









为什么会出现分布式事务?
当我们项目架构逐渐扩展增大,为了对服务器访问压力进行负载均衡,在框架层面开始使用分布式服务,数据库也开始进行分库分表操作,分库分表之后,一方面可以解决同时访问单库带来的性能压力,另一方面,又可以减少单库单表的数据量,解决了代码中SQL查询数据量比较大的表效率慢的问题。
在此之前,数据库中的增改都是对单个数据库做的操作,在这种情况下,通过框架本身自带的事务@Transactional操作很容易达到数据的一致性,不需要单独再去考虑事务问题。分库之后,每个数据库的事务只有自己知道,如果同时操作两个或以上的数据库,订单库并不知道库存库的事务执行结果,库存库也不知道用户库的修改结果,所以就造成了分布式事务的问题。其实也叫分布式数据一致性。
1、数据库事务要满足几个要求:ACID
Atomic(原子性) 事务必须是原子的工作单元
Consistent(一致性) 事务完成时,必须使所有数据都保持一致状态
Isolation(隔离性) 并发事务所做的修改必须和其他事务所做的修改是隔离的
Duration(持久性) 事务完成之后,对系统的影响是永久性的
以图为例,当系统同时要对两个服务进行调度,同时对两个不同的数据库做操作时,怎么样保证数据库操作的一致性呢
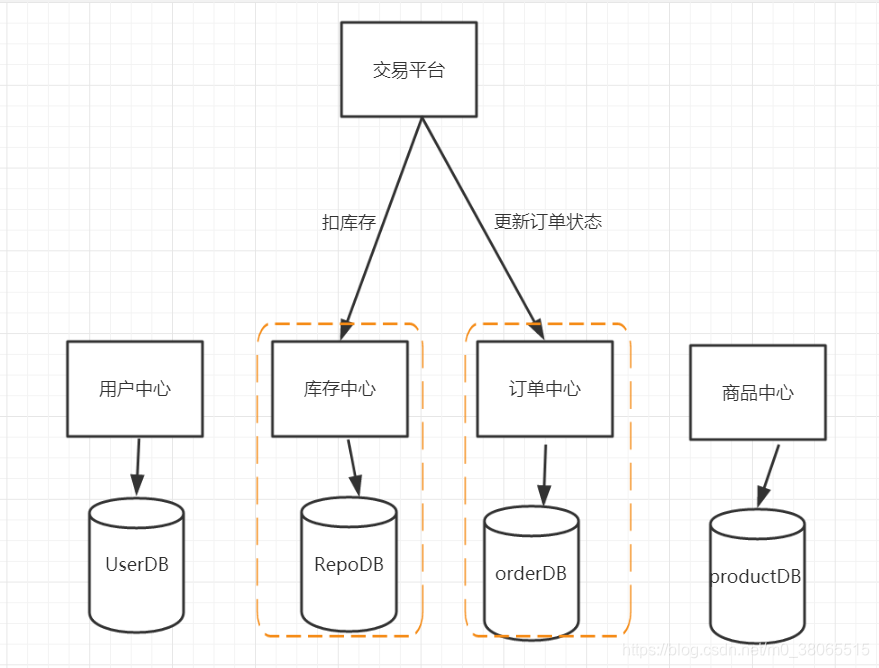
2、展示分布式框架中出现事务的情况
@Test
public void transactionTest() {
try {
orderService.transactionTest();
} catch (Exception e) {
e.printStackTrace();
}
}
orderService服务中的代码:
@Transactional(rollbackFor = Exception.class)
public void transactionTest() throws Exception {
VipOrder vipOrder = new VipOrder();
vipOrder.setVipOrderId(IDGenerater.nextId());
vipOrderMapper.insertSelective(vipOrder);
UserVip userVip = new UserVip();
userVip.setUserId(IDGenerater.nextId());
userVipService.transactionTest(userVip);
throw new Exception("插入数据自定义异常");
}
userService服务中的代码
@Override
public int transactionTest(UserVip userVip) {
return userVipExtendMapper.insertSelective(userVip);
}
以上代码,在orderService服务中添加@Transactional(rollbackFor = Exception.class)事务,抛出自定义异常,只会对orderService服务中的insert语句进行回滚操作,而userService中的insert则插入成功,这样就造成了分布式事务。

















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









