







 本文从集中式到分布式系统的发展背景出发,详细介绍了分布式系统的基本特征和CAP定理,阐述了BASE理论在分布式环境中的应用。接着,讨论了2PC和3PC协议在分布式事务中的作用,以及它们的优缺点。最后,提出了几种常见的分布式事务解决方案,如TCC、本地消息表和可靠消息最终一致性,并简要介绍了Seata分布式事务框架及其AT和TCC模式。
本文从集中式到分布式系统的发展背景出发,详细介绍了分布式系统的基本特征和CAP定理,阐述了BASE理论在分布式环境中的应用。接着,讨论了2PC和3PC协议在分布式事务中的作用,以及它们的优缺点。最后,提出了几种常见的分布式事务解决方案,如TCC、本地消息表和可靠消息最终一致性,并简要介绍了Seata分布式事务框架及其AT和TCC模式。
从集中式到分布式
20世纪60年代大型主机被发明出来,凭借其安全性和稳定性的表现成为主流。但从20世纪80年代以来,计算机系统向网络化和微型化的发展日趋明显,传统的集中式处理模式越来越不能适应人们的需求。
集中式最明显的问题就是单点。
随着PC机性能的不断提升和网络技术的快速普及,大型主机的市场份额变得越来越小,很多企业开始放弃原来的大型主机,而改用小型机和普通PC服务器来搭建分布式计算机。
分布式
什么是分布式系统?
“
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。
”
一个标准的分布式系统会有以下特征:
-
分布性(多台计算机在空间上随意分布)
-
对等性(副本是分布式系统最常见的概念之一)
-
并发性
-
缺乏全局时钟(缺乏一个全局的时钟序列控制)
-
故障总是发生
从集中式向分布式演变的过程中,必然引入了网络因素,而由于网络本身的不可靠性也引入额外的问题:
-
通信异常
-
网络分区(俗称:“脑裂”)
-
节点故障
虽然问题多多,但总有办法解决,就像解题有公式一样,分布式也有相应的理论支撑,比如:CAP定理和BASE理论。
CAP
“
2000年7月,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出CAP猜想。2年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP。之后,CAP理论正式成为分布式计算领域的公认定理。
”
CAP定理告诉我们:一个分布式系统不可能同时满足一致性(C:Consistency),可用性(A:Availability)和分区容错性(P:Partition tolerance)这三个基本要求,最多只能同时满足其中的两项。
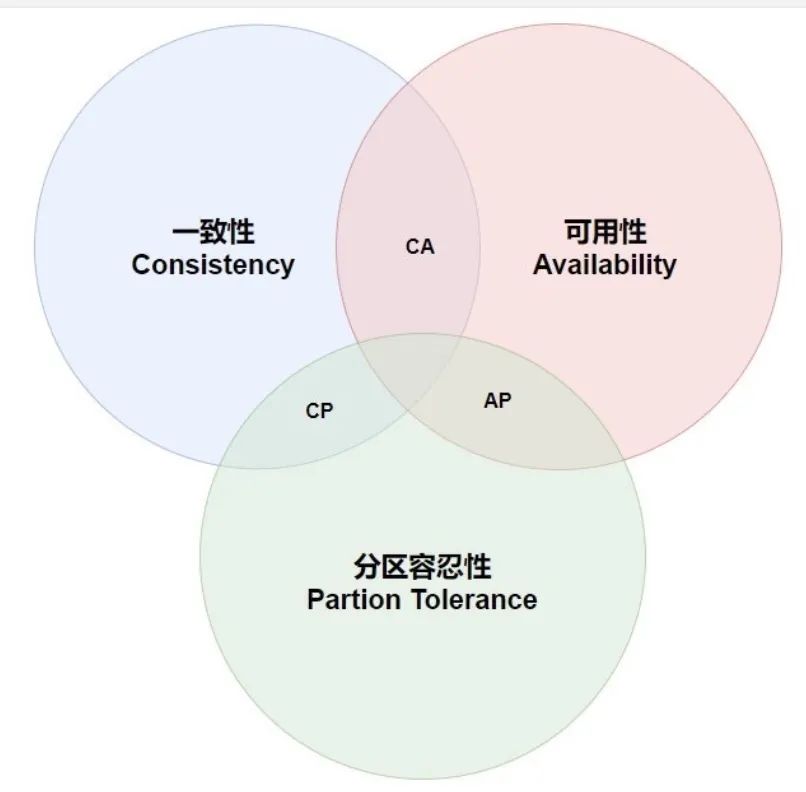
-w403
-
一致性 每次读取都能读到最新的写入或错误,等同于所有节点访问同一份最新的数据副本。
-
可用性 每个请求都会收到一个(非错误)响应,但不能保证它包含最新的写操作。
-
分区容错性 尽管节点之间的网络丢弃或延迟了任意数量的消息,但系统仍继续运行。
当网络分区发生故障时,我们应该决定
-
取消操作,从而降低可用性,但确保一致性
-
继续进行操作,从而提供可用性,但存在不一致风险
举例子:
以下是一个有3个结点的系统拓扑: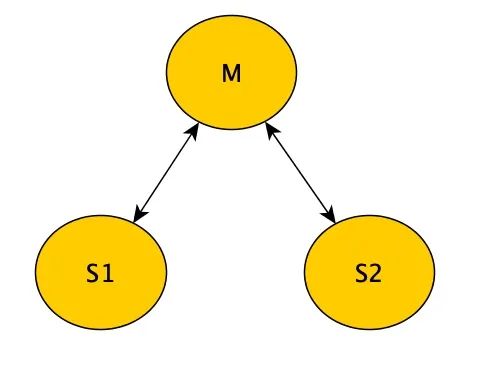
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
假设 M到S1的通信失败,或S1结点挂了,那么就有S1、M和S2这两个分区。
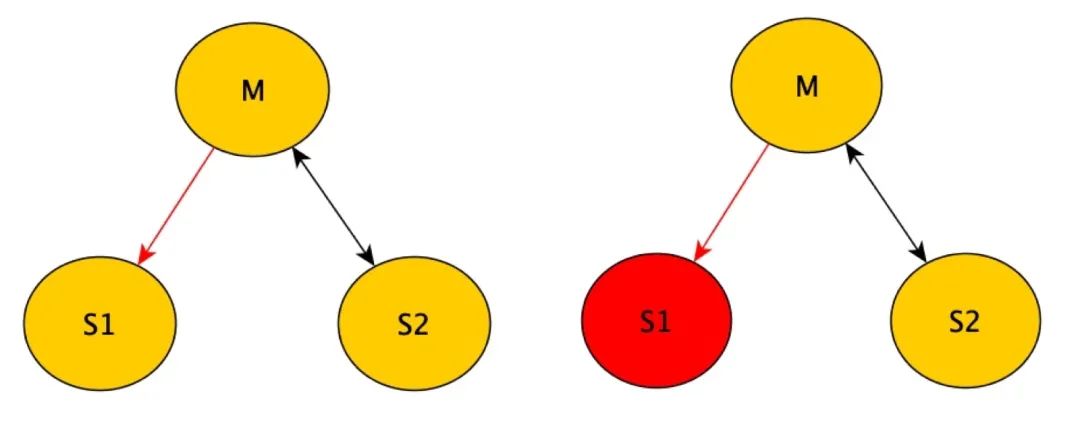
在这种情况下,我们是要容忍的,也就是说在这种情况下,系统还是要能提供服务的,不能因为这样的分区问题整体不能提供服务了。
根据CAP定理所得,CAP只能取其二,我们已经保证了P,那么就只能在C和A之间做选择。
-
选择AP,保证可用性 即让S1、M和S2这两个分区同时提供服务,保证系统的可用,但问题很明显,由于数据不能在M和S1之间同步,而一致性要求每次读取都能读到最新的写入或错误,所以无法保证数据一致性。
-
选择CP,保证一致性 在M和S1无法建立通信的这段时间,系统要进行错误恢复,恢复的这段时间系统对外是不可用状态,而可用性要求每个请求都会收到一个响应,所以无法保证可用性。恢复完成后,系统在可用状态下的数据是一致的,保证了一致性。
注意:上述当我们放弃一致性是指放弃数据的强一致性,而保留数据的最终一致性,这样的系统无法保证数据保持实时的一致性,但是能够承诺的是,数据最终会达到一个一致的状态,这就引入了一个时间窗口的概念,具体多久能够达到数据一致取决于系统的设计,主要包括数据副本在不同节点之间的复制时间长短。面对CAP,在做系统设计时我们会把
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









