







第四章 分布式文件系统 HDFS
一、分布式文件系统
1.分布式文件系统
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
2.特点
Ø 是一种允许文件通过网络在多台主机上分享的文件系统,可让多台机器上的多用户分享文件和存储空间。
Ø 通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
Ø 容错。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
Ø 适用于一次写入多次查询的情况,不支持并发写情况,不合适小文件的保存。
二、HDFS概述
1.HDFS简介
Hadoop分布式文件系统(HDFS)是一种旨在商品硬件上运行的分布式文件系统。它与现有的分布式文件系统有很多相似之处。但是,与其他分布式文件系统的区别很明显。HDFS具有高度的容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序。HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。HDFS最初是作为Apache Nutch Web搜索引擎项目的基础结构而构建的。HDFS是Apache Hadoop Core项目的一部分。
HDFS****的设想和目标:
Ø 常态的硬件错误
Ø 海量数据集
Ø 流式访问需求
Ø 一致性的困难
Ø 分布式计算的支持(数据在哪里,计算就在哪里)
Ø 平台移植的困难
2.HDFS架构
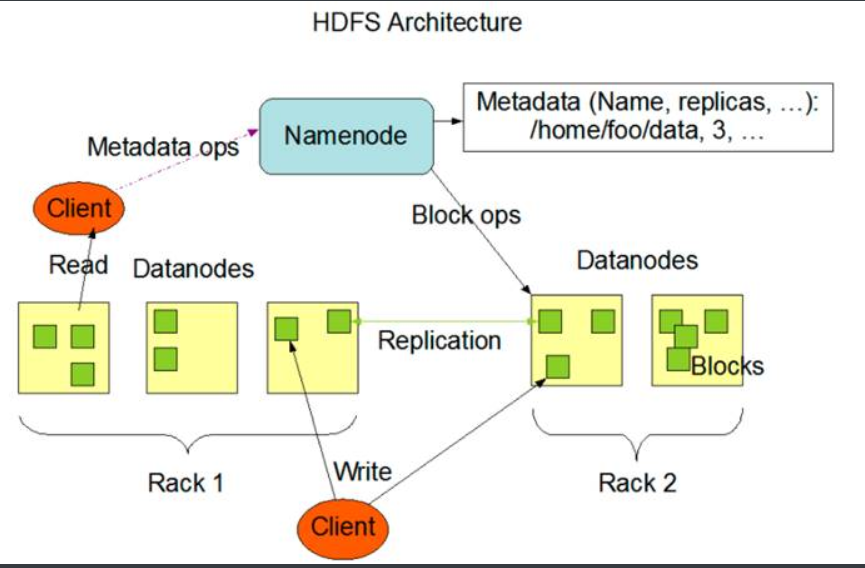
**HDFS****具有主/****从(master/slave)**体系架构。
(1) Client**(客户端):**
HDFS文件系统的使用者,进行读写操作。
(2**)NameNode****(主节点):**
Ø 整个HDFS集群的协调者,负责文件系统命名空间和负责客户端的请求
Ø 负责维护元数据信息(抽象的目录树,文件名和数据块的映射,DataNode和数据块的关系)
Ø 负责系统状态监控与调度
(3**)DataNode****(从节点):**
Ø 负责处理来自文件系统客户端的读写请求。
Ø 存储文件的数据块,执行块的创建和删除。
Ø 定期向NameNode发送心跳信息,包括本身信息和block信息。
(4**)SecondaryNameNode(**非高可靠)
一般运行在单独的物理计算机上,与NameNode进行通信,按照一定的时间间隔保持文件系统元数据的快照,是HA的一种解决方案,在生成环境的集群中,没有这个进程,当NameNode挂掉之后,可以帮助NameNode重启启动并恢复数据。
三、HDFS的基本概念
1.命名空间(namespace)与块存储服务
HDFS使用的是传统的分级文件组织结构。
namespace负责管理文件系统中的树状目录结构。
块存储服务,负责管理文件系统中文件的物理块与实际存储位置的映射关系。
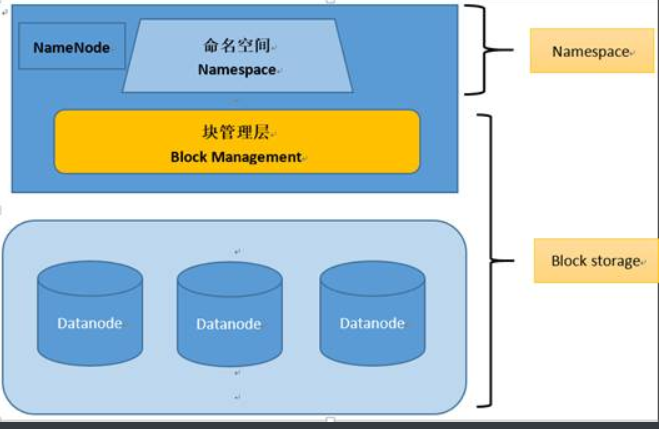
2.数据块block
HDFS旨在在大型群集中的计算机之间可靠地存储非常大的文件。它将每个文件存储为一系列块。
默认的块的大小是128M**(Hadoop2.0****)。**
文件中除最后一个块外的所有块都具有相同的大小(128M),而在添加了对可变长度块的支持后,用户可以在不填充最后一个块的情况下开始新的块,而不用配置块大小。如果一个文件的最后一个块的大小不足128M,也不会与其他的文件的块合并(因为是不同的文件)
3.数据复制data replication
复制文件的块是为了容错,每个文件都可以配置块大小和复制因子。配置属性:dfs.replaction,默认的副本系数是3。
相同block块的不同的副本不会存储在同一个节点上。
应用程序可以指定文件的副本数。复制因子可以在文件创建时指定,以后可以更改。HDFS中的文件只能写入一次(追加和截断除外),并且在任何时候都只能具有一个写入器。
NameNode定期从群集中的每个DataNode接收Heartbeat和Blockreport。收到心跳意味着DataNode正常运行。Blockreport包含DataNode上所有块的列表。
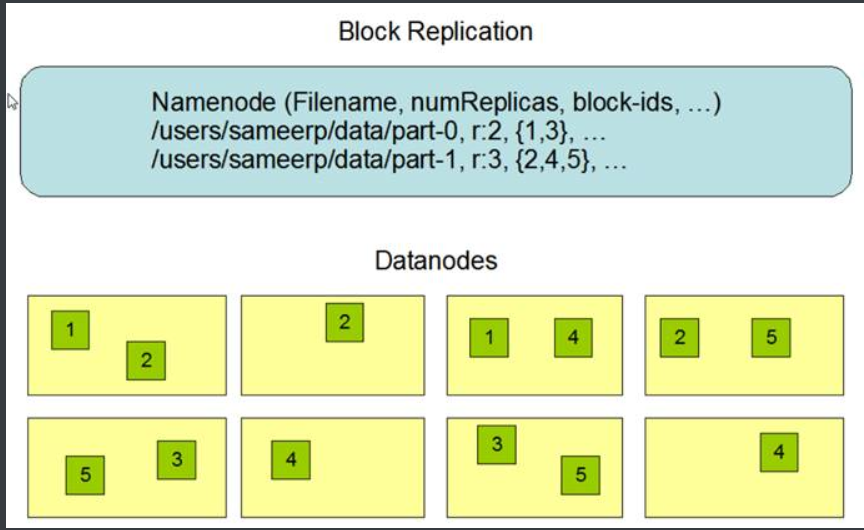
4.机架感知的副本放置策略
三份副本的放置策略如下:
Ø 第一个副本放置在客户端所在的节点,若客户端为远程访问则随机选择一个节点。
Ø 第二个副本放置在与第一个副本同机架的另外一个节点上
Ø 第三个副本放置在不同机架的节点上
5.心跳检测与副本恢复
DataNode会定期的向NameNode去发送心跳信息(本身的状况还有块的信息)
定期:DataNode多长时间去发送一次心跳信息,默认的时间是3S,如果进行配置的话,可以修改以下配置:

如果DataNode宕机了,NameNode接收不到心跳, NameNode不会立即认为该DataNode死亡,他会等10次,如果10次接收到DataNode发送信息的话,他也不会立即认为他死亡了,他会在第10次应该发送心跳信息的时间点之后的5min,向DataNode发送一次检查。
NameNode向DataNode发送检查的默认的间隔时间

如果DataNode故障之后,310+560=330S,NameNode会向DataNode发送第一次检查,发送检查如果没有收到回应,再当前的时间点再过5min发送第2次检查,如果第二次检查没有响应的话,才会认为DataNode宕机。
NameNode确认DataNode宕机的时间是 310+52*60=630S
四、HDFS的shell命
启动HDFS的服务:start-dfs.sh,HDFS安装好之后只有一个根目录(/),没有其他的目录和文件
hadoop fs 命令
hdfs dfs 命令
在操作HDFS的时候是没有相对路径,只有绝对路径(不管你操作的文件或目录在那个地方,都是从根目录开始操作)
1.hadoop fs(hdfs dfs)命令
1.1.-mkdir
将Path作为参数创建目录,用法:
hadoop fs -mkdir [-p]
选项:
-p是创建多级目录
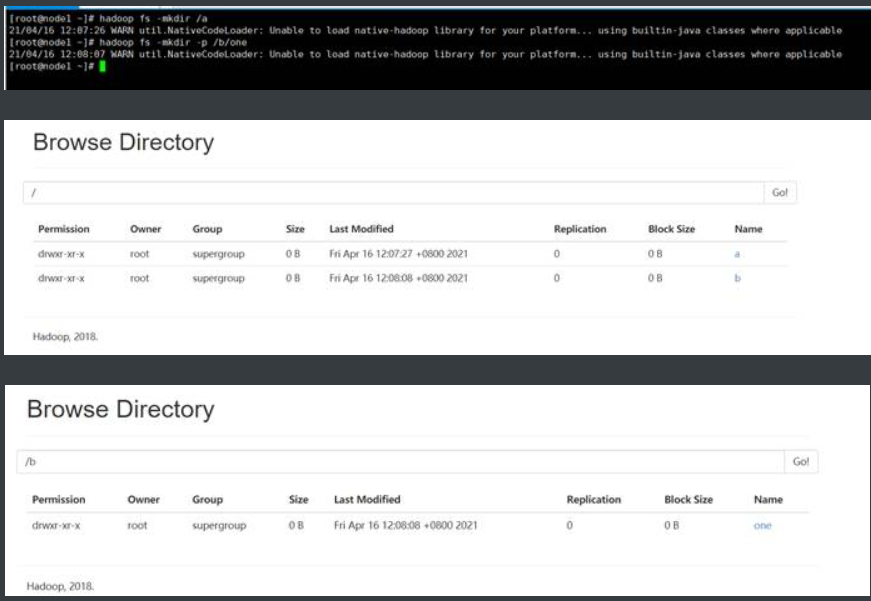
(1) 在/目录下创建a目录
hadoop fs -mkdir /a
(2) 在/目录下创建b目录,并在b目录中创建one目录
hadoop fs -mkdir -p /b/one #创建多级目录需要添加-p选项
1.2.-ls
列出path中的目录或文件,用法:
hadoop fs -ls [-d] [-h] [-R] [
选项:
-d:目录被列为纯文件
-h:以易于阅读的格式设置文件大小
-R:递归列出遇到的子目录
示例:
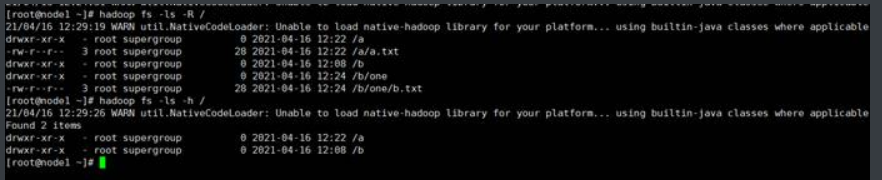
(1)查看/目录中的子目录或文件
(2)查询/目录中所有的目录和文件(-R选项)
(3)文件大小以易于阅读的格式(-h选项)
1.3.-cat
将源路径复制到标准输出,用法:
hadoop fs -cat [-ignoreCrc] URI [URI …]或
hdfs dfs –cat [-ignoreCrc] URI [URI …]
选项:
-ignoreCrc:禁用checkshum验证。
示例:查看/a/a.txt的文件内容

1.4.-put
将单个src或多个src从本地文件系统(一般Linux)复制到目标文件系统(HDFS)。
hadoop fs -put [-f] [-p] [-l] [-d] [-| …].或
hdfs dfs -put [-f] [-p] [-l] [-d] [-| …].
选项:
-p:保留访问和修改时间,所有权和权限。(假设权限可以在文件系统之间传播)
-f:如果目标文件已经存在,则将其覆盖。
-l:允许DataNode将文件延迟保存到磁盘,强制复制因子为1。此标志将导致持久性降低。小心使用。
-d:跳过带有后缀._COPYING_的临时文件的创建。
示例:将本地的a.txt文件上传到/目录中

1.5. –copyFromLocal
类似于put命令,将本地文件复制到HDFS中

1.6. -moveFromLocal
与put命令类似,不同之处在于复制后将源localsrc删除
1.7. –appendToFile
将本地文件系统中的单个src或多个src追加到目标文件系统。还从stdin读取输入,并将其追加到目标文件系统。用法:
hadoop fs -appendToFile … 或
hdfs dfs -appendToFile …
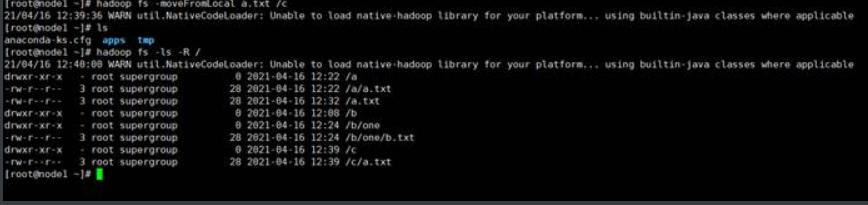
示例:
将本地b.txt的内容追加到HDFS中的/a.txt

1.8.-get
将文件复制到本地文件系统,用法:
hadoop fs -get [-ignorecrc] [-crc] [-p] [-f] 或
hdfs dfs -get [-ignorecrc] [-crc] [-p] [-f]
选项:
-p:保留访问和修改时间,所有权和权限。(假设权限可以在文件系统之间传播)。
-ignorecrc:对下载的文件跳过CRC检查。
-crc:为下载的文件写入CRC校验和
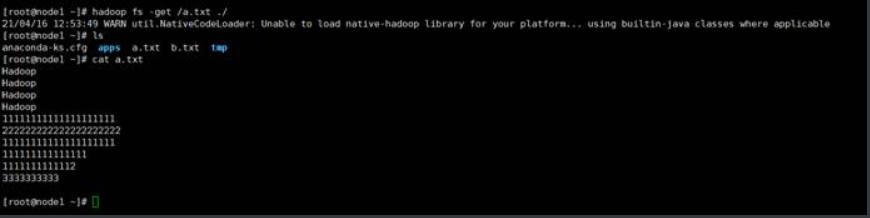
示例:将/a.txt下载到本地当前目录
1.9.-getmerge
将源目录和目标文件作为输入,并将src中的文件串联到目标本地文件中。可以选择将-nl设置为启用,以在每个文件的末尾添加换行符(LF)。用法:
hadoop fs -getmerge [-nl] 或
hdfs dfs -getmerge [-nl]
示例:
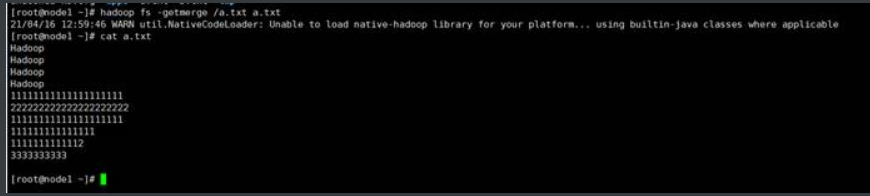
(1) 将/a. txt内容与本地的a.txt内容合
如果你指定了一个hdfs的文件,hdfs的文件会覆盖本地的文件
(2)将HDFS中的/a.txt与/b/a.txt文件下载到本地新文件c.txt
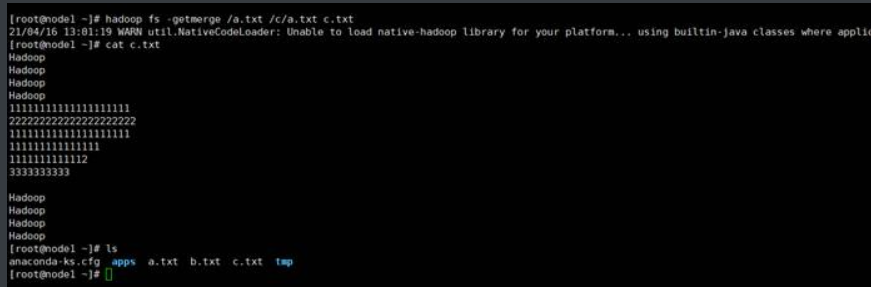
1.10.-copyToLocal
与get命令类似,将HDFS文件复制到本地

1.11.-mv
将文件从源文件移动到目标目录。此命令也允许多个源,在这种情况下,目标位置必须是目录。不允许跨文件系统移动文件(源是HDFS中的,目标也是HDFS中)。用法:
hadoop fs -mv URI [URI …] 或
hdf dfs -mv URI [URI …]
示例:

1.12. –cp
将文件从源复制到目标。此命令也允许多个源,在这种情况下,目标必须是目录(不允许跨文件系统,操作的都是HDFS的文件或目录)。用法:
hadoop fs -cp [-f] [-p | -p [topax]] URI [URI …] 或
hdfs dfs -cp [-f] [-p | -p [topax]] URI [URI …]
示例:将/a/profile复制到/b目录中

1.13. –rm
删除指定为args的文件。用法:
hadoop fs -rm [-f] [-r | -R] [-skipTrash] URI [URI …]
hdfs dfs -rm [-f] [-r | -R] [-skipTrash] URI [URI …]
选项:
-f:如果文件不存在,-f选项将不显示诊断消息或修改退出状态以反映错误。
-R选项以递归方式删除目录及其下的任何内容。
-r选项等效于-R。
-skipTrash选项将绕过垃圾桶(如果启用),并立即删除指定的文件。当需要从超配额目录中删除文件时,这很有用。
示例:
(1)删除文件

(2)删除目录(-r参数,删除目录也可用hadoop fs –rmdir命令或-rmr)

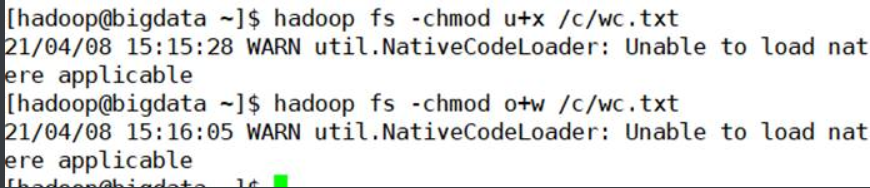
1.14.-chmod
更改文件的权限。使用-R,通过目录结构递归进行更改。用户必须是文件的所有者,或者是超级用户,用法:
hadoop fs -chmod [-R] <MODE [,MODE] … | OCTALMODE> URI [URI …]或
hdfs dfs -chmod [-R] <MODE [,MODE] … | OCTALMODE> URI [URI …]
文件的权限

上图中的第一组的d rwx r-x r-x
第一个代表的文件的类型:d-目录 -普通文件
第二个是rwx 代表的是属主的权限
第三个是r-x 代表与文件的属主同一组的其他的用户的权限
第三个r-x 代表的是其他组的用户的权限
权限: r-读的权限 w-写的权限 x-执行的权限 -没有权限
设置权限
第一种文字法设置
第一组的rwx指的是属主,u
第二组的rwx指的是同组用户,g
第三组的rwx指的的其他组的用户,o
加权限 + 减权限-
u+r o+x
第二种数字法设置
rwx :位置是不可变的,
第一个就是读的权限,如果有读的权限r ,如果没有没有读的权限- 2^2=4
第二个是写的权限,有则是w,没有是- 读权限代表数是 2^1=2
第三个是执行的全新,有x,没有- 执行的权限代表数字是2^0=1
-代表的数字是0
rwx代表数字4+2+1=7
r-x代表的数组4+0+1=5

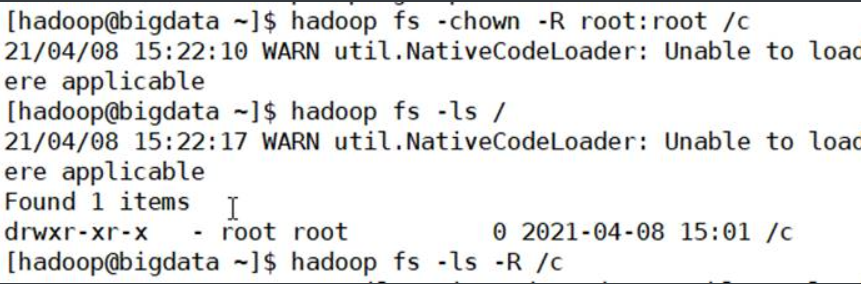
1.15.-chown
更改文件的所有者和组。该用户必须是超级用户。-R选项将通过目录结构递归进行更改。用法:
hadoop fs -chown [-R] [所有者] [:[组]] URI [URI]或
hdf dfs -chown [-R] [所有者] [:[组]] URI [URI]
示例:将/b的属主和属组改为root
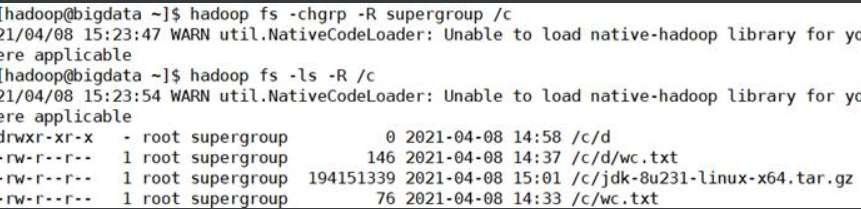
1.16.-chgrp
更改文件的组关联。用法:
hadoop fs -chgrp [-R] GROUP URI [URI …]或
hdfs dfs -chgrp [-R] GROUP URI [URI …]
1.17. –df
显示可用空间。用法:
hadoop fs -df [-h] URI [URI …]或
hdfs dfs -df [-h] URI [URI …]
选项:
-h选项将以“人类可读”的方式格式化文件大小(例如64.0m而不是67108864)

1.18.-du
显示给定目录中包含的文件和目录的大小,或仅在文件的情况下显示文件的长度。用法:
hadoop fs -du [-s] [-h] URI [URI …]或
hdfs dfs -du [-s] [-h] URI [URI …]
选项:
-s选项将导致显示文件长度的汇总摘要,而不是单个文件的摘要。
-h选项将以“人类可读”的方式格式化文件大小(例如64.0m而不是67108864)

1.19 –tail
查看文件末尾1KB的内容,用法:
hadoop fs -tail [-f] 或
hdfs dfs –tail [-f]
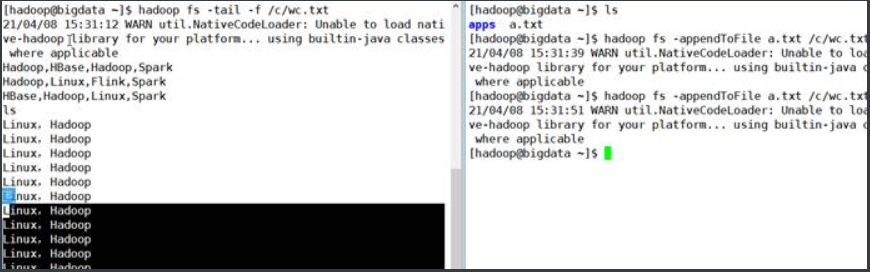
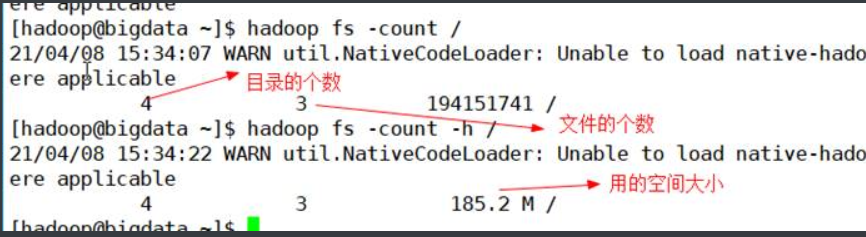
1.20. –count
计算与指定文件模式匹配的路径下的目录,文件和字节数,用法:
hadoop fs -count [-q] [-h]
hdfs dfs -count [-q] [-h]
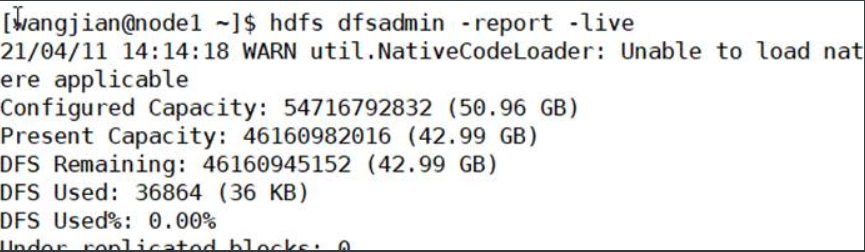
2. hdfs dfsadmin命令
2.1-report
报告基本文件系统信息和统计信息
hdfs dfsadmin -report [-live] [-dead] [-decominging]
2.2-safemode
安全模式维护命令。安全模式是Namenode状态,其中
1.不接受对名称空间的更改(HDFS是只读,不能上传、创建、修改、复制、移动,但是可以查看、下载文件)
2.不复制或删除块。
安全模式在Namenode启动时自动进入,并在配置的最小块百分比满足最小复制条件时自动退出安全模式。也可以手动进入安全模式,但是随后也只能手动将其关闭。(当Namenode启动时,会将磁盘上的fsimage(元数据快照)这些文件加载到内存中)
hdfs dfsadmin -safemode enter|leave|get|wait
\1. 获取安全状态

2.进入安装模式

\3. 测试创建一个目录和上传一个文件
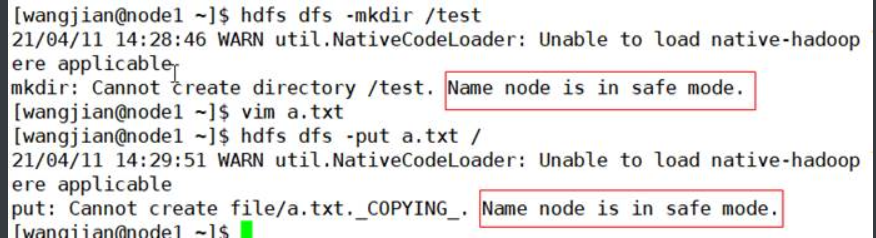
4.离开安全模式

5.上传文件,然后再进入安全模式,然后再查看和下载文件
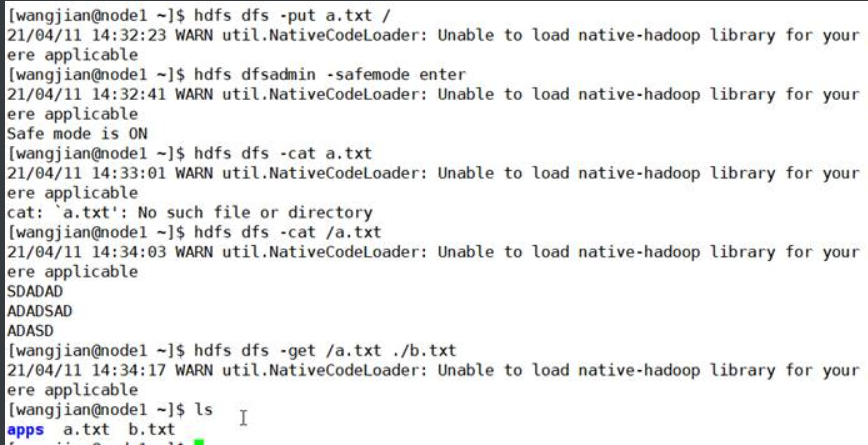
2.3 -refreshNodes
重新读取主机并排除文件,以更新允许连接到Namenode以及应停用或重新启用的Datanode集合
hdfs dfsadmin –refreshNodes
五、HDFS数据读写流程
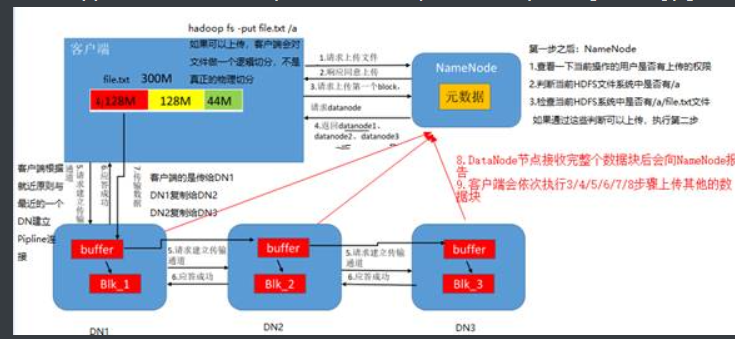
1.数据写入流程
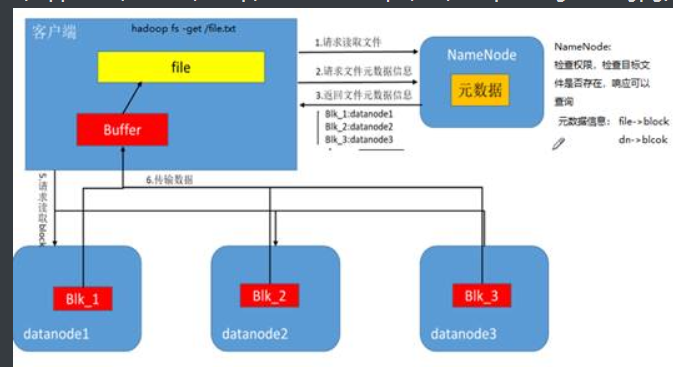
2.数据读取流程
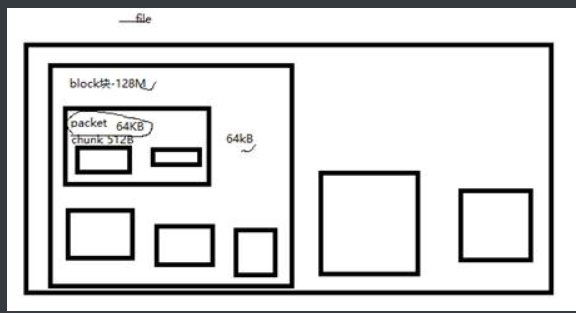
3.读写的单元
Ø Block:文件存储的最小单元(128M)
Ø Packet: 64K(网络传递的基本单元)
Ø Chunk: 校验单元 512bit
六、HDFS元数据管理机制
1.元数据
元数据(对你的文件数据做描述的一些数据)有NameNode维护
(1)文件目录结构信息(抽象的目录树),及其自身的属性信息。
(2)文件存储信息
文件分块信息:file1->blk1,blk2,blk3,blk4
block和节点对应信息: dn1,dn2,dn3->blk1
dn2,dn3,dn4-blk2,blk3
dn5,dn6,dn7->blk4
需要注意的是block和节点的对应关系是临时构建的,并不会持久化存储
(3)Datanode信息。
2.元数据存储机制
2.1元数据保存在哪
元数据信息保存在内存中,也会保存在磁盘中
保存在内存中提高元数据的读写速度,从而也提高了数据的读写速度
(1)文件目录结构信息 (2)文件和数据库的映射关系 (3)block块与节点的映射关系
保存在磁盘中为了持久化元数据,防止节点宕机导致内存中的元数据丢失。
(1) 文件目录结构信息 (2)文件和数据库的映射关系
Block与节点的映射关系不会持久化到磁盘中,当HDFS启动的时候,先启动NameNode,NameNode启动后会先进入安全模式,接着启动DataNode,DataNode启动起来之后就像NameNode通过心跳发送信息,当报告完成之后,NameNode退出安全模式。
2.2持久化文件
(1)元数据快照文件
fsimage_0000000000000000069
fsimage_0000000000000000069.md5
fsimage_0000000000000000077
fsimage_0000000000000000077.md5
(2) 日志文件
历史日志文件
edits_0000000000000000001-0000000000000000002
edits_0000000000000000003-0000000000000000003
edits_0000000000000000004-0000000000000000040
edits_0000000000000000041-0000000000000000069 edits_0000000000000000070-0000000000000000077
(2)现在正在写入的日志文件
edits_inprogress_0000000000000000078
seen_txid:记录当前向哪个一个文件记录日志
3.元数据合并机制
3.1内存中元数据、fsimage和edits的关系
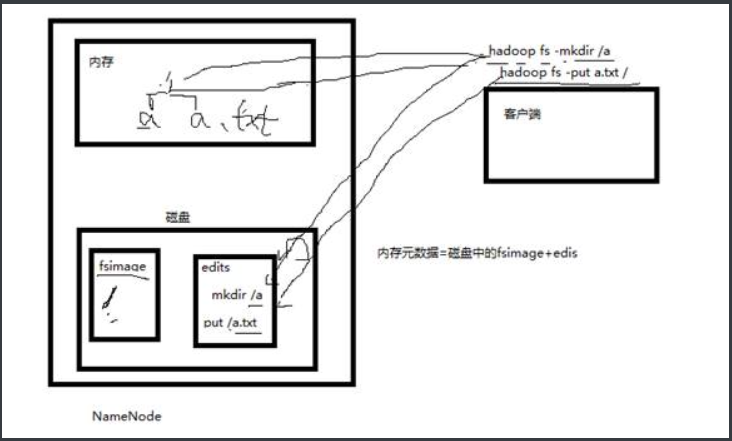
3.2合并机制
伪分布式和非高可靠分布式集群:合并是secondaryNameNode完成的

高可靠的集群中由备用的namenode节点进行Checkpoint
Checkpoint:检查点(合并点) hdfs-default.xml
dfs.namenode.checkpoint.period:设置两次相邻CheckPoint之间的时间间隔,默认是1小时;
dfs.namenode.checkpoint.txns:设置的未经检查的事务的数量,默认为1百万次。
edits_0000000000000000004-0000000000000000040
edits_0000000000000000041-0000000000000000069 edits_0000000000000000070-0000000000000000077
(2)现在正在写入的日志文件
edits_inprogress_0000000000000000078
seen_txid:记录当前向哪个一个文件记录日志
3.元数据合并机制
3.1内存中元数据、fsimage和edits的关系
[外链图片转存中…(img-qWqUoy4m-1618576061496)]
3.2合并机制
伪分布式和非高可靠分布式集群:合并是secondaryNameNode完成的
[外链图片转存中…(img-GOUBi8uf-1618576061496)]
高可靠的集群中由备用的namenode节点进行Checkpoint
Checkpoint:检查点(合并点) hdfs-default.xml
dfs.namenode.checkpoint.period:设置两次相邻CheckPoint之间的时间间隔,默认是1小时;
dfs.namenode.checkpoint.txns:设置的未经检查的事务的数量,默认为1百万次。
MAVEN

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









