






 本文是Hadoop学习笔记,详细介绍了Hadoop分布式文件系统HDFS的原理,包括数据和元数据概念,以及HDFS的设计目标和重要特性。此外,文章还探讨了HDFS的Shell操作和集群角色,最后讲解了YARN资源管理器的架构和三大组件。
本文是Hadoop学习笔记,详细介绍了Hadoop分布式文件系统HDFS的原理,包括数据和元数据概念,以及HDFS的设计目标和重要特性。此外,文章还探讨了HDFS的Shell操作和集群角色,最后讲解了YARN资源管理器的架构和三大组件。
文章目录
前言
提示:部分内容总结自https://www.bilibili.com/video/BV1CU4y1N7Sh?p=27&spm_id_from=pageDriver,仅供学习
Apache™ Hadoop® 是一个开源的, 可靠的(reliable), 可扩展的(scalable)分布式计算框架
- 允许使用简单的编程模型跨计算机集群分布式处理大型数据集
- 可扩展: 从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储
- 可靠的: 不依靠硬件来提供高可用性(high-availability),而是在应用层检测和处理故障,从而在计算机集群之上提供高可用服务
Hadoop优势
- 高可靠
- 数据存储: 数据块多副本
- 数据计算: 某个节点崩溃, 会自动重新调度作业计算
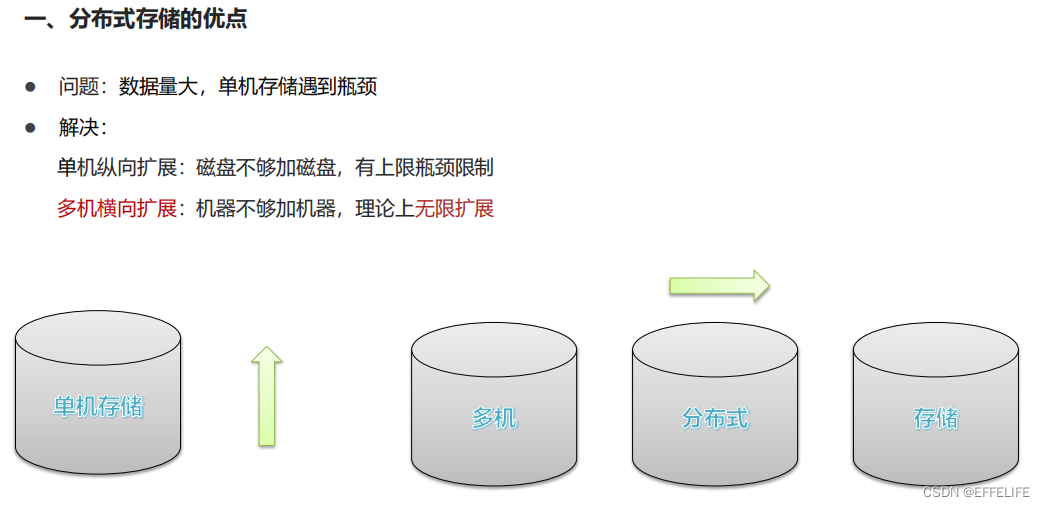
- 高扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器----横向扩展
- 一个集群中可以包含数以千计的节点–上万个
- 集群可以使用廉价机器,成本低
- Hadoop生态系统成熟—有啥bug都可以在google查到
一、Hadoop集群整体概述
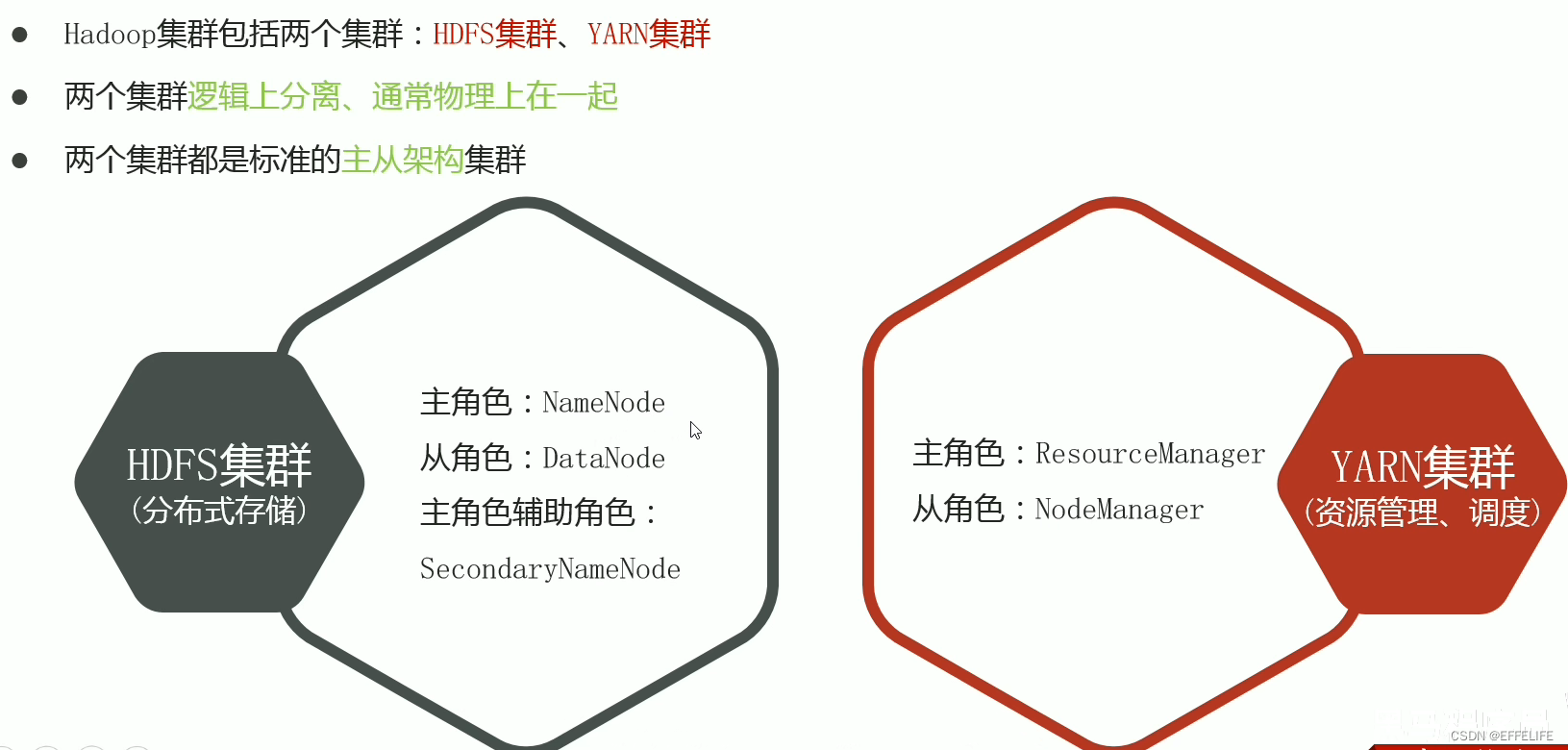
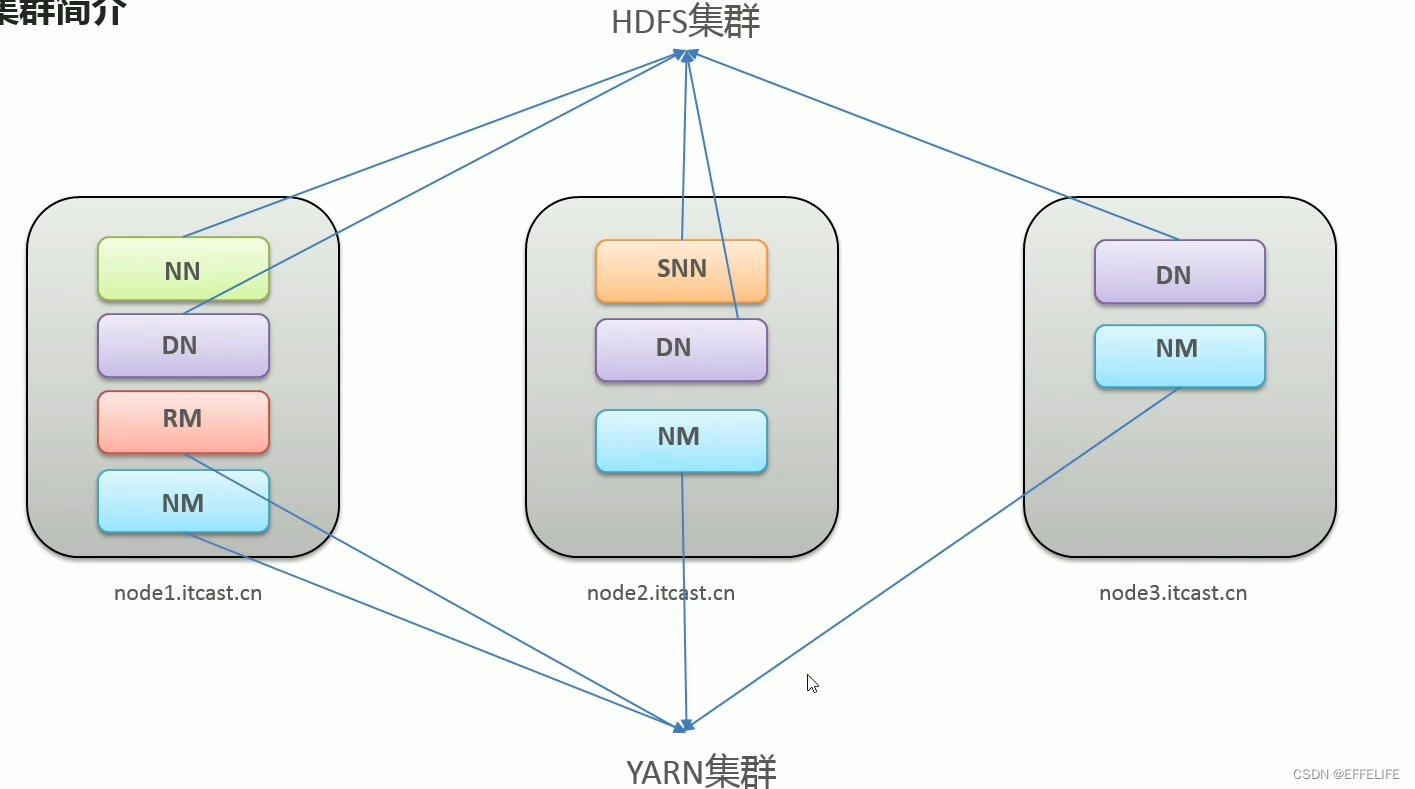
Hadoop集群 = HDFS集群 + YARN集群
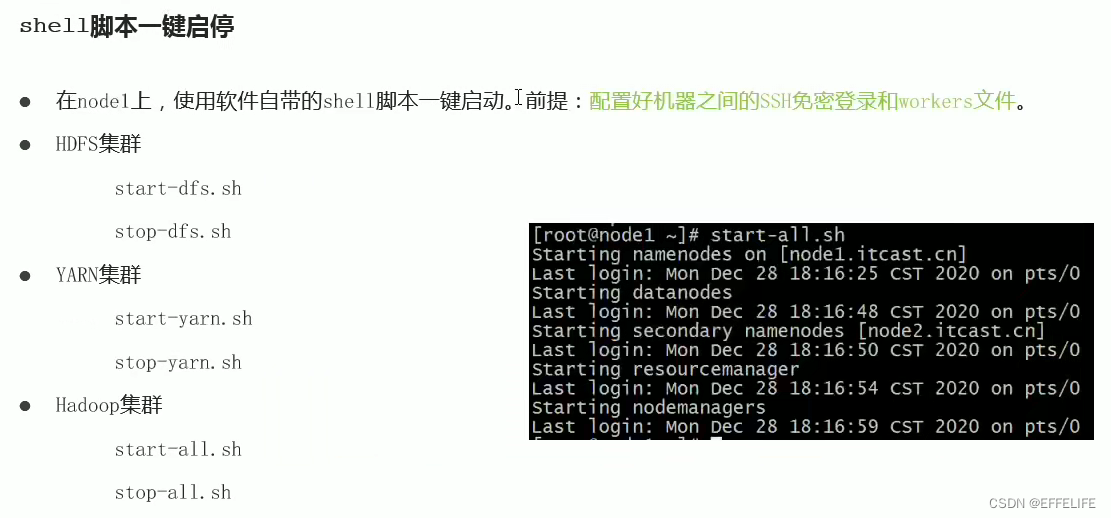
二、启动
三、HDFS分布式文件系统基础
数据
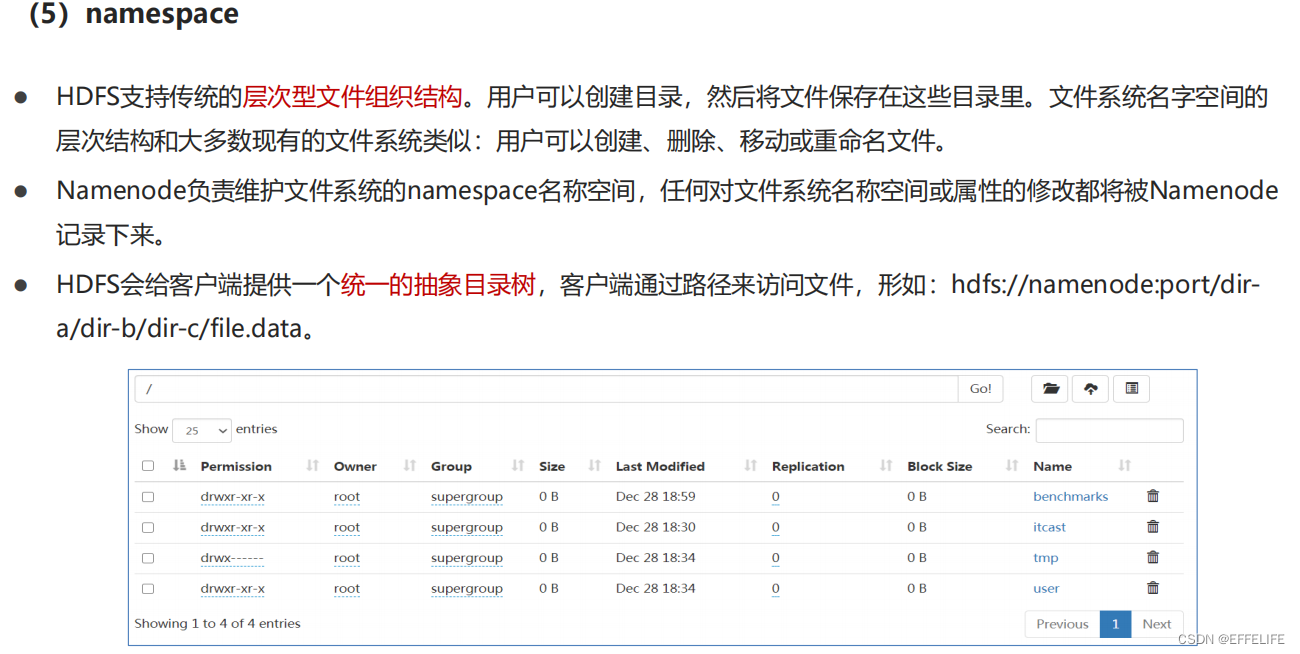
指存储的内容本身,比如文件、视频、图片等,这些数据底层最终是存储在磁盘等存储介质上的,一般用户无需关心,
只需要基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成。
元数据
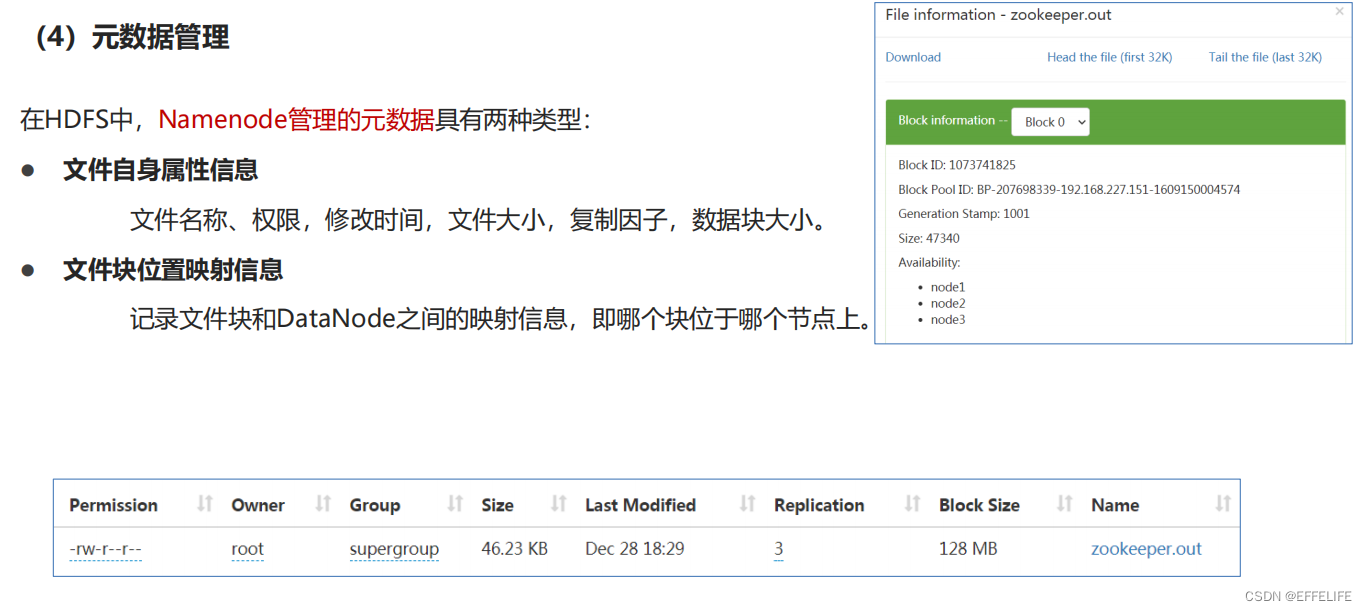
元数据(metadata)又称之为解释性数据,记录数据的数据;
文件系统元数据一般指文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息。
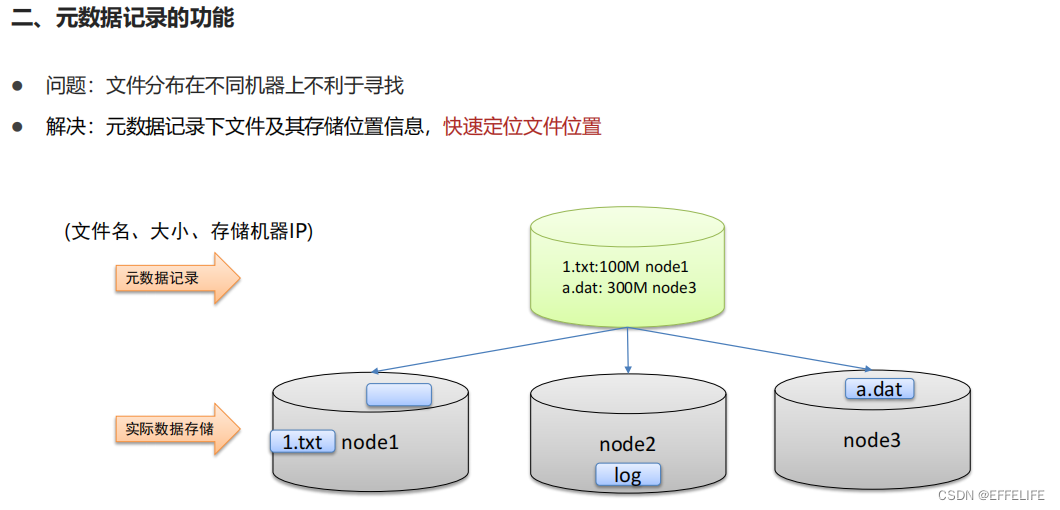
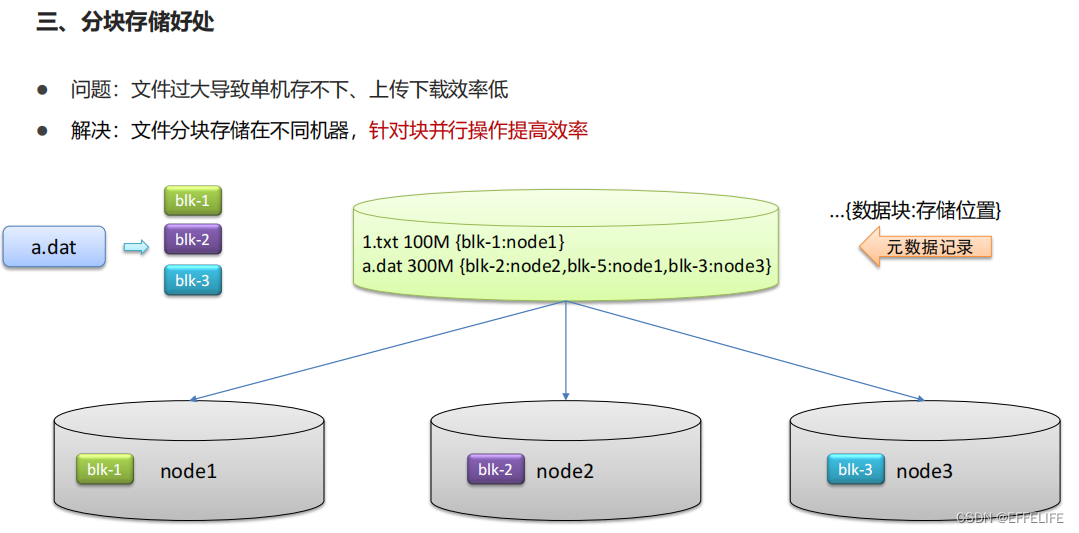
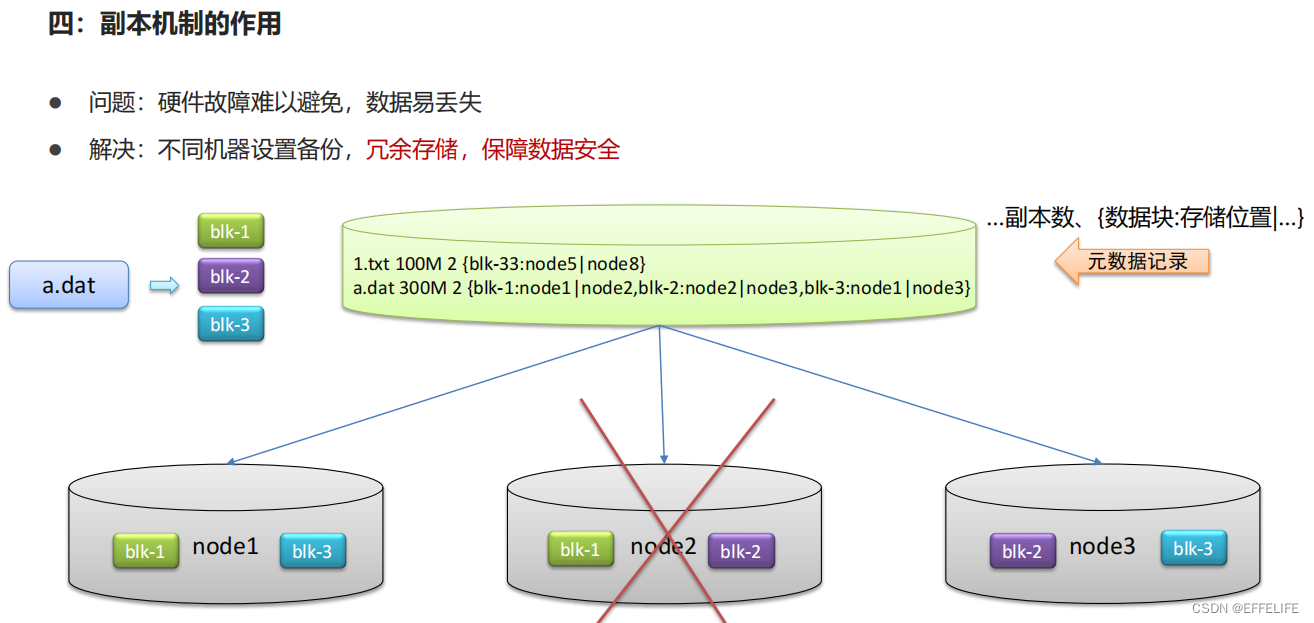
场景互动:分布式存储系统的核心属性及功能含义
• 分布式存储
• 元数据记录
• 分块存储
• 副本机制

四、HDFS
-
HDFS(Hadoop Distributed File System ),意为:Hadoop分布式文件系统。
-
是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。也可以说大数据首先要解决的问题就是海量数据的存储问题。

-
HDFS主要是解决大数据如何存储问题的。分布式意味着是HDFS是横跨在多台计算机上的存储系统。
-
HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据 (比如 TB 和PB)。
-
HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。
HDFS设计目标
-
硬件故障(Hardware Failure)是常态,HDFS可能有成百上千的服务器组成,每一个组件都有可能出现故障。因此故障检测和自动快速恢复是HDFS的核心架构目标。
-
HDFS上的应用主要是以流式读取数据(Streaming Data Access)。HDFS被设计成用于批处理,而不是用户交互式的。相较于数据访问的反应时间,更注重数据访问的高吞吐量。
-
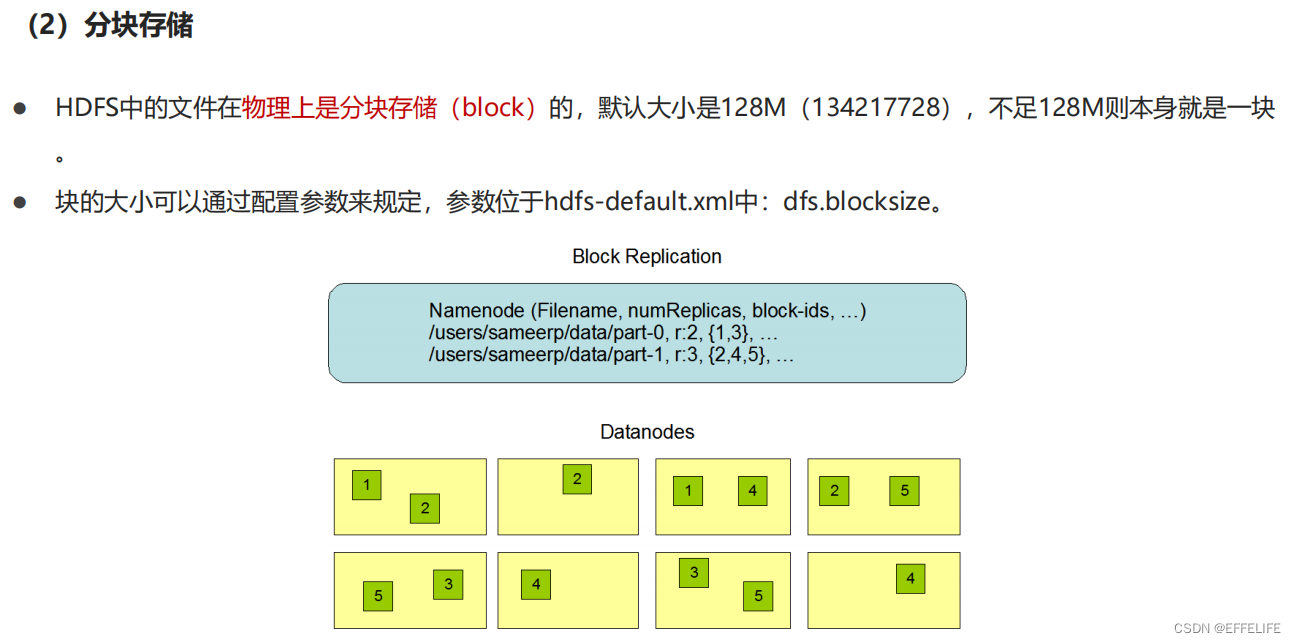
典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件(Large Data Sets)。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
-
大部分HDFS应用对文件要求的是write-one-read-many访问模型。一个文件一旦创建、写入、关闭之后就不需要修改了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
-
**移动计算的代价比之移动数据的代价低。**一个应用请求的计算,离它操作的数据越近就越高效。将计算移动到数据附近,比之将数据移动到应用所在显然更好。
-
HDFS被设计为可从一个平台轻松移植到另一个平台。这有助于将HDFS广泛用作大量应用程序的首选平台。

只注重数据的吞吐,不注重数据交互时间:一个小文件上传也需要几秒钟。
重要特性

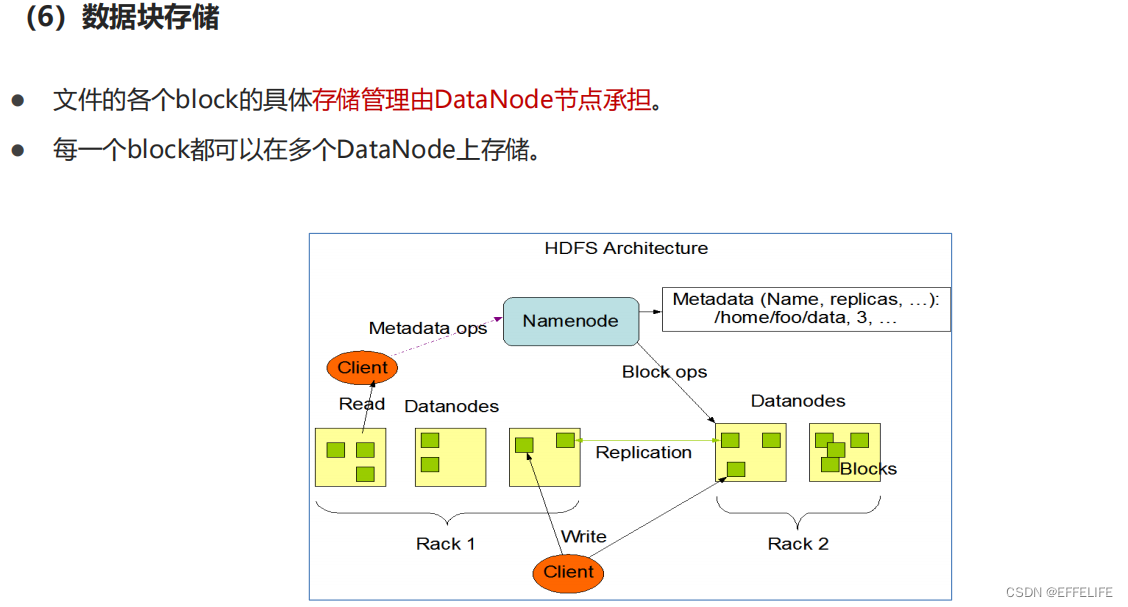
五、HDFS Shell操作
- 命令行界面(英语:command-line interface,缩写:CLI),是指用户通过键盘输入指令,计算机接收到指令后,予以执行一种人机交互方式。
- Hadoop提供了文件系统的shell命令行客户端: hadoop fs [generic options]
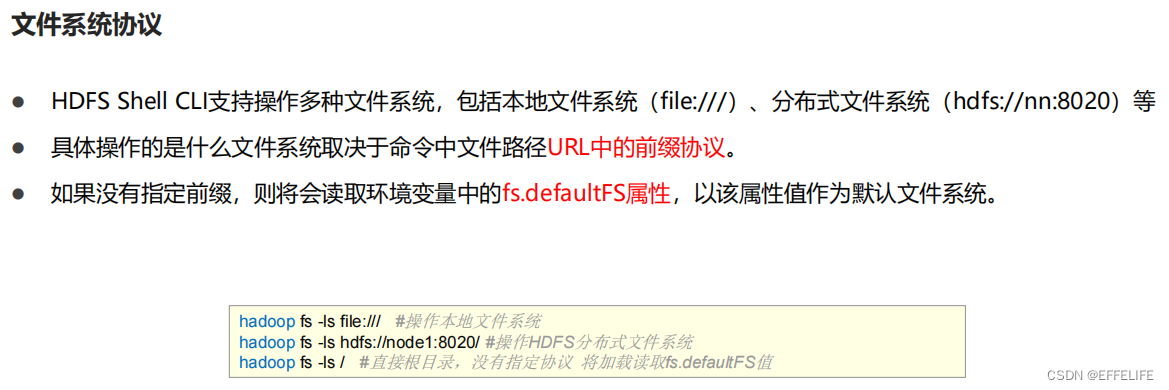

常用操作
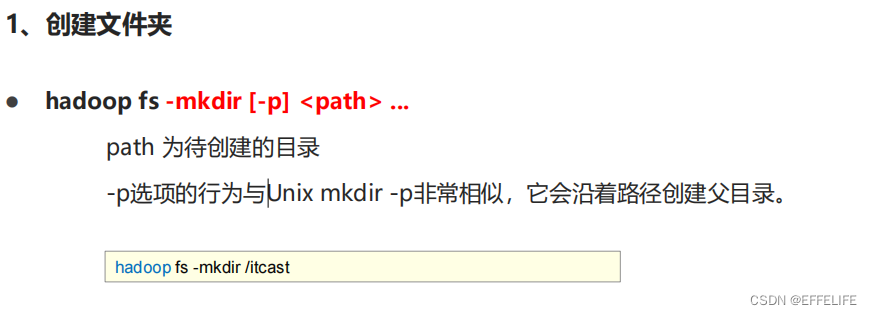
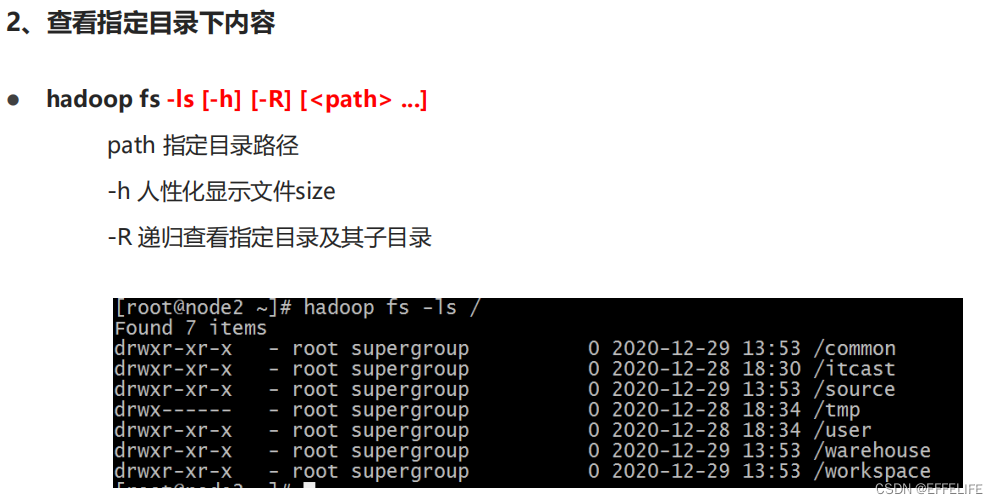

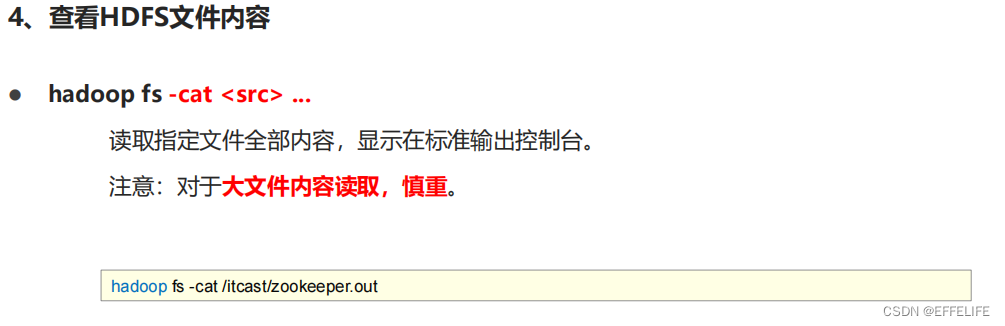
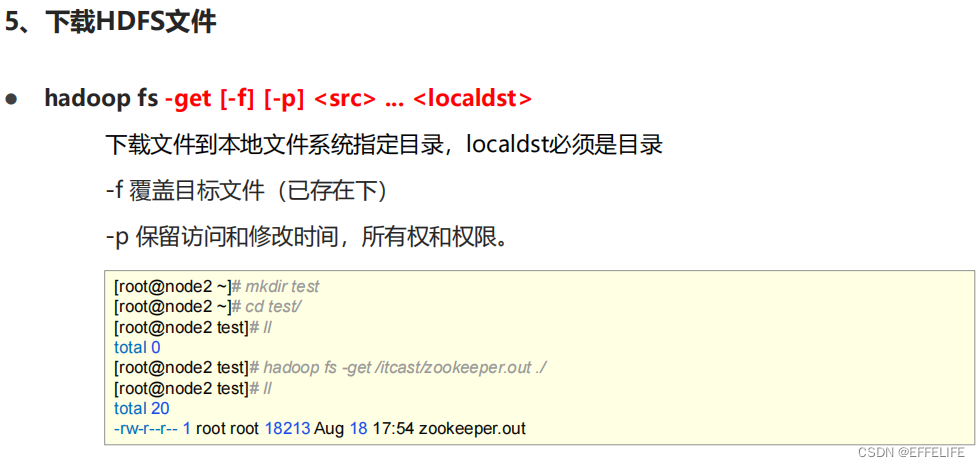
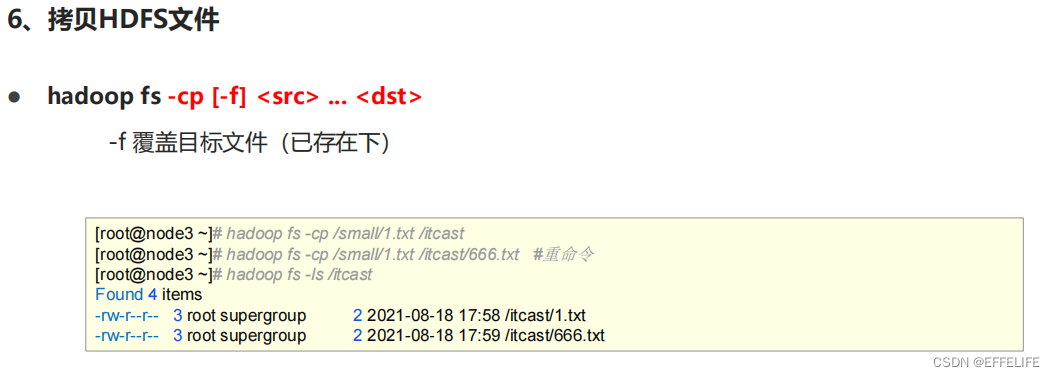
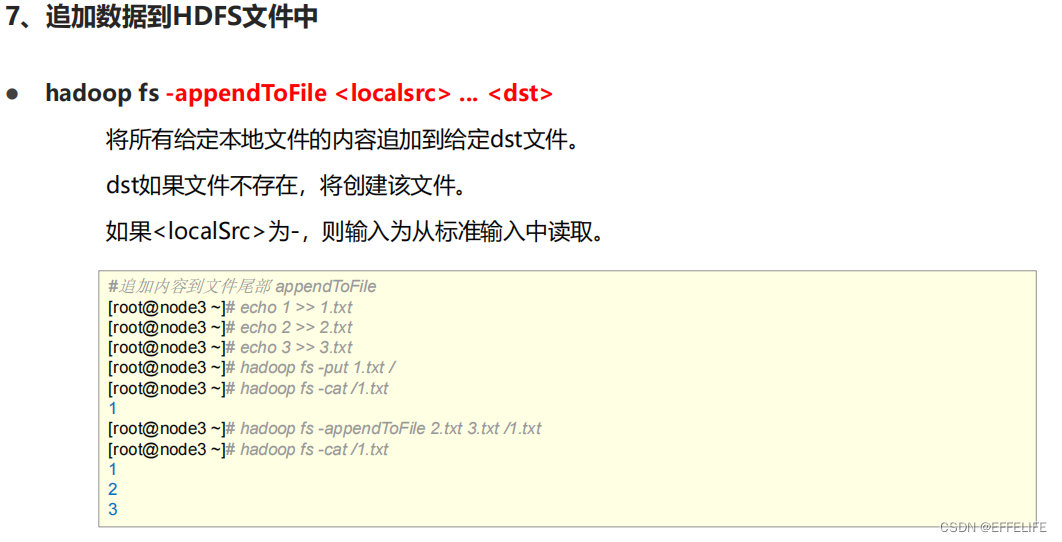

命令官方指导文档:https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
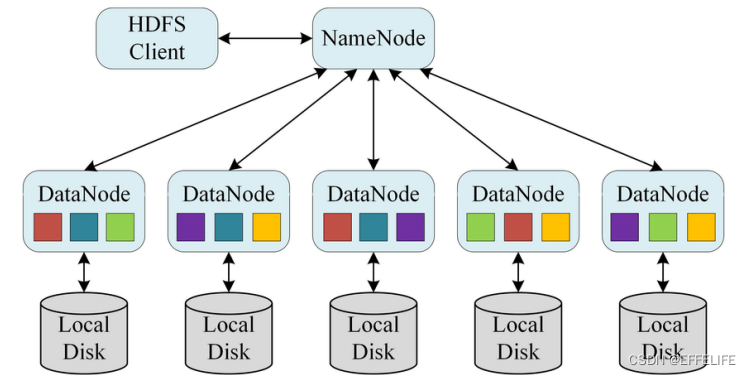
六、HDFS集群角色与职责
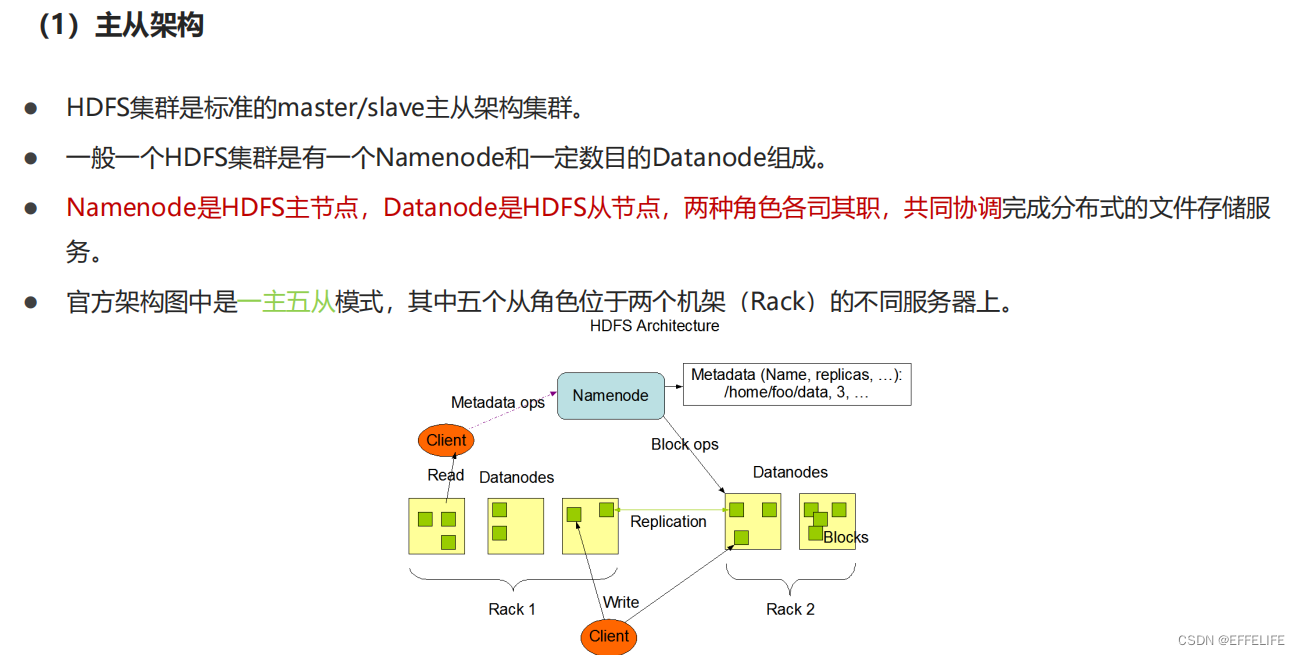
官方架构图
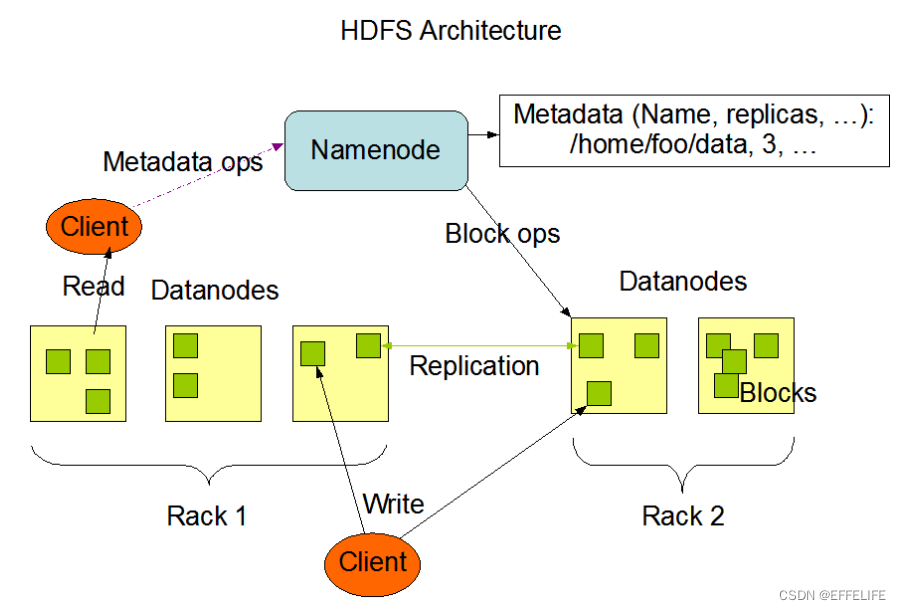
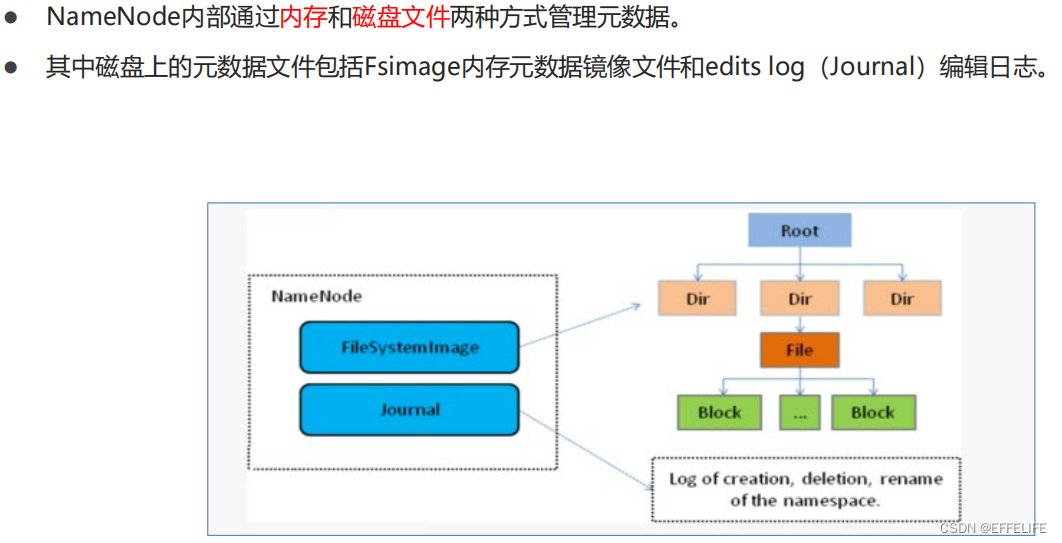
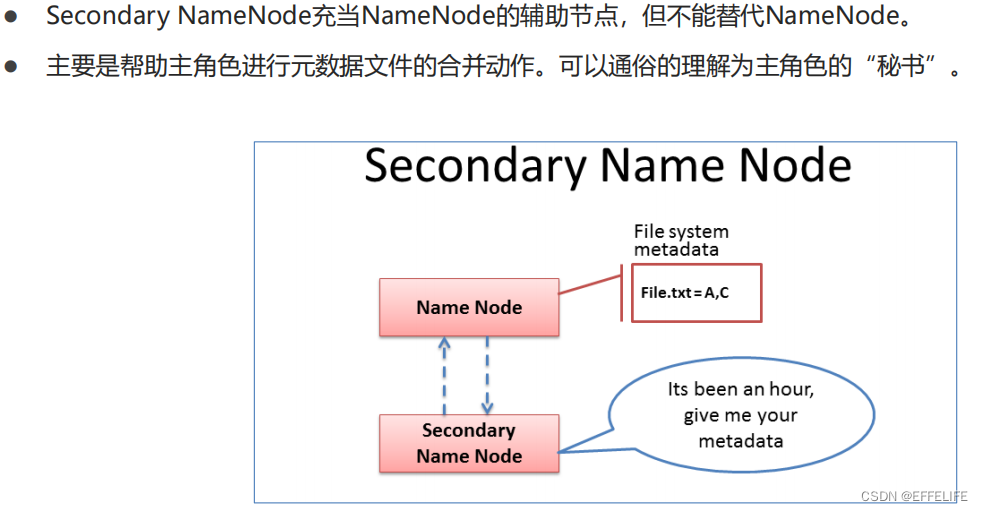
主角色:namenode


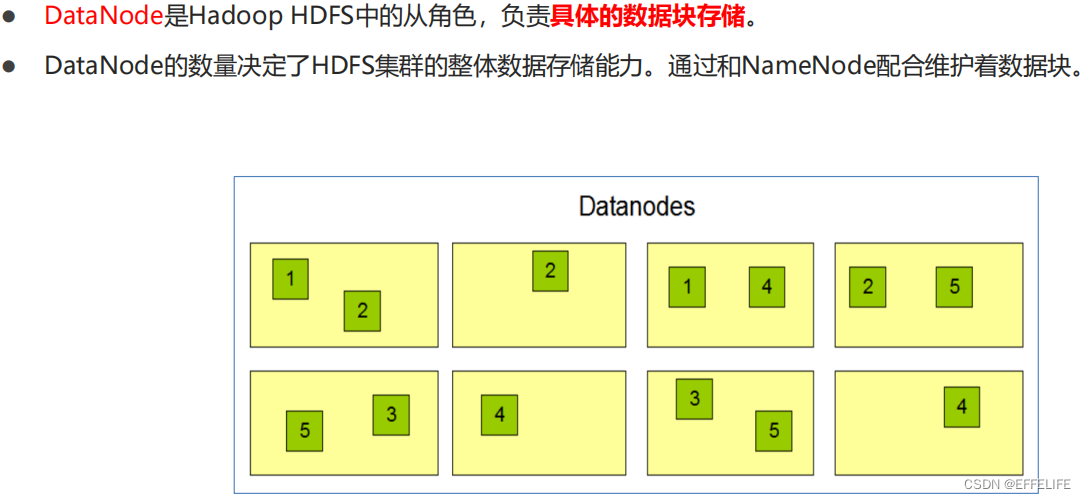
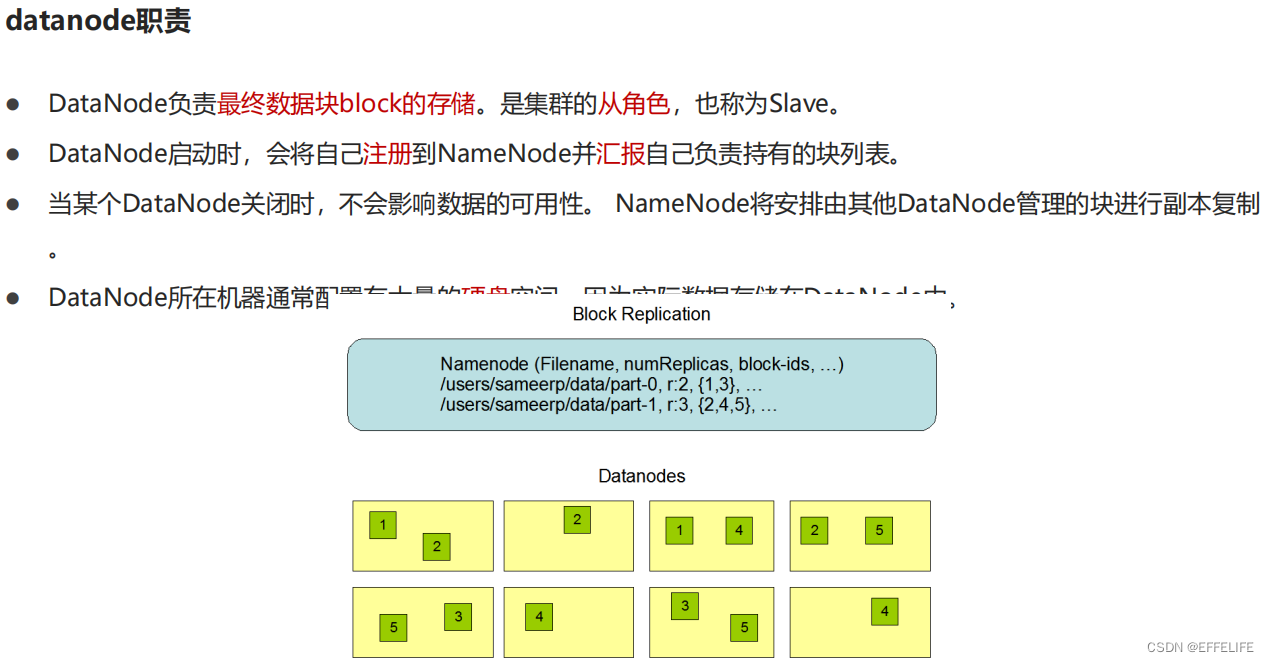
从角色:datanode
主角色辅助角色:secondarynamenode
七、YARN
- Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器。
- YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。
- 它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。

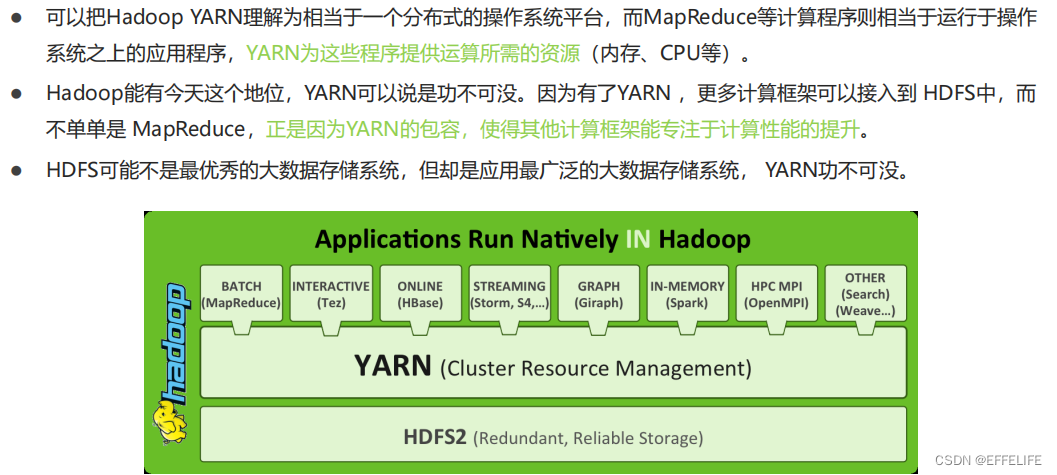
第一: 它是一个通用的资源管理系统,管理着集群的CPU、内存,所有它支持的程序都可以运行。
第二:它是一个调度平台,按照某种规则给申请资源者分配资源。
YARN官方架构图
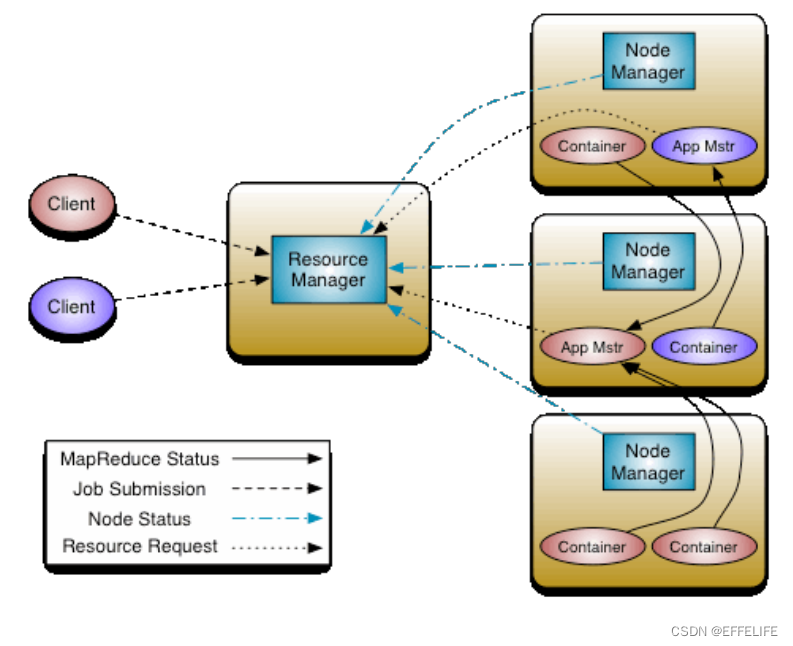
YARN三大组件
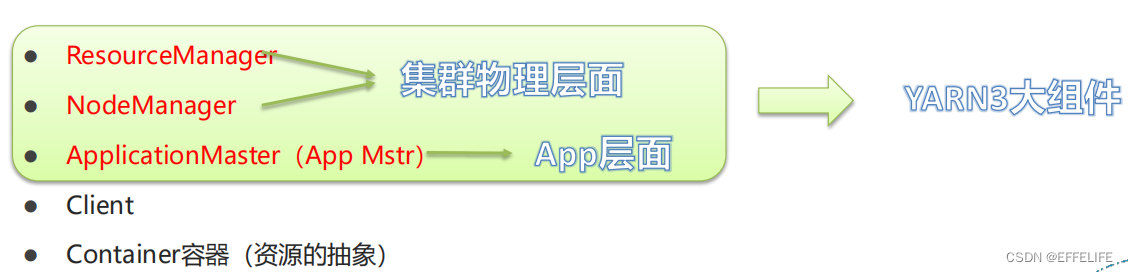
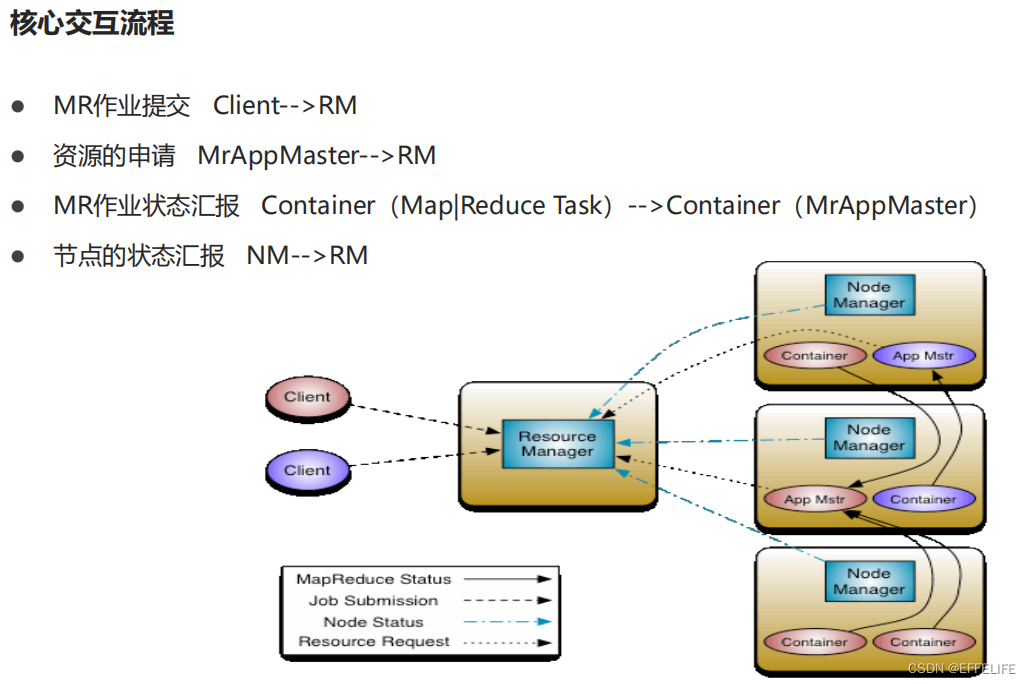
- ResourceManager(RM)
YARN集群中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁者。
接收用户的作业提交,并通过NM分配、管理各个机器上的计算资源。 - NodeManager(NM)
YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。
根据RM命令,启动Container容器、监视容器的资源使用情况。并且向RM主角色汇报资源使用情况。 - ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM。
应用程序内的“老大”,负责程序内部各阶段的资源申请,监督程序的执行情况。

















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









