










LeetCode详解系列的上一题链接:LeetCode详解之如何一步步优化到最佳解法:9. 回文数-优快云博客
目录
13. 罗马数字转整数
本题题目链接:13. 罗马数字转整数 - 力扣(LeetCode)
解法1:暴力解法
代码:
class Solution:
def romanToInt(self, s: str) -> int:
the_result = 0
store = []
for s_current_bit in s:
if not store:
store.append(s_current_bit)
else:
temp = store.pop()
if temp == "I":
if s_current_bit == "V":
the_result += 4
elif s_current_bit == "X":
the_result += 9
else:
the_result += 1
store.append(s_current_bit)
elif temp == "V":
the_result += 5
store.append(s_current_bit)
elif temp == "X":
if s_current_bit == "L":
the_result += 40
elif s_current_bit == "C":
the_result += 90
else:
the_result += 10
store.append(s_current_bit)
elif temp == "L":
the_result += 50
store.append(s_current_bit)
elif temp == "C":
if s_current_bit == "D":
the_result += 400
elif s_current_bit == "M":
the_result += 900
else:
the_result += 100
store.append(s_current_bit)
elif temp == "D":
the_result += 500
store.append(s_current_bit)
else:
the_result += 1000
store.append(s_current_bit)
if store:
temp = store.pop()
if temp == "I":
the_result += 1
elif temp == "V":
the_result += 5
elif temp == "X":
the_result += 10
elif temp == "L":
the_result += 50
elif temp == "C":
the_result += 100
elif temp == "D":
the_result += 500
else:
the_result += 1000
return the_result解法性能:
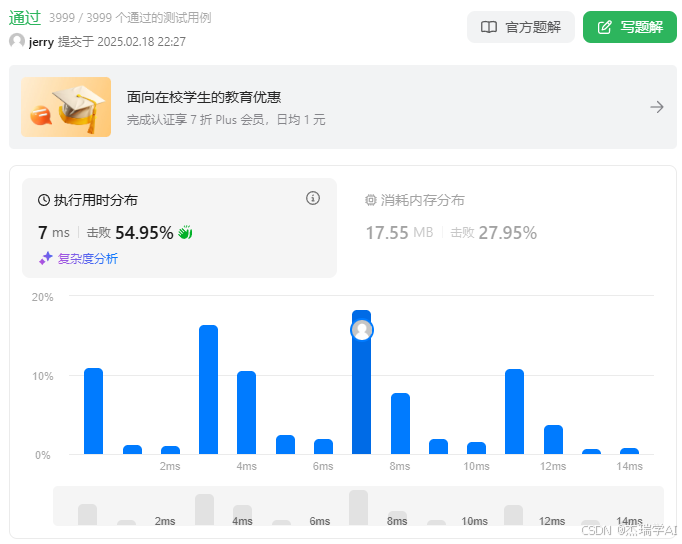
解法分析:
根据题目的指示,罗马数字的计算涉及到一些特例,并且这些特例都涉及到前后两个字符之间的关系。因此,我们在遍历这个字符串之前,设定了一个列表”store”用来在需要的时候存储前一个字符,以方便我们的比较。并且,设定了一个变量”the_result”用来储存最后的结果。
接着,遍历输入的字符串,对于每一个字符,如果当前列表为空,则表示字符串的第一个字符,或者前面的所有字符已经处理完毕。在这种情况下,我们将当前的字符存储起来,用于和下一个字符进行比较。对应的代码如下所示:
if not store:
store.append(s_current_bit)如果当前列表不为空,则列表中存储的是前一个字符,我们将这个字符取出来,并和当前的字符一起进行判断,针对特例进行特殊的处理。具体来说,先判断列表中存储的字符是哪一个字符,然后再根据当前的字符,选择如何处理输出的结果。对应的代码如下所示:
temp = store.pop()
if temp == "I":
if s_current_bit == "V":
the_result += 4
elif s_current_bit == "X":
the_result += 9
else:
the_result += 1
store.append(s_current_bit)
elif temp == "V":
the_result += 5
store.append(s_current_bit)
elif temp == "X":
if s_current_bit == "L":
the_result += 40
elif s_current_bit == "C":
the_result += 90
else:
the_result += 10
store.append(s_current_bit)
elif temp == "L":
the_result += 50
store.append(s_current_bit)
elif temp == "C":
if s_current_bit == "D":
the_result += 400
elif s_current_bit == "M":
the_result += 900
else:
the_result += 100
store.append(s_current_bit)
elif temp == "D":
the_result += 500
store.append(s_current_bit)
else:
the_result += 1000
store.append(s_current_bit)当遍历完整个字符串后,如果列表还是非空状态,说明字符串的最后一个字符被存储在了列表中,且倒数第二个字符已经被处理过(如果有倒数第二个字符的话)。此时,我们对这个最后一个字符进行单独的处理:
if store:
temp = store.pop()
if temp == "I":
the_result += 1
elif temp == "V":
the_result += 5
elif temp == "X":
the_result += 10
elif temp == "L":
the_result += 50
elif temp == "C":
the_result += 100
elif temp == "D":
the_result += 500
else:
the_result += 1000最终,整个字符串处理完毕,输出结果。
虽然这个解法能通过LeetCode的检测,但是,我们可以看到这个代码写的非常的长(这个类总共有64行),而且,含有很多的if-elif-else结构,整体很复杂。
那,我们优化的第一步就是看看如何去除这么多的if-elif-else结构。首先,我们知道罗马数字中的每一个字符都对应唯一的数值,即含有一一对应的mapping关系。而且根据上面处理最后一个字符的代码,以及处理for循环的代码,我们可以想到是否可以用一个python字典来包含所有的字符和数值对应的关系,让这些重复的if-elif-else的判断用尽可能短的代码就能实现呢?
答案是可以的,我们可以在最开始设定一个字典来存储这个mapping关系,具体的代码将在解法2中呈现出来。接着,我们从题目中获取到一个重要的信息,即“输入s是一个有效的罗马数字”。这个信息对我们优化for循环起到很大的作用。因为输入是一个有效的罗马数字,所以我们在遍历字符串时,如果前一个字符对应的数值比当前字符对应的数值要小的话,这一对组合肯定是符合正常的情况的,即我们可以直接将当前字符对应的数值减去前一个字符对应的数值获得处理后的值,而不需要多几个if语句来判断属于哪一种情况。
综上,我们获得新的解法:
解法2:改进版1
代码:
class Solution:
def romanToInt(self, s: str) -> int:
mapping = {
"I": 1,
"V": 5,
"X": 10,
"L": 50,
"C": 100,
"D": 500,
"M": 1000
}
the_result = 0
store = []
for s_current_bit in s:
if not store:
store.append(s_current_bit)
else:
temp = store.pop()
if mapping[temp] < mapping[s_current_bit]:
the_result += (mapping[s_current_bit] - mapping[temp])
else:
the_result += mapping[temp]
store.append(s_current_bit)
if store:
the_result += mapping[store.pop()]
return the_result解法性能:
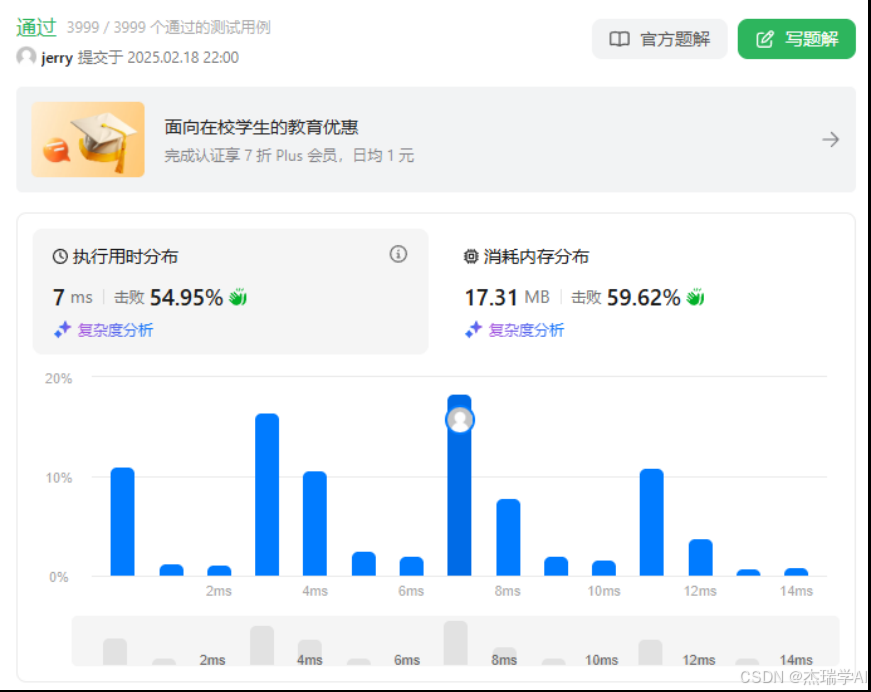
解法分析:
正如在解法1的分析中所述,我们在解法2的最开始处使用了一个字典来存储这个mapping关系。然后在for循环中,正如我们优化的第2点所述,当前一个字符所对应的数值小于当前字符所对应的数值时,我们取后者减前者的差值,存储到最终的结果中(它覆盖了所有有效的罗马数字中,前一个字符对应的数值小于当前字符对应的数值的情况)。若是大于等于的话,则将前一个字符对应的数值加到最后的结果中,然后,将当前的字符存储起来。从for循环的代码中,我们也能看到我们在取字符对应的数值时,直接是用字典的键值对机制快速获得,而省去了大部分的if-elif-else结构。
遍历完字符串后,如果还有一个字符没有处理的话,我们也是用字典快速获得对应的数值。
总体上来说,解法2比解法1优化了很多,结构上更加干净整洁,省去了很多冗长的结构。
接下来,我们进一步看看如何优化,是否能将最后一个字符的特殊处理也合并到前面的for循环中。于是,我们想想能不能将判断前一个字符和当前字符,改成判断当前字符和后一个字符。这样,我们就不需要存储一个字符供后面来判断了(这样就不用定义一个列表了)。而且,对于当前字符是倒数第二个字符的情况,如果当前字符对应的数值小于后一个字符对应的数值的话,则两个字符一起处理了;否则,将两个字符对应的数值分别加到最后的结果中(这两种情况下,最后一个字符都会被处理):
解法3:最终版
代码:
class Solution:
def romanToInt(self, s: str) -> int:
mapping = {
"I": 1,
"V": 5,
"X": 10,
"L": 50,
"C": 100,
"D": 500,
"M": 1000
}
the_result = 0
length = len(s)
for i, s_current_bit in enumerate(s):
current_bit = mapping[s_current_bit]
if i < length -1 and current_bit < mapping[s[i+1]]:
the_result -= current_bit
else:
the_result += current_bit
return the_result解法性能:
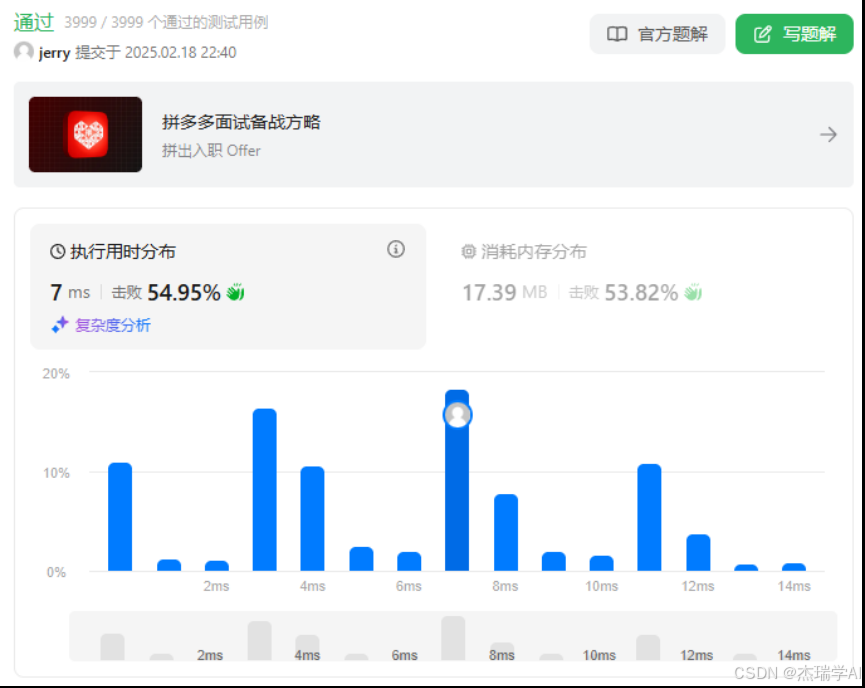
解法分析:
最终版的解法,将所有的处理合到一个for循环中,在前两个解法中存储数值的列表也不再需要。结构实现了尽可能的整洁。

















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









