






首先要明白,划分数据集的代码需要的是数据集图片和对应的txt文件,也就是YOLO格式,如果你的数据集是VOC格式,可以用一个python代码将其转换为YOLO格式得到对应的txt文件(具体代码看我主页上面文章)。
得到txt文件后,接下来要创建目录用来存放划分后的数据集图片和txt文件(标签文件)。
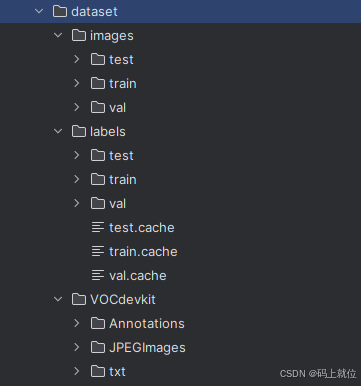
其中VOCdevkit中存放的就是划分之前的数据集,里面的Annotations存放的是xml文件,JPEGImages存放的是xml文件对应的图片(JPG格式),txt文件是通过xml文件得到的txt文件(具体代码见主页上篇文章)。
然后就创建文件目录如上图所示
接下里执行Split_Data.py 具体代码如下
import os, shutil, random
random.seed(0)
import numpy as np
from sklearn.model_selection import train_test_split
val_size = 0.2
test_size = 0.1
postfix = 'jpg'
imgpath = 'VOCdevkit/JPEGImages'
txtpath = 'VOCdevkit/txt'
os.makedirs('images/train', exist_ok=True)
os.makedirs('images/val', exist_ok=True)
os.makedirs('images/test', exist_ok=True)
os.makedirs('labels/train', exist_ok=True)
os.makedirs('labels/val', exist_ok=True)
os.makedirs('labels/test', exist_ok=True)
listdir = np.array([i for i in os.listdir(txtpath) if 'txt' in i])
random.shuffle(listdir)
train, val, test = listdir[:int(len(listdir) * (1 - val_size - test_size))], listdir[int(len(listdir) * (1 - val_size - test_size)):int(len(listdir) * (1 - test_size))], listdir[int(len(listdir) * (1 - test_size)):]
print(f'train set size:{len(train)} val set size:{len(val)} test set size:{len(test)}')
for i in train:
shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'images/train/{}.{}'.format(i[:-4], postfix))
shutil.copy('{}/{}'.format(txtpath, i), 'labels/train/{}'.format(i))
for i in val:
shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'images/val/{}.{}'.format(i[:-4], postfix))
shutil.copy('{}/{}'.format(txtpath, i), 'labels/val/{}'.format(i))
for i in test:
shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'images/test/{}.{}'.format(i[:-4], postfix))
shutil.copy('{}/{}'.format(txtpath, i), 'labels/test/{}'.format(i))其中路径要根据自己数据集所在的具体路径进行修改,为避免出错,可以使用绝对路径(我这里使用的是相对路径)。
然后运行Split_Data.py,就会发现划分后的数据集图片和标签文件就成功生成到目录中!!!
到这里就结束了,感谢你的观看,希望这篇文章对你有帮助!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









