




 本文介绍了深度学习中的线性模型局限,探讨了分段线性模型(PiecewiseLinear)和如何通过sigmoid函数逼近,以及神经元、激活函数、隐藏层等概念。还提及了优化方法(如梯度下降)和避免过拟合的重要性,预示了下节课将讲解反向传播。
本文介绍了深度学习中的线性模型局限,探讨了分段线性模型(PiecewiseLinear)和如何通过sigmoid函数逼近,以及神经元、激活函数、隐藏层等概念。还提及了优化方法(如梯度下降)和避免过拟合的重要性,预示了下节课将讲解反向传播。
通过这节课的学习,应该会对什么是深度学习有一个深刻的认识
上节课我们学到的是线性模型y = wx +b 这节课一上来先告诉我们这种线性模型存在很大的限制,比如实际情况长红线这样:
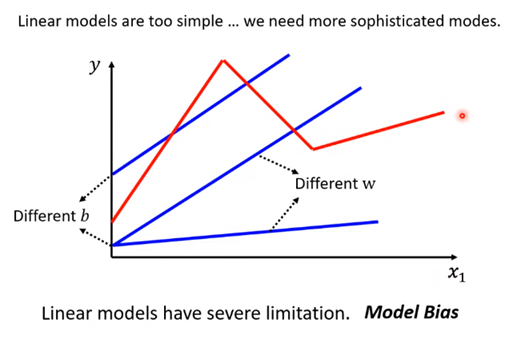
这种限制,我们有专业术语:Model Bias (注意 这个bias和b指代的bias是不太一样的)
我们把上图中的红色线称之为**Piecewise Linear (分段线性)**模型
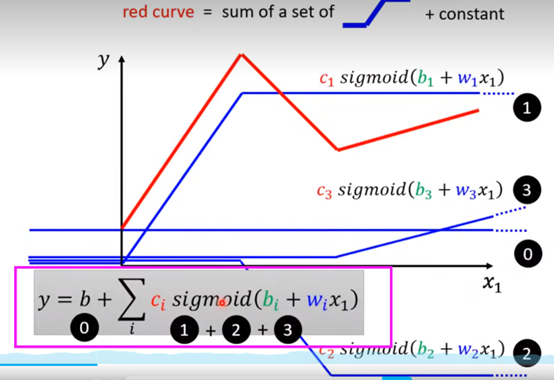
观察上面的那条红线,它其实的组成是:

红色曲线 = 常量 + 多个蓝色的折线(这个折线后面会讲是什么东东)
举个例子:如图所示 ,红线在第一个转折点是0号蓝线+1号蓝线组成;在第二个转折点是0号蓝线+1号蓝线+2号蓝线组成的,第三个转折点就再加一个蓝线(0号蓝线+1号蓝线+2号蓝线+3号蓝线)
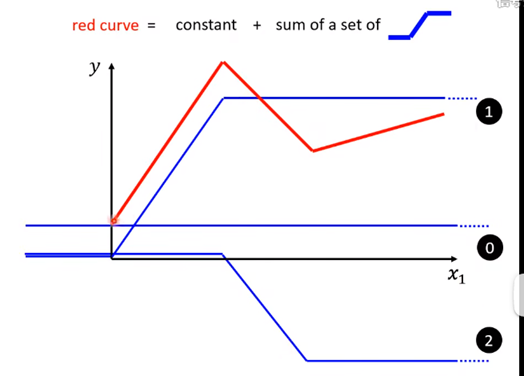
所以说,存在公式:
All Piecewise Linear Curves = constant + sum of a set of function
所有的分段线性曲线 = 常量+多个函数

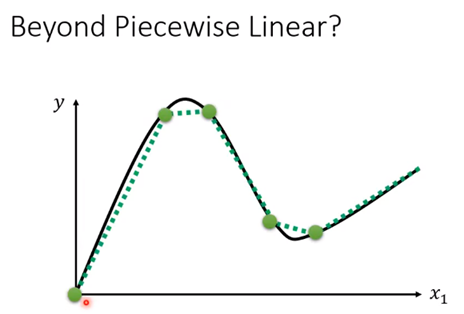
就算这个模型不是分段线性的,而是像下图这样圆滑的,也可以通过取点,【化曲为直】,逼近这个模型,也依旧符合上面的公式:
那么蓝色折线要怎么用数学式子表示呢?
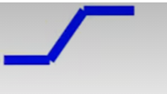
上面的蓝色的折线叫做 hard sigmoid
hard sigmoid 可以由sigmoid函数逼近的,如图所示:
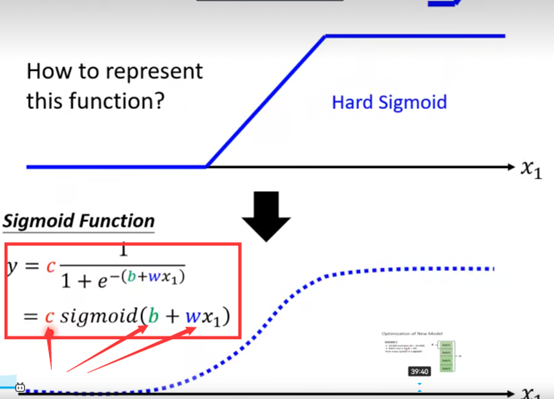
sigmoid函数的表达式如图上PPT所示,通过改变参数c,b,w,可以形成不同的sigmoid函数,去逼近不同的hard sigmoid,这些hard sigmoid可以去逼近不同的piecewise linear(分段线性)的函数,而不同的分段线性函数呢,又可以拿来近似各种不同的连续函数。【套娃】
改变w—改变函数斜率
改变b—左右移动sigmoid函数
改变c—改变函数高度
回到最前面那个红线,我们可以把那个红线模型写成如下形式:
到此为止,我们得到了一大升级,将原本存在Model Bias的线性模型变成了分段线性:
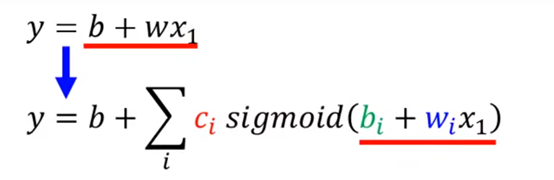
但是这个里面只有一个feature(特征),即那个i
我们可以有多个feature,比如一个月里每一天的播放量,因此再引入一个变量j:
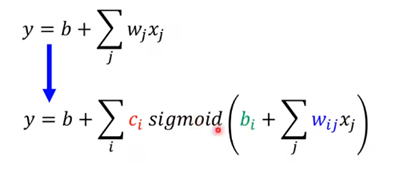
上面式子中,代入预测视频播放量的场景,则i代表不同的蓝线,j代表不同的天数
由上面的式子,最终我们会得到这样一个公式:【这个公式和上面那个是同一个东西】
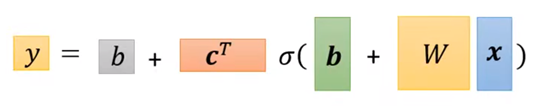
下面是它的推导过程,有需要再仔细推一下,不然直接跳过:
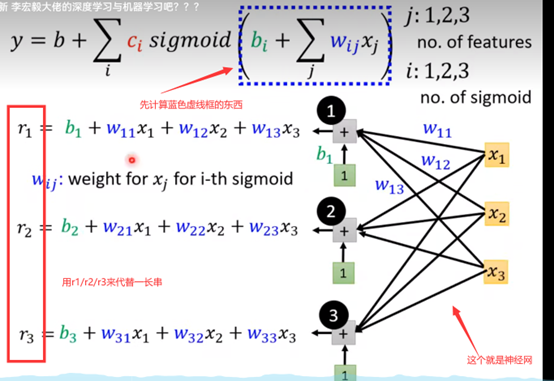
这里的r1/r2/r3可以写成矩阵的形式:

然后r经过sigmoid 记作:
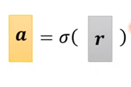
因此最后用向量矩阵的形式表示就能得到:
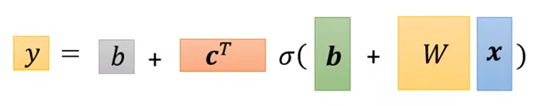
在上面那个向量式中,x是所谓feature,而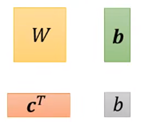
这些都是未知变量,我们可以再变换一下形式:
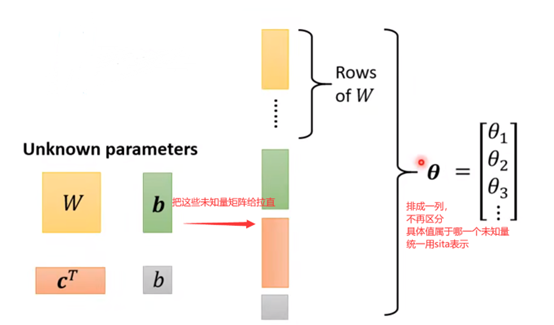
从上面,我们有了新的model,那么对应的Loss会不会有什么不同呀?(没有本质不同)
回到上一节课关于Loss的定义,Loss是变量的函数,所以这里Loss就是θ的函数
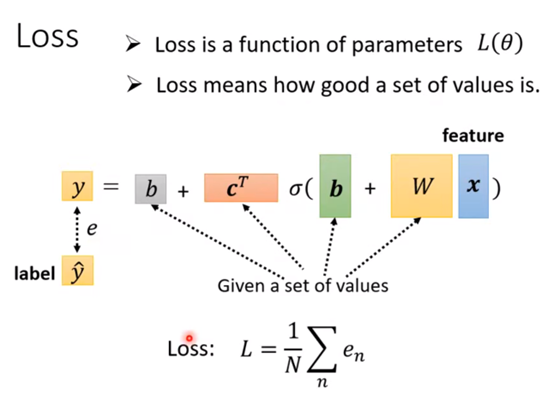
如上图,Loss可以这么表达。
最后是新模型的优化
上一节课针对前面线性模型,李宏毅老师提出的优化Gradient Decent,在这里其实也是一样适用的:(如下图)

什么是batch 什么是epoch :
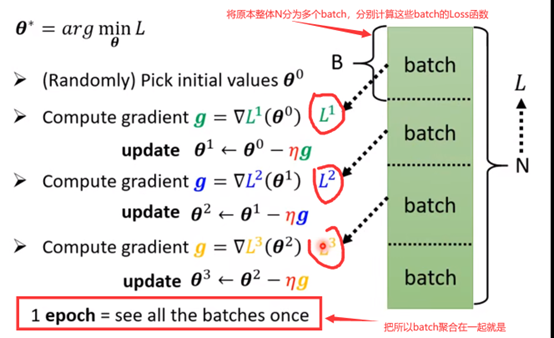
注意上面的update和epoch,都是经常会听到的词汇,这两个是不一样的东西。
每更新一次参数 叫做update
把所有batch都看过一遍,就叫做一个epoch
batch-size 就是你自己设定的,你设定一个batch是多大
(比如N=1000,你设定batch-size为100,那么就有10个batch,所以都更新一轮是10个update,所以1epoch是10update)
sigmoid ReLu(老师介绍的一种新的激活函数)
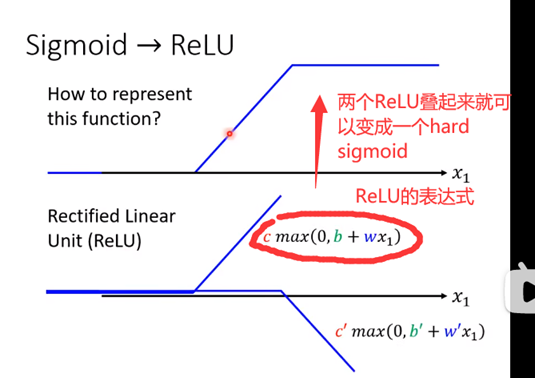
注意观察图上ReLU的表达式和长得样子
一个hard sigmoid得要两个ReLU才能合起来,因此前面推来的用sigmoid函数表述 需要变通一下:
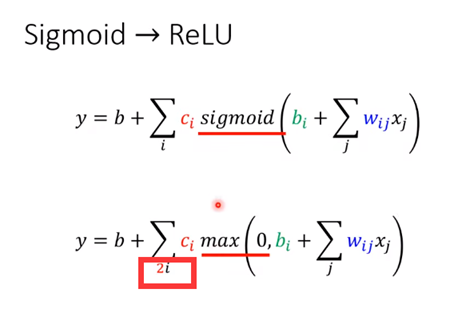
要两倍
什么是activation function(激活函数)
像上面的sigmoid和ReLU
我们在机器学习中,都叫他们 activation function (激活函数)
什么是神经元
什么是神经网络
什么是hidden layer
什么是深度学习?
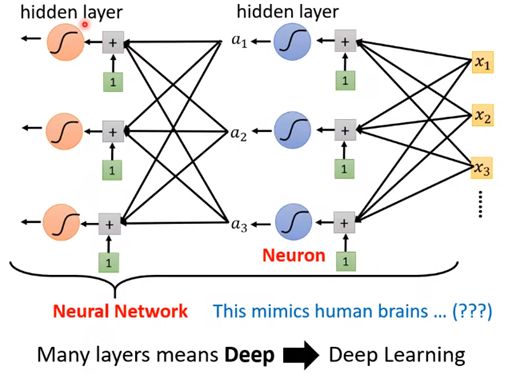
你看 这里的每一个激活函数都像一个神经元,多排神经元构成神经网络
后来因为神经网络在89年代被搞臭了,如果写神经网络论文就会被打下(玩笑话)
于是换了个名字,将每一排神经元(Neurol)称为hidden layer
有很多layer我们就叫做deep
这整套技术,我们就叫做------deep learning(深度学习)
后来人们就把神经网络越叠加叠深
那是不是神经网络层越多越好呢?
不是,存在overfitting(过拟合)

下一课——反向传播

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









