




【PoseContrast】
PoseContrast: Class-Agnostic Object Viewpoint Estimation in the Wild with Pose-Aware Contrastive Learning
1、任务
这里的pose指以image的视角,3D model应该如何旋转,能够和image中的object重合。

2、创新点
(1)class-agnostic
之前的任务都是要提前知道/预测object的类别,采用image embedding和3D model embedding相结合,然后再联合地进行pose estimation。
但这样的话是很依赖3D model数据集的,而我们一般可能只有照片,没有对应的3D model。
因此,作者提出无需预测3D model类别,且不采用3D model的信息,直接根据single image来进行pose estimation。
(2)pose-aware 对比学习
(2.1)自行进行数据增强
制造anchor的正例(分为两种:pose-variant和pose-invariant),pose相关的就是flip、rotate,pose无关的就是noise、color、blur、crop。
(2.2)在对比学习损失函数Info-NCE的基础上加入了pose-aware
对于负例,有可能是跟anchor的pose一致或相似的,不应给予过多惩罚。
所以这里会对Rotation向量进行距离运算,将距离作为参数放到Info-NCE中,修改了对比学习的损失函数。由此,pose相差越大,则负例的惩罚越大,拉得越远。
3、模型
(1)模型的损失函数结合了Pose-aware Info-NCE和angle loss。前者是创新点里说的,后者是对rotation角度作为分类问题(分bin)的交叉熵以及在bin中的offset的拟合损失。
(2)模型结构极其简单,将image输入ResNet-50,得到2048维的embedding再输入3个MLP。
4、实验和结果
(1)评价指标:Acc30和MedErr(Acc30 is the percentage of estimations with rotation error less than 30 degrees; MedErr is the median angular error in degrees.)
(2)数据集:Pascal3D+ ObjectNet3D Pix3D
(3)实验
- 全部class可见:效果最好(应该是针对pose的对比学习起的作用)
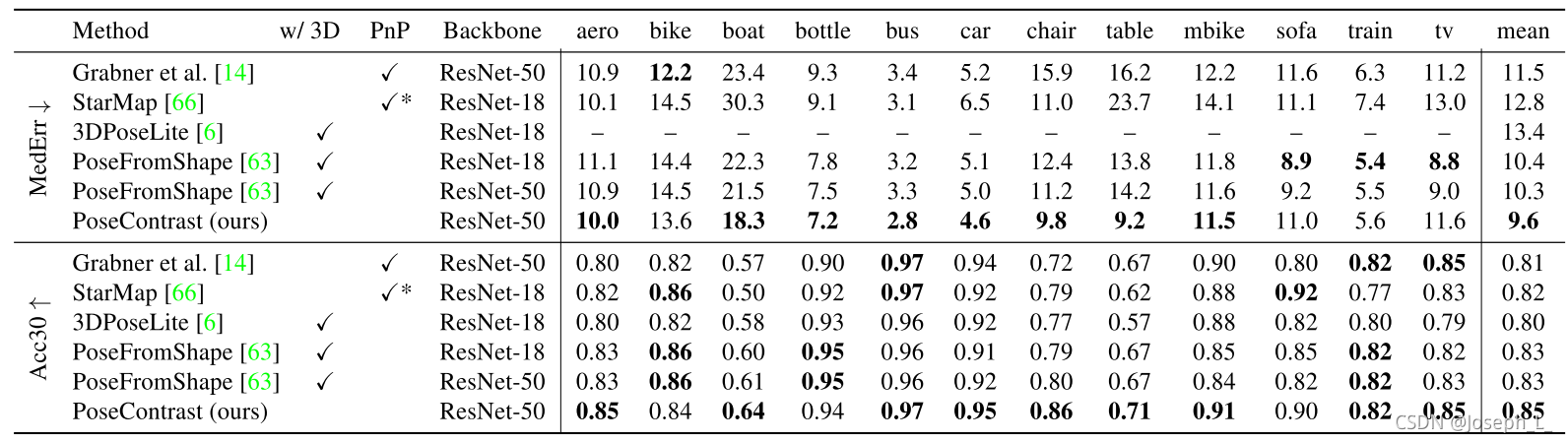
- 对unseen classes的测试:在Pascal3D+上训练,在Pix3D上进行测试。其中,测试集中有6个类是训练集中有的,但还有3个类(table sofa chair)是没见过的。同时还对Bounding Box采用ground truth还是pred进行对比。

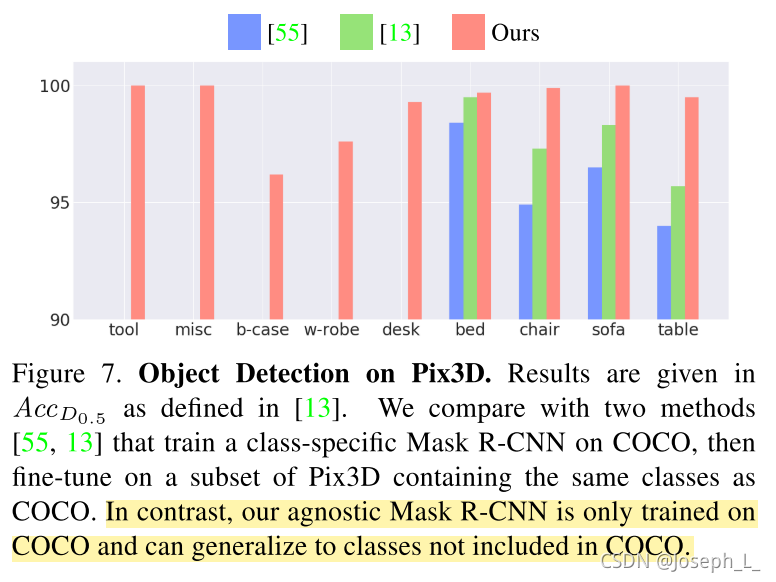
- 目标检测采用class-agnostic,效果会更好。
-
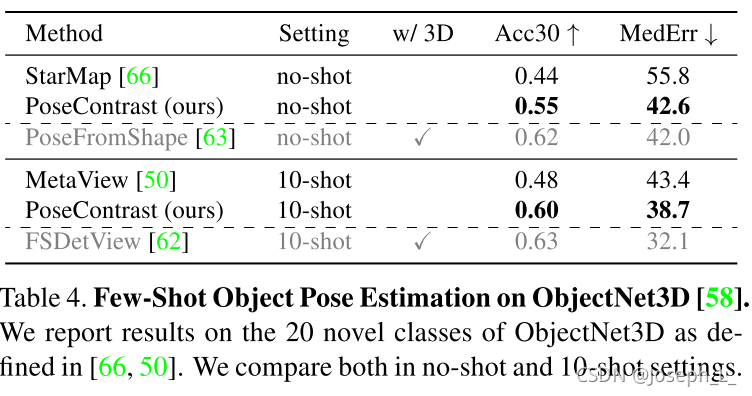
no-shot和few-shot实验
实验发现,采用3D model的信息,在两种情况下都是最好的。自己仅仅是在不用3D model信息的情况下达到SOTA。
这应该是因为对比学习可用的数据量过少,导致效果不佳。
- 消融实验:主要是体现对比学习pose-aware NCE的有效和必要性。还探讨了下rotation距离的计算方法。

- 作者自己提出的缺点:如果object变形,或者是对称结构,结果误差大。(对称结构的话应该是要界定旋转角度一共就180度而非360度)

5、一些理解和感受
这里的对比学习既然是联合了angle-loss的,那么实际上还是有标签的。之前自然语言里面的对比学习基本是数据增强+自监督地区分正负例,但这里一旦要融入angle-aware的设计,就必须要有预测angle并计算angle loss,需要angle标签。
【3D Pose Estimation and 3D Model Retrieval for Objects in the Wild】
先根据image,通过PnP算法来预测pose,然后把cad model进行相应的pose操作。之后,分别对image和cad model这种RGB image通过CNN来得到人工的depth表示(无需ground truth的深度图)。然后基于两个深度的表示,来学习triplet loss。
【Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image】
想要将image和cad model投影到同一个embedding space中。
创新点在于,采用patch的思想,仅仅是分别对image和cad model进行局部的采样,然后进行对比学习(image的正例采用ground truth的cad model的patch,负例就是其他的cad model的patch,但是考虑到有可能负例的patch会比较相似,从而扰乱对比学习效果,会提前通过IOU来设个阈值,保证得到的负例都很不同;然后还采用hard negative mining——我这里理解是,找top k个计算出来embedding distance最近的负例,选择它们来进行对比学习的拉远操作,这样更有利于识别difficult cases)。
对于测试的话,就是从image中取样K_q个patch,每个patch分别找top K_r个相似的patch,看这些patch是从哪些cad model里来的,从而进行投票,从而有K_q个cad model结果,然后再进行投票,确定最终应该对应哪个cad model。
pose estimation仍然是联合的任务,分bin和offset预测。
效果方面,在ScanNet数据集(比较多image中是不完整的object)上效果最好,但在Pix3D上效果没有利用了全部shape信息的Mask2CAD好。

















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









