




 本文通过分析2018年北京积分落户的数据,揭示了落户人数最多的公司、分数分布及年龄结构。发现华为等高科技公司、国企积分落户人数较多,90-95分段申请者最多,40-45岁年龄段占比最高。这些信息对于准备落户北京的人有一定指导意义,如选择工作单位、了解分数要求和年龄因素。
本文通过分析2018年北京积分落户的数据,揭示了落户人数最多的公司、分数分布及年龄结构。发现华为等高科技公司、国企积分落户人数较多,90-95分段申请者最多,40-45岁年龄段占比最高。这些信息对于准备落户北京的人有一定指导意义,如选择工作单位、了解分数要求和年龄因素。
1、目的
在进行数据分析之前,要先明确两个点:
1.从什么维度切入?
2.用什么指标展示?
以本数据集为例,包括以下信息:
| 序号 | 字段名 | 数据类型 | 描述 |
|---|---|---|---|
| 1 | id | int | 用户ID |
| 2 | name | str | 姓名 |
| 3 | birthday | object | 出生日期 |
| 4 | company | str | 就职公司 |
| 5 | score | float | 分数 |
本文试图通过积分落户的人的基本信息,分析一下这些可获取的信息对我们想落户北京的人有哪些指导意义,因此选取的维度和指标为——
维度:落户TOP公司排名;分数分布;年龄分布
指标:人数;分数;年龄
2、分析过程
1. 读取和查看数据
index_col = 'id'ID列设置为index
DaraFrame.describe()针对数值类型的列进行描述性统计,可以查看每一列的均值、方差、最小值和最大值等。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
luohu_data = pd.read_csv('./bj_luohu.csv',index_col = 'id')
luohu_data.describe()
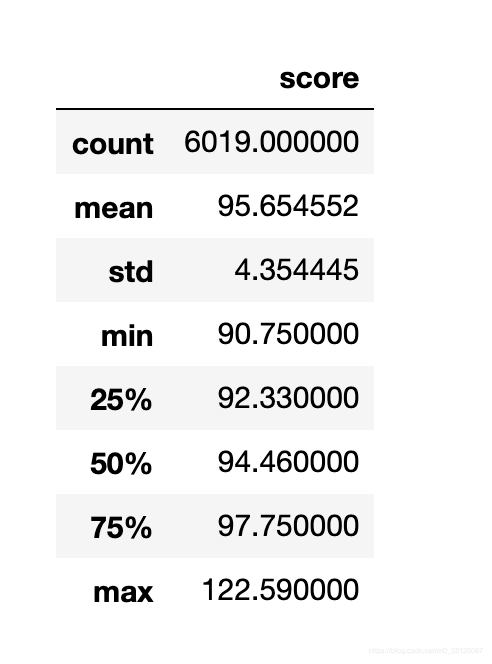
【结果】
分数的最小值为90.75,最大值为122.59
2. 公司维度
从公司的维度来看,我们需要的指标是人数,也就是我想看看每家公司在2018年积分落户成功的人数分布,排名靠前的公司都有哪些。
按照company分组,并计算每组的个数
DataFrame.rename()重命名列名
DataFrame.sort_values()按某列排序
【注】groupby默认会把by的这列作为索引返回,可以设置as_index = False
# 分组
company_data = luohu_data.groupby('company',as_index = False).count()[['company','name']]
# 重命名列名
company_data.rename(columns = {'name':'people_count'},inplace = True)
# 按照people_count这列排序
company_sorted_data = company_data.sort_values('people_count',ascending = False)
print('一共有{}家公司'.format(company_sorted_data['company'].count()))
# 按照条件过滤
## 只有一人的公司 有2626家
company_sorted_data[company_sorted_data['people_count']==1].shape[0]
print('只1人落户的公司共有:{}家'.format(one_people_count))
## 人数前50的公司
company_sorted_data.head(10)
【结果】
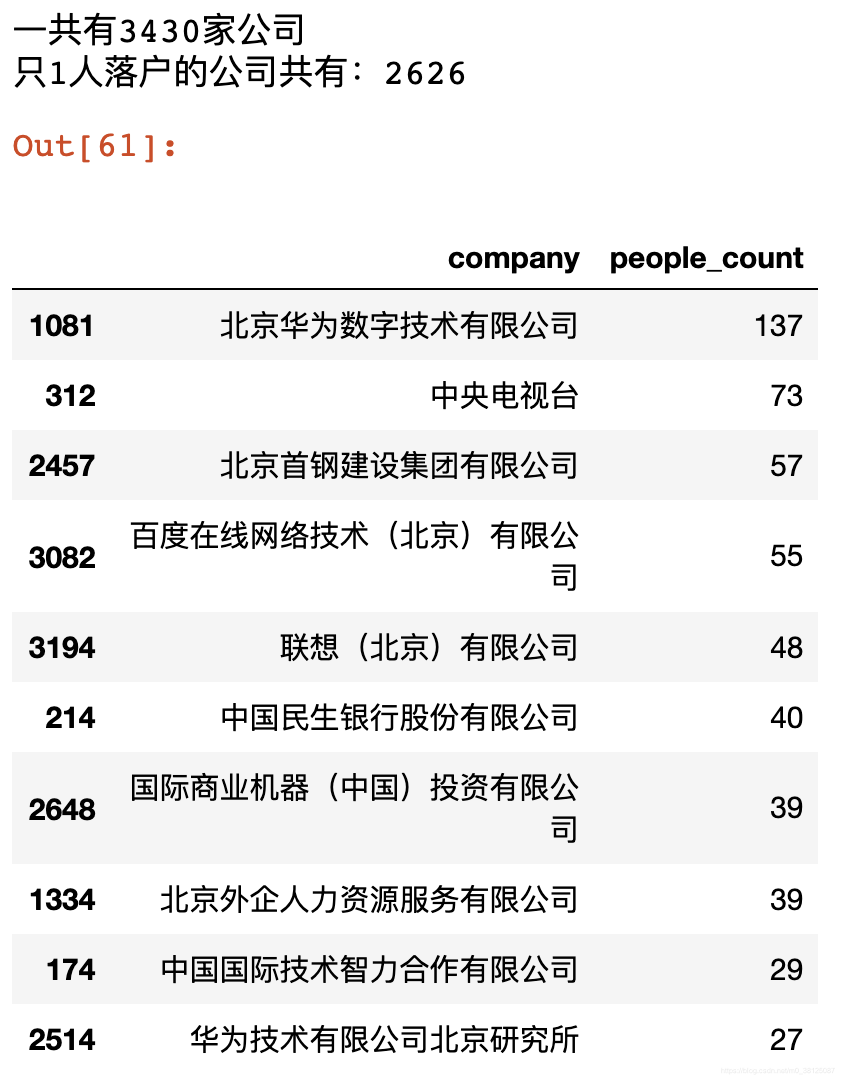
由结果可以看出,大多数公司只有1人通过积分落户北京,积分落户人数最多的是华为,TOP10公司的一些共性可以再深挖一下,比如:高科技公司、国企等。
3. 分数维度
我们把分数分成7个区间段,查看这些人分数的分布情况。先分段,再排序计数。
pd.cut()进行区间分段
# 按照步长为5,将score进行分桶统计
bins = np.arange(90,130,5)
bins = pd.cut(luohu_data['score'],bins)
bin_counts = luohu_data['score'].groupby(bins).count()
# 改变index的格式
bin_counts.index = [str(x.left) + '~' + str(x.right) for x in bin_counts.index]
print(bin_counts)
bin_counts.plot(kind = 'bar', alpha=0.7, rot=0)
plt.show()
【结果】
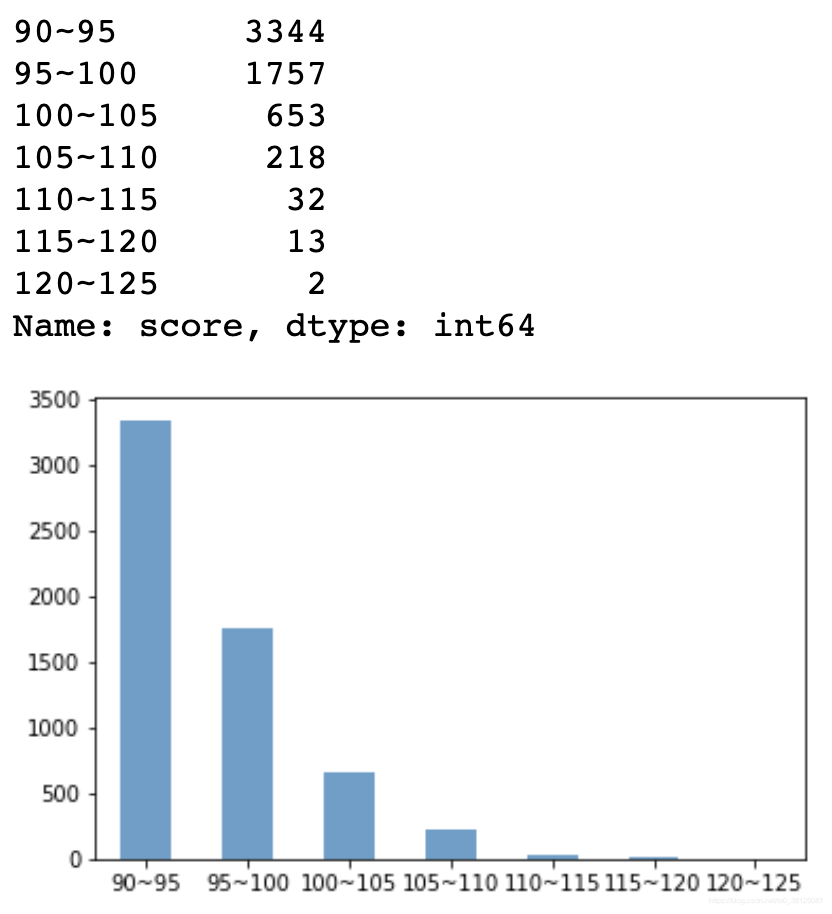
分数越高,人越少,90-95分这个区间段人是最多的。
4. 年龄维度
查看18年积分落户的人的年龄分布。首先要将出生日期转换为年龄,看一下年龄的描述性统计,然后再把年龄分段,排序计数。
# 出生日期转为年龄
luohu_data['age'] = ((pd.to_datetime('2019-12') - pd.to_datetime(luohu_data['birthday'])) / pd.Timedelta('365 days'))
luohu_data.describe()
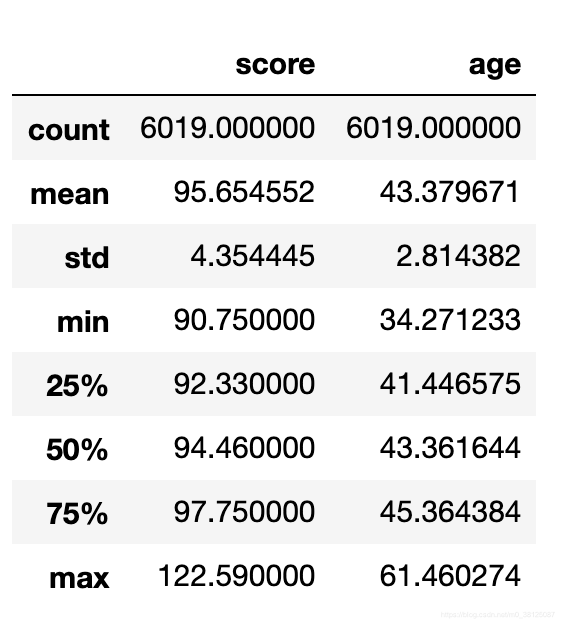
【结果】
bins = np.arange(30,70,5)
bins = pd.cut(luohu_data['age'],bins)
bins_counts = luohu_data['age'].groupby(bins).count()
bins_counts.index = [str(x.left) + '~' + str(x.right) for x in bins_counts.index]
print(bins_counts)
bins_counts.plot(kind = 'bar',alpha = 0.7, rot = 0)
plt.show()
【结果】
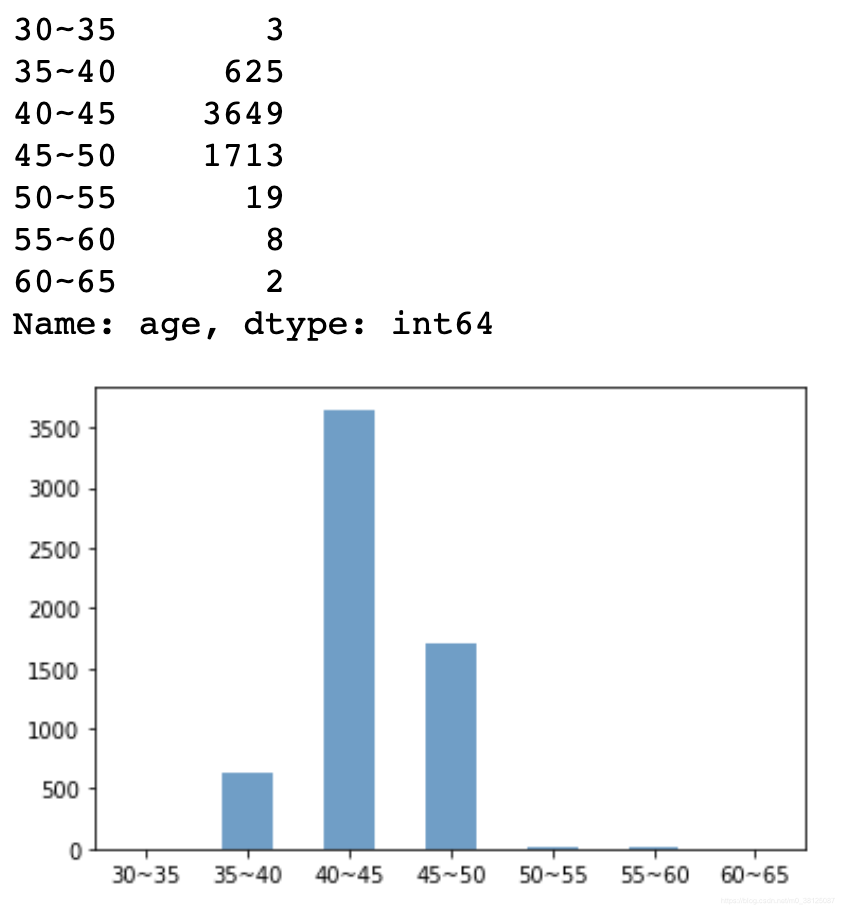
结果显示,40-45年龄段的人最多,唉,想要积分落户北京一般都是得是中年了。。
总结
通过对2018年积分落户北京的人的简单分析,对我们的指导意义有:
- 尽可能去高科技公司、国企等。(可以去扒一下,政府是否对高科技公司等有优惠政策)
- 够90分就能落户。够了就行,不是选拔制越高越高
- 30岁以前是痴心妄想- - 可能要等到40岁左右
以上纯属从数据中得到的推测,并没有查相关政策。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









