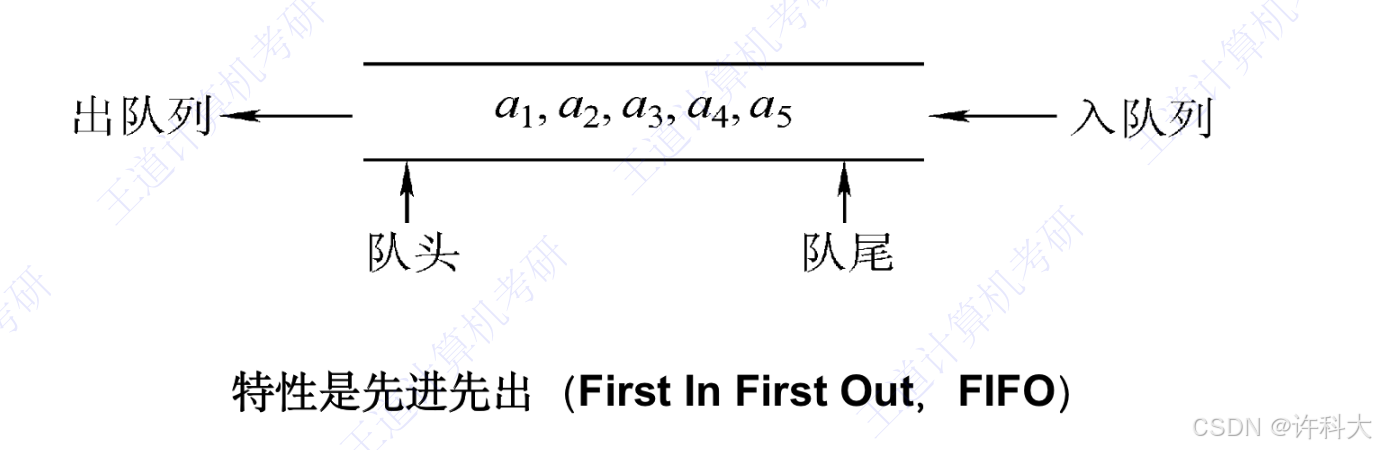
1 队列Queue
队列简称队,也是一种操作受限的线性表,只允许在表的一端进行插入,而在表的另一端进行删除。向队列中插入元素成为入队或进队;删除元素成为出队或离队;先进先出,FIFO。
对头(Front)。允许删除的一端,又称队首。
队尾(Rear)。允许插入的一端。
2 循环队列
#define MaxSize 6
typedef int ElemType;
typedef struct{
ElemType data[MaxSize]; // 数组,存储MaxSize-1个元素
int front, rear; // 队列头、队列尾
}SqQueue;
SqQueue Q;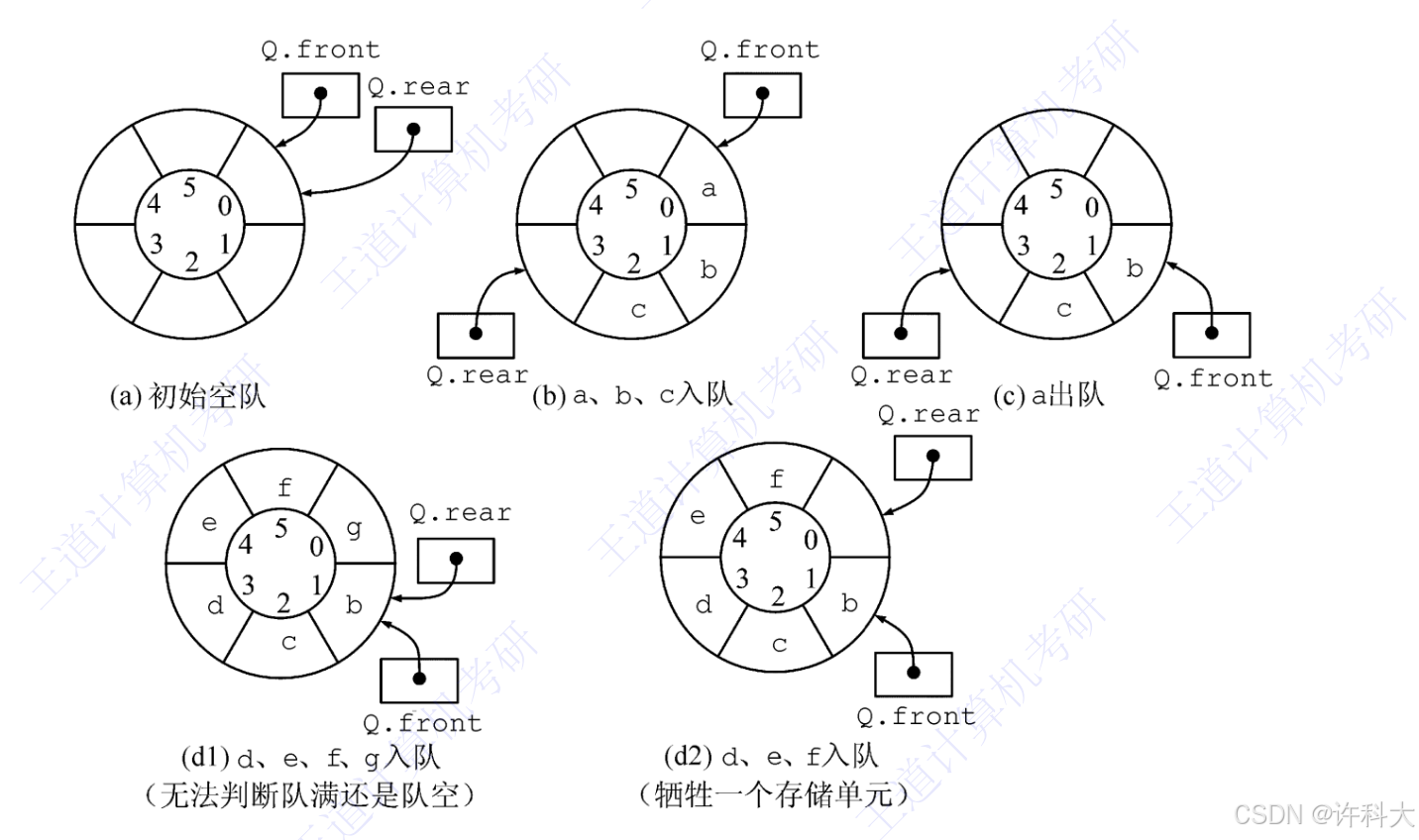
3 循环队列元素入队
bool EnQueue(SqQueue &Q,ElemType e){
if((Q.rear+1)%MaxSize==Q.front){ // 判断是否队满
return false;
}
Q.data[Q.rear] = e; // 放入元素
Q.rear = (Q.rear+1)%MazSize; // 改变队尾标记
return true;
}4 循环队列元素出队
bool DeQueue{SqQueue &Q,ElemType e){
if(Q.rear == Q.front){
return false;
}
x = Q.data[Q.front]; // 先进先出
Q.front = (Q.front + 1)%MaxSize;
return true;
}5 队列的链式存储
队列的链式表示称为链队列,实际上是一个同时带有队头指针和队尾指针的单链表。头指针指向队头结点,尾指针指向队尾结点,即单链表的最后一个结点。

https:www.cs.usfca.edu/~galles/visualization/QueueLL.heml
存储结构
typedef int ElemType;
typedef struct LinkNode{
ElemType data;
struct LinkNode *next;
typedef struct{
LinkNode *front,*rear; // 链表头、链表尾
}LinkQueue; //先进先出
LinkQueue Q;相对于原有编写的链表增加了尾指针
代码实战部分分为
1、初始化队列——依然带有头结点
2、入队
3、出队
4、判断队列是否为空
【13.5 题】
1、队列的特点是先进先出。
2、往往通过数组来实现循环队列,如果定义typedef struct{ElemType data[MaxSize]; int front,rear; // 队列头、队列尾}SqQueue;来实现循环队列,那么循环队列能放MaxSize-1个元素。
3、循环队列入队时需要判断队列是否满了,出队时需要判断队列是否为空。循环队列满了后,不能再入队元素。循环队列为空时,不能出队元素。
4、可以通过链表实现队列,操作是尾部插入、 头部删除。由于队列是先进先出,所以通过链表实现队列时,是尾部插入、头部删除。
【13.6 循环队列实战】
代码实战步骤依次是初始化循环队列,判断循环队列是否为空,入队、出队。
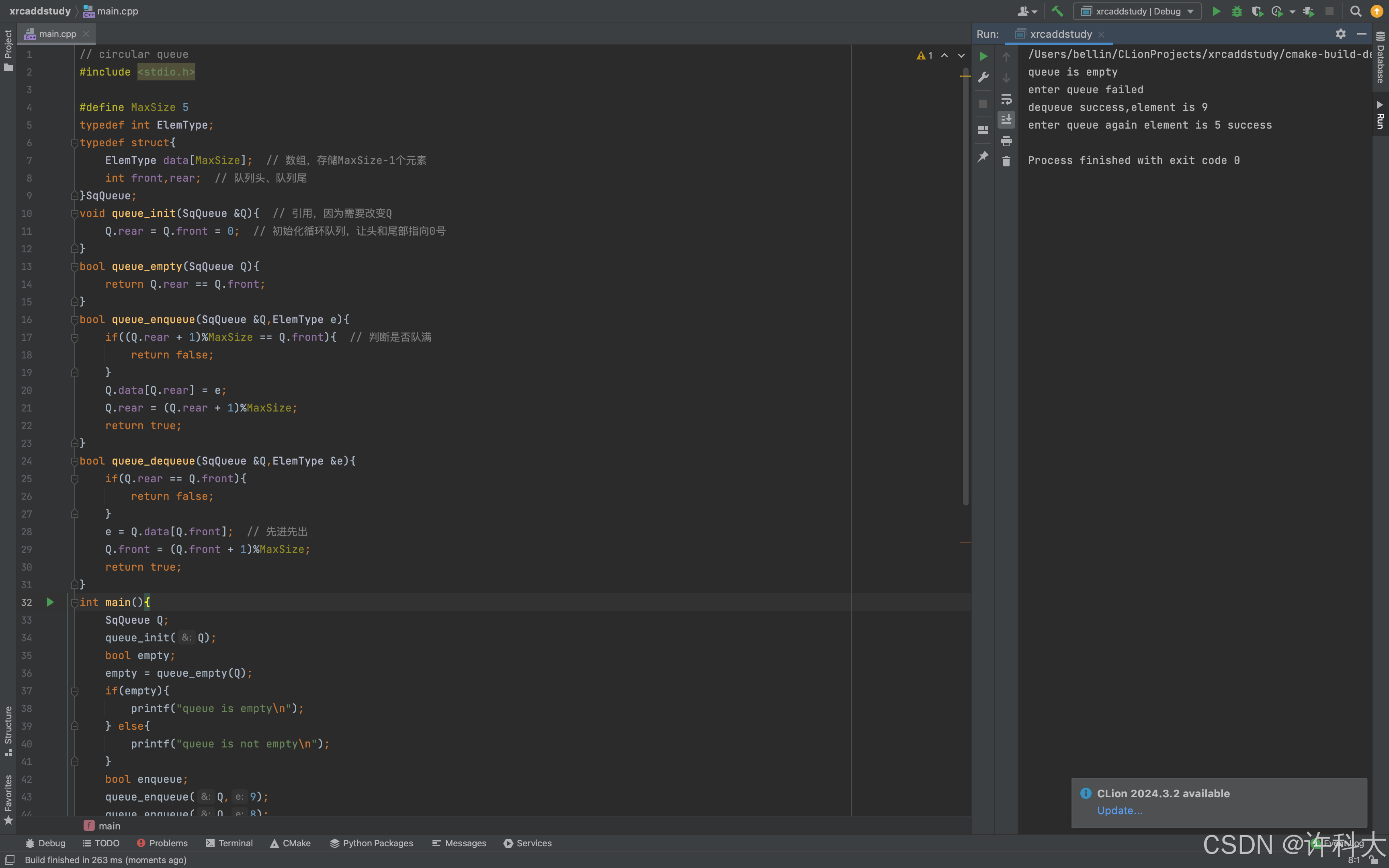
// circular queue
#include <stdio.h>
#define MaxSize 5
typedef int ElemType;
typedef struct{
ElemType data[MaxSize]; // 数组,存储MaxSize-1个元素
int front,rear; // 队列头、队列尾
}SqQueue;
void queue_init(SqQueue &Q){ // 引用,因为需要改变Q
Q.rear = Q.front = 0; // 初始化循环队列,让头和尾部指向0号
}
bool queue_empty(SqQueue Q){
return Q.rear == Q.front;
}
bool queue_enqueue(SqQueue &Q,ElemType e){
if((Q.rear + 1)%MaxSize == Q.front){ // 判断是否队满
return false;
}
Q.data[Q.rear] = e;
Q.rear = (Q.rear + 1)%MaxSize;
return true;
}
bool queue_dequeue(SqQueue &Q,ElemType &e){
if(Q.rear == Q.front){
return false;
}
e = Q.data[Q.front]; // 先进先出
Q.front = (Q.front + 1)%MaxSize;
return true;
}
int main(){
SqQueue Q;
queue_init(Q);
bool empty;
empty = queue_empty(Q);
if(empty){
printf("queue is empty\n");
} else{
printf("queue is not empty\n");
}
bool enqueue;
queue_enqueue(Q,9);
queue_enqueue(Q,8);
queue_enqueue(Q,7);
queue_enqueue(Q,6);
enqueue = queue_enqueue(Q,5);
if(enqueue){
printf("enter queue success\n");
} else{
printf("enter queue failed\n");
}
bool dequeue;
ElemType e;
dequeue = queue_dequeue(Q,e);
if(dequeue){
printf("dequeue success,element is %d\n",e);
} else{
printf("dequeue failed\n");
}
enqueue = queue_enqueue(Q,5);
if(enqueue){
printf("enter queue again element is 5 success\n");
} else{
printf("enter queue failed\n");
}
return 0;
}
【13.7 队列的实战(通过链表实现)】
代码实战步骤依次是初始化队列,入队、出队。
#include <stdlib.h>
#include <stdio.h>
// chain queue
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode* next;
}LNode;
typedef struct {
struct LNode *rear,*front; // 链表头、链表尾
}LinkQueue; // 先进先出
void init_queue(LinkQueue &Q){
Q.rear = Q.front = (LNode*)malloc(sizeof (LNode)); // 头和尾指向同一个结点
Q.front->next = NULL; // 头结点的next指针尾NULL
}
bool queue_empty(LinkQueue Q){
if(Q.rear == Q.front){
return true;
}
return false;
}
void enqueue(LinkQueue &Q,ElemType e){ // 入队,尾插法
LNode *n = (LNode*) malloc(sizeof (LNode));
n->data = e;
n->next = NULL;
Q.rear->next = n; // rear始终指向尾部
Q.rear = n;
}
bool dequeue(LinkQueue &Q,ElemType &e){ // 出队,头部删除法
if(Q.rear == Q.front){ // 队列为空
return false;
}
LNode *n;
n = Q.front->next; // 头结点什么都没有,所以头结点的下一个结点才有数据
e = n->data;
Q.front->next = n->next; // 断链
if(Q.rear == n){ // 删除的是最后一个结点
Q.rear = Q.front; // 队列置为空
}
free(n);
return true;
}
int main(){
LinkQueue Q;
init_queue(Q);
bool empty;
empty = queue_empty(Q);
if(empty){
printf("link queue is empty\n");
} else{
printf("link queue is not empty\n");
}
enqueue(Q,9);
enqueue(Q,8);
enqueue(Q,7);
bool del;
ElemType e;
del= dequeue(Q,e);
if(del){
printf("link queue delete success delete element is %d\n",e);
} else{
printf("link queue delete failed\n");
}
return 0;
}
【13.8 2019年42题真题解析】
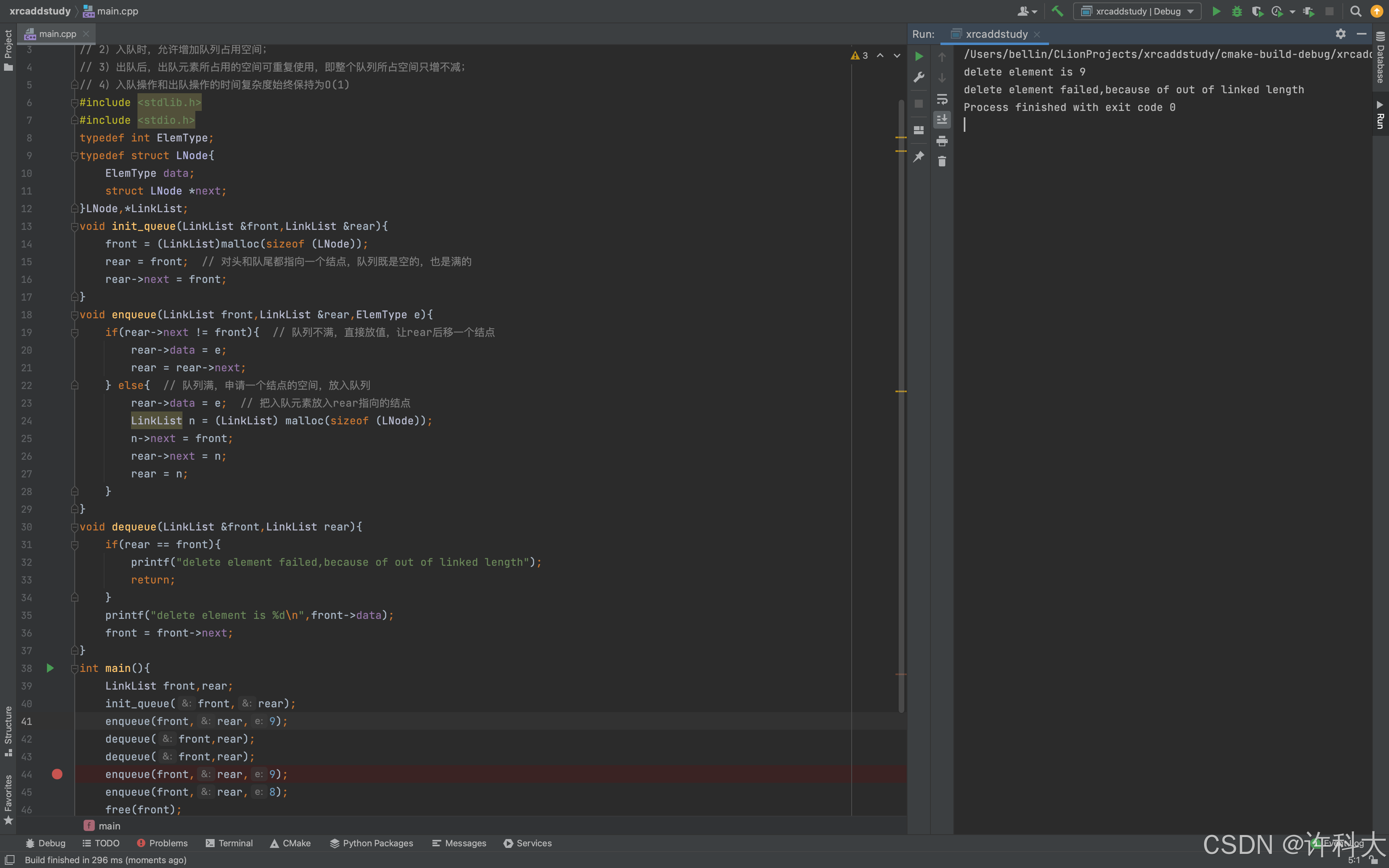
请设计一个队列,要求满足:1)初始时队列为空;2)入队时,允许增加队列占用空间;3)出队后,出队元素所占用的空间可重复使用,即整个队列所占空间只增不减;4)入队操作和出队操作的时间复杂度始终保持为O(1)。请回答下列问题:1)该队列时应选择链式存储结构,还是应选择顺序存储结构?2)画出队列的初始状态,并给出判断队空和队满的条件。3)画出第一个元素入队后的队列状态。4)给出入队操作和出队操作的基本过程。
答案解析:
1)采用链式存储结构(两段式单向循环链表),对头指针尾front,队尾指针为rear。
因为第二个要求入队时,允许增加队列占用空间,所以必须使用链式存储。
2)初始时,创建只有一个空闲结点的两段式单向循环链表,头指针front与尾指针rear均指向空闲结点。如下图所示。
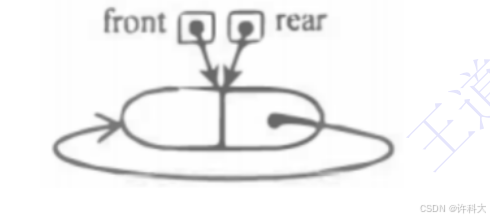
队空的判定条件:front==rear。
队满的判定条件:front==rear->next。
3)插入第一个元素后的队列状态。
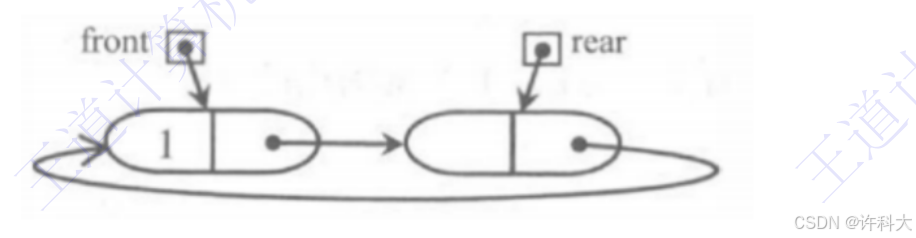
4)入队操作和出队操作的基本过程。

入队操作:
若(front==rear->next) // 队满 则在rear后面插入一个新的空闲结点;入队元素保存到rear所指结点中;rear=rear->next; 返回.
若(front==rear) // 队空 则出队失败,返回;取front所指结点中的元素e;front=front->next; 返回e。
// two stage unidirectional circular linked list
// 1)初始时队列为空;
// 2)入队时,允许增加队列占用空间;
// 3)出队后,出队元素所占用的空间可重复使用,即整个队列所占空间只增不减;
// 4)入队操作和出队操作的时间复杂度始终保持为O(1)
#include <stdlib.h>
#include <stdio.h>
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
void init_queue(LinkList &front,LinkList &rear){
front = (LinkList)malloc(sizeof (LNode));
rear = front; // 对头和队尾都指向一个结点,队列既是空的,也是满的
rear->next = front;
}
void enqueue(LinkList front,LinkList &rear,ElemType e){
if(rear->next != front){ // 队列不满,直接放值,让rear后移一个结点
rear->data = e;
rear = rear->next;
} else{ // 队列满,申请一个结点的空间,放入队列
rear->data = e; // 把入队元素放入rear指向的结点
LinkList n = (LinkList) malloc(sizeof (LNode));
n->next = front;
rear->next = n;
rear = n;
}
}
void dequeue(LinkList &front,LinkList rear){
if(rear == front){
printf("delete element failed,because of out of linked length");
return;
}
printf("delete element is %d\n",front->data);
front = front->next;
}
int main(){
LinkList front,rear;
init_queue(front,rear);
enqueue(front,rear,9);
dequeue(front,rear);
dequeue(front,rear);
enqueue(front,rear,9);
enqueue(front,rear,8);
free(front);
return 0;
}
【13 代码题】
新建一个栈,读取标准输入3个整数3 4 5,入栈3 4 5,依次出栈,打印 5 4 3。新建循环队列(Maxsize为5),读取标准输入3 4 5 6 7,入队7,队满,打印false,然后依次出队,输出 3 4 5 6。
// 新建一个栈,读取标准输入3个整数3 4 5,入栈3 4 5,依次出栈,打印 5 4 3。
// 新建循环队列(Maxsize为5),读取标准输入3 4 5 6 7,入队7,队满,打印false,然后依次出队,输出 3 4 5 6。
#include <stdio.h>
#define MaxSize 5
typedef int ElemType;
// stack
typedef struct{
ElemType data[MaxSize]; // 数组
int top;
}SqStack;
void stack_init(SqStack &s){ // 加引用
s.top = -1; // 代表栈空
}
bool push(SqStack &s,ElemType e){ // s变化,加引用
if(MaxSize - 1 == s.top){ // 数组的大小不能改变,避免访问越界
printf("stack full \n");
return false;
}
s.data[++s.top] = e;
return true;
}
bool pop(SqStack &s,ElemType &e){ // s变化,加引用
if(-1 == s.top){
printf("false\n");
return false;
}
e = s.data[s.top--];
return true;
}
// circular queue
typedef struct{
ElemType data[MaxSize]; // 数组存储MaxSize-1个元素,存满则无法判断是满还是空
int front,rear; // 队列头、队列尾
}SqQueue;
void queue_init(SqQueue &q){
q.front = q.rear = 0;
}
bool in_queue(SqQueue &q,ElemType e){
if((q.rear + 1)%MaxSize == (q.front)%MaxSize){ // 判断是否队满
printf("false\n");
return false;
}
q.data[q.rear] = e;
q.rear = (q.rear+1)%MaxSize;
return true;
}
bool de_queue(SqQueue &q,ElemType &e){
if(q.rear == q.front){
return false;
}
e = q.data[q.front]; // 先进先出
q.front++;
return true;
}
int main(){
SqStack s;
stack_init(s);
ElemType e;
for(int i = 0;i < 3;i++){
scanf("%d",&e);
push(s,e);
}
while(s.top != -1){
pop(s,e);
printf("%2d",e);
}
printf("\n");
SqQueue q;
queue_init(q);
scanf("%d",&e);
while(in_queue(q,e)){
scanf("%d",&e);
}
while (de_queue(q,e)){
printf("%2d",e);
}
printf("\n");
return 0;
}
【第14节 二叉树的建树和遍历】
【14.2 与408关联】
1 与408关联
1、二叉树的带权路径长度(WPL)是二叉树中所有叶结点的带权路径长度之和,给定一颗二叉树T,采用二叉树链表存储,结点结构如下:其中叶结点的weight域保存该结点的非负值,设root为指向T的根结点的指针,请设计求T的WPL的算法,要求:1)给出算法的基本设计思想。2)使用C或C++语言,给出二叉树结点的数据类型定义。3)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。

2、请设计一个算法,将给定的表达式树(二叉树)转换为等价的中缀表达式(通过括号反应操作服的计算次序)并输出。例如,当下列两棵表达式树作为算法的输入时,输出的等价中缀表达式分别为(a+b)*(c*(-d))和(a*b)+(-(c-d)).
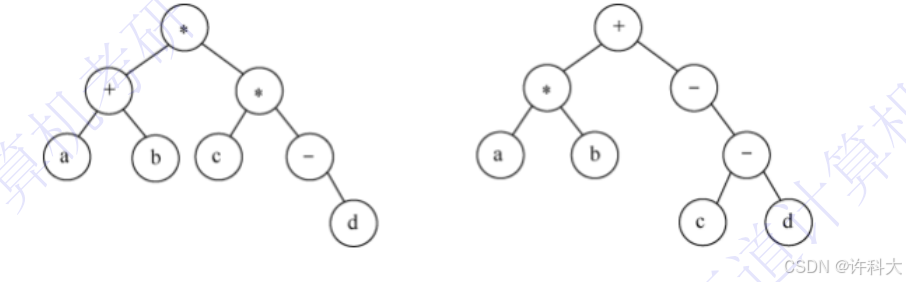
二叉树结点定义如下:
typedef struct node{
char data[10]; // 存储操作数或操作符
struct node *left,*right;
}BTree;要求:1)给出算法的基本设计思想;2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。
2 本大节课分为14.3小节到14.7小节,包含二叉树的原理解析,建树实战,遍历实战,二叉树真题实战
14.3小节是树与二叉树原理解析
14.4小节是二叉树层次建树实战
14.5小节是二叉树的前序中序后续遍历实战
14.6小节是二叉树的层序遍历实战
14.7小节是2014年41题真题解析及实战
【14.3 树与二叉树原理解析】
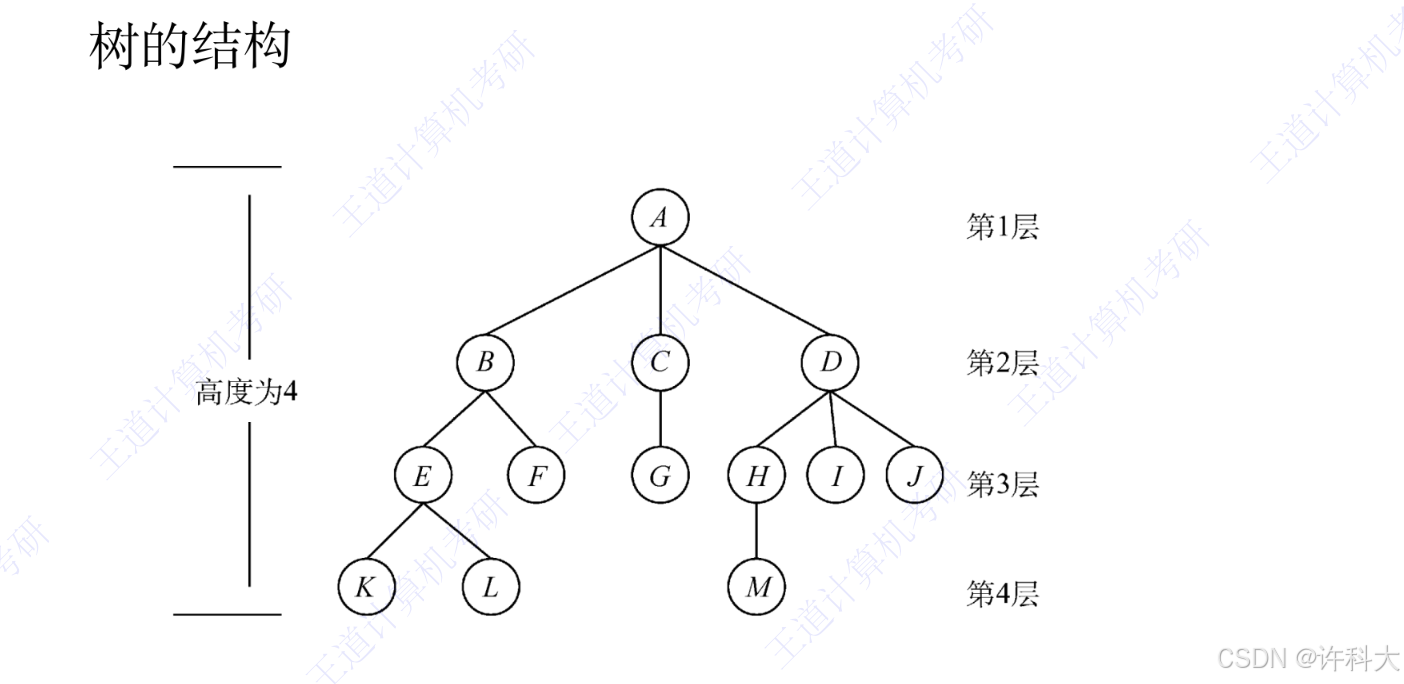
1 树Tree
树是n(n>=0)个节点的有限集。当n=0时,称为空树。在任意一棵非空树中应满足:1)有且仅有一个特定的称为根的结点。2)当n>1时,其余节点课分为m(m>0)个互不相交的有限集T1,T2,。。。,Tm,其中每个集合本身又是一棵树,并且称为根的子树。
树作为一种逻辑结构,同时也是一种分层结构,具有以下两个特点:1)树的根结点没有前驱,除根结点外的所有结点有且只有一个前驱。2)树中所有结点可以有零个或多个后继。
2 二叉树
二叉树是另一种树形结构,其特点是每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。
与树相似,二叉树也以递归的形式定义。二叉树是n(n>=0)个结点的有限集合:1)或者为空二叉树,即n=0。2)或者由一个根结点和两个互不相交的被称为根的左子树和右子树组成。左子树和右子树又分别是一棵二叉树。
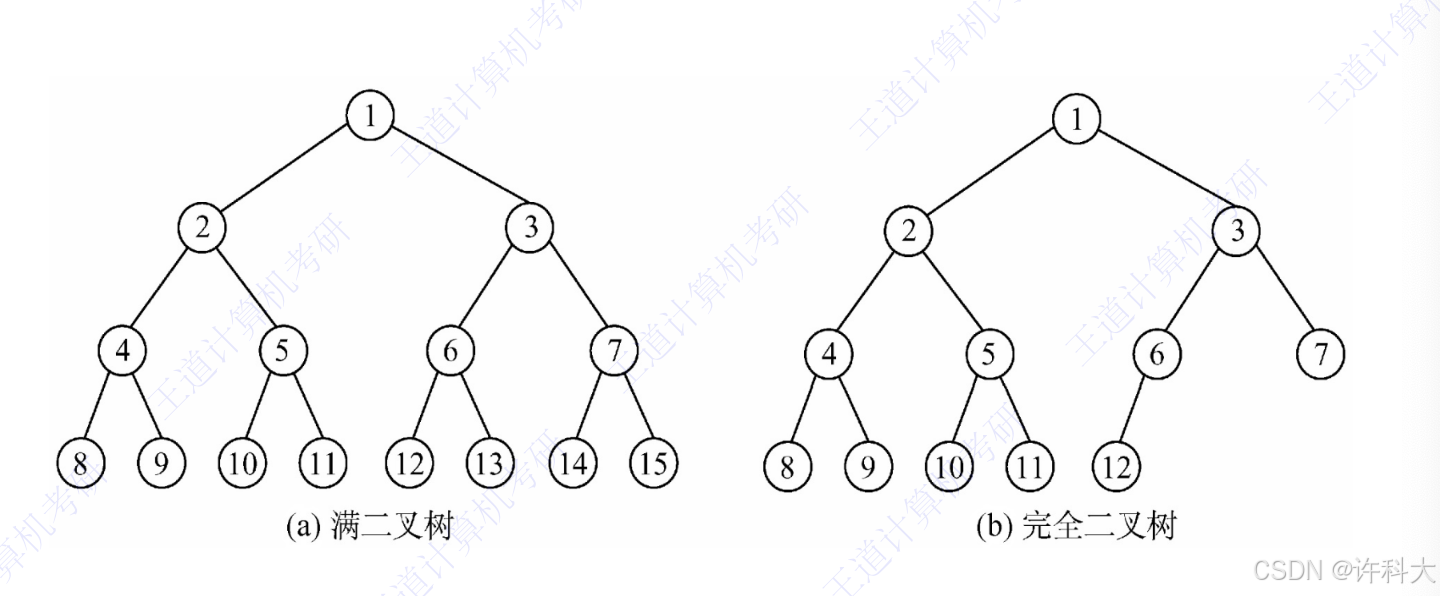
完美二叉树(perfect binary tree)
一个深度为k(>=-1)且有2^(k+1)-1个结点的二叉树称为完美二叉树。(注:国内的数据结构教材大多翻译为“满二叉树”)
完全二叉树(complete binary tree)
完全二叉树丛根结点到倒数第二层满足完美二叉树,最后一层可以不完全填充,其叶子结点都靠左对齐。
完满二叉树(full binary tree)
所有非叶子结点的度都是2。(只要有孩子,就必然是有2个孩子。)
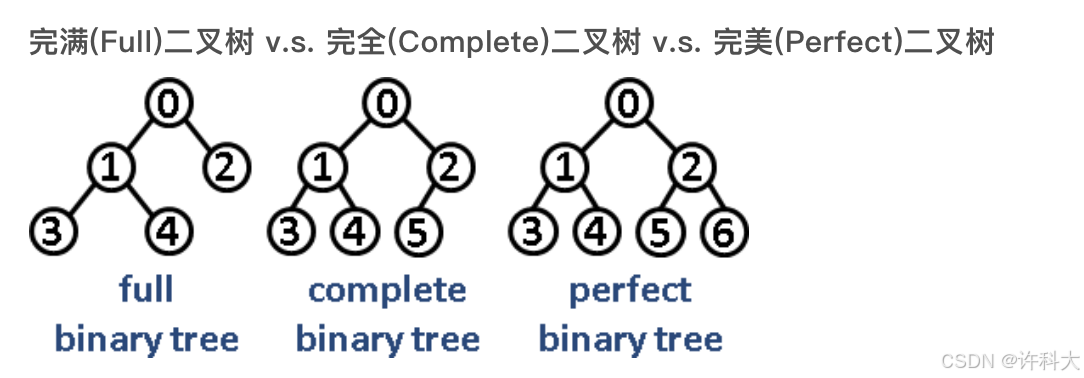
完满二叉树:除了叶子结点之外的每个结点都有两个孩子,每一层(包含最后一层)都被完全填充。
完美二叉树:除了叶子结点之外的每一个结点都有两个孩子结点。
完全二叉树:除了最后一层之外的其他每一层都被完全填充,并且所有结点都保持向左对齐。
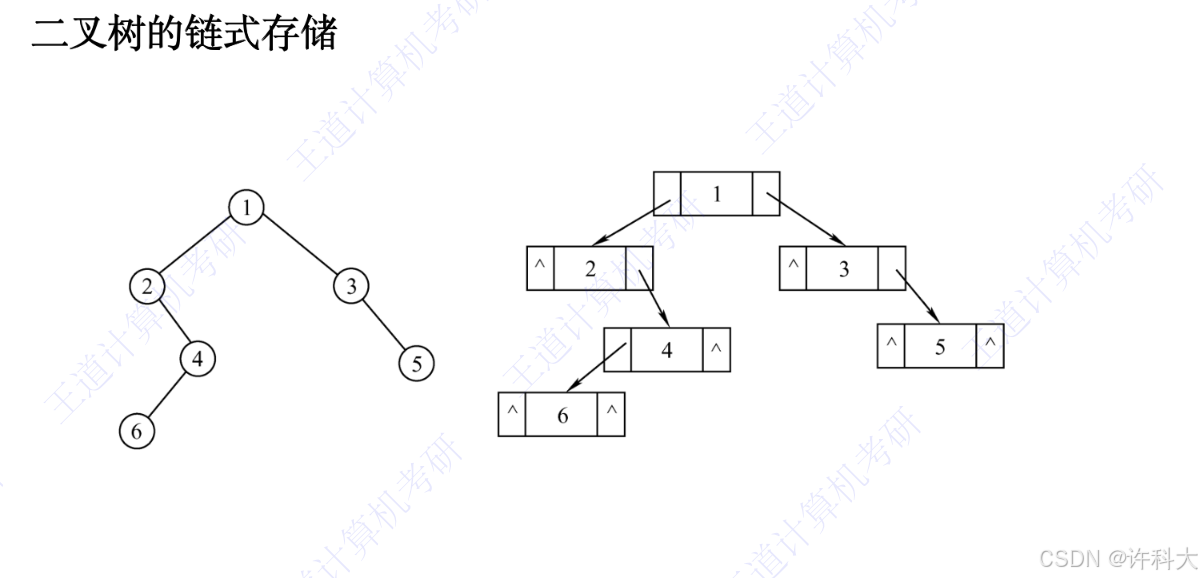
树结点数据结构
typedef char BiElemType;
typedef struct BiTNode{
BiElemType c; // c就是书上的data
struct BiTNode *lchild;
struct TiTNode *rchild;
}BiTNode,*BiTree;树中任何一个结点都是一个结构体,它的空间是通过malloc申请出来
先画图,后实战代码。勤动手。
依次是层次建树,先序遍历,中序遍历,后续遍历,层序遍历。
【14.3 题】
1、树有两个特点:1)树的根结点没有前驱,除根结点外的所有结点有且只有一个前驱,2)树中所有结点可以有零个或多个后继。
2、二叉树是n(n>=0)个结点的有限集合。1)或为空二叉树,即n=0。2)或有一个根结点和两个互不相交的被称为根的左子树和右子树组成,左子树和右子树又分别是一棵二叉树。
3、树结点的数据结构如下typedef struct BiTNode{BiElementType c; // c是存储数据 struct BiTNode *lchild; struct BiTNode *rchild;}BiTNode,*BiTree; lchild是指向左孩子,rchild是指向右孩子。
【14.4 二叉树层次建树实战】
把结构体类型的声明放入function.h头文件,function.h头文件在main.cpp进行了include。
//
// Created by bellin on 2025/2/12.
//
#ifndef XRCADDSTUDY_FUNCTION_H
#define XRCADDSTUDY_FUNCTION_H
#include <stdio.h>
#include <stdlib.h>
typedef char BiElemType;
typedef struct BiTNode{
BiElemType c; // c是书上的data
struct BiTNode *lchild;
struct BiTNode *rchild;
}BiTNode,*BiTree;
// tag结构体是辅助队列使用的
typedef struct tag{
BiTree p; // 树的某一个结点的地址值
struct tag *pnext;
}tag_t,*ptag_t;
#endif //XRCADDSTUDY_FUNCTION_H
// tree
#include "function.h"
int main(){
BiTree tree=NULL; // 用来指向树根,代表树
BiTree pnew; // 用来指向新申请的树结点
char c;
ptag_t phead=NULL,ptail=NULL,listpnew=NULL,pcur=NULL;
while(scanf("%c",&c)){
if('\n'== c){
break;
}
// calloc申请空间并对空间进行初始化,赋值为0
pnew = (BiTree) calloc(1,sizeof (BiTNode));
pnew->c = c; // 数据放进去
listpnew = (ptag_t) calloc(1,sizeof (tag_t)); // 给队列结点申请空间
listpnew->p = pnew;
if(NULL != tree){
// 让元素先入队列
ptail->pnext = listpnew; // 新结点放入链表,通过尾插法
ptail = listpnew; // 指向队列尾部
// 把结点放入树中
if(NULL == pcur->p->lchild){ // 新结点放入树
pcur->p->lchild = pnew; // 新结点放到要插入结点的左边
} else if(NULL == pcur->p->rchild){
pcur->p->rchild = pnew; // 新结点放到要插入结点的右边
pcur = pcur->pnext; // 要插入的结点的左右都放了,pcur指向队列的下一个
}
} else{
tree = pnew; // 树的根
phead = listpnew; // 队列头
ptail = listpnew; // 队列尾
pcur = listpnew;
}
}
return 0;
}
【14.4 题】
1、二叉树层次建树需要使用辅助队列。
2、使用辅助队列进行二叉树层次建树时,队列中的结点值放置的是树中某结点的地址值。辅助队列存储树中某结点的地址,这样最高效,最节省空间。
3、calloc初始也可以使用,calloc申请空间大小是其传入的两个参数相乘,calloc申请空间和malloc的区别在于,申请空间后,会对申请的空间内容,全部初始化为0.
【14.5 二叉树的前序中序后序遍历实战】
前序遍历是先打印自身,再打印左子树,再打印右子树。深度优先遍历。
中序遍历是先打印左子树,再打印当前结点,再打印右子树。
后序遍历是先打印左子树,再打印右子树,再打印当前结点。
// tree
#include "function.h"
void pre_order(BiTree t){
if(NULL != t){
printf("%c",t->e);
pre_order(t->lchild);
pre_order(t->rchild);
}
}
void in_order(BiTree t){
if(NULL != t){
in_order(t->lchild);
printf("%c",t->e);
in_order(t->rchild);
}
}
void post_order(BiTree t){
if(NULL != t){
post_order(t->lchild);
post_order(t->rchild);
printf("%c",t->e);
}
}
int main(){
BiTree tree = NULL; // 树根
BiTree tnew; // 新的树结点
LinkList front = NULL,tail = NULL,cur = NULL,lnew = NULL;
char c;
while(scanf("%c",&c)){
if('\n' == c){
break;
}
tnew = (BiTree) calloc(1,sizeof (BiTNode));
tnew->e = c;
lnew = (LinkList) calloc(1,sizeof (LNode));
lnew->p = tnew;
if(NULL != tree){
tail->pnext = lnew;
tail = lnew;
if(NULL == cur->p->lchild){
cur->p->lchild = tnew;
} else if (NULL == cur->p->rchild){
cur->p->rchild = tnew;
cur = cur->pnext;
}
} else{
tree = tnew;
front = tail = cur = lnew;
}
}
pre_order(tree);
printf("\n");
in_order(tree);
printf("\n");
post_order(tree);
printf("\n");
free(tree);
free(front);
return 0;
}
【14.6 二叉树的层序遍历】
层次遍历需要使用辅助队列。
【14.6 题】
1、二叉树前序遍历是先打印当前结点,再打印左子树,再打印右子树,前序遍历就是深度优先遍历。
2、层序遍历需要使用辅助队列来实现,步骤是树根入队,然后循环,队列不为空,循环就不断进行,循环内,先出队元素(假设元素为p)并打印,然后判断p是否有左孩子,再判断是否有右孩子,顺序不能颠倒,因为层序遍历是从左往右。
【14.7 2014年41题真题】
1、二叉树的带权路径长度(WPL)是二叉树中所有叶结点的带权路径长度之和,给定一颗二叉树T,采用二叉树链表存储,结点结构如下:其中叶结点的weight域保存该结点的非负值,设root为指向T的根结点的指针,请设计求T的WPL的算法,要求:1)给出算法的基本设计思想。2)使用C或C++语言,给出二叉树结点的数据类型定义。3)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。
function.h
//
// Created by bellin on 2025/2/12.
//
#ifndef XRCADDSTUDY_FUNCTION_H
#define XRCADDSTUDY_FUNCTION_H
#include <stdio.h>
#include <stdlib.h>
typedef char ElemType;
typedef struct BiTNode{
ElemType e;
struct BiTNode* lchild;
struct BiTNode* rchild;
}BiTNode,*BiTree;
typedef struct LNode{
BiTree p;
struct LNode* pnext;
}LNode,*LinkList;
typedef BiTree BiTreeElemType;
typedef struct LinkNode{
BiTreeElemType data;
LinkNode *next;
}LinkNode;
typedef struct {
LinkNode *front,*rear;
}LinkQueue;
void init_queue(LinkQueue &q);
bool is_empty(LinkQueue q);
void en_queue(LinkQueue &q,BiTreeElemType e);
bool de_queue(LinkQueue &q,BiTreeElemType &e);
#endif //XRCADDSTUDY_FUNCTION_H
queue.cpp
//
// Created by bellin on 2025/2/15.
//
#include "function.h"
void init_queue(LinkQueue &q){
q.front = q.rear = (LinkNode*) malloc(sizeof (LinkNode));
q.front->next = NULL;
}
bool is_empty(LinkQueue q){
return q.front == q.rear;
}
void en_queue(LinkQueue &q,BiTreeElemType e){
LinkNode *new_linknode = (LinkNode*) malloc(sizeof (LinkNode));
new_linknode->data = e;
new_linknode->next = NULL;
q.rear->next = new_linknode;
q.rear = new_linknode;
}
bool de_queue(LinkQueue &q,BiTreeElemType &e){
if(q.front != q.rear){
LinkNode *del = q.front->next;
e = del->data;
q.front->next = del->next;
if(del == q.rear){
q.front = q.rear;
}
free(del);
} else{
return false;
}
return true;
}main.cpp
// tree
#include "function.h"
void pre_order(BiTree t){
if(NULL != t){
printf("%c",t->e);
pre_order(t->lchild);
pre_order(t->rchild);
}
}
void in_order(BiTree t){
if(NULL != t){
in_order(t->lchild);
printf("%c",t->e);
in_order(t->rchild);
}
}
void post_order(BiTree t){
if(NULL != t){
post_order(t->lchild);
post_order(t->rchild);
printf("%c",t->e);
}
}
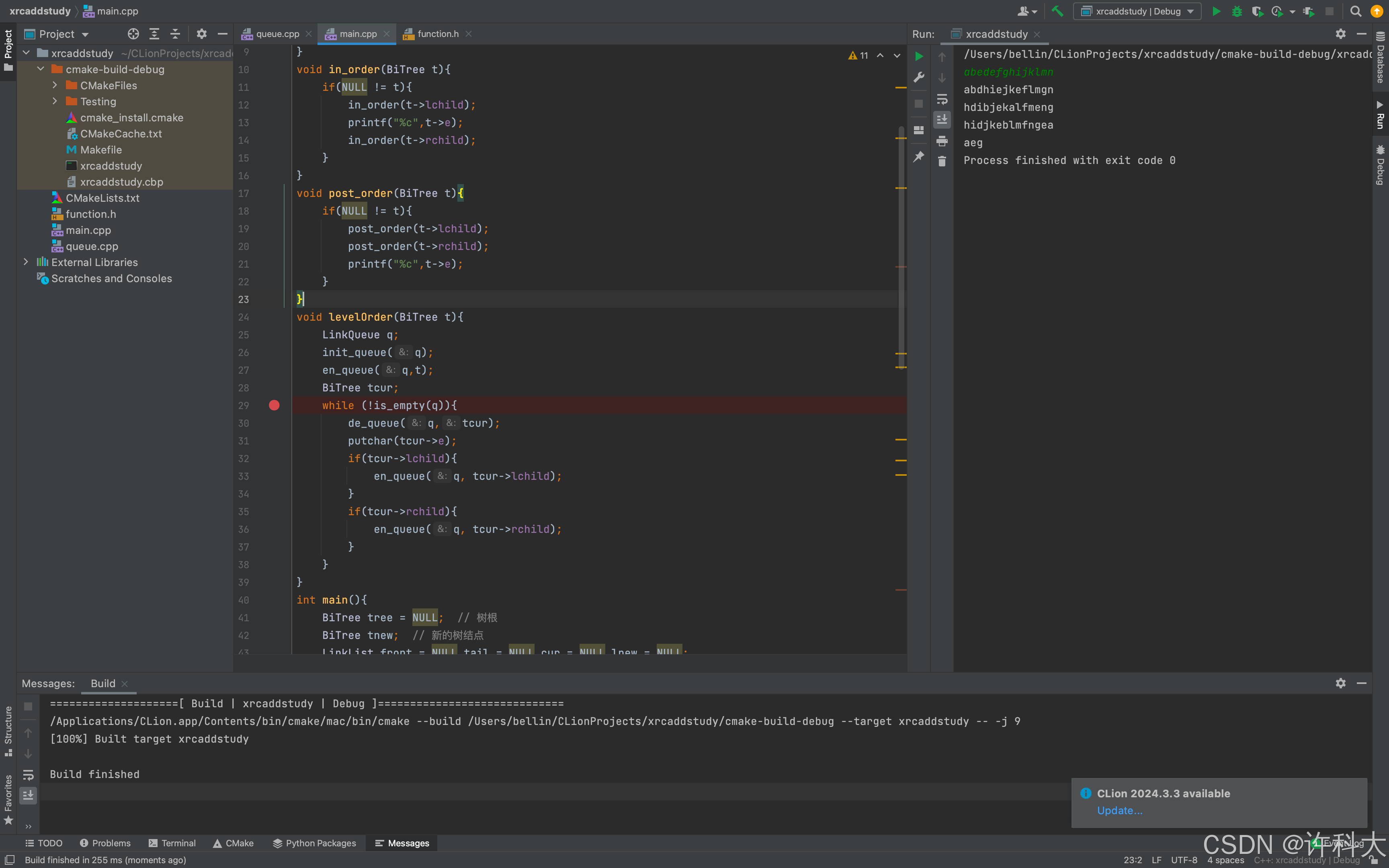
void levelOrder(BiTree t){
LinkQueue q;
init_queue(q);
en_queue(q,t);
BiTree tcur;
while (!is_empty(q)){
de_queue(q,tcur);
putchar(tcur->e);
if(tcur->lchild){
en_queue(q, tcur->lchild);
}
if(tcur->rchild){
en_queue(q, tcur->rchild);
}
}
}
int main(){
BiTree tree = NULL; // 树根
BiTree tnew; // 新的树结点
LinkList front = NULL,tail = NULL,cur = NULL,lnew = NULL;
char c;
while(scanf("%c",&c)){
if('\n' == c){
break;
}
tnew = (BiTree) calloc(1,sizeof (BiTNode));
tnew->e = c;
lnew = (LinkList) calloc(1,sizeof (LNode));
lnew->p = tnew;
if(NULL != tree){
tail->pnext = lnew;
tail = lnew;
if(NULL == cur->p->lchild){
cur->p->lchild = tnew;
} else if (NULL == cur->p->rchild){
cur->p->rchild = tnew;
cur = cur->pnext;
}
} else{
tree = tnew;
front = tail = cur = lnew;
}
}
pre_order(tree);
printf("\n");
in_order(tree);
printf("\n");
post_order(tree);
printf("\n");
levelOrder(tree);
free(tree);
free(front);
return 0;
}
【第15节 考研必会的查找算法】
【15.2 与408关联】
1 与408关联解析
2009年
42.(15分)已知一个带有表头结点的单链表,结点结构为

假设该链表只给出了头指针list,在不改变链表的前提下,请设计一个尽可能高效的算法,查找链表中倒数第k个位置上的结点(k为正整数),若查找成功,算法输出该结点的data域的值,并返回1;否则,只返回0.要求:1)描述算法的基本设计思想。2)描述算法的详细实现步骤。3)根据设计思想和实现步骤,采用程序设计语言描述算法(使用C、C++或Java语言实现),关键之处给出简要注释。
2011年
42.(15分)一个长度为L(L>=1)的升序序列S,处在第「L/2」个位置的数称为S的中位数。例如,若序列S1={11,13,15,17,19},则S1的中位数是15,两个序列的中位数是含它们所有元素的升序序列的中位数。例如,若S2={2,4,6,8,20},则S1和S2的中位数是11,现在有两个等长升序序列A和B,试设计一个在时间和空间两方面都尽可能高效的算法,找出两个序列A和B的中位数。要求:1)给出算法的基本设计思想。2)根据设计思想,采用C、C++或java语言描述算法,关键之处给出注释。3)说明你所设计算法的时间复杂度和空间复杂度。
2 本节内容介绍
本大节课分为15.3小节到15.7小节,包含顺序查找、折半查找,二叉树排列树,真题实战。
15.3小节是顺序查找原理及实战
15.4小节是折半查找原理及实战
15.5小节是二叉排列树原理及建树实战
15.6小节是二叉树删除实战
15.7小节是2011年42题真题讲解
【15.3 顺序查找原理及实战】
1 顺序查找原理解析
顺序查找又称线性查找。对于顺序表和链表都是适用的。对于顺序表,可以通过数组下标递增来顺序扫描每个元素;对于链表,则通过指针next来一次扫描每个元素。
2 顺序查找代码实战
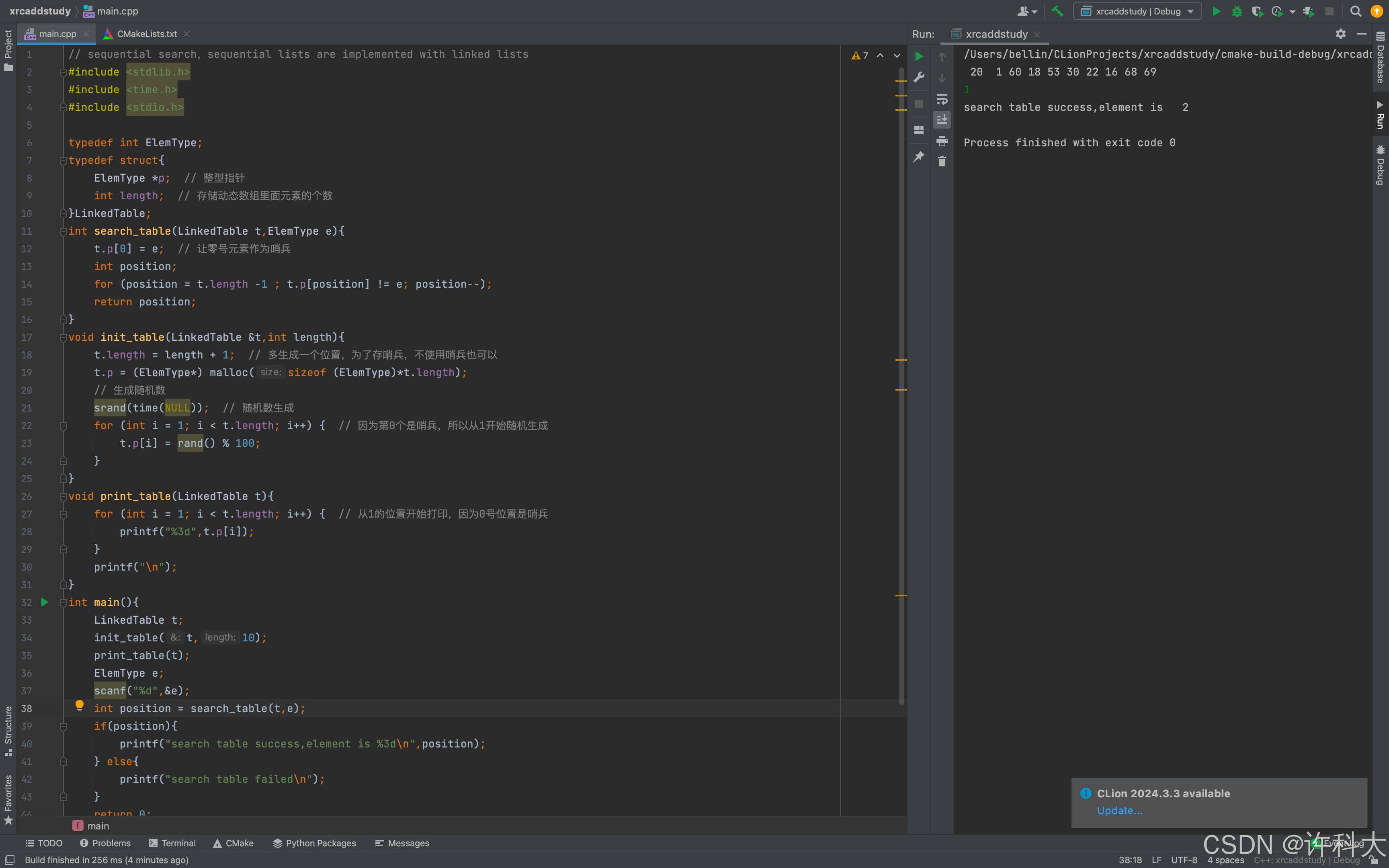
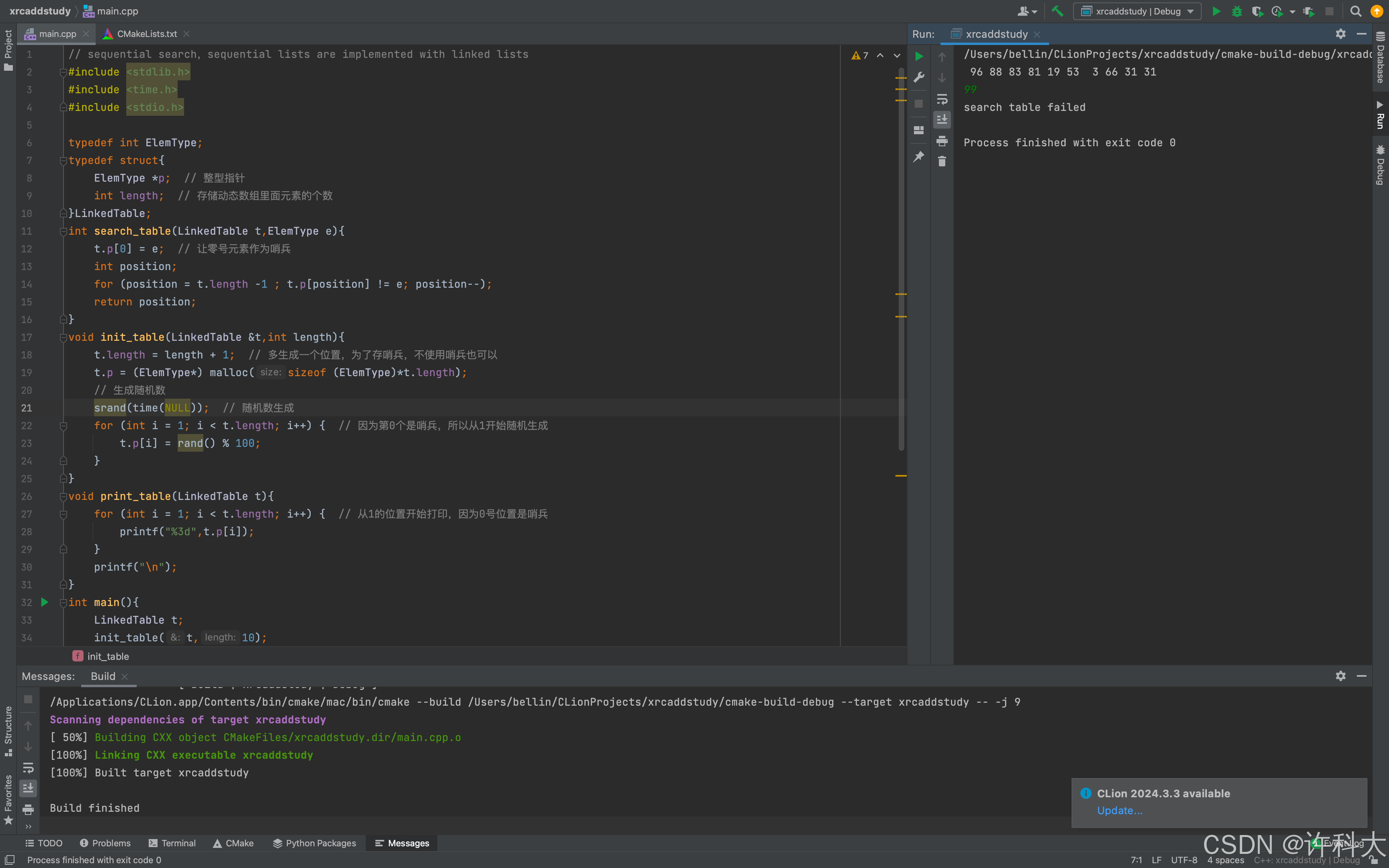
使用指针实现,申请一个堆空间,使用方式和数组一致。
// sequential search,sequential lists are implemented with linked lists
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
typedef int ElemType;
typedef struct{
ElemType *p; // 整型指针
int length; // 存储动态数组里面元素的个数
}LinkedTable;
int search_table(LinkedTable t,ElemType e){
t.p[0] = e; // 让零号元素作为哨兵
int position;
for (position = t.length -1 ; t.p[position] != e; position--);
return position;
}
void init_table(LinkedTable &t,int length){
t.length = length + 1; // 多生成一个位置,为了存哨兵,不使用哨兵也可以
t.p = (ElemType*) malloc(sizeof (ElemType)*t.length);
// 生成随机数
srand(time(NULL)); // 随机数生成
for (int i = 1; i < t.length; i++) { // 因为第0个是哨兵,所以从1开始随机生成
t.p[i] = rand() % 100;
}
}
void print_table(LinkedTable t){
for (int i = 1; i < t.length; i++) { // 从1的位置开始打印,因为0号位置是哨兵
printf("%3d",t.p[i]);
}
printf("\n");
}
int main(){
LinkedTable t;
init_table(t,10);
print_table(t);
ElemType e;
scanf("%d",&e);
int position = search_table(t,e);
if(position){
printf("search table success,element is %3d\n",position);
} else{
printf("search table failed\n");
}
return 0;
}
【15.3 题】
1、顺序查找又称线性查找,对于顺序表和链表都是适用的,对于顺序表,可通过数组下标递增来顺序扫描每个元素;对于链表,则通过指针next来依次扫描每个元素。
2、顺序表查找不一定非要使用哨兵,不使用也可以的,哨兵可以帮助减少代码的编写量。
3、顺序查找时间复杂度是O(n)。顺序查找是查找某个元素值,依次遍历整个顺序表,或者链表来实现。
【15.4 折半查找原理解析及实战】
1 折半查找原理解析
折半查找又称二分查找,仅适用于有序的顺序表。
折半查找的基本思想:首先将给定值key与其表中中间位置的元素比较,若相等,则查找成功,返回元素的存储位置;若不等,则所需查找的元素只能在中间元素以外的前半部分或后半部分(例如,在查找表升序排列时,若给定值key大于中间元素,则所查找的元素只可能在后半部分)。然后在缩小的范围内继续进行同样的查找,如此重复,直到找到为止,或确定表中没有所需要查找的元素,则查找不成功,返回查找失败的信息。
针对顺序表有序,使用qsort来排序,具体排序算法16节课进行讲解,qsort的使用方法如下:
#include <stdio.h>
void qsort(void *buf,size_t num,size_t size,int (*compare)(const void*,const void*));buf:要排序数组的起始地址,也可以是指针,申请了一块连续的堆空间
num:数组中元素的个数
size:数组中每个元素所占用的空间大小
compare:比较规则,需要传递一个函数名,这个函数由我们自己编写,返回值必须是int类型,形参是两个void类型指针,这个函数自己编写,但是是qsort内部调用的,相当于传递一种行为给qsort。
https://www.cs.usfca.edu/~galles/visualization/Search.html
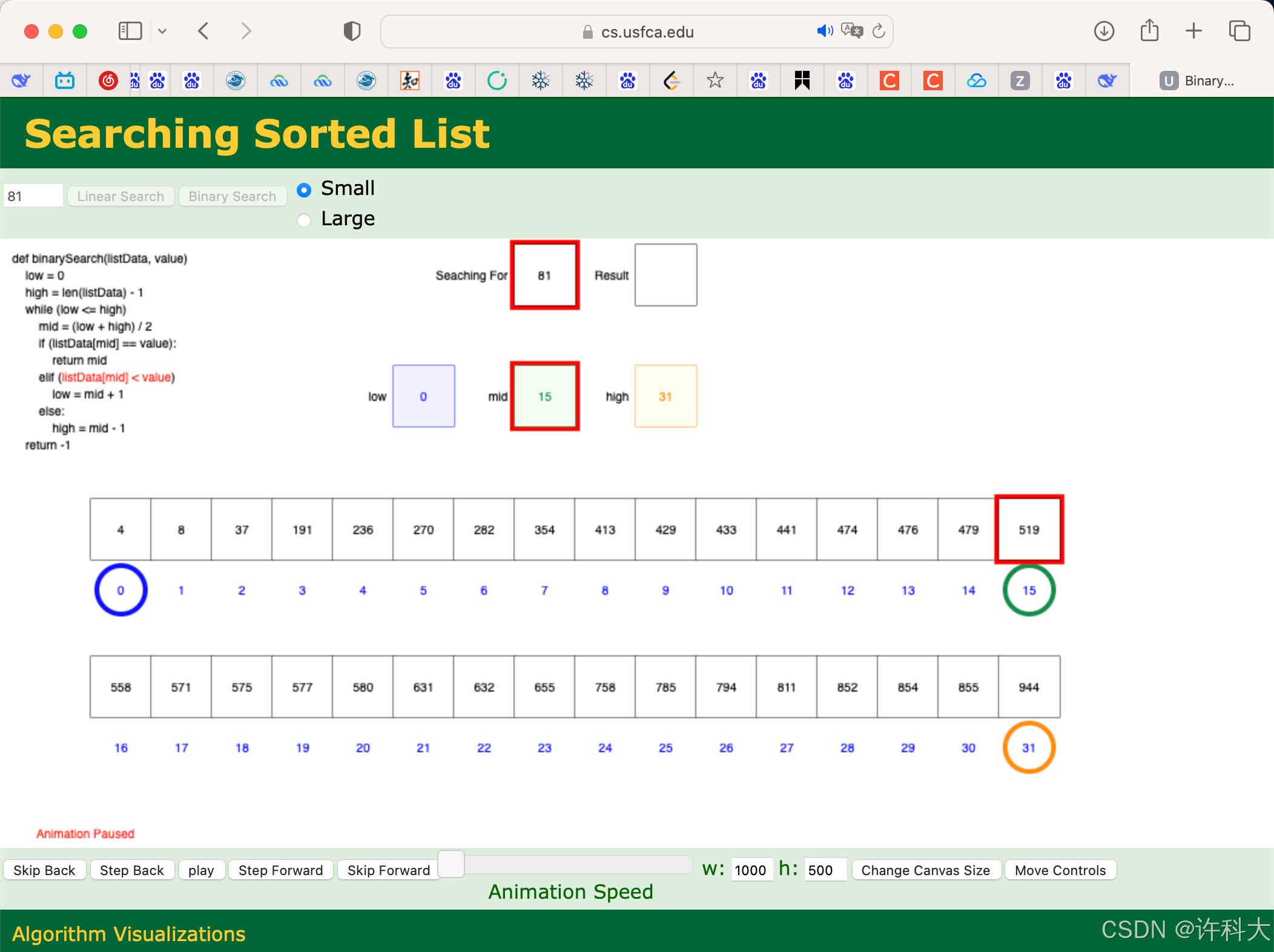
2 折半查找代码实战
折半查找不需要用到哨兵。代码实战流程是:
1)初始化顺序表,随机10个元素
2)使用qsort进行排序,排序完毕后,打印
3)输入要查找的元素值,存入变量key中
4)通过二分查找对应key值,找到则输出在顺序表中的位置,没找到输出未找到。
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
// binary search
typedef int ElemType;
typedef struct {
ElemType *e; // 整型指针
int length; // 存储动态数里面元素的个数
}LinkedTable;
int binary_search(LinkedTable t,ElemType elem){ // 时间复杂度logn
int low=0,high = t.length-1,mid;
while (low<=high){
mid = (low + high)/2;
if(elem < t.e[mid]){
high = mid - 1;
} else if(elem > t.e[mid]){
low = mid + 1;
} else {
return mid; // 等于就是找到了
}
}
return -1;
}
int compare(const void* left,const void* right){ // left、right是任意两个元素的地址值
return *(ElemType*)left - *(ElemType*)right; // 从小到大
}
void init_table(LinkedTable &t,int length){ // 进行了随机数生成,折半查找没有使用哨兵
t.length = length;
t.e = (ElemType*) malloc(sizeof (ElemType) * length);
srand(time(NULL)); // 随机数生成
for (int i = 0; i < t.length; i++) {
t.e[i] = rand()%100;
}
}
void print_table(LinkedTable t){
for (int i = 0; i < t.length; ++i) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
LinkedTable t;
init_table(t,10);
print_table(t);
qsort(t.e,t.length,sizeof (ElemType),compare); // qsort实现的是快排
print_table(t);
int elem;
scanf("%d",&elem);
int position = binary_search(t,elem); // 有序数组,二分查找,折半查找
if(-1!=position){
printf("search success,position is %d\n",position);
} else{
printf("search failed\n");
}
return 0;
}
【15.4 题】
1、折半查找又称二分查找,仅适用于有序的顺序表,不适用于链表。
2、void qsort(void *buf,size_t num,size_t size,int(*compare)(const void*,const void*));buf是要排序数组的起始地址,也可以是指针,申请了一块连续的堆空间。num是数组中元素的个数。size是数组中每个元素所占用的空间大小。compare是比较规则,需要传递一个函数名,compare函数需要自己编写。qsort不可以用来排序链表。qsort只能用来排序数组
3、whil(low<=high).
【15.5 二叉排序树原理及建树实战】
1 二叉排序树原理解析
二叉排序树(也称二叉查找树)或者是一棵空树,或者是具有下列特性的二叉树:1)若左子树非空,则左子树上所有结点的值均小于根结点的值。2)若右子树非空,则右子树上所有结点的值均大于根结点的值。3)左、右子树也分别是一棵二叉排序树。
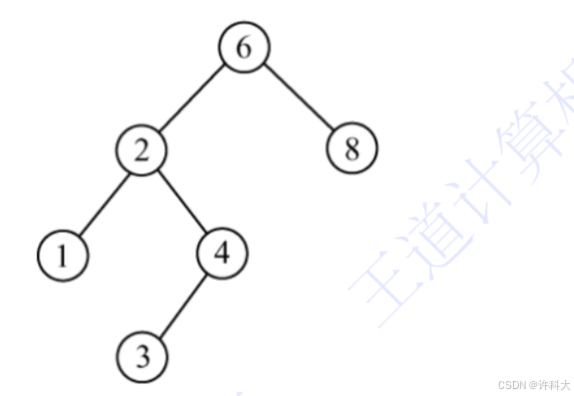
通过网址来演示二叉排序树动画效果。
https://www.cs.usfca.edu/~galles/visualization/BST.html
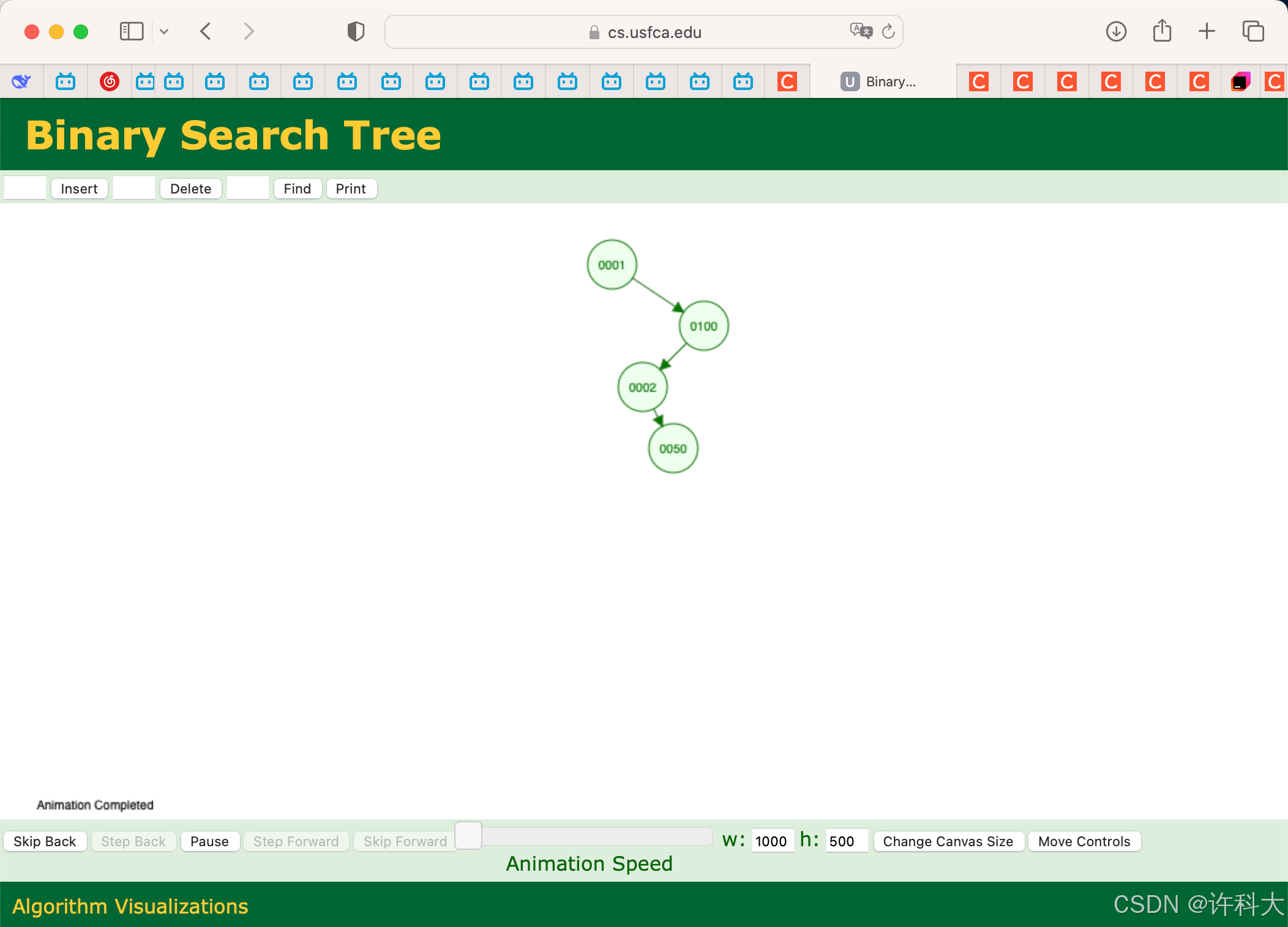
2 二叉排序树代码实战
代码实战步骤:先新建一棵二叉排序树,使用的是非递归的方法新建,然后针对建好的二叉排序树进行中序遍历输出,接着对二叉排序树进行查找。二叉排序树的最大查找次数是树的高度。
如果是根结点,返回的父结点可以处理一下。通常元素的值可能是非零或非负整数。
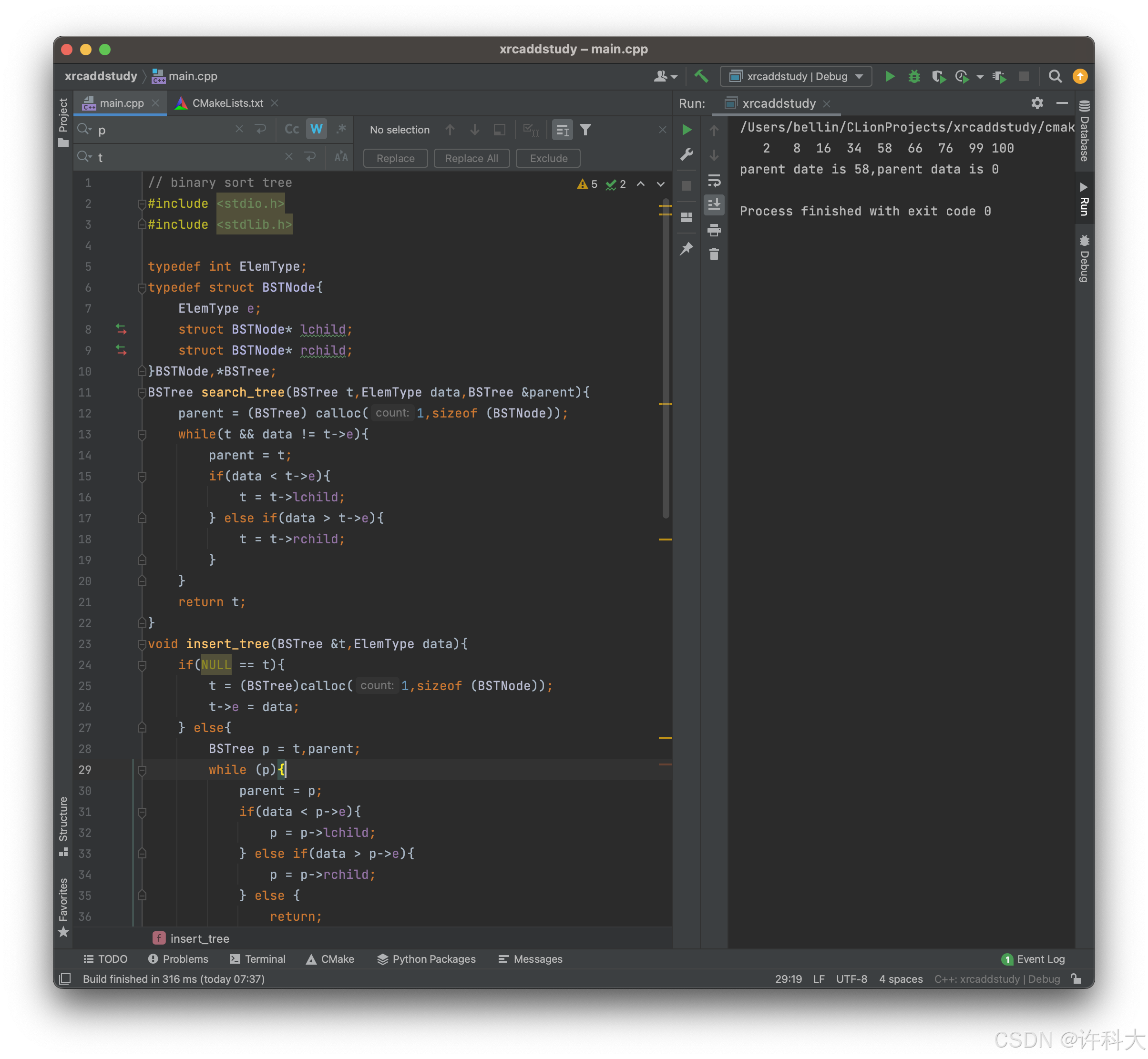
// binary sort tree
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct BSTNode{
ElemType e;
struct BSTNode* lchild;
struct BSTNode* rchild;
}BSTNode,*BSTree;
void insert_tree_recursion(BSTree &t,ElemType date){ // 递归插入
if(NULL == t){
t = (BSTree) malloc(sizeof (BSTNode)); // 为新节点申请空间,第一个节点作为树根,后面再递归进入的不是树根,是为叶子节点
t->e = date;
t->lchild = NULL;
t->rchild = NULL;
return; // 插入成功
}
if (date < t->e){ // 要插入的元素小于当前节点值
insert_tree_recursion(t->lchild,date); // 函数调用结束后,左孩子和原来的父节点会关联起来,巧妙利用了引用机制
} else if (date > t->e){ // 要插入的元素大于当前节点值
insert_tree_recursion(t->rchild,date);
} else if (date == t->e){
return; // 发现相同元素,不插入
}
}
BSTree search_tree(BSTree t,ElemType data,BSTree &parent){
parent = (BSTree) calloc(1,sizeof (BSTNode));
while(t && data != t->e){
parent = t;
if(data < t->e){ // 比当前节点值小,在左边继续查找
t = t->lchild;
} else if(data > t->e){ // 比当前节点值大,在右边继续查找
t = t->rchild;
}
}
return t;
}
void insert_tree(BSTree &t,ElemType data){
if(NULL == t){ // 为新节点申请空间,第一个节点作为根,t是树根
t = (BSTree)calloc(1,sizeof (BSTNode));
t->e = data;
} else{
BSTree p = t,parent; // p用来遍历,parent用来存p的父节点。
while (p){
parent = p;
if(data < p->e){
p = p->lchild;
} else if(data > p->e){
p = p->rchild;
} else {
return;
}
}
BSTree n = (BSTree) calloc(1,sizeof (BSTNode)); // 开始申请空间并插入
n->e = data;
if(data < parent->e){
parent->lchild = n; // 新节点在父节点的左边
} else if(data > parent->e){
parent->rchild = n; // 新节点在父节点的右边
}
}
}
void create_tree(BSTree &t,ElemType arr[],int length){ // 创建二叉排序树
for (int i = 0; i < length; i++){
// insert_tree(t,arr[i]); // 把某一节点放入二叉查找树
insert_tree_recursion(t,arr[i]); // 递归插入
}
}
void order_tree(BSTree t){
if(t){
order_tree(t->lchild);
printf("%4d",t->e);
order_tree(t->rchild);
}
}
int main(){
BSTree t = NULL;
ElemType arr[9] = {58,34,100,76,2,99,66,16,8};
create_tree(t,arr,9);
order_tree(t);
printf("\n");
BSTree parent;
BSTree search;
search = search_tree(t,99,parent);
if(search){
printf("parent date is %d,parent data is %d\n",search->e,parent->e);
} else{
printf("have not found data\n");
}
free(t);
return 0;
}
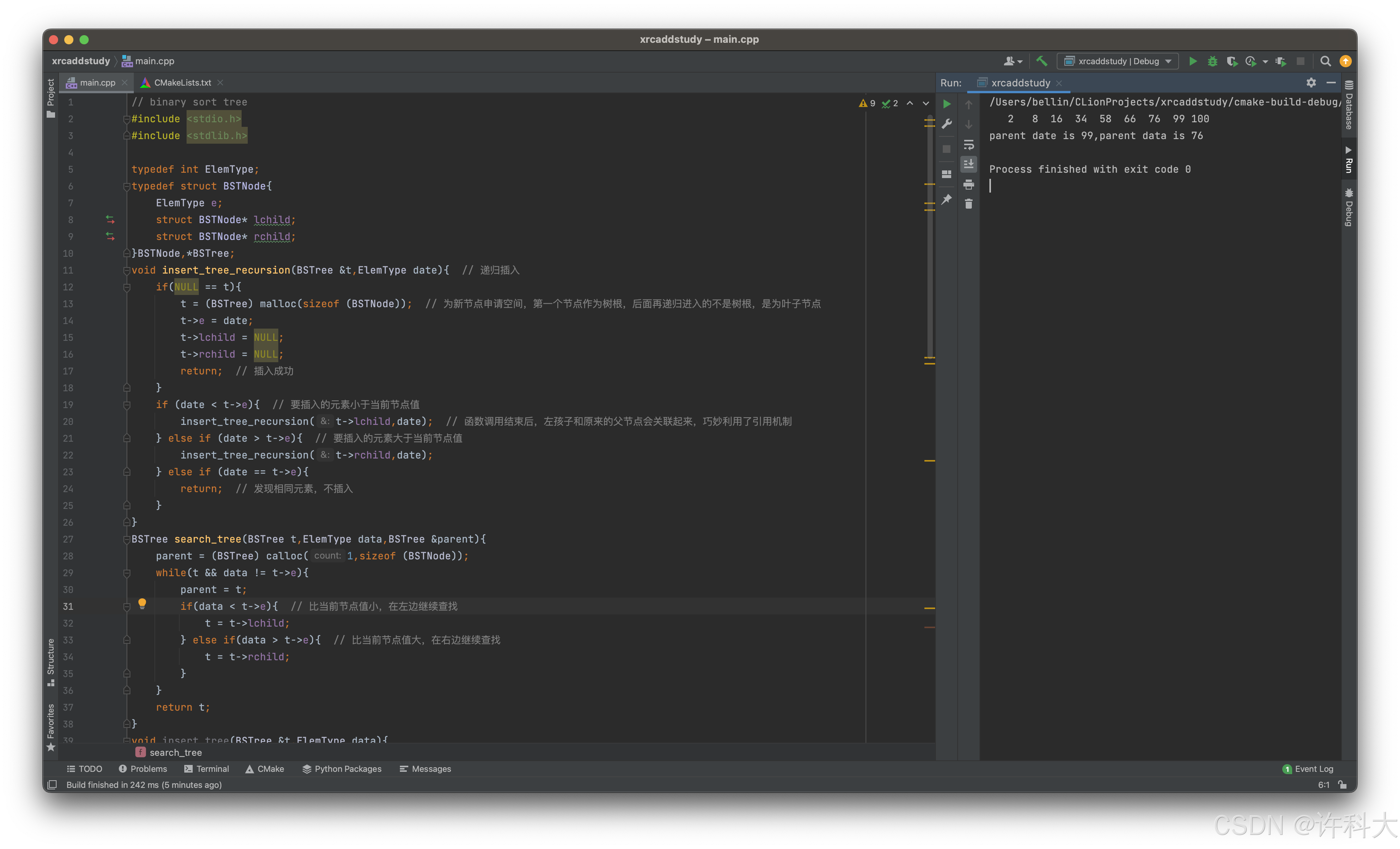
【15.6 二叉排序树删除实战】
二叉排序树的删除使用递归来实现。
// binary sort tree
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct BSTNode{
ElemType e;
struct BSTNode* lchild;
struct BSTNode* rchild;
}BSTNode,*BSTree;
void delete_tree(BSTree &t,ElemType date){
if(NULL == t){
return;
}
if(date < t->e){
delete_tree(t->lchild,date); // 往左子树找要删除的节点
} else if (date > t->e){
delete_tree(t->rchild,date); // 往右子树找要删除的结点
} else if (date == t->e){
if (NULL == t->lchild){ // 左子树为空,右子树直接顶上去
BSTree del = t; // 用临时的存着的目的是需要释放,待free
t = t->rchild;
free(del);
} else if (NULL == t->rchild){ // 右子树为空,左子树直接顶上去
BSTree del = t; // 临时指针
t = t->lchild;
free(del);
} else { // 左右子树都不为空
// 一般的删除策略是左子树的最大数据 或 右子树的最小数据,代替要删除的节点(这里采用查找左子树最大数据来代替)
BSTree temp = t->lchild;
while(NULL != temp->rchild){ // 向右找到最大的
temp = temp->rchild;
}
t->e = temp->e; // 把temp对应的值替换到要删除的节点位置上
delete_tree(t->lchild,temp->e); // 删除临时指针temp
}
}
}
void insert_tree_recursion(BSTree &t,ElemType date){ // 递归插入
if(NULL == t){
t = (BSTree) malloc(sizeof (BSTNode)); // 为新节点申请空间,第一个节点作为树根,后面再递归进入的不是树根,是为叶子节点
t->e = date;
t->lchild = NULL;
t->rchild = NULL;
return; // 插入成功
}
if (date < t->e){ // 要插入的元素小于当前节点值
insert_tree_recursion(t->lchild,date); // 函数调用结束后,左孩子和原来的父节点会关联起来,巧妙利用了引用机制
} else if (date > t->e){ // 要插入的元素大于当前节点值
insert_tree_recursion(t->rchild,date);
} else if (date == t->e){
return; // 发现相同元素,不插入
}
}
BSTree search_tree(BSTree t,ElemType data,BSTree &parent){
parent = (BSTree) calloc(1,sizeof (BSTNode));
while(t && data != t->e){
parent = t;
if(data < t->e){ // 比当前节点值小,在左边继续查找
t = t->lchild;
} else if(data > t->e){ // 比当前节点值大,在右边继续查找
t = t->rchild;
}
}
return t;
}
void insert_tree(BSTree &t,ElemType data){
if(NULL == t){ // 为新节点申请空间,第一个节点作为根,t是树根
t = (BSTree)calloc(1,sizeof (BSTNode));
t->e = data;
} else{
BSTree p = t,parent; // p用来遍历,parent用来存p的父节点。
while (p){
parent = p;
if(data < p->e){
p = p->lchild;
} else if(data > p->e){
p = p->rchild;
} else {
return;
}
}
BSTree n = (BSTree) calloc(1,sizeof (BSTNode)); // 开始申请空间并插入
n->e = data;
if(data < parent->e){
parent->lchild = n; // 新节点在父节点的左边
} else if(data > parent->e){
parent->rchild = n; // 新节点在父节点的右边
}
}
}
void create_tree(BSTree &t,ElemType arr[],int length){ // 创建二叉排序树
for (int i = 0; i < length; i++){
// insert_tree(t,arr[i]); // 把某一节点放入二叉查找树
insert_tree_recursion(t,arr[i]); // 递归插入
}
}
void order_tree(BSTree t){
if(t){
order_tree(t->lchild);
printf("%4d",t->e);
order_tree(t->rchild);
}
}
int main(){
BSTree t = NULL;
ElemType arr[9] = {58,34,100,76,2,99,66,16,8};
create_tree(t,arr,9);
order_tree(t);
printf("\n");
BSTree parent;
BSTree search;
search = search_tree(t,99,parent);
if(search){
printf("parent date is %d,parent data is %d\n",search->e,parent->e);
} else{
printf("have not found data\n");
}
delete_tree(t,58);
order_tree(t);
free(t);
return 0;
}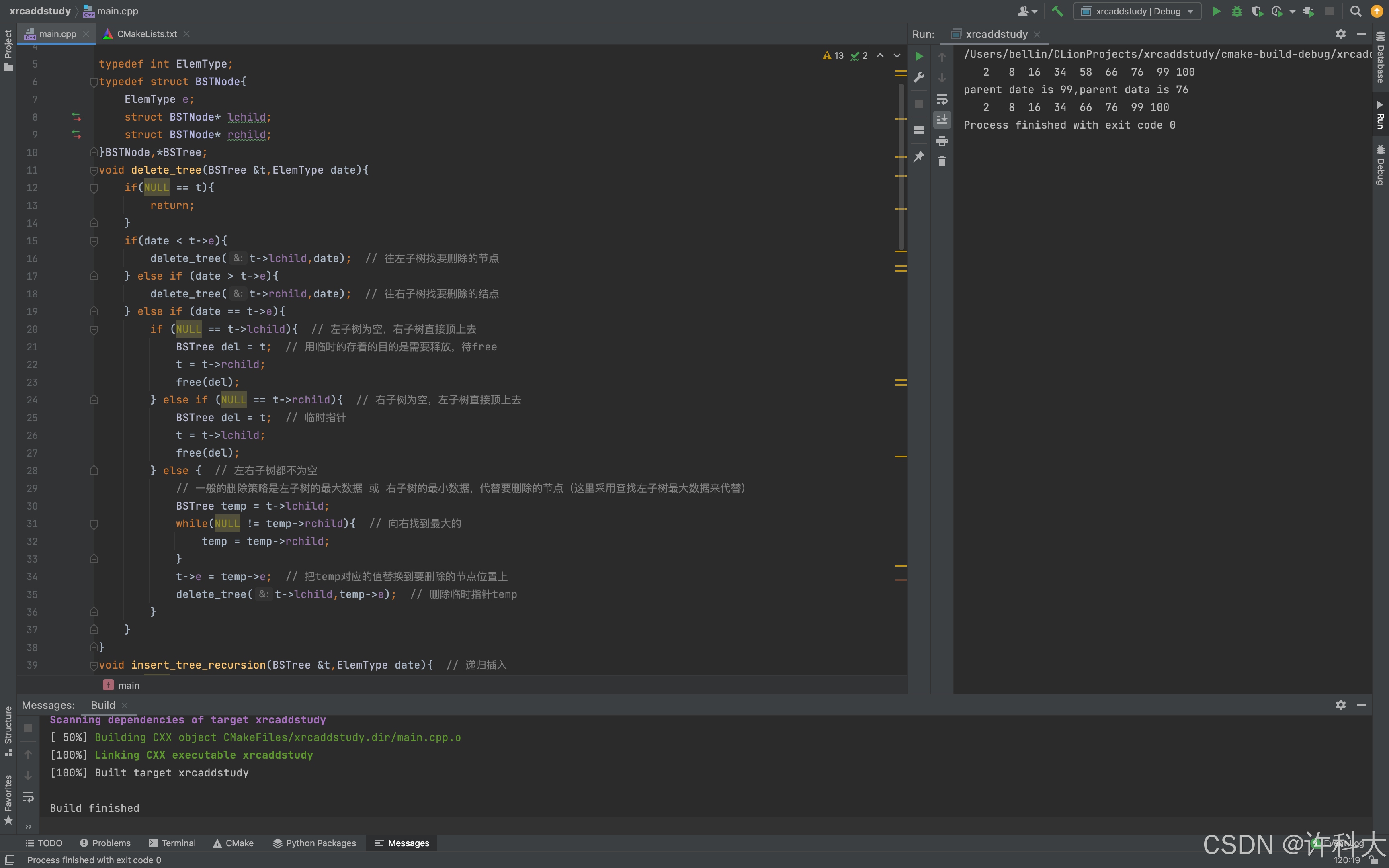
【15.6 题】
1、二叉排序树建树不需要使用辅助队列。
2、二叉排序树建树可以使用递归方式实现,也可以使用非递归方式来建树,设计左孩子小于父亲,右孩子大于父亲。
3、一个二叉树,如果中序遍历是从小到大,这棵二叉树一定是二叉排序树。它的任何一棵小的子树,左孩子、父亲、右孩子是存在有序关系的。
4、二叉排序树的删除,需要首先通过二叉查找,找到要删除的节点,如果要删除的节点是叶子节点,那么直接删除,删除后需要free对应节点空间;如果要删除的是父亲节点有一个孩子,那么左子树不为空,左子树顶上去,右子树不为空,右子树顶上去;如果要删除的节点是父节点(左右均有孩子),需要找到叶子节点或一棵子树的父亲节点来顶替,可以找左子树的最大值,也可以找右子树的最小值,把顶替者的值放到要删除的节点,然后删除顶替者即可。
【15.7 2011年42题真题】
42.(15分)一个长度为L(L>=1)的升序序列S,处在第「L/2」个位置的数称为S的中位数。例如,若序列S1={11,13,15,17,19},则S1的中位数是15,两个序列的中位数是含它们所有元素的升序序列的中位数。例如,若S2={2,4,6,8,20},则S1和S2的中位数是11,现在有两个等长升序序列A和B,试设计一个在时间和空间两方面都尽可能高效的算法,找出两个序列A和B的中位数。要求:1)给出算法的基本设计思想。2)根据设计思想,采用C、C++或java语言描述算法,关键之处给出注释。3)说明你所设计算法的时间复杂度和空间复杂度。
答案解析:
考察的内容是二分查找,但是有两个数组,是双数组的二分查找。因为空间尽可能高效,因此不能再去新建一个大数组,把两个数组合并到一起。
1)算法的基本设计思想如下:
分别求出序列A和B的中位数,设为a和b,求序列A和B的中位数过程如下:
1、若a=b,则舍弃序列A中较小的一半,同时舍弃序列B中较大的一半,要求舍弃的长度相等。
2、若a>b,则舍弃序列A中较大的一半,同时舍弃序列B中较小的一半,要求舍弃的长度相等。
3、若a<b,则舍弃序列A中较小的一半,同时舍弃序列B中较大的一半,要求舍弃的长度相等。
在保留的两个升序序列中,重复过程1、2、3,直到两个序列中均只含一个元素时为止,较小者即为所求的中位数。
2)代码实现如下:
// binary search for even groups
#include <stdio.h>
int mid_search(int A[],int B[],int length){
int a1 = 0,a9 = length - 1,b1 = 1,b9 = length - 1,mida,midb; // 分别表示序列A和B的首位、末位、中位
while(a1 != a9 || b1 != b9){ // 循环判断结束条件是,两个数均不断删除最后均只能剩余一个元素
mida = (a1 + a9)/2;
midb = (b1 + b9)/2;
if(A[mida] < B[midb]) { // A序列的中位数 小于 B序列的中位数
if((a1 + a9)%2 == 0) { // 元素个数为奇数
a1 = mida; // 舍弃A中间以前的部分,且保留中间元素
b9 = midb; // 舍弃B中间以后的部分,且保留中间元素
} else { // 元素个数为偶数
a1 = mida + 1; // 舍弃A中间以前的部分,且删除中间元素
b9 = midb; // 舍弃B中间以后的部分,且保留中间元素
}
} else if(A[mida] > B[midb]){ // A序列的中位数 大于 B序列的中位数
if((a1 + a9)%2 == 0){ // 元素个数为奇数
a9 = mida; // 舍弃A中间以后的部分,且保留中间元素
b1 = midb; // 舍弃B中间以前的部分,且保留中间元素
} else { // 元素个数为偶数
a9 = mida; // 舍弃A中间以后的部分,且保留中间元素
b1 = midb + 1; // 舍弃B中间以前的部分,且删除中间元素
}
} else if(A[mida] == B[midb]){ // A序列的中位数 等于 B序列的中位数
return A[mida];
}
}
return A[a1] < B[b1] ? A[a1] : B[b1]; // 取较小的元素
}
int main(){
int A[] = {11,13,15,17,19};
int B[] = {2,4,6,8,20};
int mid = mid_search(A,B,5);
printf("mid element is %d\n",mid);
int C[] = {7,11,13,15,17,19};
int D[] = {2,4,6,8,20,21};
int mid2 = mid_search(C,D,6);
printf("mid2 element is %d\n",mid2);
return 0;
}
3)算法的时间复杂度为,空间复杂度为O(1)。
因为没有使用额外的跟n相关的空间,因为不断的二分,次数是,所以时间复杂度是
。
【15 代码题】
读取10个元素87 7 60 80 59 34 86 99 21 3,然后建立二叉查找树,中序遍历输出3 7 21 34 59 60 80 86 87 99,针对排序后的元素,存入一个长度为10的数组中,通过折半查找找到21的下标(下标为2),然后输出2.每个元素占3个字母位置。
这道题考察的是二叉查找树,建树、中序遍历、二分查找。主要是如何把元素存入到一个数组中。
【第16节 考研必会的排序算法(上)】
【16.2 与408关联】
1 与408关联
2016年
43.已知由n(n>=2)个正整数构成的集合A={ak|0<=k<n},将其划分为两个不相交的子集A1和A2,元素个数分别是n1和n2,A1和A2中元素之和分别为S1和S2,设计一个尽可能高效的划分算法,满足|n1-n2|最小且|S1-S2|最大,要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。3)说明你所设计算法的平均时间复杂度和空间复杂度。
2 本节内容介绍
本大节课分为16.3小节到16.7小节,包含冒泡排序、快速排序、插入排序等常考排序算法。快排大题常考。
16.3小节是冒泡排序原理解析
16.4小节是冒泡排序实战
16.5小节是快速排序原理解析
16.6小节是快速排序实战
16.7小节是插入排序原理及实战
【16.3 冒泡排序原理解析】
1 排序
排序算法分为交换类排序,插入类排序,选择类排序,归并类排序
交换排序分为:冒泡排序、快速排序
2 冒泡排序
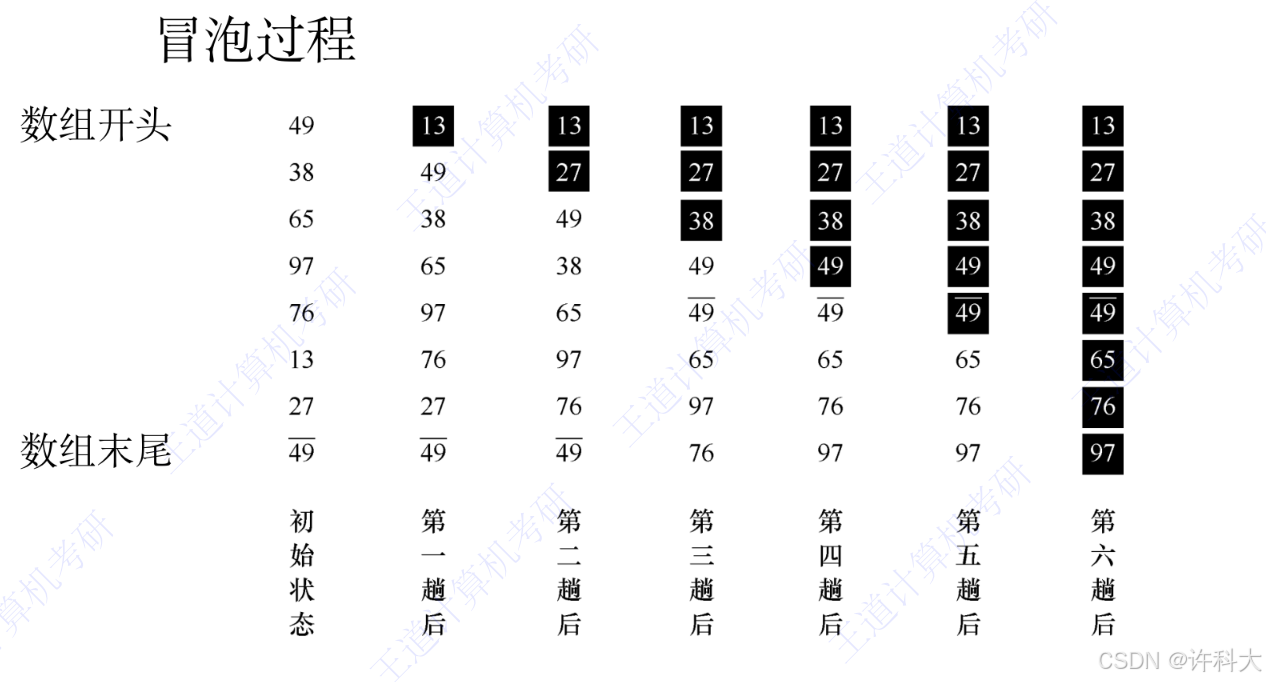
冒泡排序的基本思想是:从后往前(或从前往后)两两比较相邻元素的值,(若A[j-1]>A[j]),则交换它们,直到序列比较完。称它为第一趟冒泡,结果是将最小的元素交换到待排序列的第一个位置。关键字最小的元素如气泡一般逐渐往上“漂浮”直至“水面”。下一趟冒泡时,前一趟确定的最小元素不再参与比较,每趟冒泡的结果是把序列中的最小元素放到了序列的最终位置。。。这样最多做n-1趟冒泡就能把所有元素排好序。
也可以通过下面动画网址来理解
Comparison Sorting Visualization
动画使用的方法是,先点play,然后及时点击pause,自己通过StepForward来查看。
【16.4 冒泡排序实战】
代码实战步骤:先通过随机数生成10个元素,通过随机数生成,可以多次测试排序算法是否正确,然后打印随机生成后的元素顺序,然后通过冒泡排序对元素进行排序,然后再次打印排序后的元素顺序。
// bubble sort
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
#include <string.h>
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void swap(ElemType &a,ElemType &b){ // 交换两个元素
ElemType temp;
temp = a;
a = b;
b = temp;
}
void bubble_sort(SSTable &t){
bool flag;
for (int i = 0; i < t.len - 1; i++) { // 外层完成一次循环后,最小值到了最前面,最多访问到8
for (int j = t.len - 1; j > i; j--) { // 把最小值就放在最前面
if (t.e[j] < t.e[j-1]){
swap(t.e[j],t.e[j-1]);
flag = true;
}
}
if(false == flag){ // 如果一趟比较没有发生任何交换,说明有序,提前结束排序
return;
}
}
}
void init_table(SSTable &t,int length){
t.len = length;
t.e = (ElemType*)malloc(sizeof (ElemType)*t.len); // 申请一块堆空间,当数组来使用
srand(time(NULL)); // 随机数生成,每一次执行代码就会得到随机的10个元素
for (int i = 0; i < length; i++) {
t.e[i] = rand()%100; // 生成的是0-99之间
}
}
void print_table(SSTable t){ // 打印数组中的元素
for (int i = 0; i < t.len; i++) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
init_table(t,10);
print_table(t);
bubble_sort(t);
print_table(t);
// 内存copy借口,当copy整个数组,或者浮点型是,使用memcpy,不能使用strcpy。
ElemType num[10] = {64,94,95,79,69,84,18,22,12,78};
memcpy(t.e,num,sizeof (num));
print_table(t);
bubble_sort(t);
print_table(t);
free(t.e);
return 0;
}
时间复杂度是程序实际的运行次数。内层是j>i,外层i的值是从0到length-1,所以程序的总运行次数是1+2+3+...+(N-1),即从1一直加到length-1,是等差数列求和,得到的结果是length(length-1)/2,即总计运行了这么多次。忽略了低阶项和高阶项的首项系数,因此时间复杂度为,因为未使用额外的空间(额外空间必须与输入元素的个数length相关),所以空间复杂度为O(1).
如果数组本身有序,那么就是最好的时间复杂度O(n)。
【16.4 题】
1、冒泡排序可以使用元素是否发生交换的标志,如果一趟比较没有发生任何交换,说明有序,提前结束排序。
2、冒泡排序的时间复杂度是最坏和平均都是,最好是O(n)。
【16.5 快速排序原理解析】
1 排序
交换排序分为:冒泡排序、快速排序
2 快速排序
快速排序的核心是分治思想:假设目的是按从小到大的顺序排列,找到数组中的一个分割值,把比分割值小的数都放在数组的左边,把比分割值大的数都放在数组的右边,这样分割值的位置就被确定。数组一分为二,只需排前一般数组和后一半数组,复杂度直接减半。采用这种思想,不断地进行递归,最终分割的只剩一个元素时,整个序列自然就是有序的。
动画示例:Comparison Sorting Visualization
【16.6 快速排序实战】
代码实战步骤:先通过随机数生成10个元素,通过随机数生成,可以多次测试排序算法是否正确,然后打印随机生成后的元素顺序,然后通过快速排序对元素进行排序,然后再次打印排序后的元素顺序。
// quick sort
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
int partition(ElemType e[],int low,int high){
int part_point = e[low]; // 首先使用左边元素作为分割值
while (low < high){
while (low < high && e[high] >= part_point){ // 从后往前遍历,找到一个比分割值小的
high--;
}
e[low] = e[high]; // 把比分割值小的那个元素,放到e[low]
while (low < high && e[low] <= part_point){ // 从前往后遍历,找到一个比分割值大的
low++;
}
e[high] = e[low]; // 把比分割值大的那个元素,放到e[high],因为刚才high位置的元素已经放到low位置
}
e[low] = part_point;
return low; // 返回分割值所在的下标
}
void quick_sort_table(ElemType e[],int low,int high){ // 分治思想
if(low < high){
int part_point = partition(e,low,high);
quick_sort_table(e,low,part_point - 1);
quick_sort_table(e,part_point + 1,high);
}
}
void init_table(SSTable &t,int length){
t.len = length;
t.e = (ElemType*) malloc(sizeof (ElemType) * length); // 申请一块堆空间,当数组来使用
srand(time(NULL)); // 随机数生成,每一次执行代码就会得到随机的10个元素
for (int i = 0; i < t.len; i++) {
t.e[i] = rand()%100; // 生成的是0-99之间
}
}
void print_table(SSTable t){
for (int i = 0; i < t.len; i++) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
init_table(t,10);
print_table(t);
quick_sort_table(t.e,0,9);
print_table(t);
return 0;
}
假如每次快速排序数组都被平均一分为二,那么可以得出quicksort递归的次数是,第一次partition遍历次数为n,分成两个数组后,每个数组遍历n/2次,加起来还是n,因此时间复杂度是
,因为计算机是二进制的,所以在复试面试回答复杂度或与人交流时,提到复杂度时一般直接讲
,而不带下标2,快速排序最差的时间复杂度是
,因为数组本身从小到大有序时,如果每次仍然用最左边的数作为分割值,那么每次数组都不会二分,导致递归n次,所以快速排序最坏时间复杂度为n的平方。为了避免这种情况,有时首先随机选择一个下标,先将对应下标的值与最左边的元素交换,再进行partition操作,从而极大地降低出现最坏时间复杂度的概率,但是仍然不能完全避免。
因此快速排序最好和平均时间复杂度是,最差是
。
快排的空间复杂度是,因为递归的次数是
,而每次递归的形参都是需要占用空间的。
【16.6 题】
1、交换排序分为冒泡排序与快速排序。
【16.7 插入排序原理解析】
1 插入排序原理解析
插入排序分为直接插入排序、折半插入排序、希尔排序。
如果一个序列只有一个数,那么该序列自然是有序的,插入排序首先将第一个数视为有序序列,然后把后面9个数视为要一次插入的序列。首先,通过外层循环控制要插入的数,用insert_value保存要插入的值87,比较arr[0]是否大于arr[1],即3是否大于87,由于不大于,因此不发生移动,这时有序序列是3,87.接着,将数值2插入有序序列,首先将2赋给insert_value,这时判断87是否大于2,因为87大于2,所以将87向后移动,将2覆盖,然后判断判断3是否大于2,因为3大于2,所以3移动到87所在的位置,内层循环结束,这时将2赋给arr[0]的位置,得到下表中第2次插入后的效果。
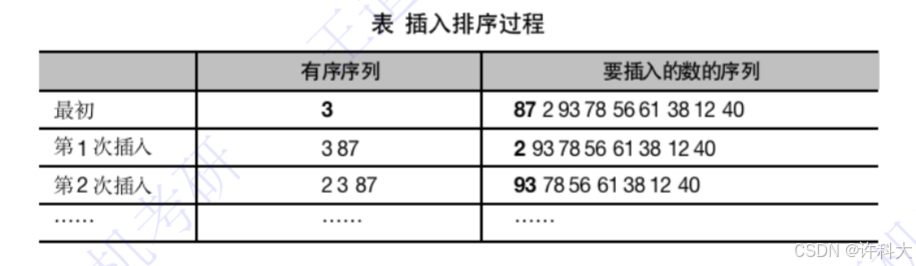
继续循环会将数一次插入有序序列,最终使得整个数组有序。插入排序主要用在部分数有序的场景,例如手机通讯录时时刻刻都是有序的,新增一个电话号码时,以插入排序的方法将其插入原有的有序序列,这样就降低了复杂度。
动画示例:Comparison Sorting Visualization
随着有序序列的不断增加,插入排序比较的次数也会增加,插入排序的执行次数也是从1加到n-1,总运行次数为n(n-1)/2,时间复杂度依然为。因为未使用额外的空间(额外空间必须与输入元素的个数N相关),所以空间复杂为O(1)。
如果数组本身有序,那么就是最好的时间复杂度O(n)。当数组有序,内层循环每次都是无法进入的,因此,最好的时间复杂度就是O(n)。
插入排序使用哨兵,用了哨兵只是省略了j>=0这一句代码。

2 插入排序代码实战
// insertion sort
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void insertion_sort_table(SSTable &t){
ElemType temp;
for (int i = 1; i < t.len; i++) { // 控制要插入的数
temp = t.e[i]; // 先保存要插入的值
int j;
for (j = i; j > 0 && t.e[j-1] > temp; j--) { // 内层控制比较j 要大于0,同时e[j]大于要插入的值,e[j-1]位置元素往后覆盖
t.e[j] = t.e[j-1];
}
t.e[j] = temp;
}
}
void init_table(SSTable &t,int length){
t.len = length;
t.e = (ElemType*) malloc(sizeof (ElemType) * length); // 申请一块堆空间,当数组来使用
srand(time(NULL)); // 随机数生成,每一次执行代码就会得到随机的10个元素
for (int i = 0; i < t.len; i++) {
t.e[i] = rand()%100; // 生成的是0-99之间
}
}
void print_table(SSTable t){
for (int i = 0; i < t.len; i++) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
init_table(t,10);
print_table(t);
insertion_sort_table(t);
print_table(t);
return 0;
}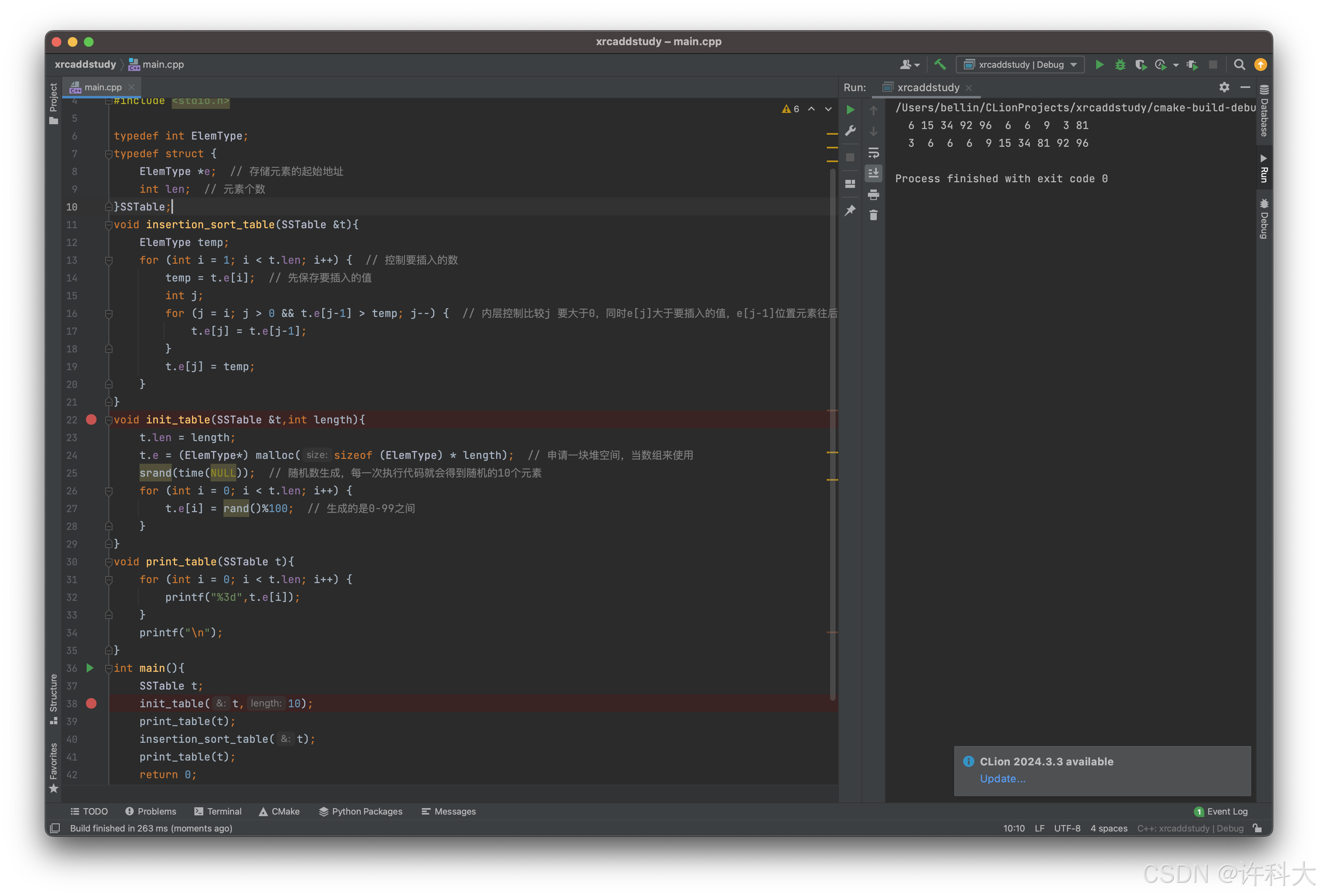
【16.7 题】
1、插入排序分为:直接插入排序、折半插入排序、希尔排序。
2、插入排序首先将第一个数视为有序序列,然后把后面9个数视为要依次插入的序列。
3、插入排序的时间复杂度是最坏和平均都是,最好是O(n)。插入本身有序,提前结束排序,那么时间复杂度就是最好。
【16 代码题】
读取10个整型数据12 63 58 95 41 35 65 0 38 44,然后通过冒泡排序,快速排序,插入排序,分别对该组数据进行排序,输出3次有序结果,每个数的输出占3个空格。
【TODO】
【第17节 考研必会的排序算法(下)】
【17.2 与408关联】
1 与408关联
2022年
42.(10分)现有n(n>=100000)个数保存在一个数组M中,需要查找M中最小的10个数,请回答下列问题。1)设计一个完成上述查找任务的算法,要求平均情况下的比较次数尽可能少,简单描述其算法思想,不需要程序实现。2)说明你所设计的算法平均情况下的时间复杂度和空间复杂度。
2 本节内容介绍
本大节课分为17.3小节到17.6小节,包含选择排序,堆排序,归并排序等常考排序算法。
17.3小节是选择排序原理及实战
17.4小节是堆排序原理解析
17.5小节是堆排序代码实战
17.6小节是归并排序原理及实战
【17.3 选择排序原理及实战】
1 选择排序原理解析
选择排序分为:简单选择排序、堆排序(重要)
简单选择排序原理是:假设排序表为L{1...n},第i趟排队即从L{i...n}中选择关键字最小的元素与L(i)交换,每一趟排序可以确定一个元素的最终位置,这样经过n-1趟排序就可使得整个排序有序。
首先假定第零个元素是最小的,把下标0赋值给min(min记录最小的元素的下标),内层比较时,从1号元素一直比较到9号元素,谁更小,就把它的下标赋给min,一轮比较结束后,将min对应位置的元素与元素i交换。如下表所示,第一轮确认2最小,将2与数组开头的元素3交换,第二轮最初认为87最小,经过一轮比较,发现3最小,这时将87与3交换,持续进行,最终使数组有序。
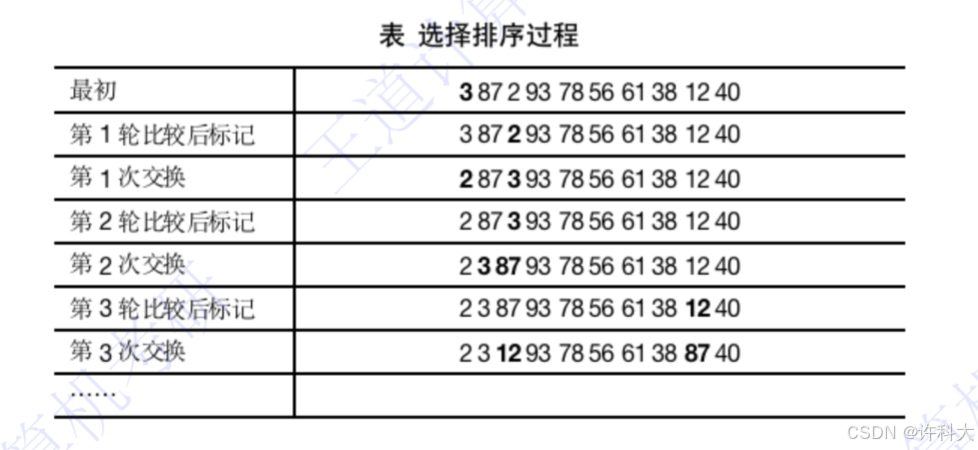
动画示例:
Comparison Sorting Visualization
2 选择排序代码实战
// selection sort
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void swap(ElemType &a,ElemType &b){
ElemType temp = a;
a = b;
b = temp;
}
void selection_sort_table(SSTable &t){
ElemType i,j,min; // 记录最小的元素的下标
for (i = 0; i < t.len - 1; i++) { // 最多可以为n-2
min = i; // 认为第i个位置最小
for (j = i+1; j < t.len; j++) { //最多可以为n-1
if (t.e[j] < t.e[min]){
min = j;
}
}
if(min!=i){
swap(t.e[i],t.e[min]); // 遍历完毕找到最小值的位置后,与t.e[i]交换,这样最小值被放到了最前面
}
}
}
void init_table(SSTable &t,int length){
t.len = length;
t.e = (ElemType*) malloc(sizeof (ElemType) * length); // 申请一块堆空间,当数组来使用
srand(time(NULL)); // 随机数生成,每一次执行代码就会得到随机的10个元素
for (int i = 0; i < t.len; i++) {
t.e[i] = rand()%100; // 生成的是0-99之间
}
}
void print_table(SSTable t){
for (int i = 0; i < t.len; i++) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
init_table(t,10);
print_table(t);
selection_sort_table(t);
print_table(t);
return 0;
}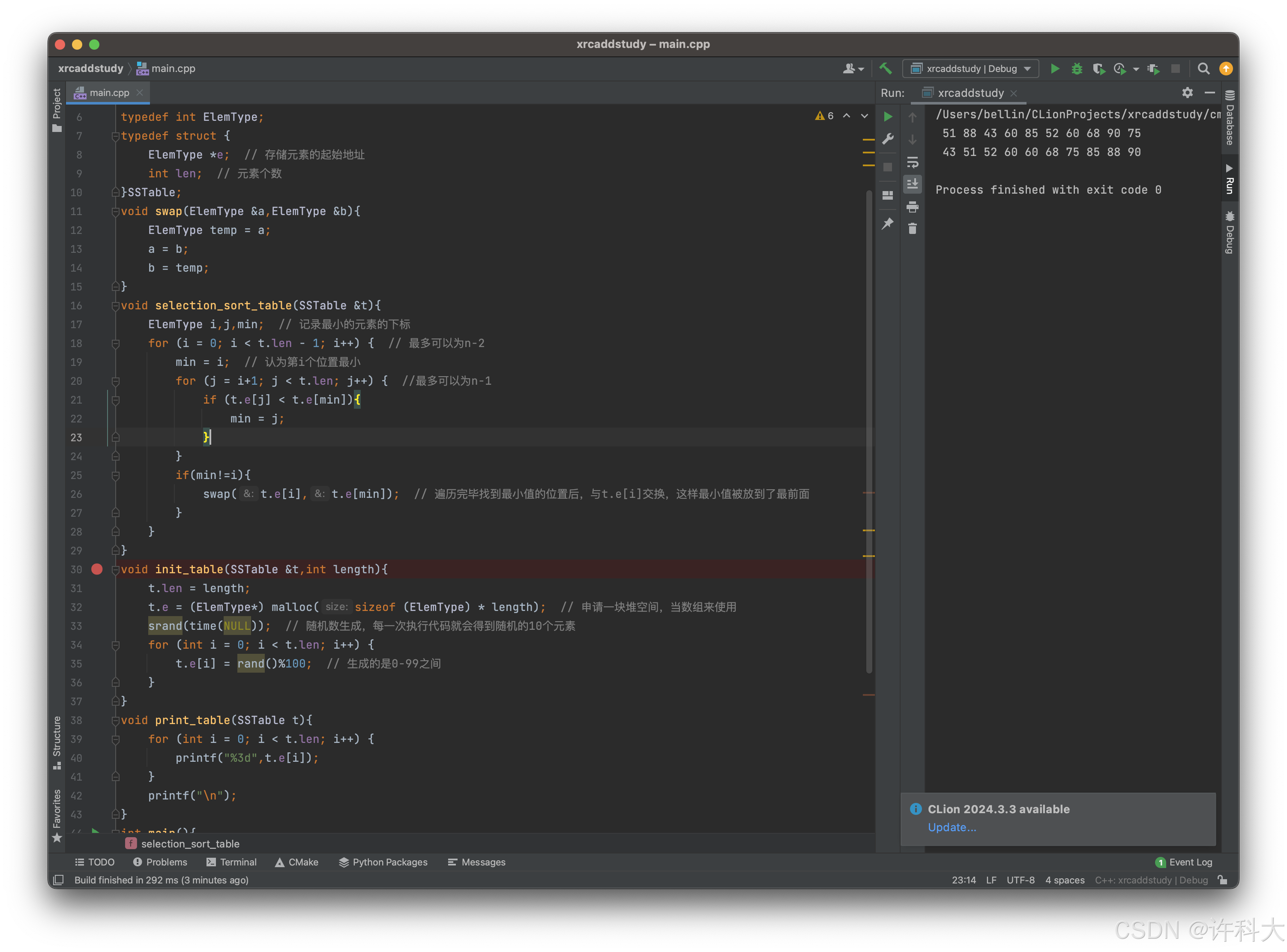
选择排序虽然减少了交换次数,但是循环比较的次数依然和冒泡排序的数量是一样的,都是从1加到n-1,总运行次数为n(n-1)/2,忽略循环内语句的数量,因为在计算时间复杂度时,主要考虑与n有关的循环,如果循环内交换得多,例如有5条语句,那么最终得到的无非是;循环内交换得少,例如有2条语句,那么得到的就是
,但是时间复杂度计算时忽略首项系数的,因此选择排序的时间复杂度依然为
。因为未使用额外的空间(额外的空间必须与输入元素的个数n相关),所以空间复杂度为O(1)。
【17.3 题】
1、简单选择排序原理:假设排序表为L{1...n},第i趟排序即从L{i...n}中选择关键字最小的元素与L(i)交换,每一趟排序可以确定一个元素的最终位置,这样经过n-1趟排序就可使得整个排序表有序。
2、对于序列3 87 2 93 78 56 61 38 12 40,经过第一趟选择排序后,得到的结果是2 87 3 93 78 56 61 38 12 40.
3、选择排序的时间复杂度是最坏和平均都是,最好是
,空间复杂度是O(1)。
【17.4 堆排序原理解析】
堆(heap)是计算机科学中的一种特殊的树状数据结构。若满足以下特性,则可称为堆:“给定队中任意节点P和C,若P是C的父节点,则P的值小于等于(或大于等于)C的值。”若父节点的值恒小于等于子节点的值,则该堆称为最小堆(min heap);反之,若父节点的值恒大于等于子节点的值,则称该堆为最大堆(max heap)。堆中对顶端的那个节点称为根节点(root node),根节点本身没有父节点(parent node)。平时在工作中,将最小堆称为小根堆或小顶堆,把最大堆称为大根堆或大顶堆。
假设有3,87,2,93,78,56,61,38,12,40共10个元素,将这10个元素建成一个完全二叉树,这里采用层次建树法,虽然只用一个数组存储元素,但是能将二叉树中任意一个位置的元素对应到数组下标上,将二叉树中每个元素对应到数组下标的这种数据结构称为堆,比如最后一个父元素的下标是n/2-1,也就是a[4],对应的值为78.为什么是n/2-1,因为这时层次建立一棵完全二叉树的特性。如果父节点的下标是dad,那么父节点对应的左子节点的下标值是2*dad+1.接着,一次将每棵子树都调整为父节点最大,最终将整棵树变为一个大根堆。
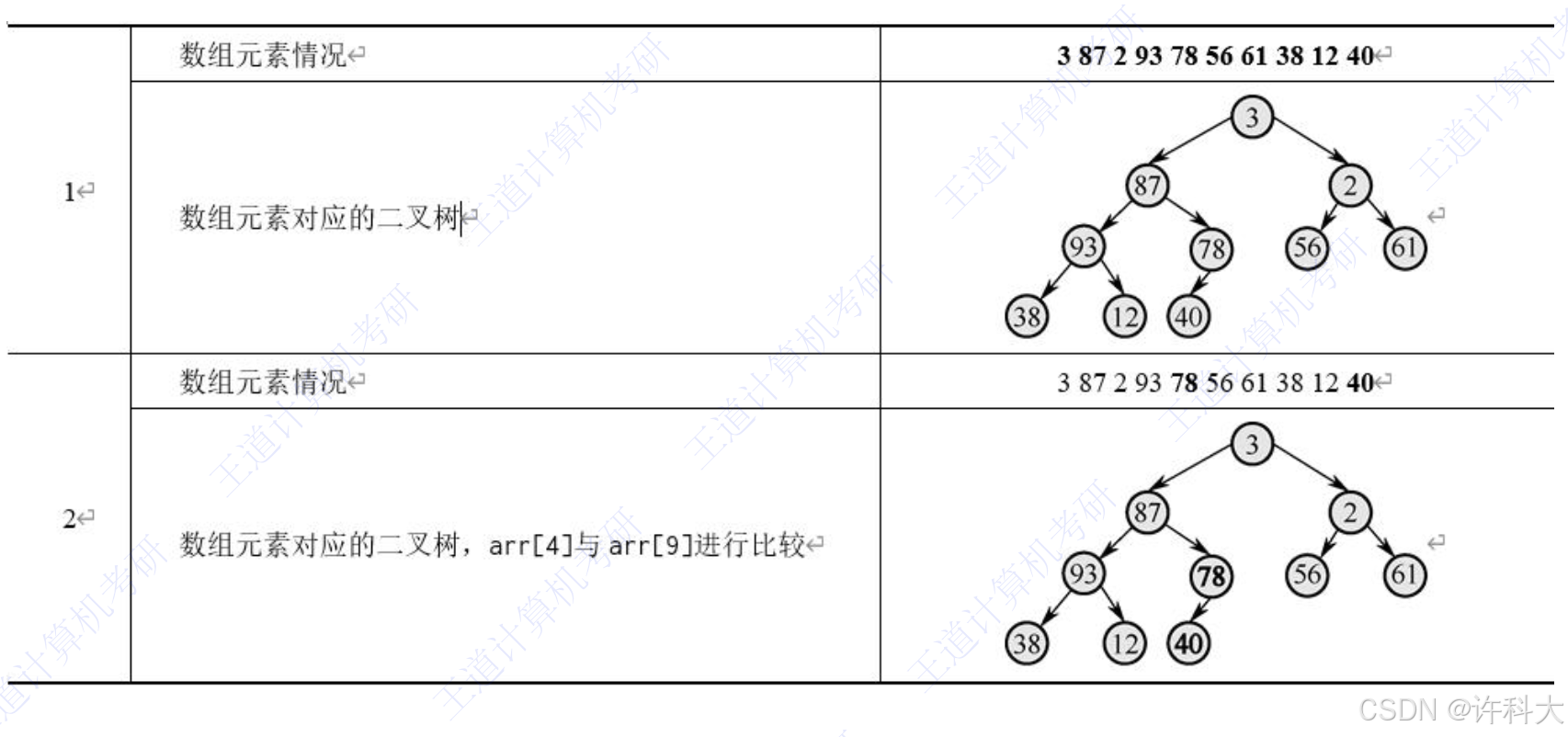
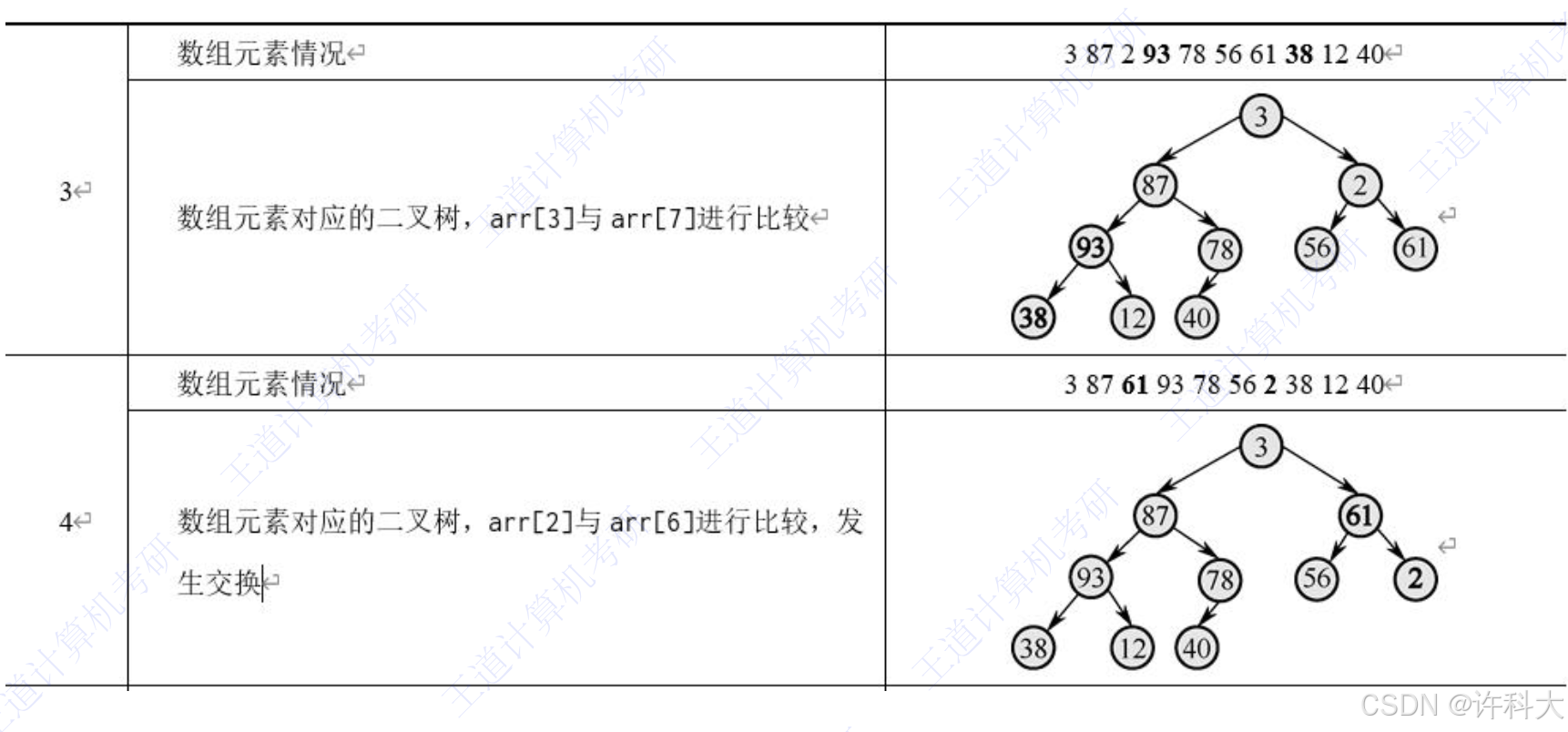
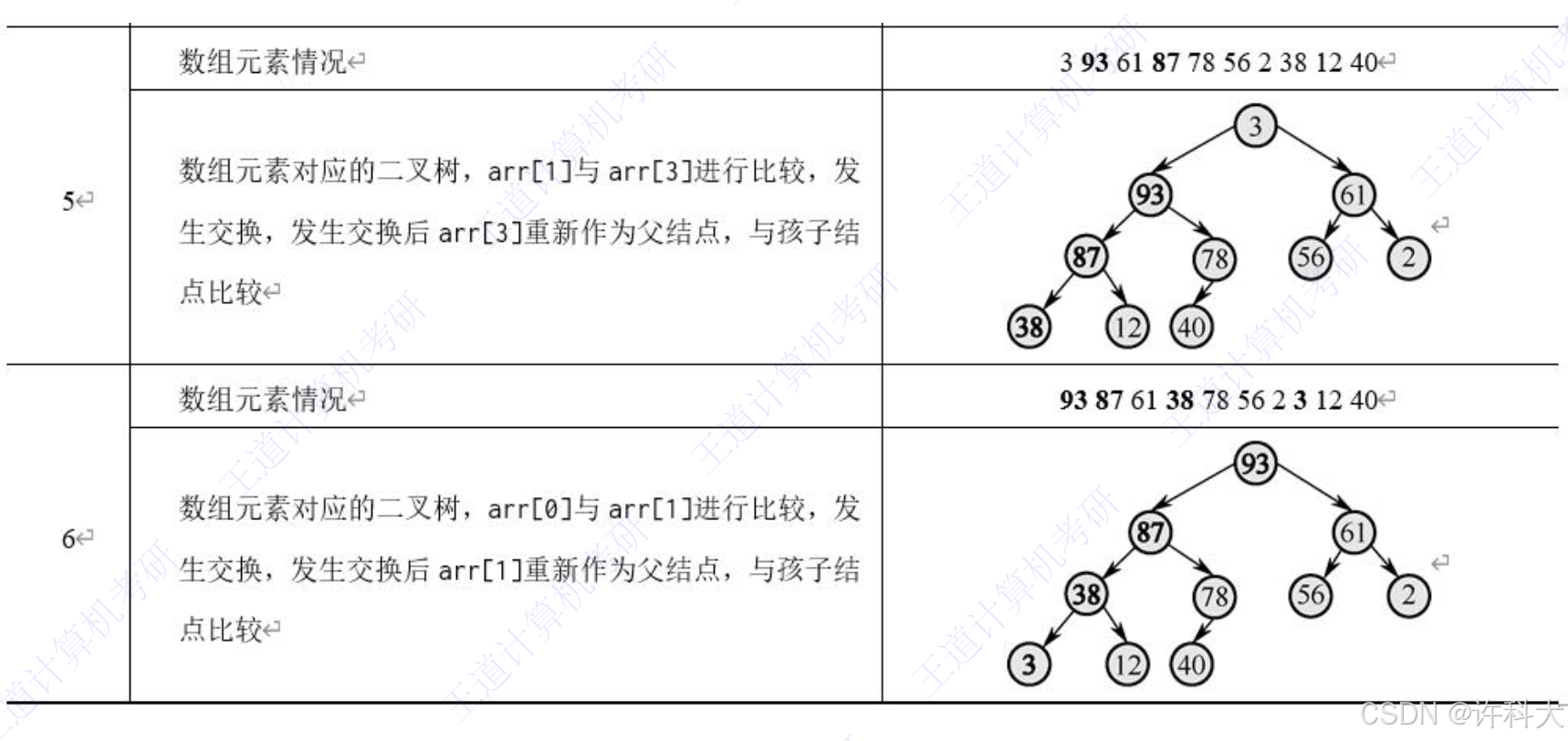
【17.5 堆排序实战】
代码实战步骤:先通过随机数生成10个元素,通过随机数生成,可以多次测试排序算法是否正确,然后打印随机生成后的元素顺序,然后通过对排序对元素进行排序,然后再次打印排序后的元素顺序。
堆排序的步骤是先把堆调整为大根堆,然后交换根部元素也就是A[0],和最后一个元素,这样最大的元素就放到了数组最后,接着将剩余9个元素继续调整为大根堆,然后交换A[0]和9个元素的最后一个,循环往复,直到有序。
如果还是比较迷糊,超级推荐看代码的同时结合动图理解,然后写代码的时候,结合图来写。
// heap sort
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void swap(ElemType &a,ElemType &b){
ElemType temp = a;
a = b;
b = temp;
}
void adjust(SSTable &t,int dad,int tail){
int son = 2*dad + 1; // 左子节点下标
while(son <= tail){
if(son < tail && t.e[son] < t.e[son+1]){ // 当右子节点存在时,左子节点与右子节点比较大小
son++;
}
if(t.e[dad] < t.e[son]){ // 父节点与子节点比较大小
swap(t.e[dad],t.e[son]);
dad = son;
son = 2*dad + 1;
} else{
break;
}
}
}
void heap_sort_table(SSTable &t){
for (int dad = t.len/2-1; dad >= 0 ; dad--) { // 建立大根堆,所有子节点都小于父节点
adjust(t,dad,t.len-1);
}
swap(t.e[0],t.e[t.len-1]); // 交换根部和数组最后一个元素
for (int tail = t.len - 2; tail > 0; tail--) { // 不断调整剩余元素为大根堆,因为根部需要最大,只有根节点需要往下调整
adjust(t,0,tail);
swap(t.e[0],t.e[tail]); // 调整后,再次将根节点与当前部分数组最后一个元素交换,保证当前数组的末尾是当前数组的最大值
}
}
void init_table(SSTable &t,int length){
t.len = length;
t.e = (ElemType*) malloc(sizeof (ElemType) * length); // 申请一块堆空间,当数组来使用
srand(time(NULL)); // 随机数生成,每一次执行代码就会得到随机的10个元素
for (int i = 0; i < t.len; i++) {
t.e[i] = rand()%100; // 生成的是0-99之间
}
}
void print_table(SSTable t){
for (int i = 0; i < t.len; i++) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
init_table(t,10);
print_table(t);
heap_sort_table(t);
print_table(t);
return 0;
}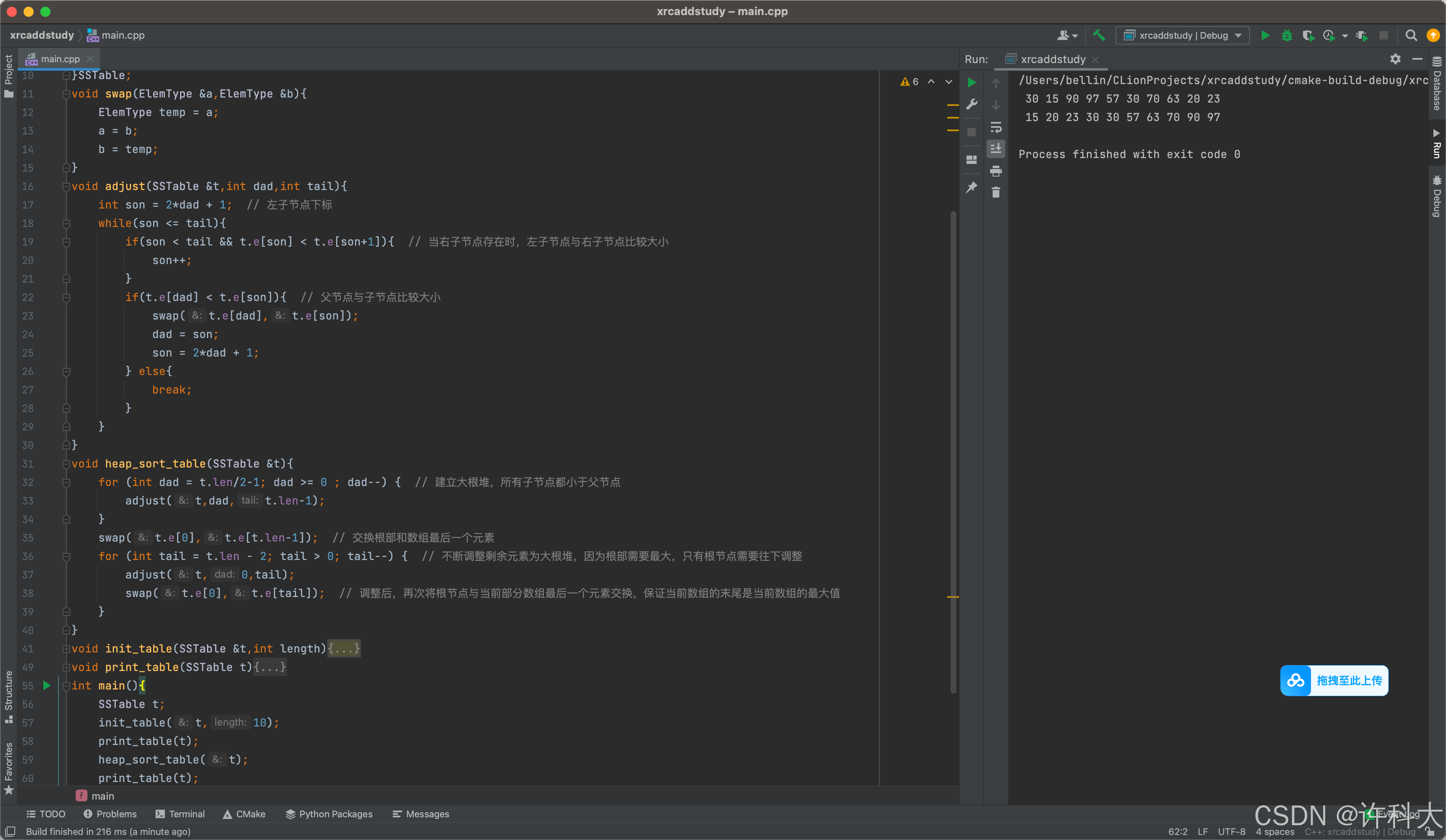
adjust函数的循环次数是,heap_sort函数的第一个for循环了n/2次,第二个for循环了n次,总计次数是3/2
次,因此时间复杂度是
。
堆排最好、最坏、平均时间复杂度都是。
堆排的空间复杂度是O(1),因为没有使用与n相关的额外空间。
【17.5 题】
1、将二叉树中每个元素对应到数组下标的这种数据结构称为堆。堆是用数组去表示二叉树的一种结构,而且表示的一定是完全二叉树。
2、大根堆的根部元素一定是最大的。数组第0个元素,就是根部元素。
3、数组3 87 2 93 78 56 61 38 12 40,将其看成堆,那么调整为大根堆后,元素顺序为93 87 61 38 78 56 2 3 12 40。
【17.6 归并排序原理及实战】
1 归并排序原理解析
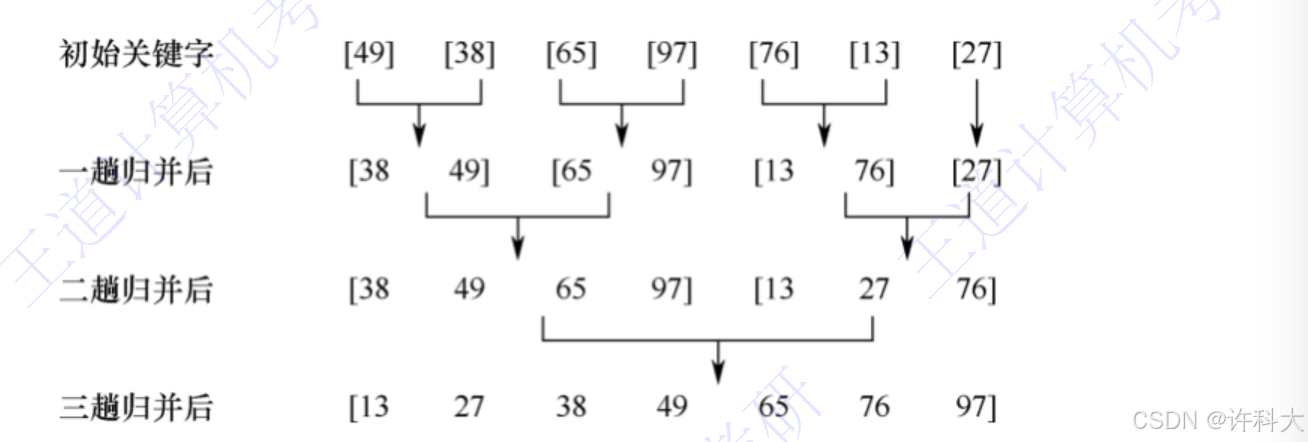
把每个元素归为一组,进行小组内排序,然后再次把两个有序小组合并为一个有序小组,不断进行,最终合并为一个有序数组。
动画示例:Comparison Sorting Visualization
2 归并排序代码实战
归并排序的代码是采用递归思想实现的。首先,最小下标值和最大下标值相加并除以2,得到中间下标值mid,用merge对low到mid排序,然后用merge对mid+1到high排序。当数组的前半部分和后半部分都排好序后,使用merge函数。merge函数的作用是合并来个有序数组,为了提高合并有序数组的效率,在merge函数内定义了B[n]。首先,通过循环吧数组A中从low到high的元素全部复制到B中,这时游标i(遍历的变量称为游标)从low开始,游标j从mid+1开始,谁小就先放入数组A,对其游标加1,并在每轮循环时对数组A的计数游标k加1。
// merge sort
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
#define N 10
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void swap(ElemType &a,ElemType &b){
ElemType temp = a;
a = b;
b = temp;
}
void merge(ElemType t[],int low,int mid,int high){
static ElemType b[N]; // 加static的目的是无论递归调用多少次,都只有一个b[n]
for (int i = low; i <= high; i++) { // 复制元素到b中
b[i] = t[i];
}
int i,j,k;
for (i = low,j = mid + 1,k = i;i <= mid && j <= high;k++) { // 合并两个有序数组
if(b[i] <= b[j]){
t[k] = b[i++];
} else if (b[i] > b[j]){
t[k] = b[j++];
}
}
while (i <= mid){ // 如果有剩余元素,接着放入
t[k++] = b[i++]; // 前一半的有剩余的放入
}
while (j <= high){
t[k++] = b[j++]; // 后一半的有剩余的放入
}
}
void merge_sort_table(ElemType t[],int low,int high){ // 递归分割
int mid ;
if(low<high){
mid = (low+high)/2;
merge_sort_table(t,0,mid); // 排序好前一半
merge_sort_table(t,mid+1,high); // 排序好后一半
merge(t,low,mid,high); // 将两个排序排好的数组合并
}
}
void init_table(SSTable &t,int length){
t.len = length;
t.e = (ElemType*) malloc(sizeof (ElemType) * length); // 申请一块堆空间,当数组来使用
srand(time(NULL)); // 随机数生成,每一次执行代码就会得到随机的10个元素
for (int i = 0; i < t.len; i++) {
t.e[i] = rand()%100; // 生成的是0-99之间
}
}
void print_table(SSTable t){
for (int i = 0; i < t.len; i++) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
init_table(t,10);
print_table(t);
merge_sort_table(t.e,0,t.len-1);
print_table(t);
free(t.e);
return 0;
}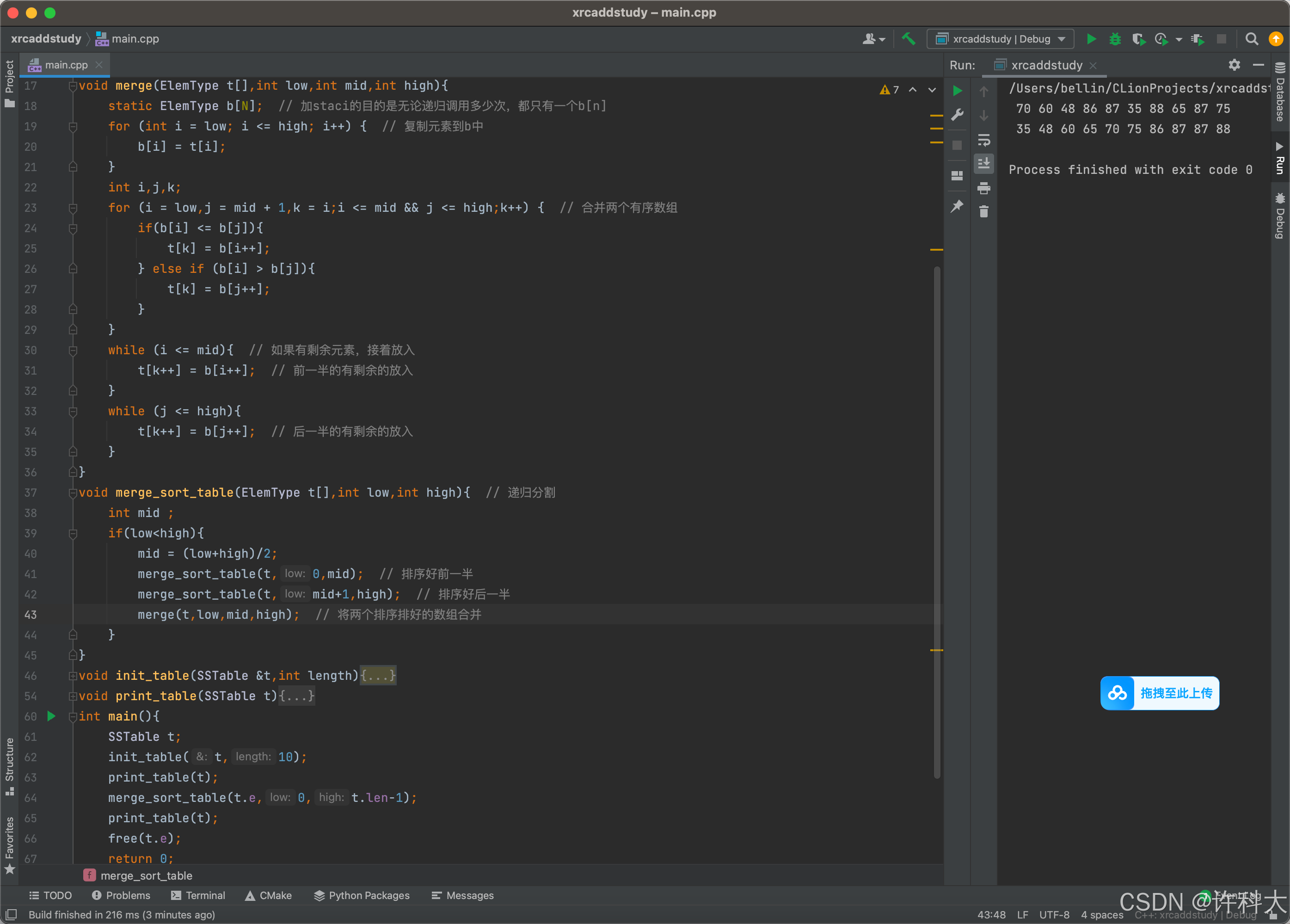
merge函数的递归次数是,merge函数循环了n次,因此时间复杂度是
.
归并排序最好、最坏、平均时间复杂度都是。
归并排序的空间复杂度是O(n),因为使用了数组B,它的大小与A一样,占用n个元素的空间。
3 所有排序算法时间与空间复杂度汇总
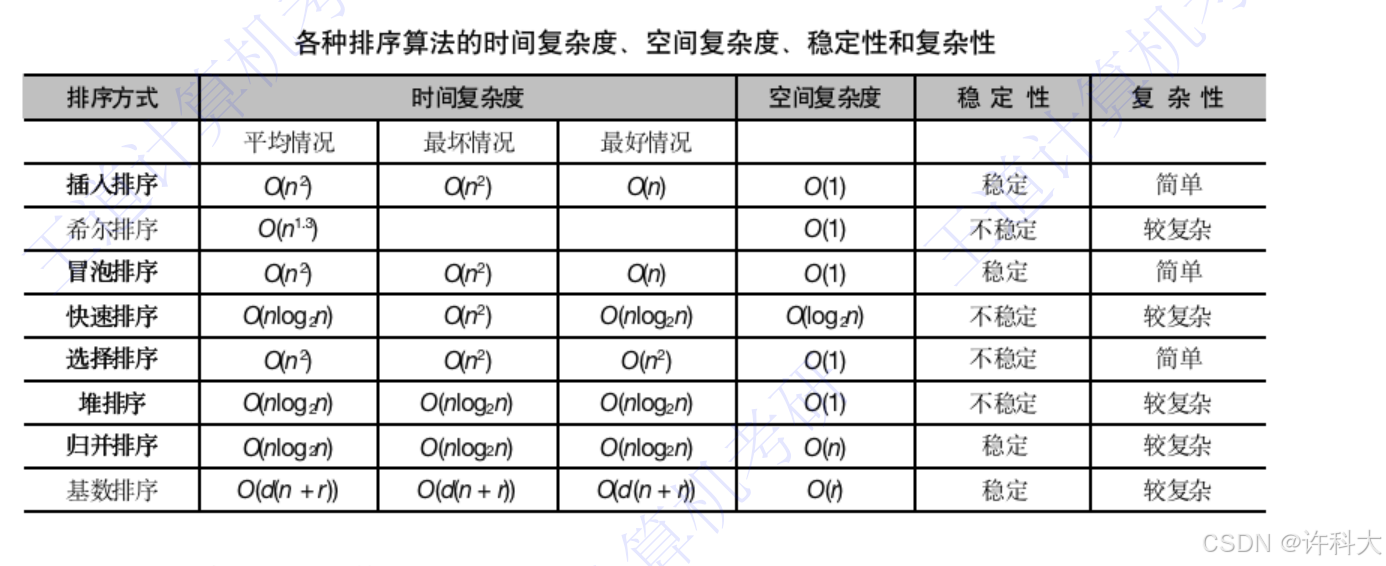
稳定性是指排序前后,相等的元素位置是否会被交换。
复杂性是指代码编写的难度
【17.6 题】
1、归并排序是不断进行二分,最终各自剩余1个元素,自然有序,然后先将每两个元素进行合并,变为有序,然后再将两个小组合并,变为有序,循环往复,直到整个数组有序。
2、49 38 65 97 76 13 27经过第一趟归并后的结果为38 49 65 97 13 76 27。
3、归并排序的时间复杂度最坏、平均、最好都是,空间复杂度是O(n)。
【17 代码题】
1、读取10个整型数据12 63 58 95 41 35 65 0 38 44,然后通过选择排序,堆排序,分别对该组数据进行排序,输出2次有序结果,每个数的输出占3个空格。
// selection sort、heap sort
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void swap(ElemType &a,ElemType &b){
ElemType temp = a;
a = b;
b = temp;
}
void select_sort_table(SSTable &t){
int min; // 记录最小的元素的下标
for (int i = 0; i < t.len - 1; ++i) { // 最多可以为length-2
min = i;
for (int j = i+1; j < t.len; ++j) { // 最多可以为length-1
if (t.e[min] > t.e[j]){
min = j;
}
}
if (min != i){
swap(t.e[i],t.e[min]);
}
}
}
void adjust(SSTable &t,int dad,int tail){
int son = 2*dad + 1; // 左子节点下边
while(son <= tail){
if(son < tail && t.e[son]<t.e[son+1]){ // 如果有右子节点,比较左右子节点的大小
son++;
}
if(t.e[dad] < t.e[son]){ // 比较子节点和父节点的大小
swap(t.e[dad],t.e[son]);
dad = son;
son = 2*dad+1;
} else{
break;
}
}
}
void heap_sort_table(SSTable &t){
for (int i = t.len/2 - 1; i >= 0; i--) { // 建立大根堆
adjust(t,i,t.len-1);
}
swap(t.e[0],t.e[t.len-1]); // 交换顶部(根部)和数组最后一个元素
for (int tail = t.len-2;tail > 0;tail--) {
adjust(t,0,tail); // 剩下元素调整为大根堆
swap(t.e[0],t.e[tail]); // 继续将最大的元素交换到数组末尾
}
}
void init_table(SSTable &t,ElemType num[],int length){
t.len = length;
t.e = (ElemType*) malloc(sizeof (ElemType));
for (int i = 0; i < length; ++i) {
t.e[i] = num[i];
}
}
void print_table(SSTable t){
for (int i = 0; i < t.len; ++i) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
int A[10] = {12,63,58,95,41,35,65,0,38,44};
init_table(t, A,10);
print_table(t);
select_sort_table(t);
print_table(t);
init_table(t, A,10);
print_table(t);
heap_sort_table(t);
print_table(t);
free(t.e);
return 0;
}
2、读取10个整型数据12 63 58 95 41 35 65 0 38 44,然后通过归并排序,对该组数据进行排序,输出有序结果,每个数的输出占3个空格。
// merge sort
#include <stdio.h>
#include <stdlib.h>
#define N 10
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void merge(ElemType num[],int low,int mid,int high){
static ElemType b[N]; // 为了降低操作次数
for (int i = low; i <= high; ++i) { // 赋值元素到b中
b[i] = num[i];
}
int k,n;
for (k = low,n = mid+1;low <= mid && n <= high;k++) { // 合并两个有序数组
if(b[low] <= b[n]){
num[k] = b[low++];
} else if(b[low] > b[n]){
num[k] = b[n++];
}
}
while(low <= mid){ // 如果有剩余元素,接着放入
num[k++] = b[low++];
}
while(n <= high){
num[k++] = b[n++];
}
}
void merge_sort_table(ElemType num[],int low,int high){ // 递归分割
int mid;
if(low < high){
mid = (low + high)/2;
merge_sort_table(num,low,mid);
merge_sort_table(num,mid+1,high);
merge(num,low,mid,high);
}
}
void swap(ElemType &a,ElemType &b){
ElemType temp = a;
a = b;
b = temp;
}
void select_sort_table(SSTable &t){
int min; // 记录最小的元素的下标
for (int i = 0; i < t.len - 1; ++i) { // 最多可以为length-2
min = i;
for (int j = i+1; j < t.len; ++j) { // 最多可以为length-1
if (t.e[min] > t.e[j]){
min = j;
}
}
if (min != i){
swap(t.e[i],t.e[min]);
}
}
}
void adjust(SSTable &t,int dad,int tail){
int son = 2*dad + 1; // 左子节点下边
while(son <= tail){
if(son < tail && t.e[son]<t.e[son+1]){ // 如果有右子节点,比较左右子节点的大小
son++;
}
if(t.e[dad] < t.e[son]){ // 比较子节点和父节点的大小
swap(t.e[dad],t.e[son]);
dad = son;
son = 2*dad+1;
} else{
break;
}
}
}
void heap_sort_table(SSTable &t){
for (int i = t.len/2 - 1; i >= 0; i--) { // 建立大根堆
adjust(t,i,t.len-1);
}
swap(t.e[0],t.e[t.len-1]); // 交换顶部(根部)和数组最后一个元素
for (int tail = t.len-2;tail > 0;tail--) {
adjust(t,0,tail); // 剩下元素调整为大根堆
swap(t.e[0],t.e[tail]); // 继续将最大的元素交换到数组末尾
}
}
void init_table(SSTable &t,ElemType num[],int length){
t.len = length;
t.e = (ElemType*) malloc(sizeof (ElemType));
for (int i = 0; i < length; ++i) {
t.e[i] = num[i];
}
}
void print_table(SSTable t){
for (int i = 0; i < t.len; ++i) {
printf("%3d",t.e[i]);
}
printf("\n");
}
int main(){
SSTable t;
int A[10] = {12,63,58,95,41,35,65,0,38,44};
init_table(t, A,10);
print_table(t);
select_sort_table(t);
print_table(t);
init_table(t, A,10);
print_table(t);
heap_sort_table(t);
print_table(t);
init_table(t,A,10);
print_table(t);
merge_sort_table(t.e,0,t.len-1);
print_table(t);
free(t.e);
return 0;
}
【第18节 排序算法真题实战】
【18.2 2016年43题题目解析】
2016年
43.已知由n(n>=2)个正整数构成的集合A={ak|0<=k<n},将其划分为两个不相交的子集A1和A2,元素个数分别是n1和n2,A1和A2中元素之和分别为S1和S2,设计一个尽可能高效的划分算法,满足|n1-n2|最小且|S1-S2|最大,要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。3)说明你所设计算法的平均时间复杂度和空间复杂度。
答案解析:
1)算法的基本设计思想
由题意知,将最小的n/2个元素放在A1中,其余元素放在A2中,分组结果即可满足题目要求。
仿照快速排序的思想,基于枢轴将n个整数划分为两个子集。根据划分后枢轴所处的位置i分别处理:
1、若i=n/2,则分组完成,算法结束;
2、若i<n/2,则枢轴及之前的所有元素均属于A1,继续对i之后的元素进行划分;
3、若i>n/2,则枢轴及之后的所有元素均属于A2,继续对i之前的元素进行划分。
基于该设计思想实现的算法,无需对全部元素进行排序,其平均时间复杂度是O(n),空间复杂度是O(1)。
动画示例:Comparison Sorting Visualization
【18.3 2016年43题代码实战】
// merge sort
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
#define N 10
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
int set_partition(ElemType t[],int length){
// 快速排序,找中间位置
int low = 0,low0,high = length - 1,high0,flag = 1,mid = length/2-1,temp;
low0 = low;
high0 = high;
while (flag){
temp = t[low]; // 选择枢轴
while (low < high){ //基于枢轴对数据进行划分
while(low < high && t[high] >= temp){
high--;
}
if (low != high) t[low] = t[high];
while (low < high && t[low] <= temp){
low++;
}
if(low != high) t[high] = t[low];
} // end of while(low < high)
t[low] = temp;
if (low == mid){ // 如果枢轴是第n/2个元素,划分成功
flag = 0;
} else if (low < mid){ // 继续划分
low0 = ++low; // low0只是暂存,为下次使用准备,++low后,low比分割值大一
high = high0; // 把上次暂存的high0取出
} else if (low > mid){
low = low0; // 把上次暂存的low0取出
high0 = --high; // high0只是暂存,为下次使用准备
}
}
// 求和。如果n是偶数,就各分一半,如果n是奇数,s2比s1多一个元素
int s1=0,s2=0;
for (int i = 0; i <= mid; i++) {
s1+=t[i];
}
for (int i = mid+1; i <= length-1; i++) {
s2+=t[i];
}
// 求差
return s2-s1;
}
int main(){
int A[10] = {4,1,12,18,7,13,18,16,2,15};
int different = set_partition(A,10);
printf("%d",different);
return 0;
}
【review】
// quick sort
#include <stdio.h>
void print_table(int num[],int length){
for (int i = 0; i < length; ++i) {
printf("%3d",num[i]);
}
printf("\n");
}
int set_partition(int num[],int length){ // 中分,左小右大,利用快速排序算法
int low=0,low0=0,high=length-1,high0=length-1,mid = length/2-1,temp;
while(low < high){
temp = num[low]; // 将低位作为枢轴,进行高低划分
while(low < high && num[high] >= temp){ //高位值比枢轴高 或 相等时,继续遍历
high--;
}
if(low < high){ // 高位元素值比枢轴低,需要覆盖到低位(第一次是覆盖到枢轴原本的位置)
num[low++] = num[high];
}
while(low < high && num[low] <= temp){ // 低位元素值比枢轴低 或 相等时,继续遍历
low++;
}
if(low < high){ // 低位元素值比枢轴低,需要覆盖到高位
num[high--] = num[low];
}
num[low] = temp;
if(low == mid){ // 枢轴是在中心的位置
break;
} else if(low < mid){ // 继续调整数组,寻找中心枢轴,遍历后半部分。需要更新低位,需要重置高位
low0 = ++low;
high = high0;
} else{ // 继续调整数组,寻找中心枢轴,遍历前半部分。需要更新高位,需要重置低位
low = low0;
high0 = --high;
}
}
int s1=0,s2=0;
for (int i = 0; i <= mid; ++i) {
s1+=num[i];
}
for (int i = mid+1; i < length; ++i) {
s2+=num[i];
}
return s2-s1;
}
int main(){
int num[10] = {4,1,12,18,7,13,18,16,2,15};
int diff = set_partition(num,10);
printf("diff = %d\n",diff);
print_table(num,10);
return 0;
}
// 1 2 4 7 12 13 15 16 18 18
1)2)问的考研评分说明
1、本题只需将最大的一半元素与最小的一半元素分组,不需要对所有元素进行全部排序,参考答案基于快速排序思想,采用非递归的方式实现。根据所实现算法的平均时间复杂度给分。
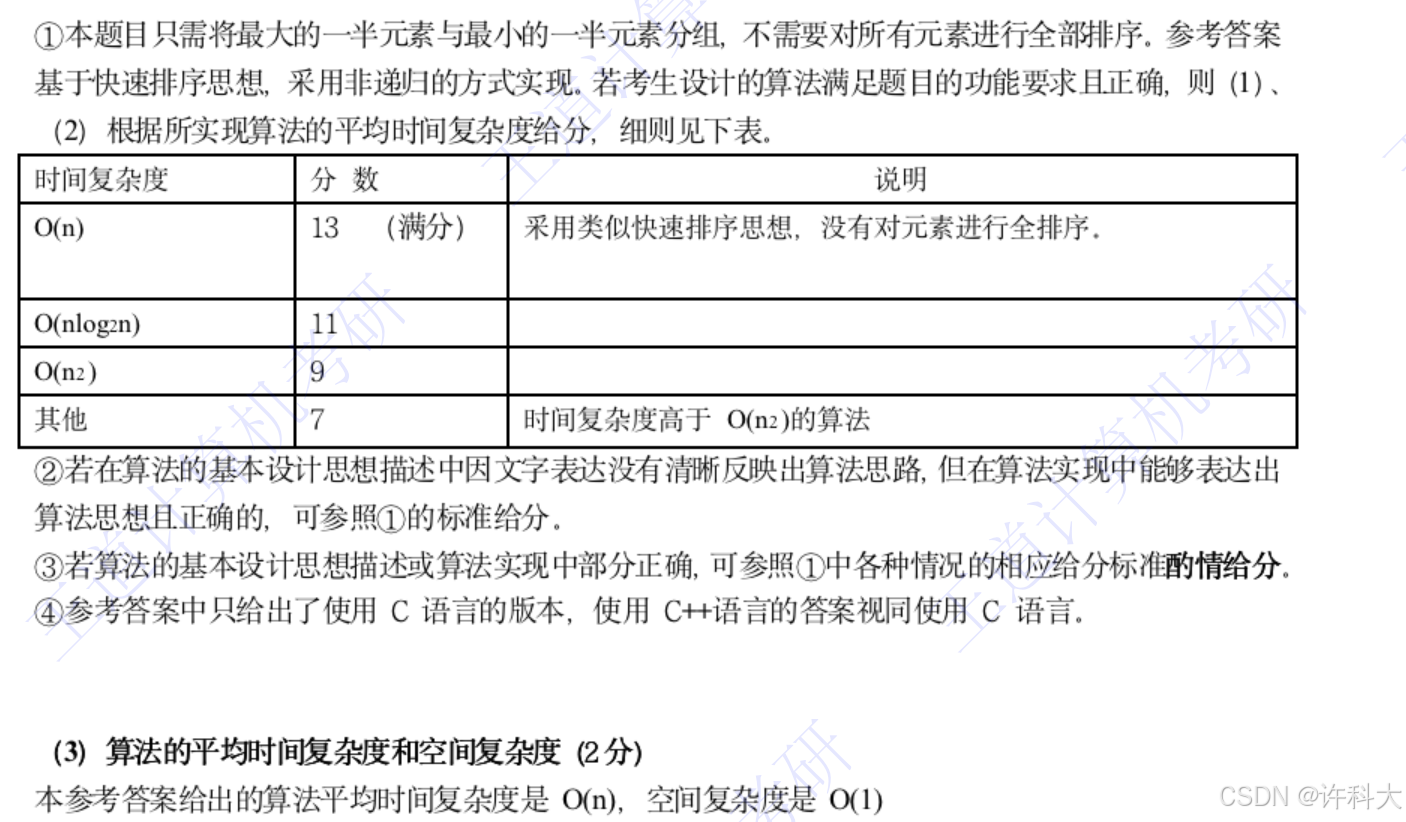
【18.4 2022年42题题目解析】
2022年
42.(10分)现有n(n>=100000)个数保存在一个数组M中,需要查找M中最小的10个数,请回答下列问题。1)设计一个完成上述查找任务的算法,要求平均情况下的比较次数尽可能少,简单描述其算法思想,不需要程序实现。2)说明你所设计的算法平均情况下的时间复杂度和空间复杂度。
答案解析:
方法一:最小值(选择排序思想)
1)算法思想
定义含10个元素的数组A,初始时元素值为该数组类型能表示的最大数MAX。
for M中的每个元素s
if(s < A[9]) 丢弃A[9]并将s按升序插入到A中;(插入排序的算法)
当数据全部扫描完毕,数组A[0]~A[9]保存的即是最小的10个数。
2)时间复杂度:O(n),每次要插入时都是需要对小数组A进行遍历的
空间复杂度:O(1),中间过程额外需要常数个变量。
如果这里将10改为k,则:
时间复杂度:O(nk),需要遍历k次数组。
空间复杂度:O(1),中间过程额外需要常数个变量。
方法二:堆(堆排序思想)
1)算法思想
定义含10个元素的大根堆H,元素均为该堆元素类型能表示的最大数MAX。
for M中的每个元素s
if(s < H的堆顶元素) 删除堆顶元素并将s插入到H中;
当数据全部扫描完毕,堆H中保存的即是最小的10个数。
2)算法平均情况下的时间复杂度是O(n),空间复杂度是O(1)。
进一步解析:
先用A[0:9]原地建立大顶堆(注意:这里不能用顶堆),遍历A[10:n],每个元素A[i]逐一和堆顶元素A[0]进行比较,其中11<=i<=n,如果A[i]大于等于堆顶元素A[0],不进行任何操作,如果该元素小于堆顶元素A[0],那么就删除堆顶元素,将该元素放入堆顶,即最后堆A[0:9]中留存的元素即为最小的10个数。
方法三:快排
通过快速排序,分割思想,第一次直到n/2位置,再次partition得到n/4,最终缩小为10个,就拿到了最小的10个元素,遍历的平均次数是n+n/2+n/4+...1,次数为2n,因此时间复杂度为O(n)。由于不进行快排,只是记录剩余部分的起始和结束,因此空间复杂度是O(1)。
【18.5 2022年42题代码实战】
堆(堆排序思想)
// merge sort
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 20
typedef int ElemType;
typedef struct {
ElemType *e; // 存储元素的起始地址
int len; // 元素个数
}SSTable;
void print_table(SSTable t){
for (int i = 0; i < t.len; ++i) {
printf("%3d",t.e[i]);
}
printf("\n");
}
void swap(ElemType &a,ElemType &b){
ElemType temp = a;
a = b;
b = temp;
}
void adjust(SSTable &t,int dad,int tail){
int son = 2*dad + 1; // 左子节点
while(son <= tail){
if(son < tail && t.e[son] < t.e[son + 1]){ // 如果有右子节点,比较左右子节点大小
son++;
}
if (t.e[dad] < t.e[son]){ // 比较父节点和子节点大小
swap(t.e[dad],t.e[son]);
dad = son; // 子节点作为父节点,继续判断下一棵树是否符合大根堆
son = 2 * dad + 1;
} else{
break;
}
}
}
void heap_sort_table(SSTable &t,int length){
for (int i = length/2-1; i >= 0; i--) { // 先对前10个元素建立大根堆
adjust(t,i,length - 1);
}
// print_table(t);
for (int i = 10; i < t.len; ++i) { // 剩余的元素,小于堆顶,则放入根
if(t.e[i] < t.e[0]){
t.e[0] = t.e[i];
adjust(t,0,9); // 继续调整大根堆
// print_table(t);
}
}
}
void init_table(SSTable &t){
t.len = N;
t.e = (ElemType*) malloc(sizeof (ElemType) * t.len);
srand(time(NULL));
for (int i = 0; i < t.len; ++i){
t.e[i] = rand()%100;
}
}
int main(){
SSTable t;
// init_table(t);
ElemType num[20] = {39,93,84,43,99,27,8,43,6,36,40,25,57,85,24,69,20,52,27,2};
t.len = 20;
t.e = (ElemType*) malloc(sizeof (ElemType) * t.len);
for (int i = 0; i < 20; ++i){
t.e[i] = num[i];
}
print_table(t);
heap_sort_table(t,10);
print_table(t);
free(t.e);
return 0;
}
【TODO】
只需要新建一个大小为10的树。不需要新建大小为n的树。
【TODO】
需熟练:
14.6 二叉树的层序遍历
14.7 2014年41题真题
15.6 二叉排序树删除
————————————
仅用于本人学习
来源:网络


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









