






话不多说,上代码
from selenium.webdriver import Edge
from urllib.request import urlretrieve
from selenium.webdriver.common.by import By
#download image from imgurl
def urllib_download(url,save_path):
urlretrieve(url, save_path)
def get_images(driver,text,times):
driver.get('某网站.com')
driver.find_element_by_id('kw').send_keys(text)#'美伊礼芽')
driver.find_element_by_class_name('s_btn_wr').click()
currenturl = driver.current_url
driver.get(currenturl)
for t in range(times):
js = "window.scrollBy(0,5000)"
driver.execute_script(js)
items=driver.find_elements(by=By.XPATH, value='//li[contains(@class,"imgitem")]')
i = 0
for imgitem in items:
img_url = imgitem.get_attribute('data-objurl')
print(f'Saving {img_url}')
save_path = 'image/myly_' + str(i) + '.' + img_url.split('.')[-1]
urllib_download(img_url, save_path)
i += 1
测试一下吧~
if __name__=="__main__":
driver=Edge()
text='美伊礼芽'
times=100
get_images(driver,text,times)
看看我小美的美照~~
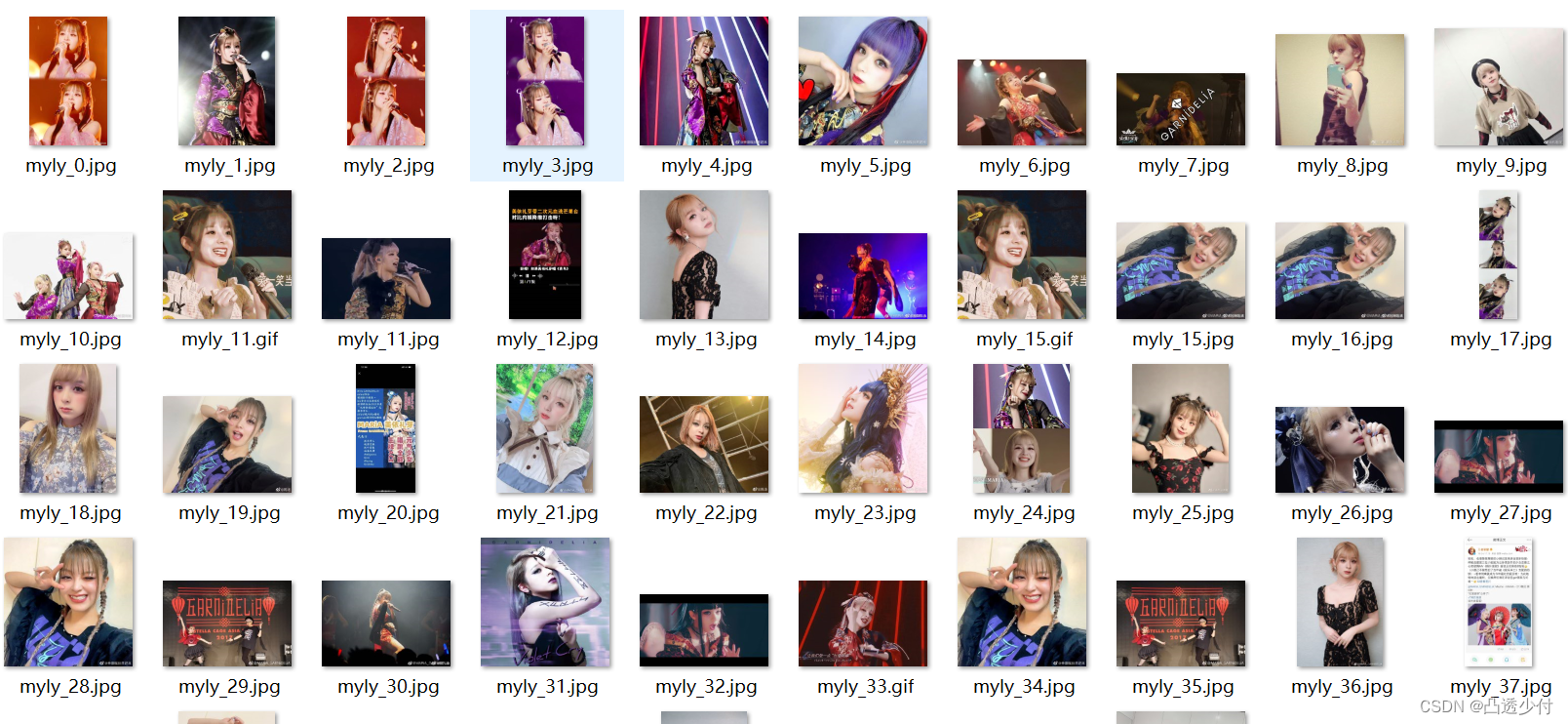
代码里面有很多细节也,二阳太难受了,不想动脑子一一解释了,就酱吧先

















 4646
4646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









