






 本文介绍了使用递归和层次遍历两种方法解决完全二叉树节点连接问题的代码实现。通过递归函数setNext处理节点连接,并采用队列实现层次遍历,确保每层节点正确连接,特别关注边界条件处理。
本文介绍了使用递归和层次遍历两种方法解决完全二叉树节点连接问题的代码实现。通过递归函数setNext处理节点连接,并采用队列实现层次遍历,确保每层节点正确连接,特别关注边界条件处理。
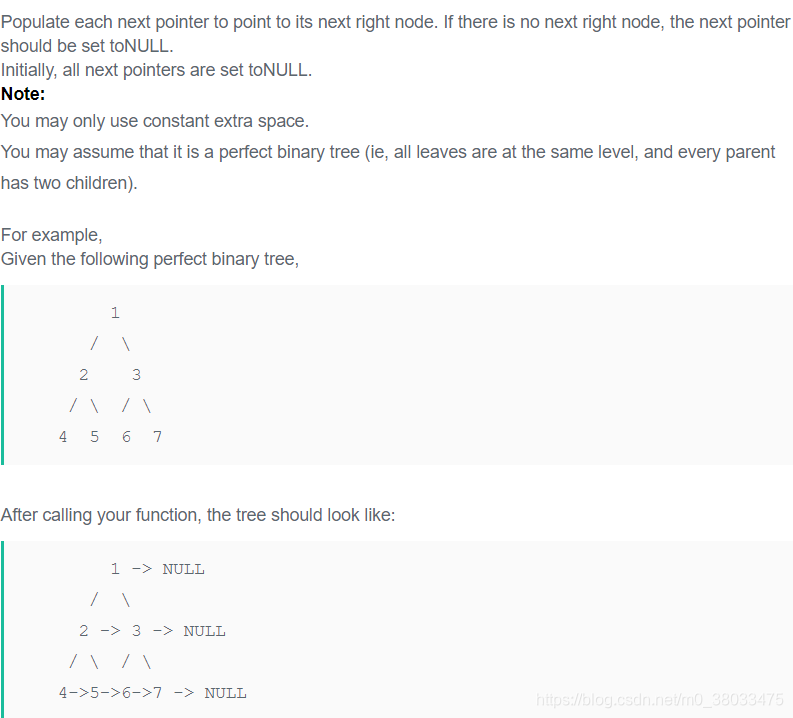
这个我自己一次性AC了,因为是完全二叉树,比较好讨论,用递归来做的。
AC代码:
/**
* Definition for binary tree with next pointer.
* struct TreeLinkNode {
* int val;
* TreeLinkNode *left, *right, *next;
* TreeLinkNode(int x) : val(x), left(NULL), right(NULL), next(NULL) {}
* };
*/
class Solution {
public:
void setNext(TreeLinkNode *h, int isLeft, TreeLinkNode *pre)
{
if(isLeft==1)
h->next=pre->right;
else
{
if(pre==NULL)
h->next=NULL;
else
h->next=pre->left;
}
//对它下面的结点进行递归
if(h->left==NULL && h->right==NULL)
return;
else
{
setNext(h->left,1,h);
setNext(h->right,0,h->next);
}
}
void connect(TreeLinkNode *root) {
//思路:setNext(h,isleft,pre) //isleft=1则为左,传入共同根节点指向pre->right;
//isleft=0则为右,传入根节点->next指向next->left,若pre为空则指向空
if(root==NULL)
return;
if(root->left==NULL && root->right==NULL)
return;
setNext(root->left,1,root);
setNext(root->right,0,NULL);
}
};
Populating Next Right Pointers in Each Node II

大致思路:
想在第一问的代码基础上进行进一步的情况讨论(传了root和root->next两个指针,分别判空分别处理),但出现了“递归过多+超时”的问题。
看题解恍然大悟,这就是层次遍历!对每一层的结点进行连接。用队列实现。
但是有个判断条件很磨人,我刚开始以为:q.size()==0就表示结点到达了该层的最右边缘,设其next=NULL。但是没考虑好的点在于:我在对该层的每个点进行处理的时候,设置next之后还需要将其的孩子入队,所以你该层的最右边缘的结点并不会一定满足“队列为空”。
那怎么样可以判断,该层到达了最右边缘呢?
思路是,在每进入一层时,该层的结点都已经全部入队了,所以此时先求队的长度len=q.size(),以len次的for循环来处理len个结点,这len个结点都是这一层的,直到i==len-1则说明该层的最后一个结点即最右边缘的结点,设其->next=NULL。
AC代码:
/**
* Definition for binary tree with next pointer.
* struct TreeLinkNode {
* int val;
* TreeLinkNode *left, *right, *next;
* TreeLinkNode(int x) : val(x), left(NULL), right(NULL), next(NULL) {}
* };
*/
class Solution {
public:
void connect(TreeLinkNode *root) {
if(root==NULL)
return;
if(root->left==NULL && root->right==NULL)
return;
//层次遍历的思想,用队来存储
queue<TreeLinkNode*>q;
q.push(root);
while(q.size()!=0)
{
int len = q.size(); //这里先取长度,然后一个for循环把该层的结点都处理了
for(int i=0;i<len;i++) //len次
{
TreeLinkNode* p = q.front();
q.pop();
//先解决自己的next问题
if(i==len-1) //这里没一次性写对。有可能有孩子,但该结点仍在右边缘!
p->next=NULL;
else
p->next=q.front();
//再入队自己的孩子
if(p->left!=NULL)
q.push(p->left);
if(p->right!=NULL)
q.push(p->right);
}
}
}
};

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









