







1 java集合类有哪些?
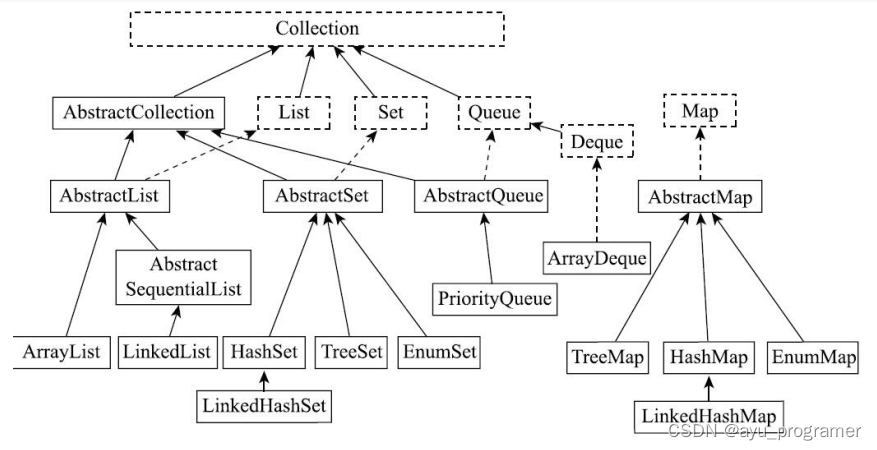
- List是有序的Collection,使用此接口能够精确的控制每个元素的插入位置,用户能根据索引访问List中元素。常用的实现List的类有LinkedList,ArrayList,Vector,Stack。
ArrayList是容量可变的非线程安全列表,其底层使用数组实现。当几何扩容时,会创建更大的数组,并把原数组复制到新数组。ArrayList支持对元素的快速随机访问,但插入与删除速度很慢。
LinkedList本质是一个双向链表,与ArrayList相比,,其插入和删除速度更快,但随机访问速度更慢。
Set不允许存在重复的元素,与List不同,set中的元素是无序的。常用的实现有HashSet,LinkedHashSet和TreeSet。
-
HashSet通过HashMap实现,HashMap的Key即HashSet存储的元素,所有Key都是用相同的Value,一个名为PRESENT的Object类型常量。使用Key保证元素唯一性,但不保证有序性。由于HashSet是HashMap实现的,因此线程不安全。
LinkedHashSet继承自HashSet,通过LinkedHashMap实现,使用双向链表维护元素插入顺序。
TreeSet通过TreeMap实现的,添加元素到集合时按照比较规则将其插入合适的位置,保证插入后的集合仍然有序。 -
Map 是一个键值对集合,存储键、值和之间的映射。Key 无序,唯一;value 不要求有序,允许重复。Map 没有继承于 Collection 接口,从 Map 集合中检索元素时,只要给出键对象,就会返回对应的值对象。主要实现有TreeMap、HashMap、HashTable、LinkedHashMap、ConcurrentHashMap
HashMap:JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突),JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间
LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
HashTable:数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
TreeMap:红黑树(自平衡的排序二叉树)
ConcurrentHashMap:Node数组+链表+红黑树实现,线程安全的(jdk1.8以前Segment锁,1.8以后CAS锁)
2 Hashmap原理介绍一下?
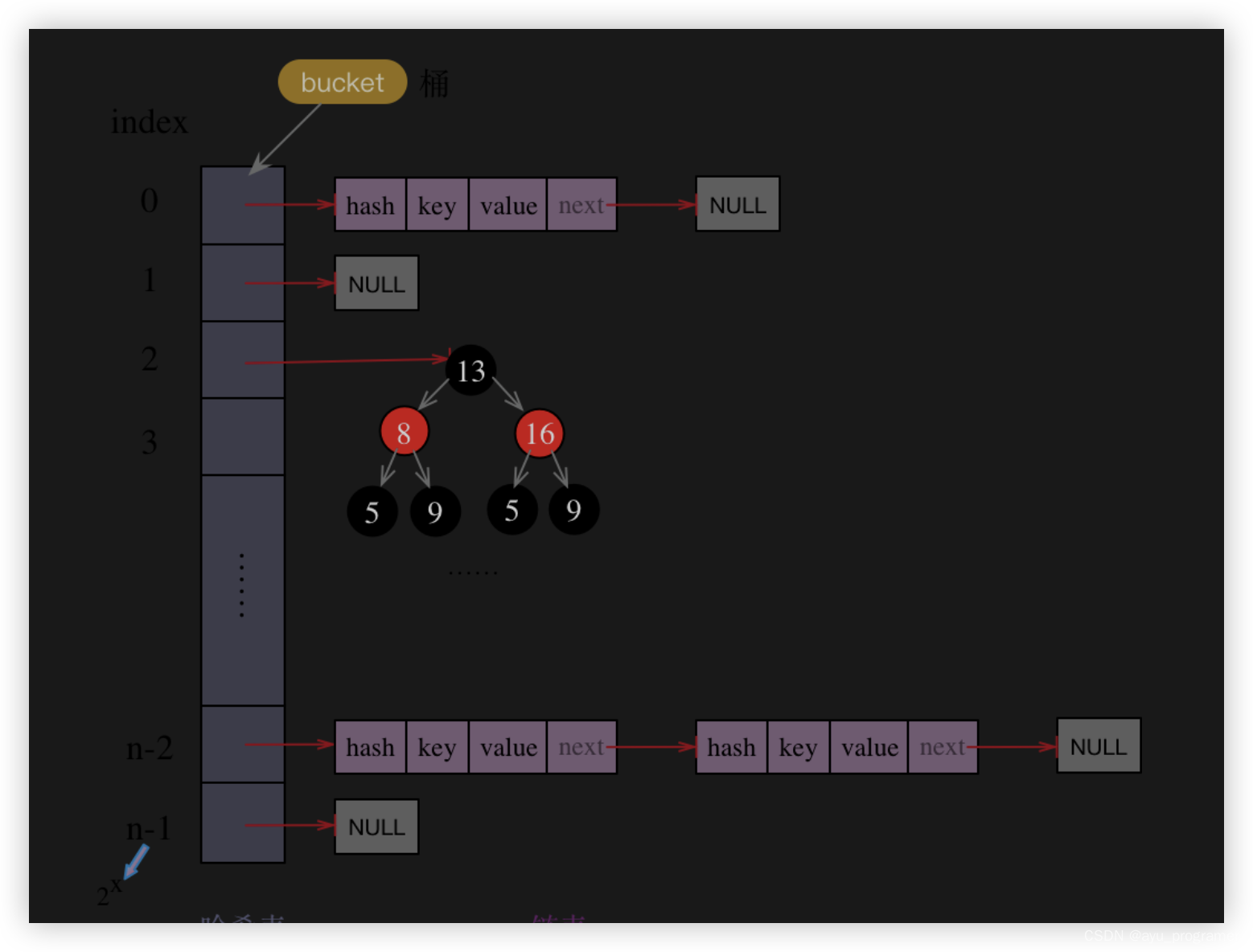
存储对象时,我们将K/V传给put方法时,它调用hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量(超过Load Facotr则resize为原来的2倍)。
获取对象时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。如果发生碰撞的时候,Hashmap通过链表将产生碰撞冲突的元素组织起来,在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。
3 hashmap为什么是线程不安全的?
JDK1.7 中,由于多线程对HashMap进行扩容,调用了HashMap#transfer(),具体原因:某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据已经被改变,造成死循环、数据丢失。
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
改善:
数据丢失、死循环已经在在JDK1.8中已经得到了很好的解决&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









