







 本文深入讲解Python内置的urllib库,包括其四个核心模块:request、error、parse和robotparser的功能与用法。通过实例演示如何使用urllib发送GET和POST请求,解析URL,处理异常,以及设置超时时间。
本文深入讲解Python内置的urllib库,包括其四个核心模块:request、error、parse和robotparser的功能与用法。通过实例演示如何使用urllib发送GET和POST请求,解析URL,处理异常,以及设置超时时间。
一.使用urllib
urllib库是Python内置的HTTP请求库,不需要安装就能直接使用。
它主要包含了以下四个模块:
- request:最基本的HTTP请求模块。
- error:异常处理模块
- parse:工具模块
- robotparser:
发送请求
使用urllib的request模块,可以方便的实现请求发送与响应。
1.urlopen()
爬取Python官网:
import urllib.request
response = urllib.request.urlopen(‘http://www.python.org’)
print(response.read().decode(‘utf-8’))

爬取的结果
以上是抓取到的网页源代码。
看下返回的类型,使用type()方法输出相应的类型:
import urllib.request
response = urllib.request.urlopen(‘http://www.python.org’)
print(tyoe(response))

输出结果如下:

它是一个HTTPResponse对象,包含 read()、 readinto ()、 getheader(name)、
getheaders() 、 fileno()等方法,以及 msg 、 version 、status 、reason 、debuglevel 、losed 等属性 。
得到对象后,把它赋值为response变量,就可以使用以上的对象和方法。

urlopen()函数的API:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
data参数
data 参数是可选的。如果要添加该参数,并且如果它是字节流编码格式的内容,即 bytes 类型,则需要通过 bytes()方法转化。如果传递了这个参数,则它的请求方式就不再是GET方式,而是POST方式 。
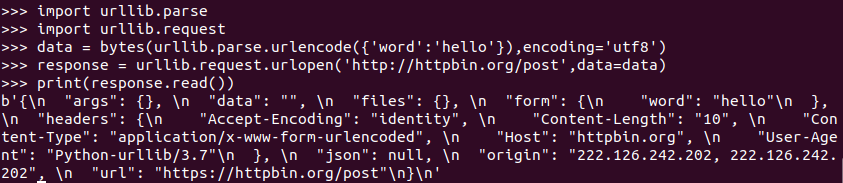
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({‘word’:‘hello’}),encoding=‘utf8’)
response = urllib.request.urlopen(‘http://httpbin.org/post’,data=data)
print(response.read())
timeout参数
timeout 参数用于设置超时时间,单位为秒,意思就是如果请求超 出 了设置的这个时间, 还没有得到响应 , 就会抛出异常。 如果不指定该参数 ,就会使用全局默认时间 。 它支持 HTTP , HTTPS 、 FTP请求 。
import urllib.request
response = urllib.request.urlopen(‘http://httpbin.org/get’,timeout=1)
print(response.read())



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









