







1.首先说一下部署环境 MacBookPro M1pro 16+512版本,系统更新到了最新MacOS Sequoia 15.3

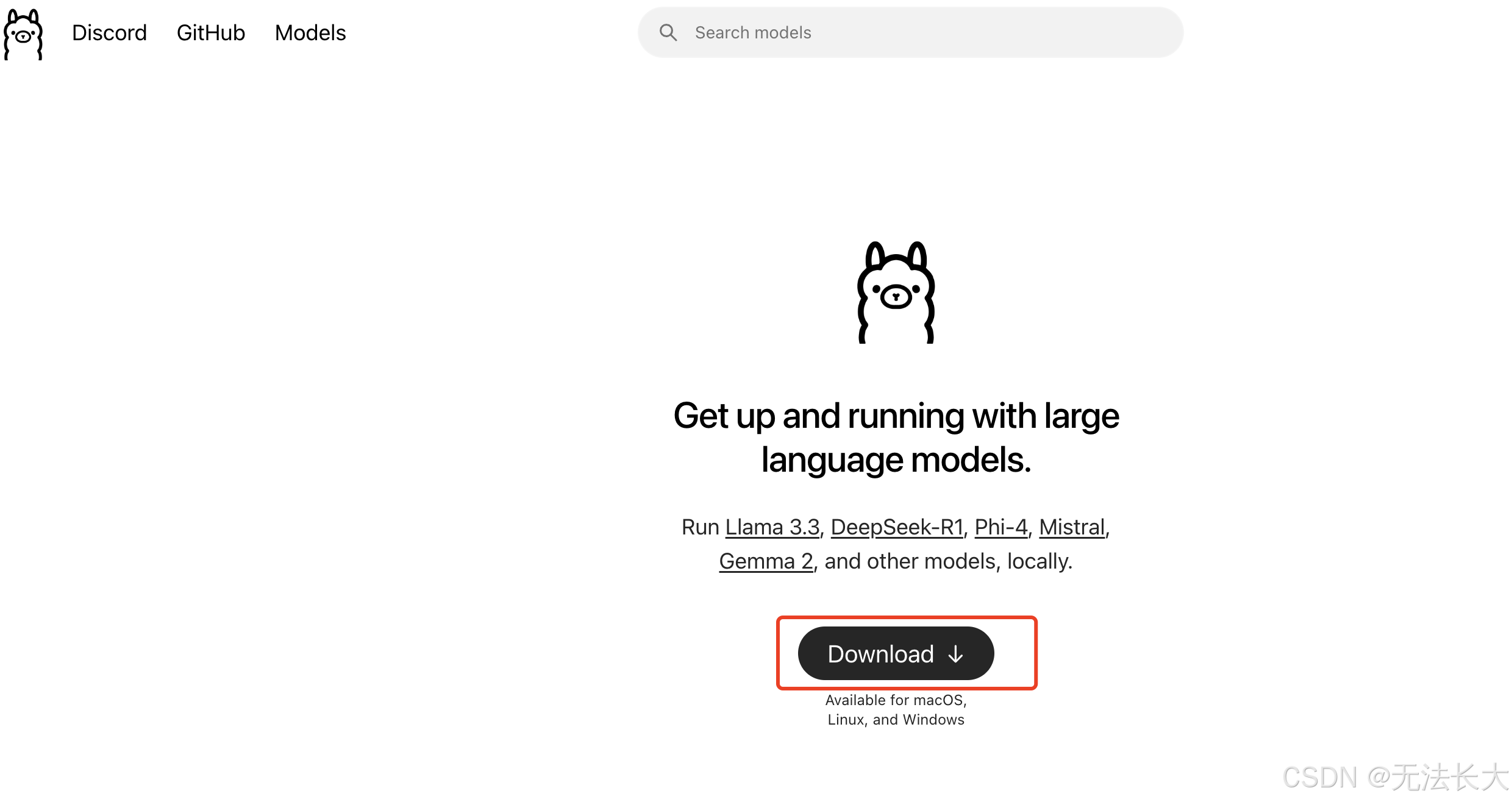
2.安装开源的大语言模型本地部署框架Ollama
Ollama,是一款开源的大语言模型本地部署框架,主要用于在本地机器上便捷地部署和运行大语言模型(LLM)。类似的部署框架还有别的,具体没有研究,从这个软件的设置可以看出。
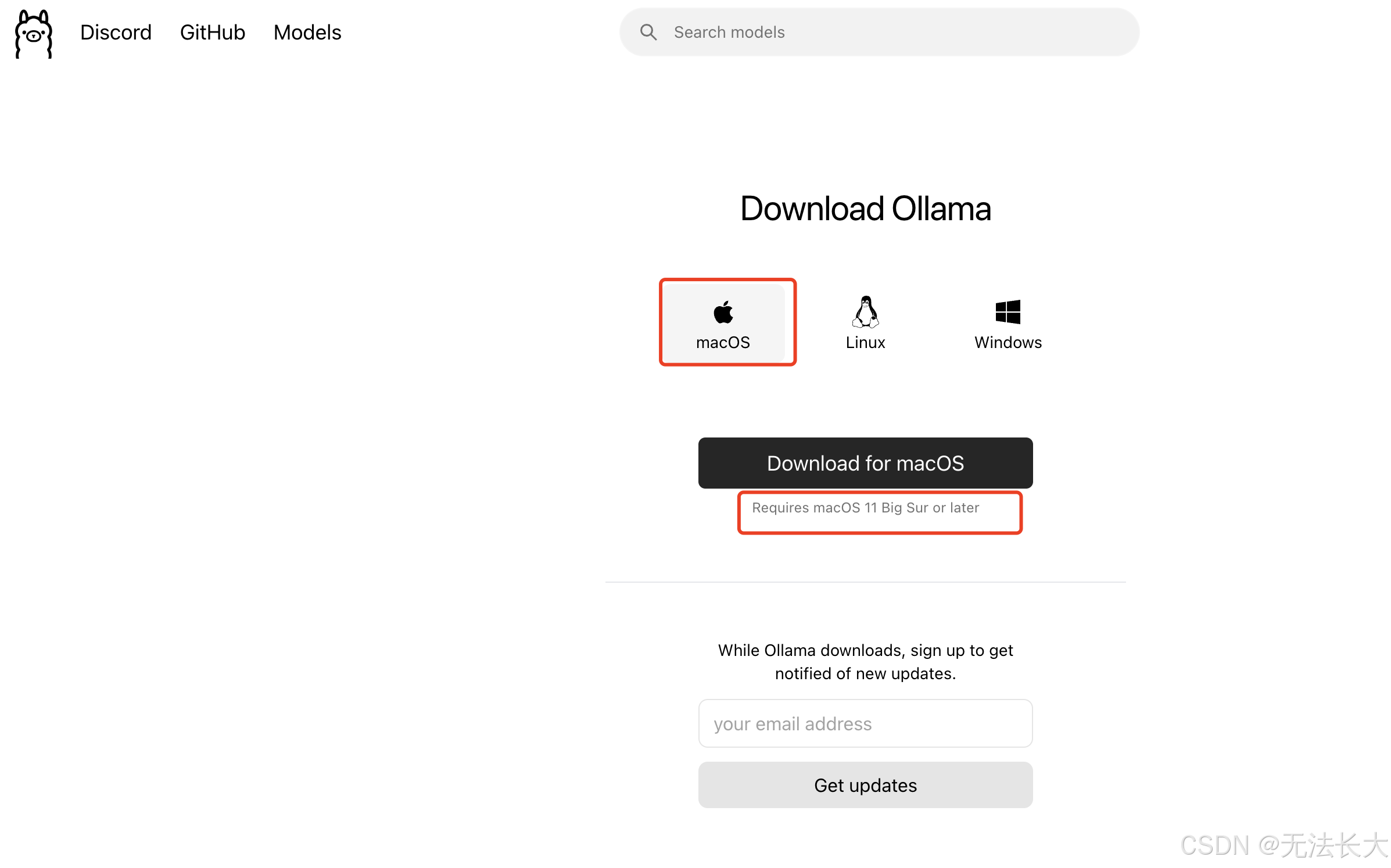
如何安装Ollama:注意要求最低的系统
安装成功后,桌面多出一个logo图标

进一步验证是否安装成功:打开终端,输入命令,看到版本号即可

ollama -v

3.下载安装 DeepSeek-R1
依旧在Ollama网站,搜索DeepSeek-R1,点击进入
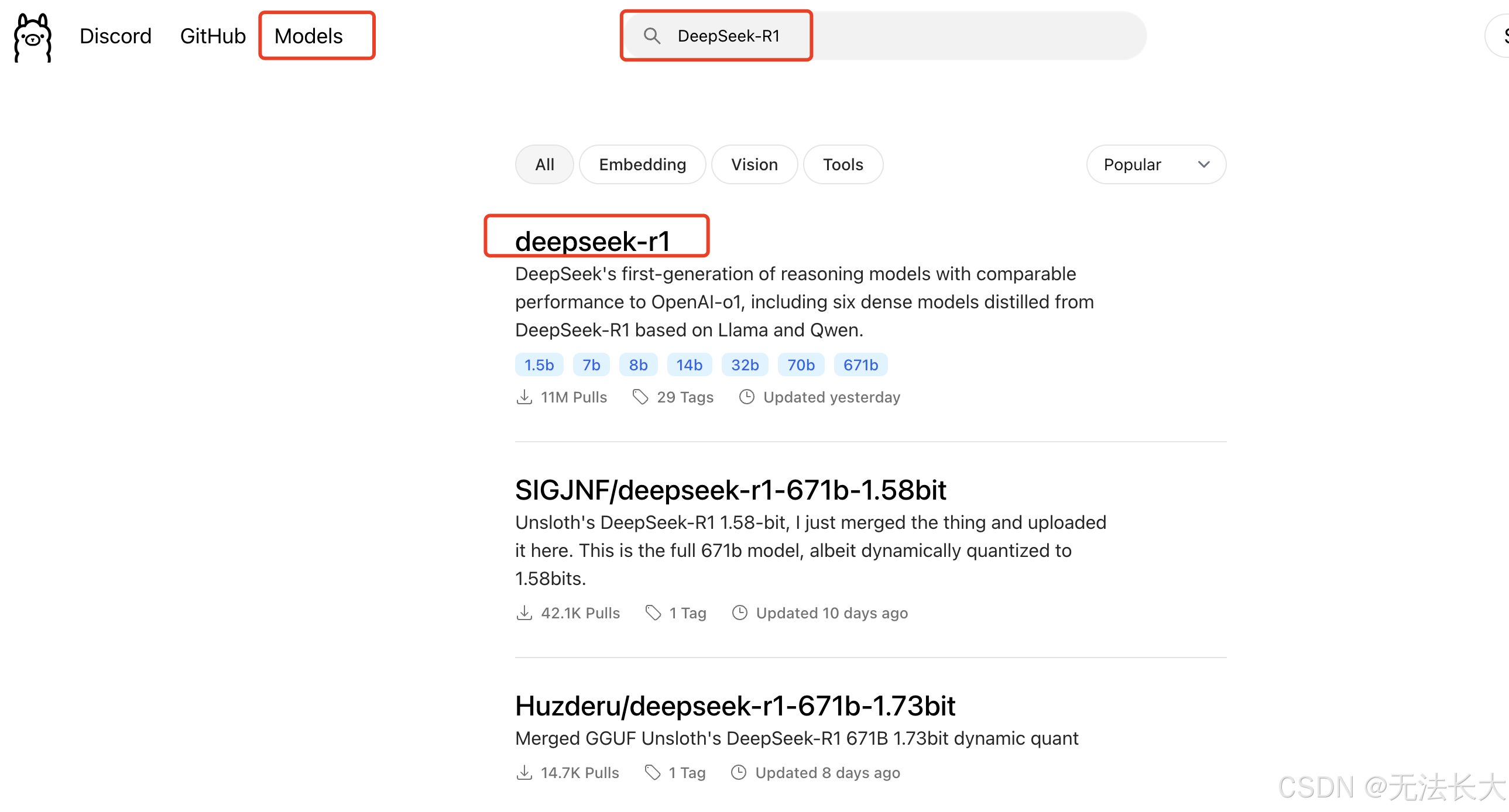
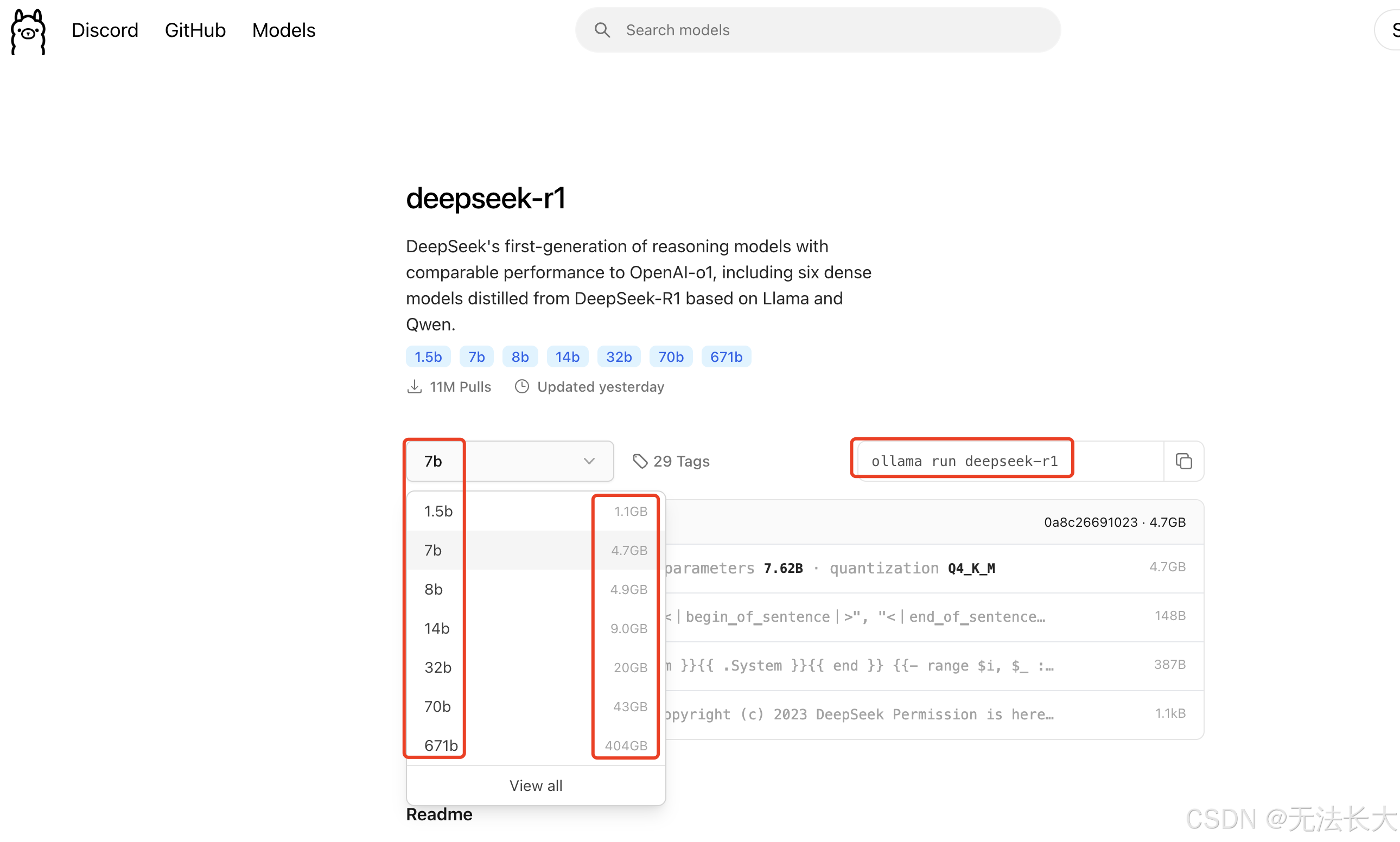
ollama run deepseek-r1:1.5b 即为安装 1.5b
ollama run deepseek-r1:14b 即为安装 14b
我个人也看到了一些配置要求的帖子,我先安装了7b的版本,后装了14b的版本,运行起来均没有问题
安装过程,及成功后的情况如下
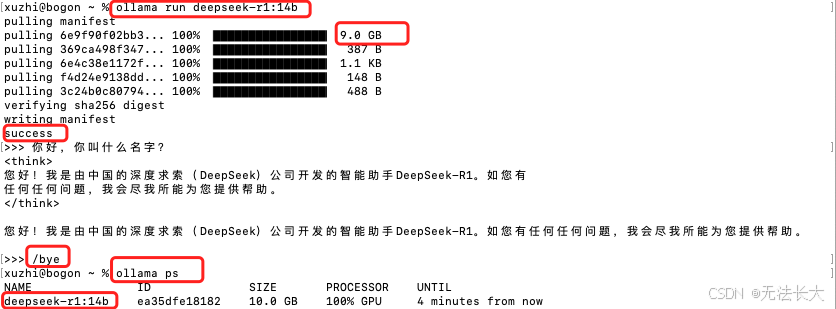
安装成功后,出现success字样即可输入问题和 DeepSeek-R1 对话了
4.ollama 的一些命令
ollama run deepseek-r1:14b 运行模型服务
ollama stop deepseek-r1:14b 停止模型服务
/bye 退出模型对话 注意:退出不会停止模型服务
ollama ps 列出正在运行的模型
ollama -v 查看ollama版本信息
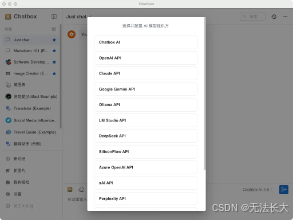
5.安装客户端 Chatbox 使用本地模型,增强体验感
Chatbox,是一个开源的 AI 模型桌面客户端,支持多种主流 AI 模型 和 API。
安装成功后,打开设置
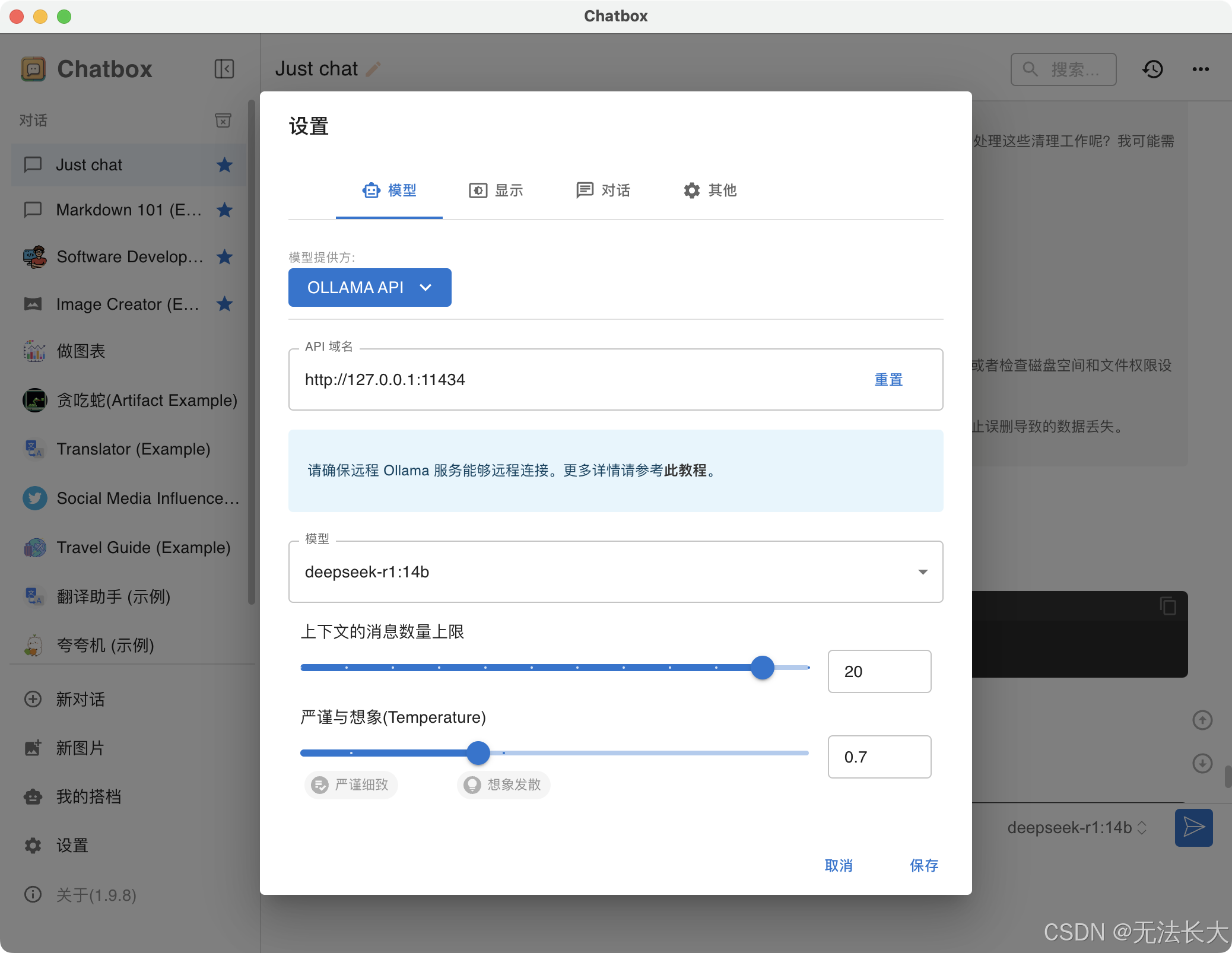
注意:使用时一定要先启动本地模型,即先 ollama run deepseek-r1:14b 运行模型服务

















 7804
7804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









