







 本文探讨了如何使用GMM和神经网络评估GAN生成数据的质量,介绍了InceptionScore方法,强调了多样性和清晰度的重要性。同时,讨论了为何GAN生成的是独特而非数据库内的样本,并提到了Mini-batch Discrimination和评估GAN生成数据真实性的挑战。
本文探讨了如何使用GMM和神经网络评估GAN生成数据的质量,介绍了InceptionScore方法,强调了多样性和清晰度的重要性。同时,讨论了为何GAN生成的是独特而非数据库内的样本,并提到了Mini-batch Discrimination和评估GAN生成数据真实性的挑战。
最生成数据进行评估可以人来看,但是需要一些客观的方法。
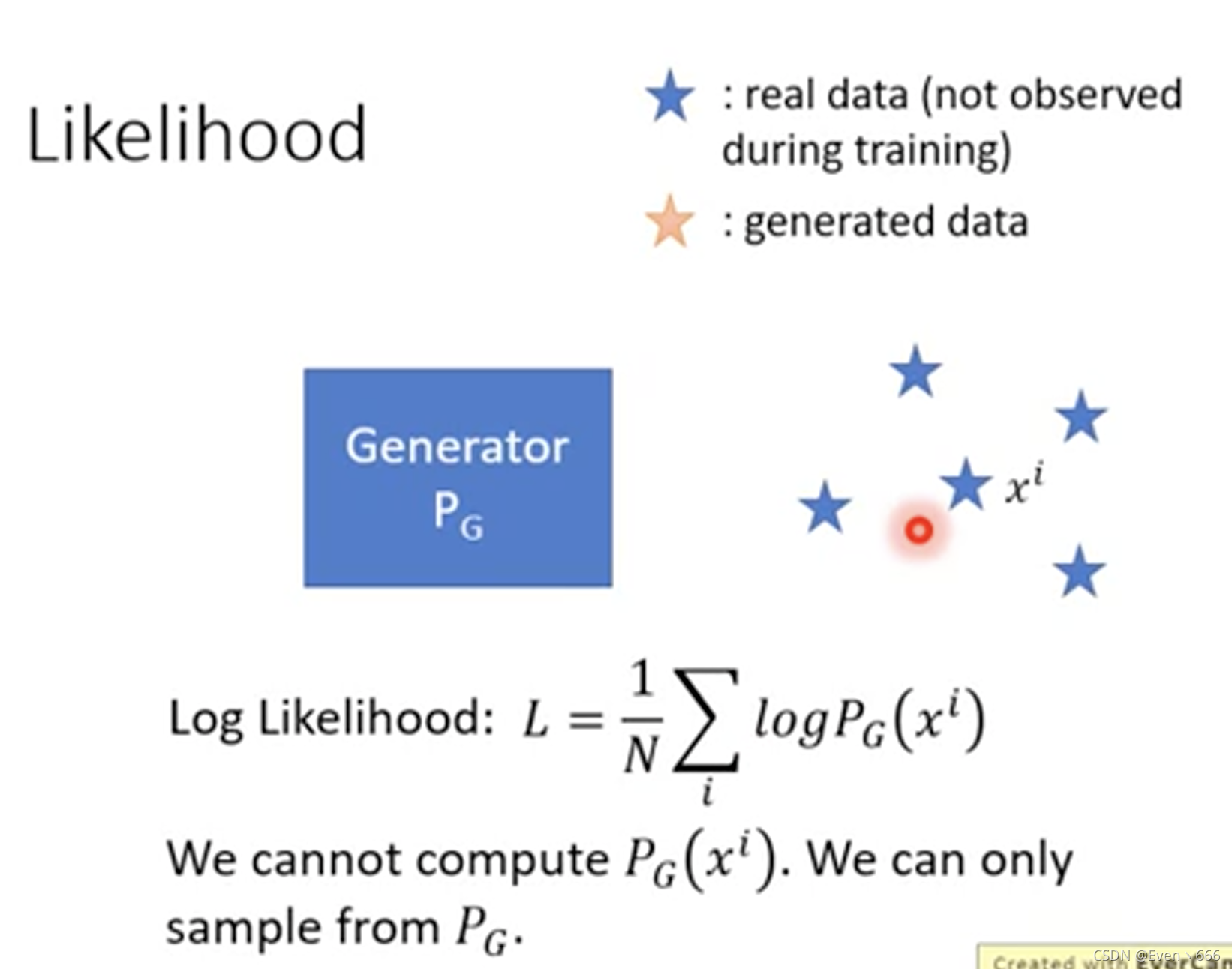
传统的方法可以使用likelihood,但是使用GAN,我们无法计算概率。
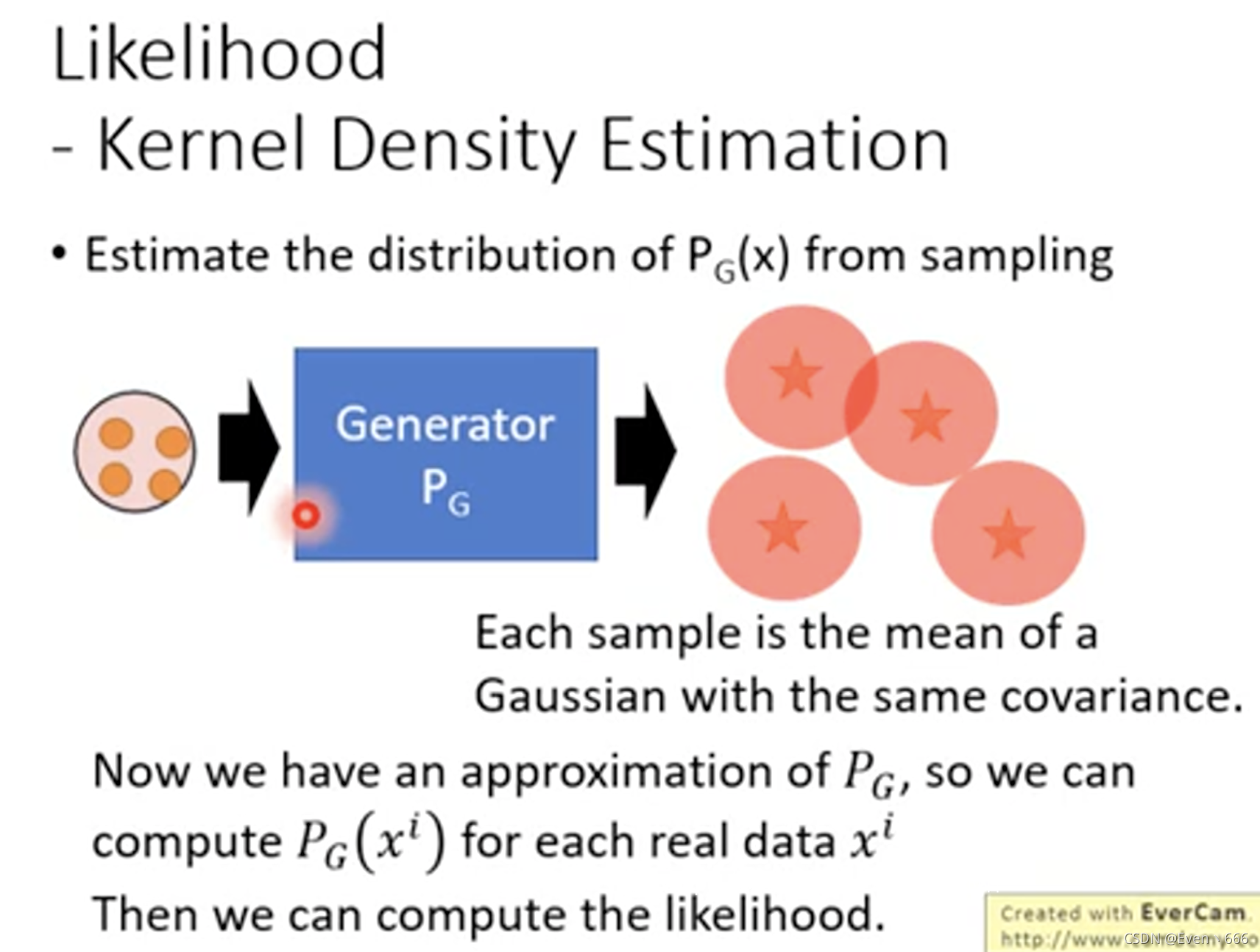
我们可以用generator来生成多组数据,用GMM模型来拟合生成的数据,可以用最大似然来估计参数,进而得到概率。

一个较客观的评估方法是:
拿一个train好的神经网络,拿一个image classifier,如果输出概率越高,可能说明产生的图片足够清晰。
但是上述方法可能是不够的,比如我们训练的Generator只能生成一张同样的图,这不是我们想要的,因此我们引入diverse。
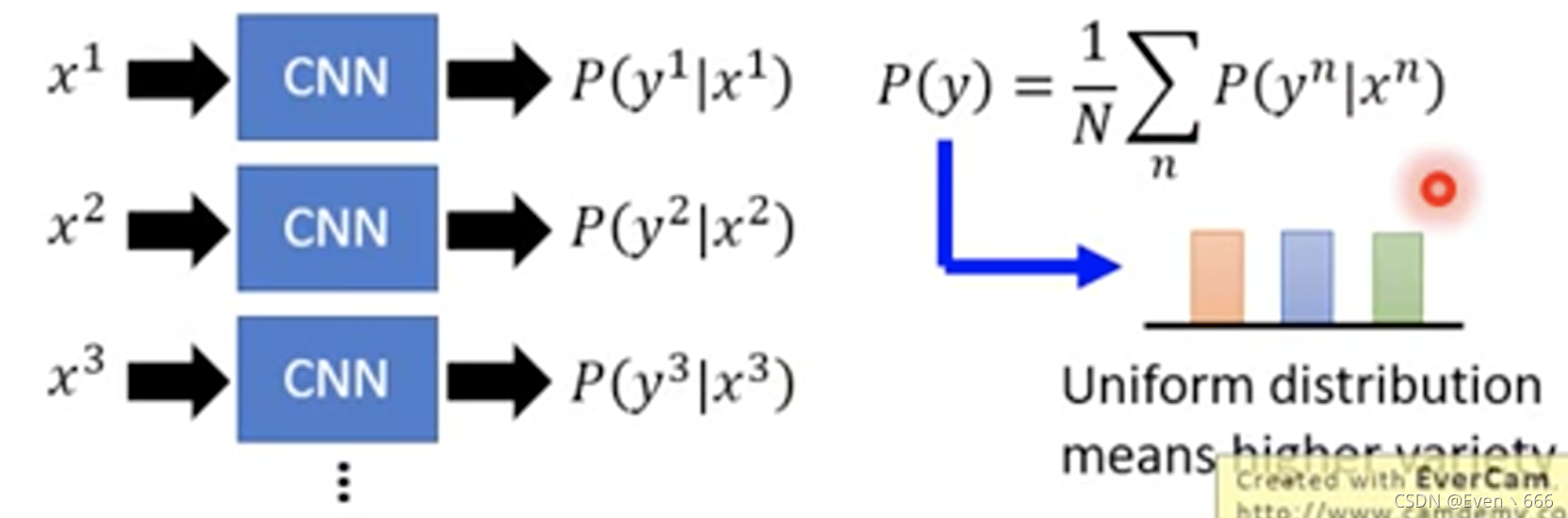
将生成的多张图片通过CNN,将CNN输出的分布做一下平均,如果平均后的分布很uniform,说明生成的数据是diverse的。
如果某个class足够多,说明generator倾向于产生这一个class。
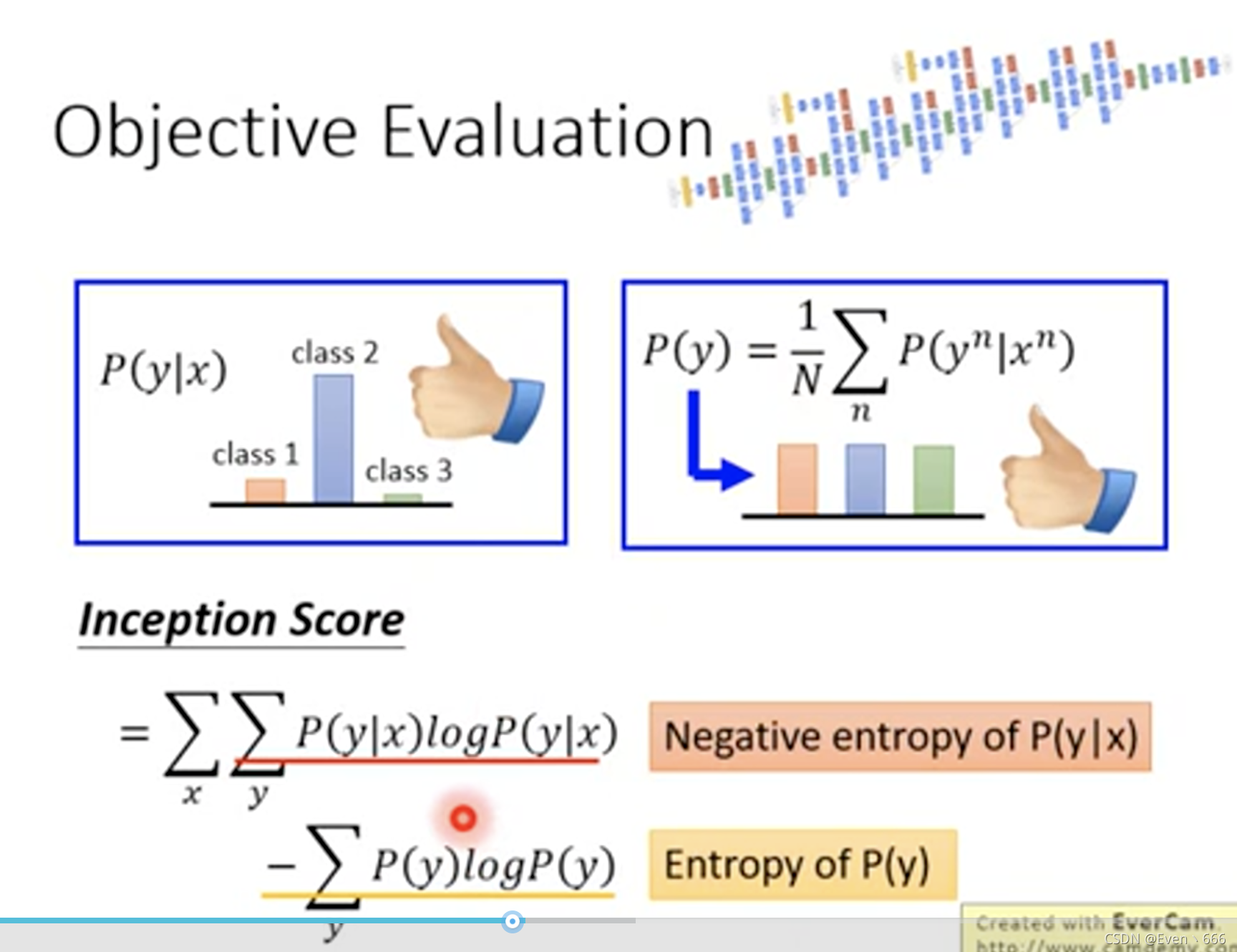
因此有了以上inception score,因为它是在inception net中进行的,所以叫做inception score。
左图中分布越sharp越好,因为越sharp说明分类效果越好,因此左项应该越大;有图中的分布越smooth越好,因此entropy越大越好。
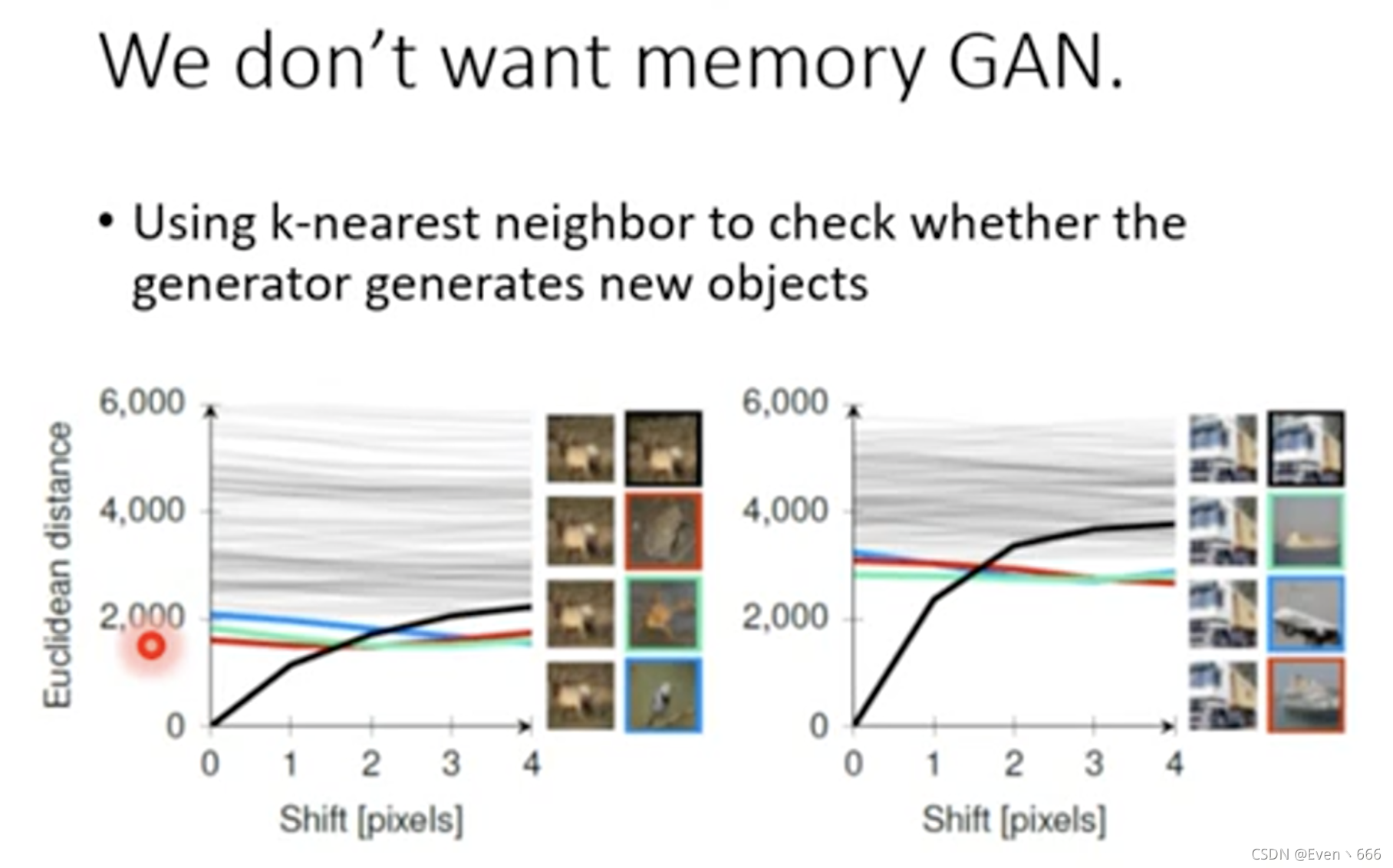
还有一个问题,we don’t want memory GAN
我们的GAN生成的不是database中存在的,如果存在的话我们直接sample就行,为啥还需要GAN呢?
有人提出使用L1和L2相似度,但是这也是不可行的。


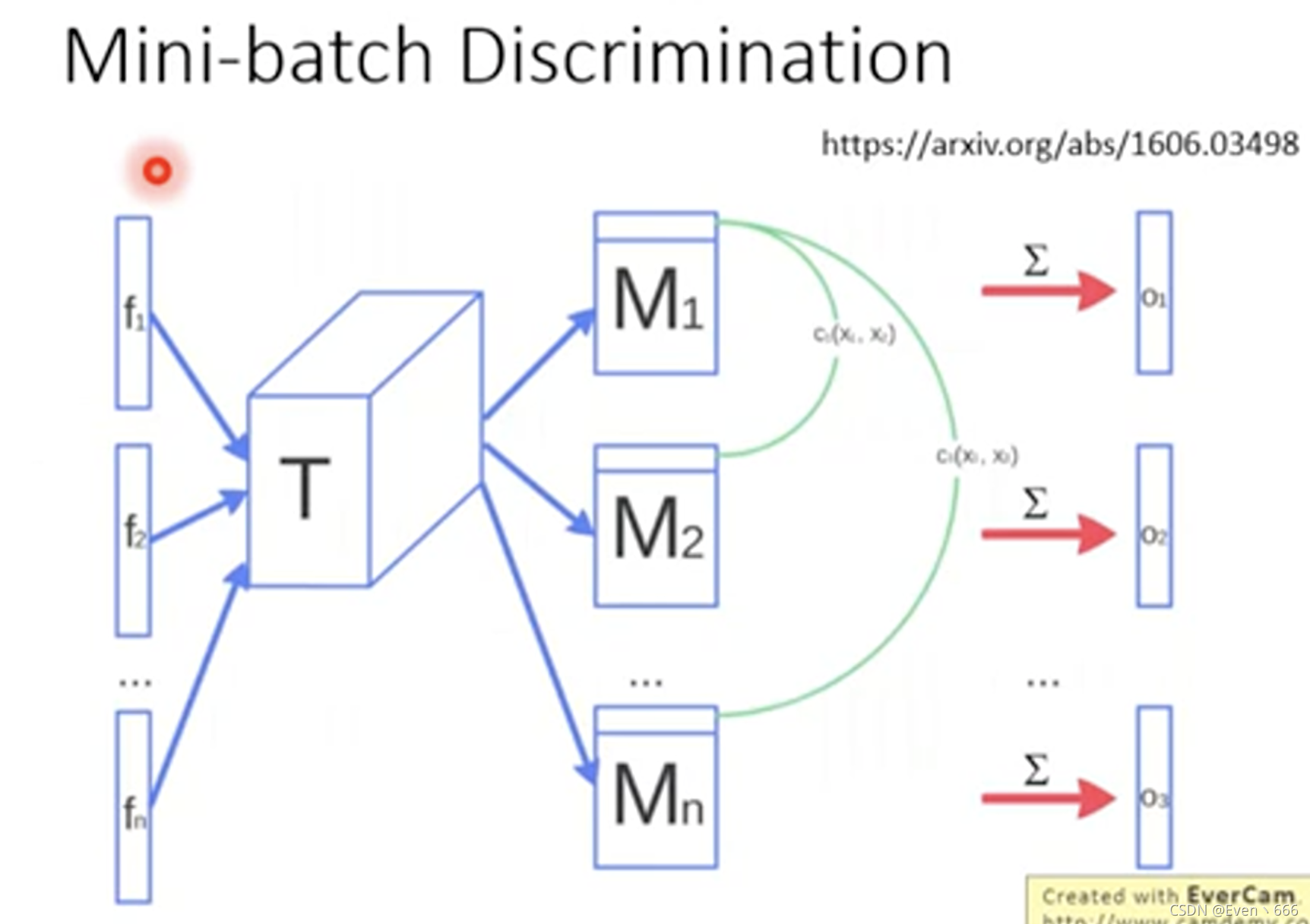
mini-batch discrimination一次不放入一张图,一次放入一把图,这样还可以判别相似度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









