







背景,在线迁移当前ES集群到新机器
当前:
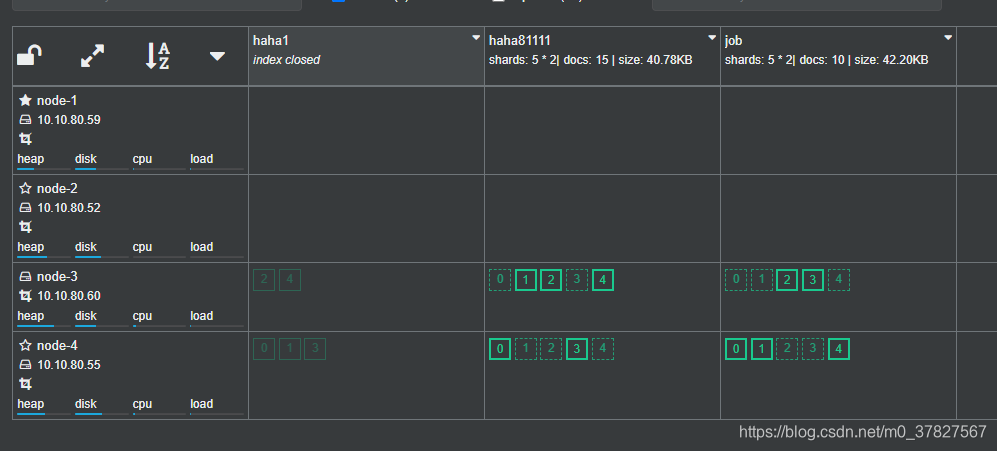
ES设计了集群分片的负载平衡机制,当有新节点加入集群或者离开集群,集群会自动平衡分片的负载分布
迁移目标:平滑迁移
迁移策略:
关闭集群自动平衡 自动平衡可能会带来网络以及IO压力
启动新节点与旧节点集群组成一个集群
人工迁移集群数据到新节点
外围 访问切换到新节点
关闭旧节点
开启集群自动平衡
迁移过程:
1.配置新集群
2.关闭集群自动平衡
GET _cluster/settings

可以通过动态方式更新:
#禁用集群新创建索引分配 禁用此选项将无法对最新的索引进行分配
cluster.routing.allocation.enable:none
#禁用集群自动平衡
cluster.routing.rebalance.enable:none
#限制索引的分布范围
“index.routing.allocation.include._ip”:“多个新集群IP”
KIBANA:
关闭自动分片
PUT _cluster/settings
{
"transient": {
"cluster.routing.rebalance.enable":"none"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.enable":"none"
}
}
cluster.routing.allocation.enable 设置成none,主要是影响集群中新创建的索引无法进行分片分配(把分片分配到某个节点上去)。
cluster.routing.rebalance.enable设置成none, 主要是影响集群中已有索引的分片不会rebalance到(迁移)其他节点上去
可以按照ip进行排除,也可以按照节点名进行排除,在对有索引得节点操作exclude时,该节点将自动迁移索引到集群其他节点
同时存在于exclude和include时 exclude优先
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "10.10.80.59"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.include._ip": "10.10.80.55,10.10.80.60,10.10.80.52"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": "node-1,node-2"
}
}
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.include._name": "node-4,node-3"
}
}
3.启动数据节点
此时不会自动平衡分片 由于cluster.routing.allocation.enable 设置成none 新建的索引将不会被分配
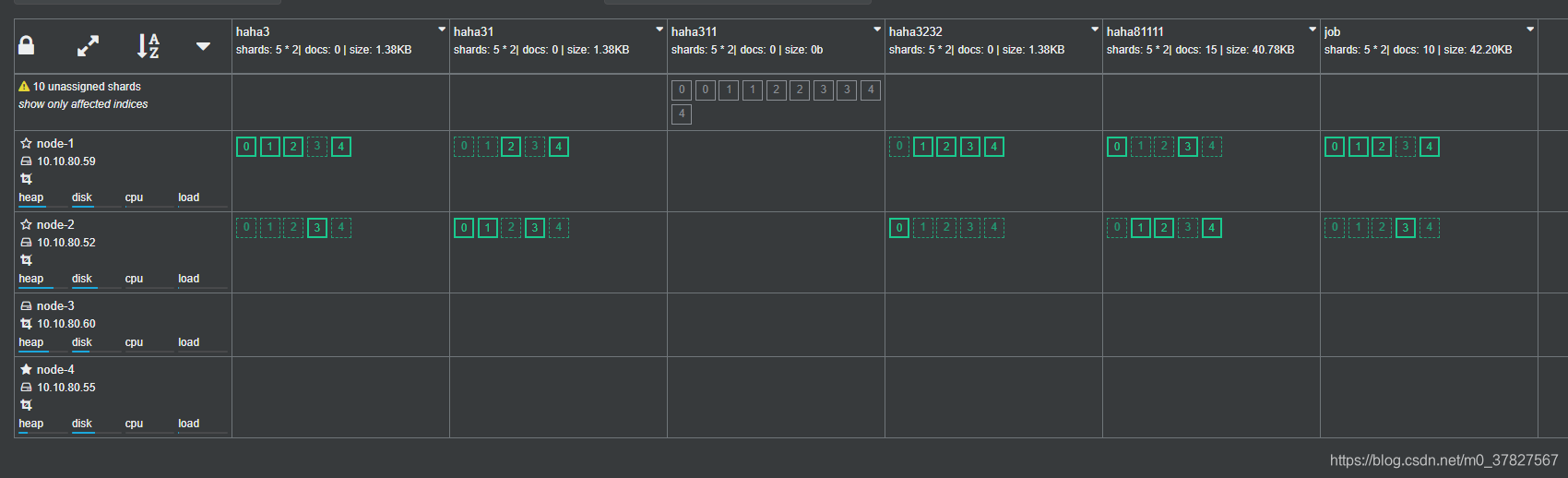
4.切换外部访问 通过新节点的IP来访问ES
5.修改副本数,手动迁移数据
修改索引副本数为0,加快迁移速度
kibana:job为索引名,
PUT job/_settings
{
“number_of_replicas”: 0
}
(如果索引多也可以通过脚本修改副本数)
curl -H “Content-Type: application/json” -XPUT ‘http://10.10.80.55:9200/haha3/_settings’ -d ‘{“index”: {“number_of_replicas”: “0”}}’
手动迁移:
1.获取所有索引名:参考脚本1 1es_prepare.sh
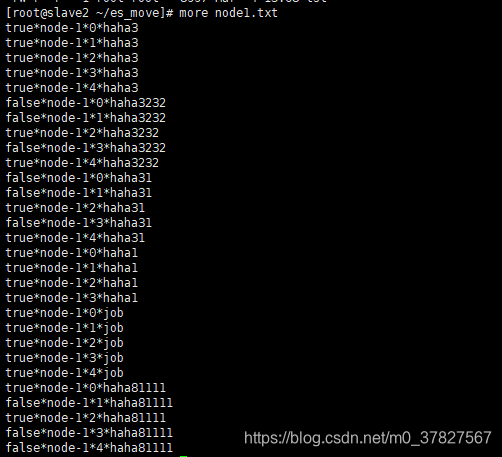
2。生成迁移语句:参考脚本2 按分片迁移 每个nodeX.txt都需要生成
sh 2make.sh node1.txt
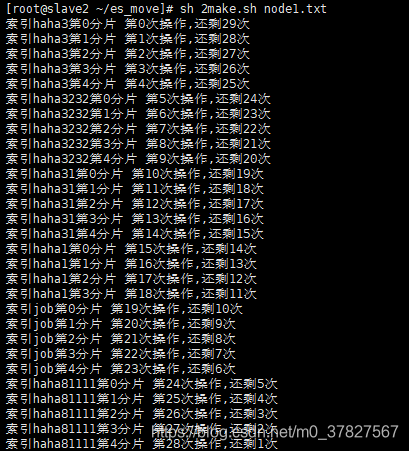
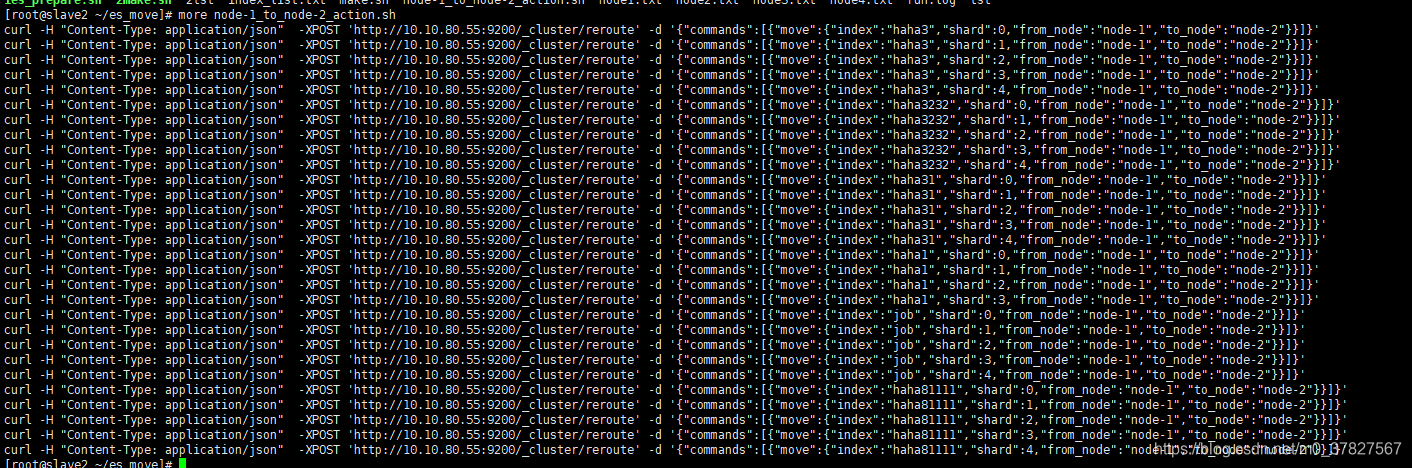
执行生成得命令 一个shard一个shard进行迁移 (本例由node1–>node3)
sh node-1_to_node-2_action.sh >run.log
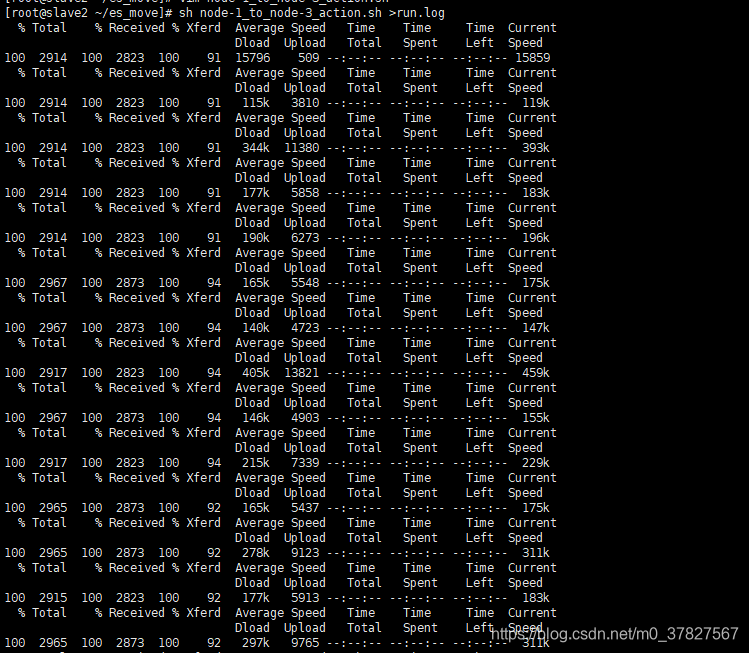
迁移前后:对比
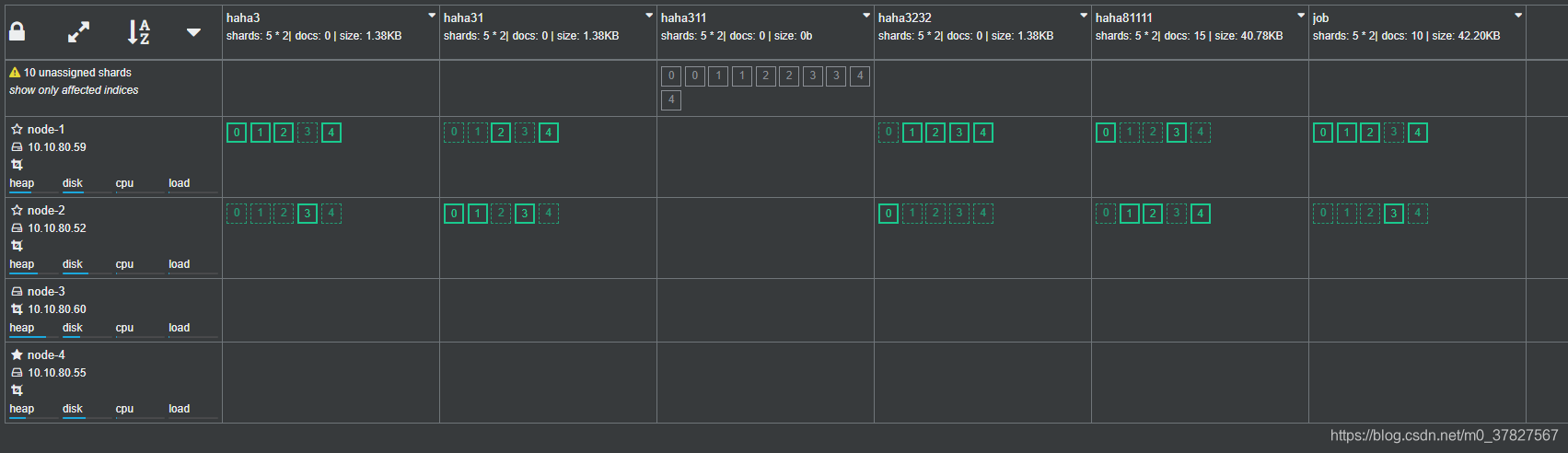
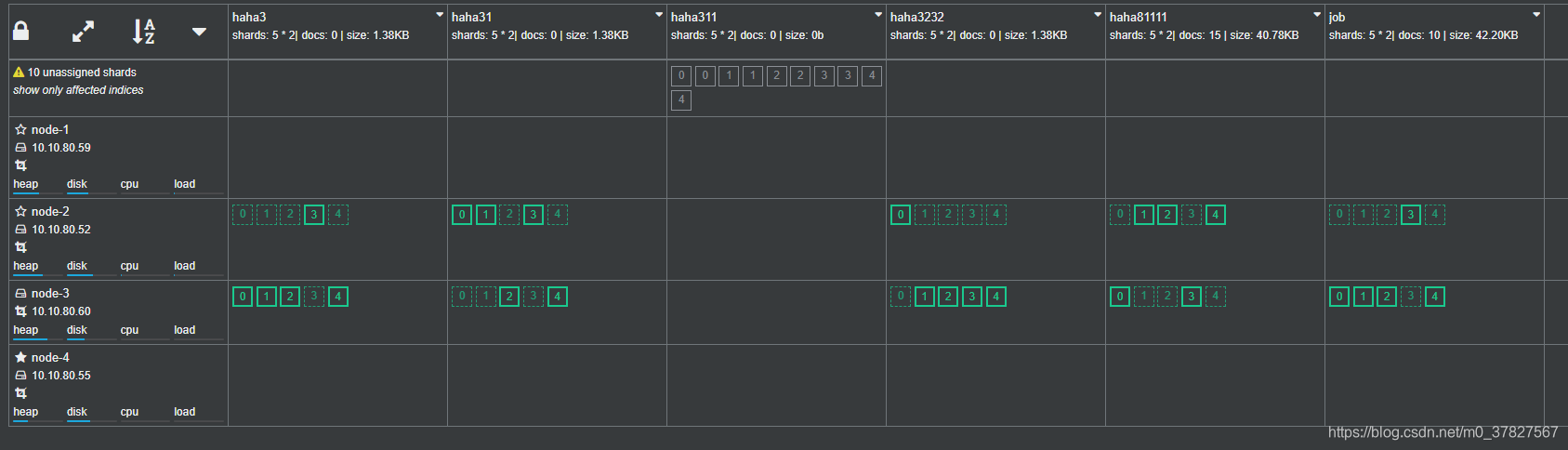
依次迁移
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









