







 本文介绍视频超分辨率的概念及其实现方法,探讨了帧对齐的重要性,并详细讲解了光流法及其优缺点。此外,还介绍了基于金字塔结构的视频超分辨率技术。
本文介绍视频超分辨率的概念及其实现方法,探讨了帧对齐的重要性,并详细讲解了光流法及其优缺点。此外,还介绍了基于金字塔结构的视频超分辨率技术。
https://www.bilibili.com/video/BV1vF411T7o4?spm_id_from=333.337.search-card.all.click&vd_source=8d577ea55b2ca468536bc192e53bd524
1.视频超分辨率的定义
https://blog.youkuaiyun.com/happyrobot01/article/details/120284289
输入一个低分辨率的视频,经过卷积模型输出高分辨率的模型
2.帧对齐是什么
所谓对齐就是将不同帧间的同一物体(位置发生变化的)对齐到同一位置,使得物体特征都处在相同位置,方便特征提取网络提取到物体尽可能多的特征。
帧对齐是通过对齐字符/F/来监控的。发送器在帧的结束插入该字符。/A/字符表明多帧的结束。该字符替换算法取决于是否使能或禁用加扰,不管csr_lane_sync_en寄存器的设置。
对齐检测的流程为:
*
如果在同一位置,而不是在假定的帧结束检测到两个连续的有效对齐字符—无需在两个对齐字符之间的预期位置接收有效或无效的对齐字符—这个接收器将其帧重新对齐到所接收的对齐字符的新位置。
*
如果通道重新对齐会导致帧对齐错误,那么接收器发出错误信息。
在JESD204B RX IP内核中,同一个灵活的缓冲器用于帧和通道对齐。通道重新对齐给出了正确的帧对齐,因为通道对齐字符加倍作为一个帧对齐字符。一个帧重新对齐会导致不正确的通道对齐或链路延迟。行动的过程是让RX通过SYNC_N请求重新对齐。
3.使用光流的目的是?
一般而言,帧间对齐是依靠显式计算不同帧之间的光流来完成的
众多光流估计网络比如FolwNet等基本上可以实现较为准确的光流估计。有了帧间光流以后,就可以将上一帧的运动目标补偿到这一帧中进行对齐,这样就可以将多帧输入同时输送到通用的图像超分SR网络进行超分。值得一提的是每次输出一张高分辨率HR帧,都会用到该帧对应的低分辨率LR帧和相邻的LR帧。
不难看出,上面基于光流的帧间信息对齐方法的准确性严重依赖于光流估计的准确性。并且由于除了超分网络还要借助光流估计网络,所以基于光流对齐的视频超分算法属于二阶段模型。因此除了显式的计算光流之外,最近逐渐出现了隐式对齐的一阶段算法,即不需要进行光流估计。
————————————————
原文链接:https://blog.youkuaiyun.com/happyrobot01/article/details/120284289
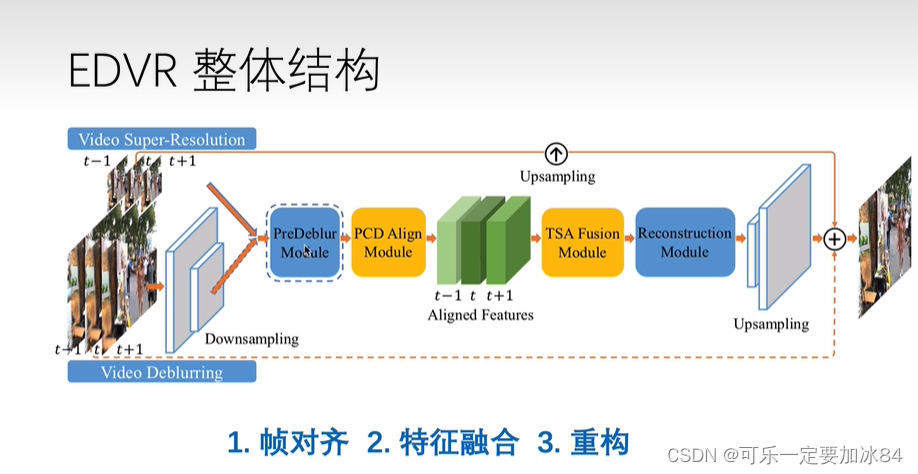
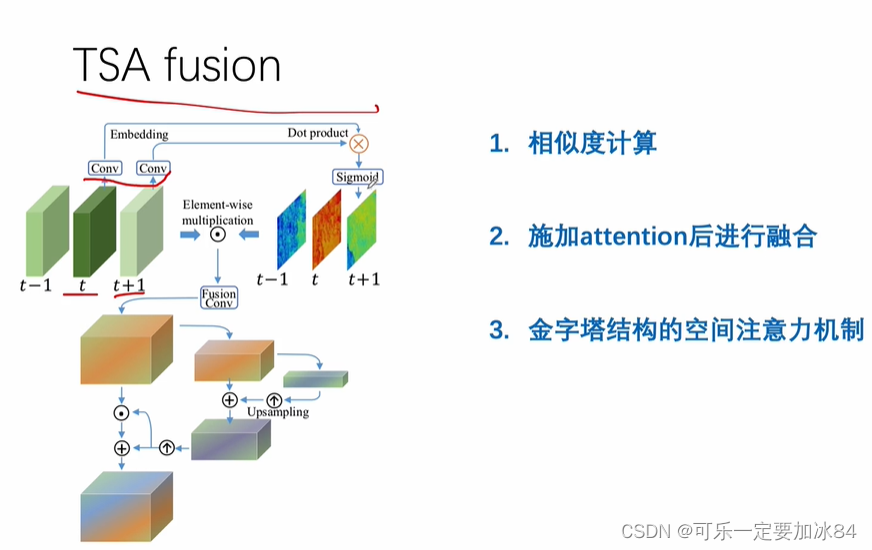
preDeblur是可以 被拿掉的
PCD主要实现对齐
TSA主要实现聚合
整体是多帧输入单帧输出的结构
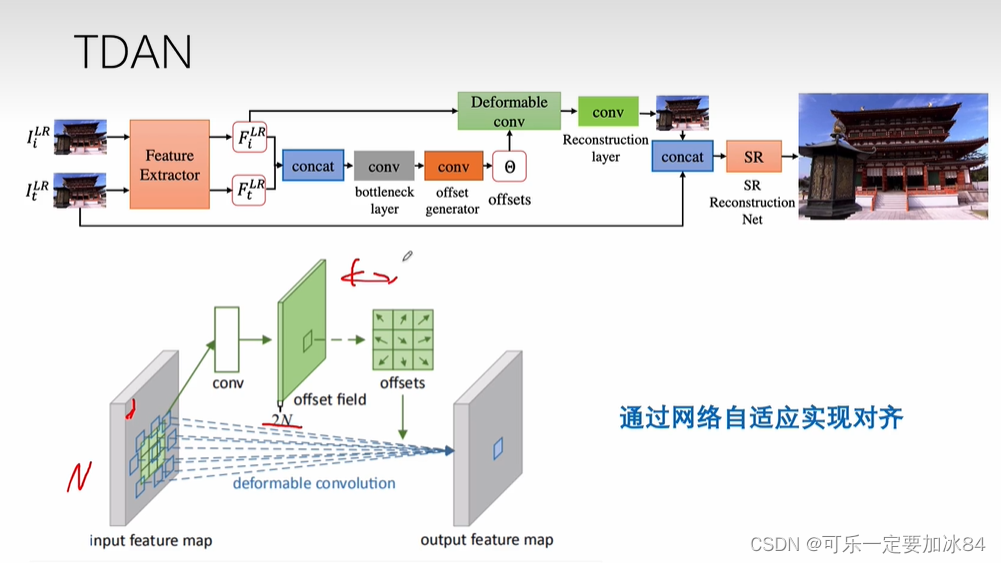
每个点都学到偏移量
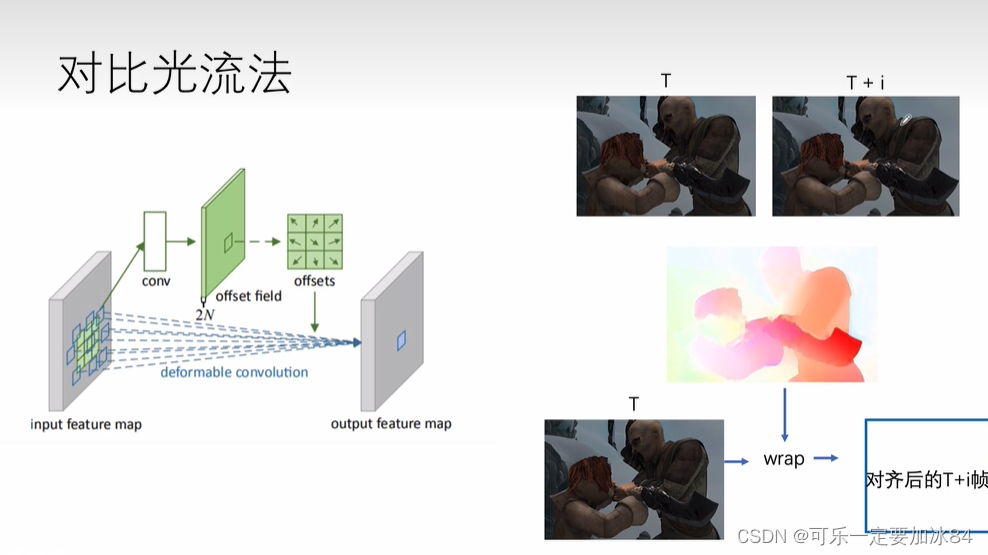
光流法:有T帧和T+i帧,提取出光流,光流和T帧进行wrap,运动补偿,得到对齐后的T+i帧
对比:
相比左边,光流可解释性更强,但是灵活性不够
左边可解释性不强但是灵活性更高,能自适应的处理
总体而言,左边的是local的方式
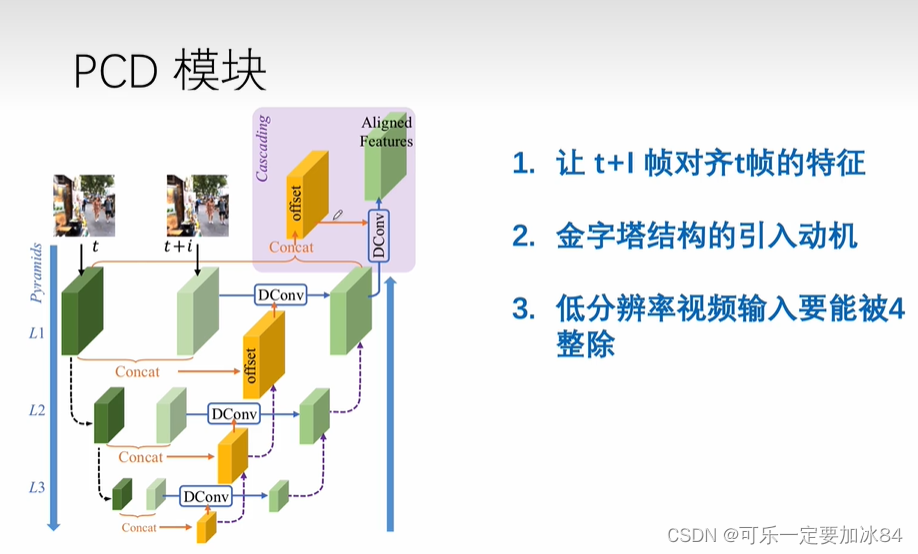
卷积网络感受野如果不够大,可能无法对齐T帧的相同区域,无法学习到对应区域。
故采用金字塔结构,特征图变小,感受野变大,也就更容易学习到对应区域。
但是不可避免有局限性,有些可能捕获不到。


















 2548
2548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









