







聚类是一种无监督学习算法。
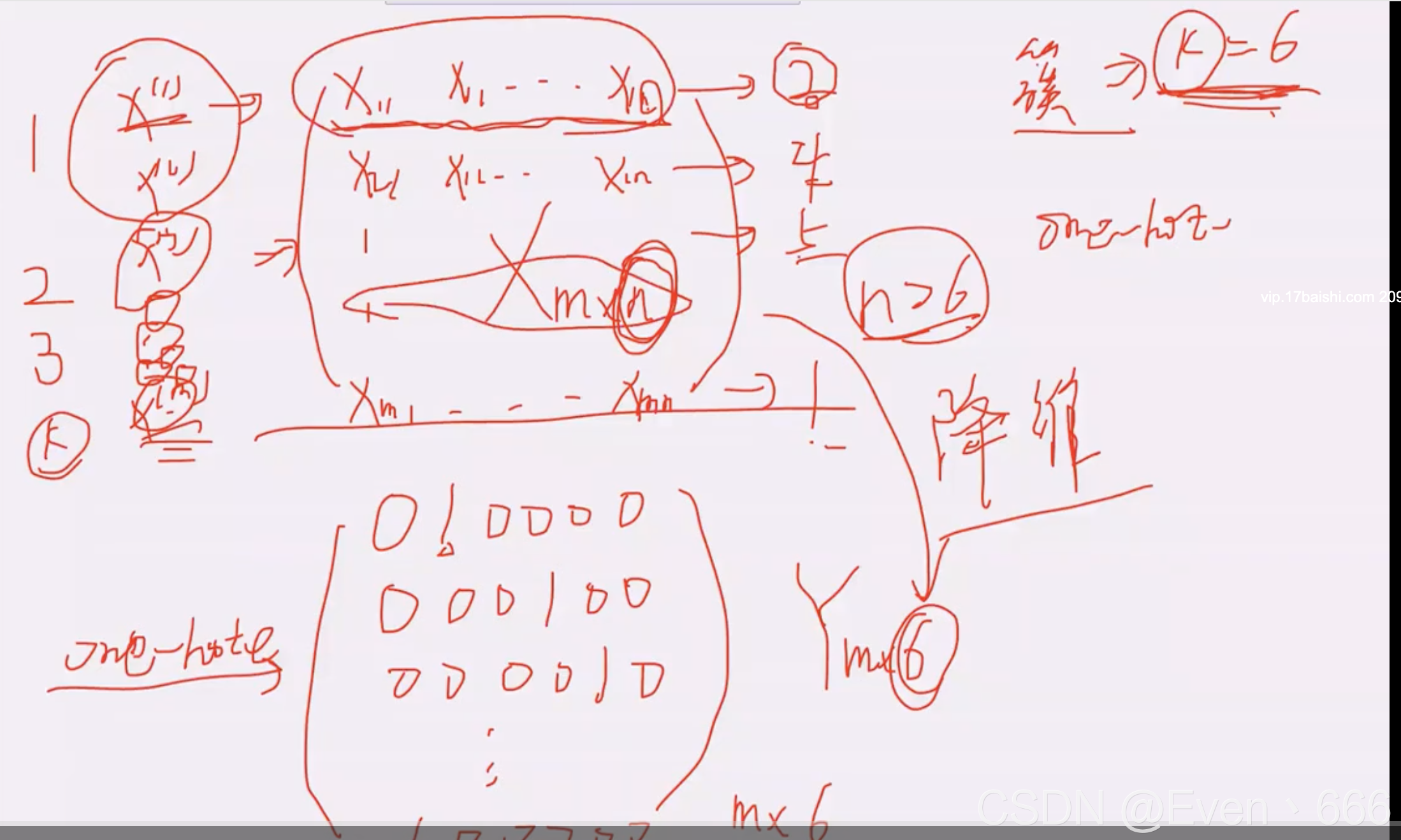
输入x为mn维,通过聚类聚为6簇,使得输出为m6维。有种降维的感觉。

1.相似度
因为聚类是通过样本间的联系来分成多个簇,所以要进行相似度的度量。



2、kmeans




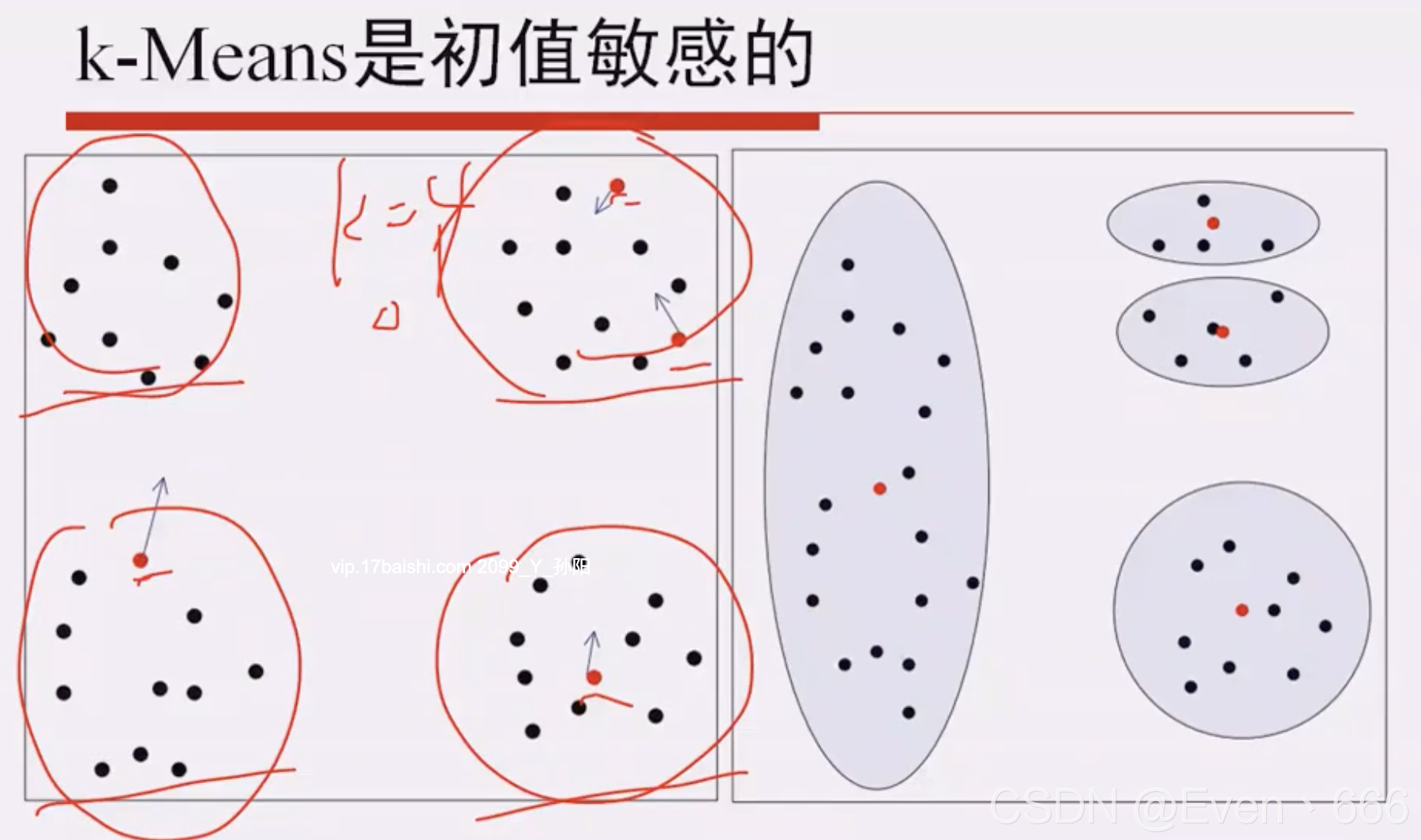
改进
方法一:
计算一下四个簇的均值,MSE;如图,其中两个簇的MSE会比较小,均值会比较接近,说明这两个簇距离比较近,应该分为一个簇。同样地,第一个簇MSE比较大,应该分为两个簇。因此在最左边的簇中重新随机选取两个点进行计算,右边两个比较近的簇随机选取一个点进行计算。
即二分kmeans
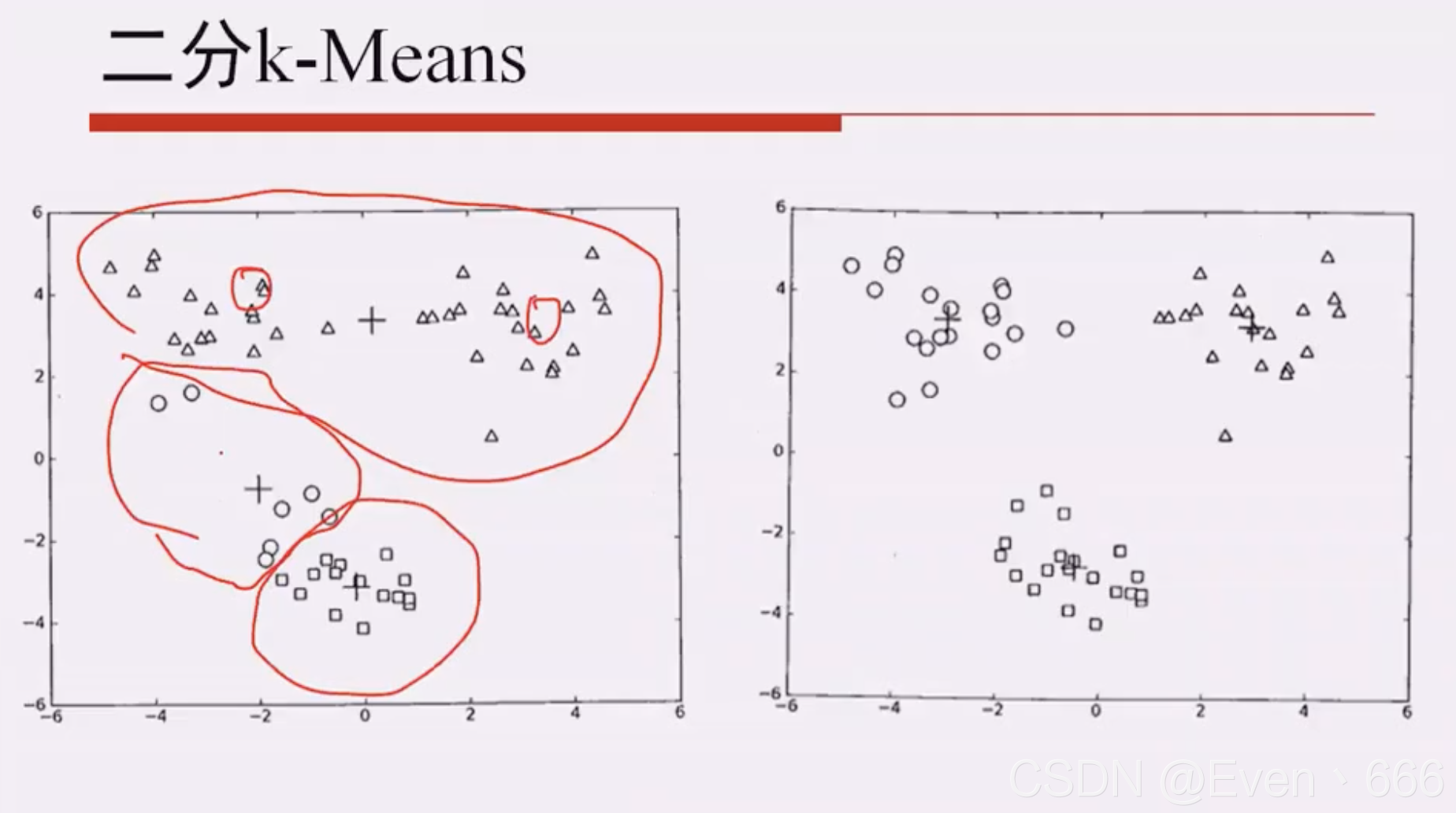
方法二:
kmeans++
先选择一个中心点,计算所有点到该点的距离,然后将得到的距离进行归一化(概率),选择概率最大的点,可以理解为距离最远的点。

推导的时候可以理解为k簇方差相同的高斯分布,求最大似然。



公式中H为熵。可以类比precision和recall




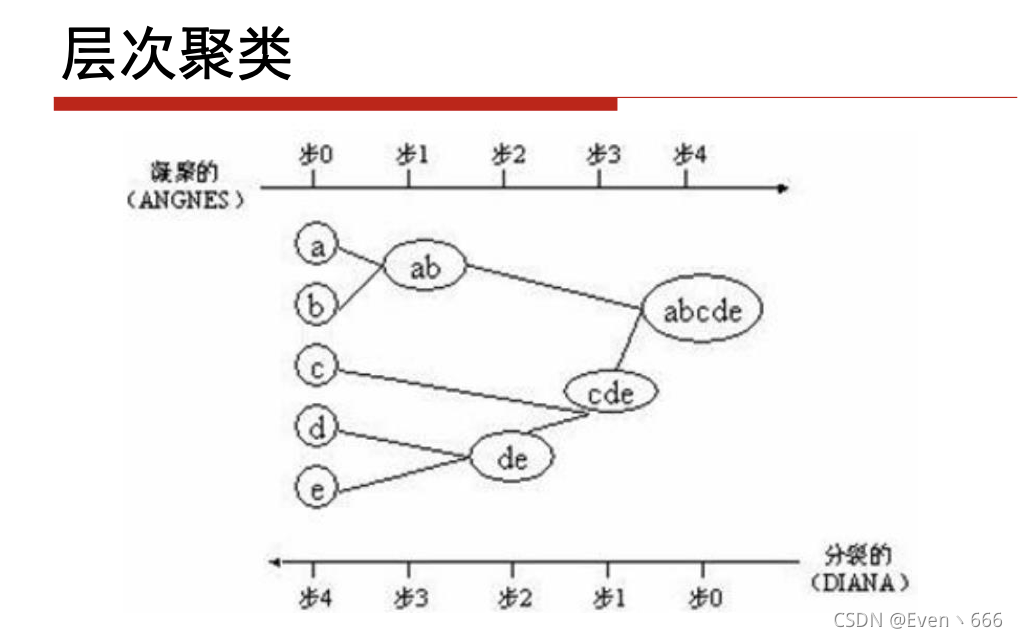
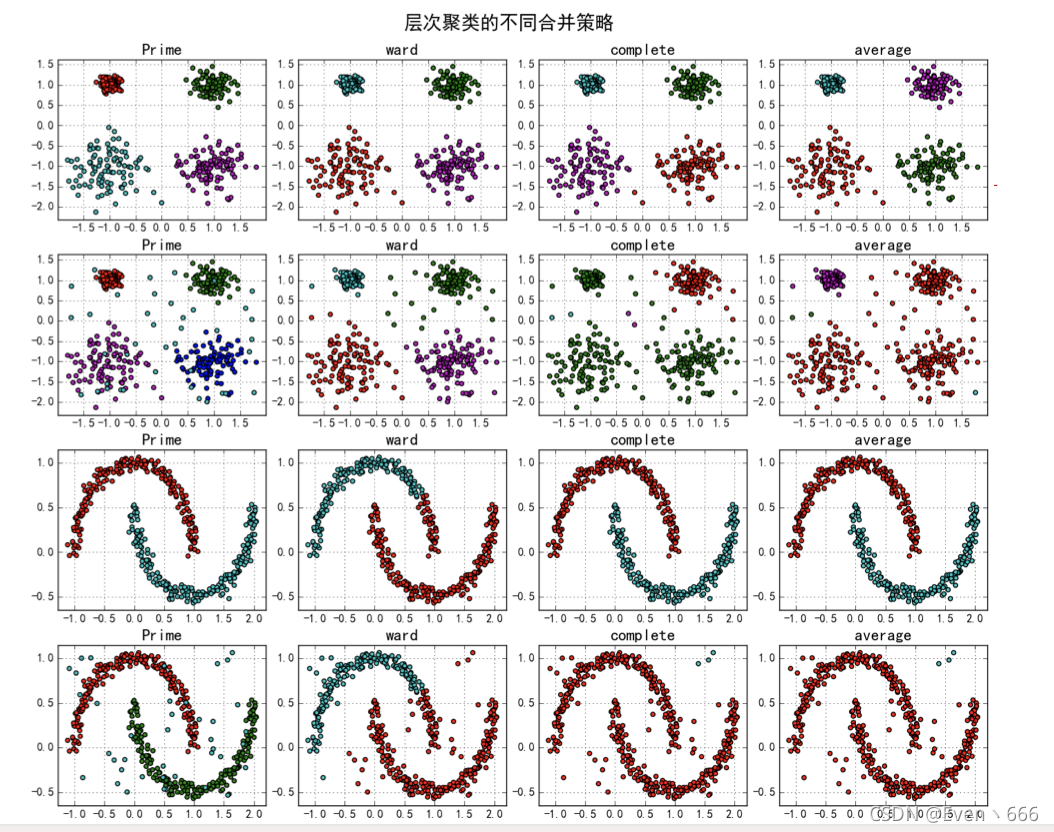
3.层次聚类方法



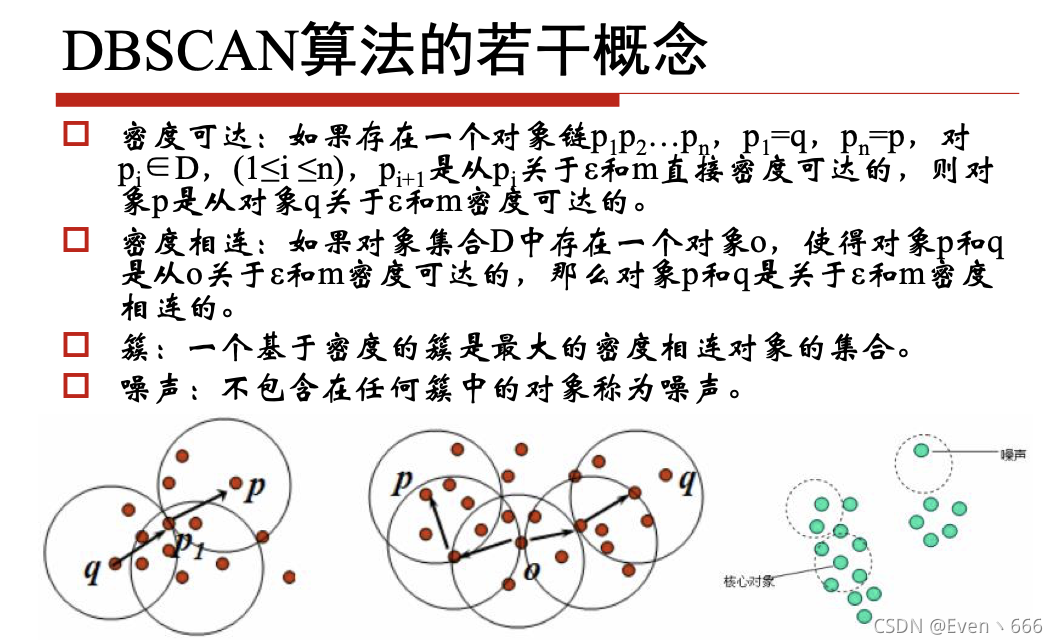
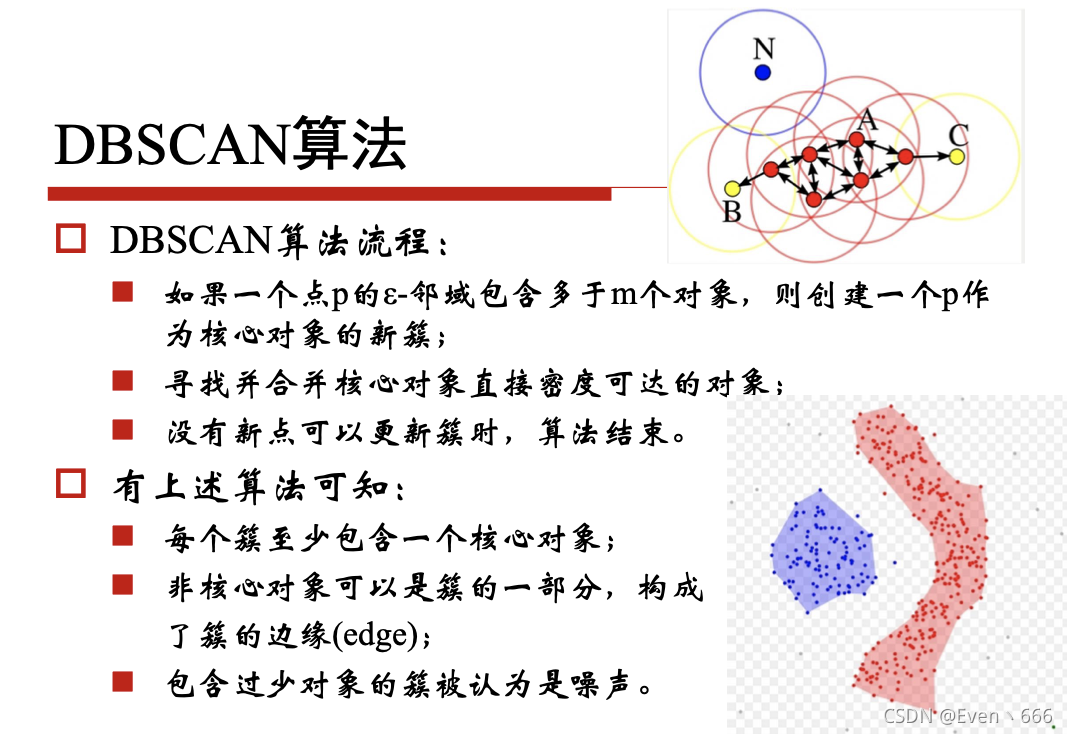
4、DBSCAN



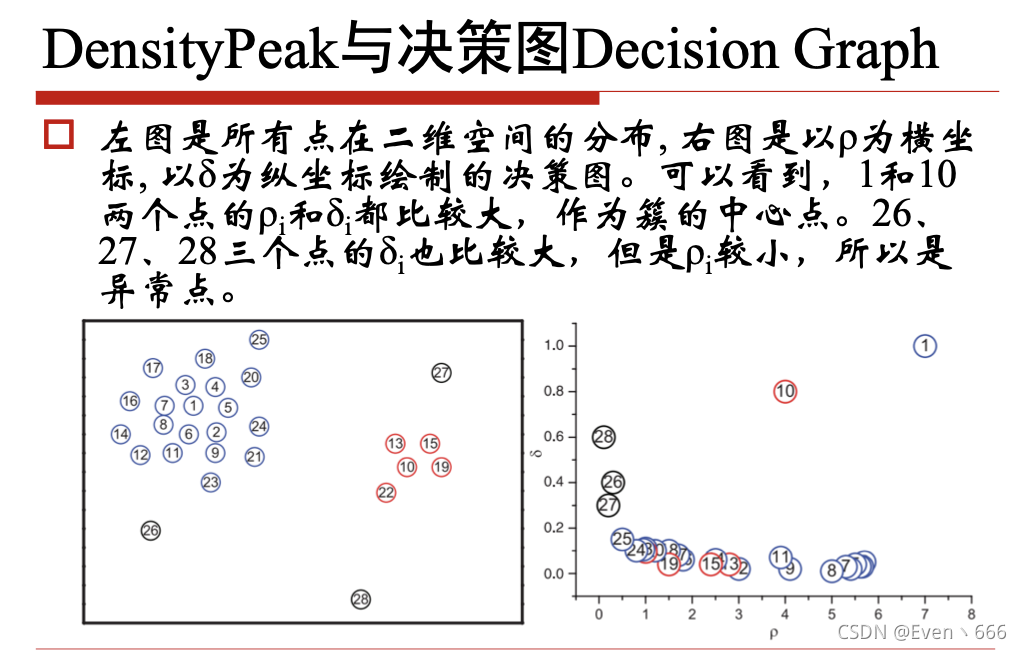
5、密度最大值聚类





6、谱聚类













7、标签传递算法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









