










l = parse_yolo(options, params);
layer parse_yolo(list *options, size_params params)
{
int classes = option_find_int(options, "classes", 20);//获取类别数
int total = option_find_int(options, "num", 1);//获取锚点框总数
int num = total;//将锚点框总数赋给num
char *a = option_find_str(options, "mask", 0);//获取yolo层的anchor索引
int *mask = parse_yolo_mask(a, &num);//处理yolo层的anchor索引,令其指向每层第一个anchor,同时将num设置为一个yolo层需要检测的anchor数量
//创建yolo层
layer l = make_yolo_layer(params.batch, params.w, params.h, num, total, mask, classes);
assert(l.outputs == params.inputs);
//每张图片含有的真实矩形框参数的个数
//(max_boxes表示一张图片中最多有max_boxes个ground truth矩形框,
//每个真实矩形框有5个参数,包括x,y,w,h四个定位参数,以及物体类别),
//注意max_boxes是darknet程序内写死的,实际上每张图片可能
//并没有max_boxes个真实矩形框,也能没有这么多参数,
//但为了保持一致性,还是会留着这么大的存储空间,只是其中的值为空而已
l.max_boxes = option_find_int_quiet(options, "max",90);//这个其实没有用到,在make_yolo_layer中设置死了为90;
//对训练参数进行赋值
l.jitter = option_find_float(options, "jitter", .2);
l.ignore_thresh = option_find_float(options, "ignore_thresh", .5);
l.truth_thresh = option_find_float(options, "truth_thresh", 1);
l.random = option_find_int_quiet(options, "random", 0);
char *map_file = option_find_str(options, "map", 0);
if (map_file) l.map = read_map(map_file);
//设置yolo层anchor尺寸,并存入l.biases中
a = option_find_str(options, "anchors", 0);
if(a){
int len = strlen(a);
int n = 1;
int i;
for(i = 0; i < len; ++i){
if (a[i] == ',') ++n;
}
for(i = 0; i < n; ++i){
float bias = atof(a);
l.biases[i] = bias;
a = strchr(a, ',')+1;
}
}
return l;
}
*int mask = parse_yolo_mask(a, &num);
int *parse_yolo_mask(char *a, int *num)
{
int *mask = 0;
if(a){
int len = strlen(a);//获取索引长度
int n = 1;
int i;
for(i = 0; i < len; ++i){//去除索引中的逗号
if (a[i] == ',') ++n;
}
mask = calloc(n, sizeof(int));//令指针mask指向新分配的内存
for(i = 0; i < n; ++i){
int val = atoi(a);
mask[i] = val;
a = strchr(a, ',')+1;
}
*num = n;//将n赋给num指向的值,令每个yolo层有n个anchor
}
return mask;
}
layer l = make_yolo_layer(params.batch, params.w, params.h, num, total, mask, classes);
layer make_yolo_layer(int batch, int w, int h, int n, int total, int *mask, int classes)
{
int i;
layer l = {0};
l.type = YOLO;
l.n = n;
//如上,在yolov3中,有大中小分别有三个边框聚合,一共是3*3=9
//而在yolov3-tiny中,有大小分别三个边框聚合,一共是3*2=6
l.total = total;//anchors的数目,为9
l.batch = batch;// 一个batch包含图片的张数
l.h = h; // 输入图片的宽度
l.w = w; // 输入图片的高度
l.c = n*(classes + 4 + 1); // 输入图片的通道数, 3*(20 + 5)
l.out_w = l.w;// 输出图片的宽度
l.out_h = l.h;// 输出图片的高度
l.out_c = l.c;// 输出图片的通道数
l.classes = classes;//目标类别数
l.cost = calloc(1, sizeof(float));//分配用于保存损失的内存
l.biases = calloc(total*2, sizeof(float));//存储bbox的Anchor box的[w,h]
if(mask) l.mask = mask;//设置mask,l.mask 里保存了 [yolo] 配置里 “mask = 0,1,2” 的数值
else{//如果没有设置mask,则总是使用前3个框
l.mask = calloc(n, sizeof(int));
for(i = 0; i < n; ++i){
l.mask[i] = i;
}
}
l.bias_updates = calloc(n*2, sizeof(float));//存储bbox的Anchor box的[w,h]的更新值
//一张训练图片经过yolo层后得到的输出元素个数
l.outputs = h*w*n*(classes + 4 + 1);
//一张训练图片输入到yolo层的元素个数(注意是一张图片,对于yolo_layer,输入和输出的元素个数相等)
l.inputs = l.outputs;
l.truths = 90*(4 + 1);//标签,这里设置了一幅图最大检测框为90个
l.delta = calloc(batch*l.outputs, sizeof(float));//分配内存保存min_batch图像的误差项
l.output = calloc(batch*l.outputs, sizeof(float));//分配用于保存min_batch图像输出的内存
// 存储bbox的Anchor box的[w,h]的初始化,在src/parse.c中parse_yolo函数会加载cfg中Anchor尺寸
for(i = 0; i < total*2; ++i){
l.biases[i] = .5;
}
l.forward = forward_yolo_layer;
l.backward = backward_yolo_layer;
#ifdef GPU
l.forward_gpu = forward_yolo_layer_gpu;
l.backward_gpu = backward_yolo_layer_gpu;
l.output_gpu = cuda_make_array(l.output, batch*l.outputs);
l.delta_gpu = cuda_make_array(l.delta, batch*l.outputs);
#endif
fprintf(stderr, "yolo\n");
srand(0);
return l;
}
l.forward = forward_yolo_layer;
void forward_yolo_layer(const layer l, network net)
{
int i,j,b,t,n;
//将层输入直接拷贝到层输出,因为此层就是检测层,不会对输入数据做什么处理
memcpy(l.output, net.input, l.outputs*l.batch*sizeof(float));
#ifndef GPU//定义了GPU的运行下面程序
for (b = 0; b < l.batch; ++b){
for(n = 0; n < l.n; ++n){
int index = entry_index(l, b, n*l.w*l.h, 0);
activate_array(l.output + index, 2*l.w*l.h, LOGISTIC);
index = entry_index(l, b, n*l.w*l.h, 4);
activate_array(l.output + index, (1+l.classes)*l.w*l.h, LOGISTIC);
}
}
#endif
//把 l.delta 初始化为0,即将误差先初始化为0
memset(l.delta, 0, l.outputs * l.batch * sizeof(float));
if(!net.train) return;//非训练阶段则直接给出预测输出
//定义输出参数并初始化为0
float avg_iou = 0;
float recall = 0;
float recall75 = 0;
float avg_cat = 0;
float avg_obj = 0;
float avg_anyobj = 0;
int count = 0;//用于记录该yolo层检测到几个有目标的gt框
int class_count = 0;//计算检测到的类别个数与count一样
*(l.cost) = 0;//损失值初始化
for (b = 0; b < l.batch; ++b) {//遍历batch中的每一幅图像
//遍历每一个grid cell,即(j,i)表示第j行第i列的grid cell;
for (j = 0; j < l.h; ++j) {
for (i = 0; i < l.w; ++i) {
//遍历每一个bbox,一个cell对应num个bbox,当前bbox编号[n]
for (n = 0; n < l.n; ++n) {
//获得第b幅图像第j*w+i个cell第n个bbox的index
//l.outputs内的存放方式为先存放完相对应第一种anchor的所有框的数据然后存放第二种的;
int box_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, 0);
/*static int entry_index(layer l, int batch, int location, int entry)
{
int n = location / (l.w*l.h);//一个cell中的第几种框
int loc = location % (l.w*l.h);//第j*l.w+i个cell
//因为l.outputs的特色存放方式,
//所有存放同一个cell的不同bbox时需要跨过上一个bbox的所有数据,
//例如第一个cell的第一个bbox的索引为0,
//则第二个bbox的索引就是l.w*l.h*(4+1+l.classes),
//跨过了第一种bbox所有的数据;同样第三种bbox就是2*l.w*l.h*(4+1+l.classes)。
return batch*l.outputs + n*l.w*l.h*(4+1+l.classes) + entry*l.w*l.h + loc;
}*/
// 计算第j*w+i个cell第n个bbox在当前特征图上的相对位置[x,y],在网络输入图片上的相对宽度,高度[w,h]
box pred = get_yolo_box(l.output, l.biases, l.mask[n], box_index, i, j, l.w, l.h, net.w, net.h, l.w*l.h);
/*box get_yolo_box(float *x, float *biases, int n, int index, int i, int j, int lw, int lh, int w, int h, int stride)
{
box b;
//这里和公式一样,只是进行了归一化处理,这里的index就是tx的索引,由于
//l.output存放时除了之前的按照anchor种类来存放外,对于同一种anchor会先存放它的tx,然后是ty,
//格式如下(tx1,tx2,tx3...;ty1,ty2,...;tw1,tw2,...;th1,th2,...);
//且跨越的步长就是l.w*l.n;所以对于每一个yolo层,其stride是变化的,例如19*19的特征图步长为361.
b.x = (i + x[index + 0*stride]) / lw;
b.y = (j + x[index + 1*stride]) / lh;
b.w = exp(x[index + 2*stride]) * biases[2*n] / w;
b.h = exp(x[index + 3*stride]) * biases[2*n+1] / h;
return b;
}*/
float best_iou = 0;// 保存最大iou
int best_t = 0;// 保存最大iou的bbox id
//这里会发现每一个预测框都会和所有的真实框进行IOU计算
//找到与 pred 的 iou 最大的 label(ground truth)
//即和一张图片中所有的GT做IOU比较,只取一个IOU最高的匹配
for(t = 0; t < l.max_boxes; ++t){// 遍历每一个GT bbox
// 将第t个bbox由float数组转bbox结构体,方便计算iou
box truth = float_to_box(net.truth + t*(4 + 1) + b*l.truths, 1);
/*box float_to_box(float *f, int stride)
{
box b = {0};
b.x = f[0];
b.y = f[1*stride];
b.w = f[2*stride];
b.h = f[3*stride];
return b;
}
*/
// 如果x坐标为0则取消,不允许ground truth的中心点为0!!
if(!truth.x) break;//感觉这里应该是continue,即如果坐标为0则继续下一个gt,而不是直接退出循环,这样才能使得所有的gt与pred进行IOU,从而选出最大的IOU的那个
// 计算pred bbox与第t个GT bbox之间的iou
float iou = box_iou(pred, truth);
//选出iou最大那个gt框作为这个预测框的标签框
if (iou > best_iou) {
best_iou = iou;
best_t = t;
}
}
//获取该预测框对象置信度索引
int obj_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, 4);
//将所有预测框的置信度进行累加,这里是所有预测框的置信度,即包括有目标的也包含没有目标的
avg_anyobj += l.output[obj_index];
//l.output[obj_index]是网络输出的置信度,而l.delta[obj_index]计算的是置信度误差,
//置信度损失计算分为两步,先假设没有真实框,于是l.delta[obj_index] = 0 - l.output[obj_index],
//在后面阶段对于真实框位置的预测框再进行处理,在best_iou<ignore_thresh时,计算损失,
//若best_iou>ignore_thresh,赋值0,作为后面程序的判定条件,后面会用到,而它的置信度损失后面会计算。
//在论文中置信度损失也是由两部分组成的,一个是no-obj的C,一个是obj的C,这里是no-obj的C。
l.delta[obj_index] = 0 - l.output[obj_index];
//这里进行了刷选,如果该预测框与之对应gt框的最大交并比大于阈值,
//如果最大 iou 大于 ignore_thresh,则不计算损失
if (best_iou > l.ignore_thresh) {
l.delta[obj_index] = 0;
}
//这个参数在cfg文件中,值为1,这个条件语句永远不可能成立
if (best_iou > l.truth_thresh) {
//作者在YOLOv3的论文中的第四节提到了这部分。
//作者尝试Faster R-CNN中提到的双IoU策略,
//当anchor与GT的IoU大于0.7时,该anchor被算作正样本计入损失中。
//但训练过程中并没有产生好的效果,所以最后放弃了。
l.delta[obj_index] = 1 - l.output[obj_index];//包含目标的可能性越大,则delta[obj_index]越小
int class = net.truth[best_t*(4 + 1) + b*l.truths + 4];//得到GT所属类别。(0,1,2,3,4)分别表示(x,y,w,h,class),这里是4
if (l.map) class = l.map[class];//类别统一转换,直接忽略
int class_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, 4 + 1);//定位到类别概率
delta_yolo_class(l.output, l.delta, class_index, class, l.classes, l.w*l.h, 0);//计算类别损失
box truth = float_to_box(net.truth + best_t*(4 + 1) + b*l.truths, 1);
//计算定位损失
//以每个预测框为基准。让每个cell对应的预测框去拟合GT,若IOU大于阈值,则计算损失。(注意和另一个delta_yolo_box的区别哦!)
//由于有阈值限制,这样有可能造成有个别的GT没有匹配到对应的预测框,漏了这部分的损失。
//这样只把预测框与GT之间的IOU大于设定的阈值的算作定位损失
delta_yolo_box(truth, l.output, l.biases, l.mask[n], box_index, i, j, l.w, l.h, net.w, net.h, l.delta, (2-truth.w*truth.h), l.w*l.h);
}
}
}
}
//上面遍历了整张图片的每个cell中的每个pre box,
//下面代码处理的基本单元是整张图片(即,第n张图片)。
//计算真实框与anchor框的iou,寻找与真实框最匹配的anchor框
//遍历该图片中的所有GT
for(t = 0; t < l.max_boxes; ++t){
//与上面一样获取真实坐标的索引
box truth = float_to_box(net.truth + t*(4 + 1) + b*l.truths, 1);
if(!truth.x) break;
float best_iou = 0;
int best_n = 0;
label 在yolo层中的位置,即GT的中心点位于第(i,j)个cell,也就是该cell负责预测这个truth
i = (truth.x * l.w);
j = (truth.y * l.h);
//将真实标签赋给truth_shift
box truth_shift = truth;
//不考虑 x,y,只考虑 w,h,即只考虑 iou
truth_shift.x = truth_shift.y = 0;
//遍历每个先验框,找出与GT具有最大iou的先验框
for(n = 0; n < l.total; ++n){
box pred = {0};
pred.w = l.biases[2*n]/net.w;//net.w表示图片的宽,即按网络输入尺寸进行归一化,这样就和输入的宽一样的比例了
pred.h = l.biases[2*n+1]/net.h;
float iou = box_iou(pred, truth_shift);//此iou是不考虑x,y,仅考虑w,h的得到的,即都把中心点设置为了(0,0)
//通过寻找与真实框交并比最大的作为最匹配的anchor框
if (iou > best_iou){
best_iou = iou;
best_n = n;
}
}
//计算预测框与真实框的损失
//获取该标签框所对应的anchor框在此yolo层anchor索引,若存在则返回索引,若不存在则返回-1;
//例如yolov3的3个yolo层,每一个yolo层对应3种尺寸的anchor框,分别为(6,7,8)(3,4,5)(0,1,2)
//假设该真实标签框对应的anchor框的索引best_n=7,那么它对应的就是第一层yolo层的第二个
//故该真实标签框只有在第一个yolo层时才会返回索引mask_n,其他yolo层都是-1;
int mask_n = int_index(l.mask, best_n, l.n);
/*int int_index(int *a, int val, int n)
{
int i;
for(i = 0; i < n; ++i){
if(a[i] == val) return i;
}
return -1;
}
*/
//若是该标签框所匹配的anchor框在此yolo层,则运行下面代码
if(mask_n >= 0){
//定位到该gt框对应的预测框索引,这里通过之前的i,j定位到了cell,通过mask_n定位到了该cell中的第几个框
int box_index = entry_index(l, b, mask_n*l.w*l.h + j*l.w + i, 0);
//获取gt与对应预测框的交并比
float iou = delta_yolo_box(truth, l.output, l.biases, best_n, box_index, i, j, l.w, l.h, net.w, net.h, l.delta, (2-truth.w*truth.h), l.w*l.h);
/*float delta_yolo_box(box truth, float *x, float *biases, int n, int index, int i, int j, int lw, int lh, int w, int h, float *delta, float scale, int stride)
{
//获取该gt对应的预测框坐标
box pred = get_yolo_box(x, biases, n, index, i, j, lw, lh, w, h, stride);
//获取gt与对应预测框的交并比
float iou = box_iou(pred, truth);
//论文公式反推即可,为了与预测坐标宽高对应,方便计算误差
float tx = (truth.x*lw - i);
float ty = (truth.y*lh - j);
float tw = log(truth.w*w / biases[2*n]);
float th = log(truth.h*h / biases[2*n + 1]);
//将定位误差存入delta内
delta[index + 0*stride] = scale * (tx - x[index + 0*stride]);
delta[index + 1*stride] = scale * (ty - x[index + 1*stride]);
delta[index + 2*stride] = scale * (tw - x[index + 2*stride]);
delta[index + 3*stride] = scale * (th - x[index + 3*stride]);
return iou;
}*/
//获取与该gt对应预测框的置信度索引
int obj_index = entry_index(l, b, mask_n*l.w*l.h + j*l.w + i, 4);
//这里将有gt对应的预测框置信度累加
avg_obj += l.output[obj_index];
//之前假设了所有预测框都没有目标,这里将有目标的预测框重新定义,即该预测框为正样本,所以误差为 1-predict
l.delta[obj_index] = 1 - l.output[obj_index];
//获取gt框的类别标签
int class = net.truth[t*(4 + 1) + b*l.truths + 4];
if (l.map) class = l.map[class];//统一类别标签
//获gt对应预测框的类别索引
int class_index = entry_index(l, b, mask_n*l.w*l.h + j*l.w + i, 4 + 1);
//计算类别误差
delta_yolo_class(l.output, l.delta, class_index, class, l.classes, l.w*l.h, &avg_cat);
/*void delta_yolo_class(float *output, float *delta, int index, int class, int classes, int stride, float *avg_cat)
{
int n;
if (delta[index]){//不会进入这个判断,因为 delta[index] 初值为0
delta[index + stride*class] = 1 - output[index + stride*class];
if(avg_cat) *avg_cat += output[index + stride*class];
return;
}
//遍历所有类
for(n = 0; n < classes; ++n){
//判断该类是不是真实类别标签,如果是则为1,不是则为0
//然后如果是真则将1-output[index + stride*n]存入误差相应位置
//如果是假则将0-output[index + stride*n]存入误差相应位置
delta[index + stride*n] = ((n == class)?1 : 0) - output[index + stride*n];
//判断如果该类是真则将该类的预测概率累加到*avg_cat
if(n == class && avg_cat) *avg_cat += output[index + stride*n];
}
}
*/
++count;
++class_count;
//用于计算不同交并比下的召回率
if(iou > .5) recall += 1;
if(iou > .75) recall75 += 1;
//将所有有目标的gt与对应预测框的交并比累加到avg_iou
avg_iou += iou;
}
}
}
//计算一个min_batch的损失值
*(l.cost) = pow(mag_array(l.delta, l.outputs * l.batch), 2);
/*
float mag_array(float *a, int n)
{
int i;
float sum = 0;
for(i = 0; i < n; ++i){
sum += a[i]*a[i];
}
return sqrt(sum);
}
*/
printf("Region %d Avg IOU: %f, Class: %f, Obj: %f, No Obj: %f, .5R: %f, .75R: %f, count: %d\n", net.index, avg_iou/count, avg_cat/class_count, avg_obj/count, avg_anyobj/(l.w*l.h*l.n*l.batch), recall/count, recall75/count, count);
}
由于论文中没有给出损失函数,这里根据代码得出的yolov3损失函数
这里首先根据公式转换真实标签的坐标信息,使其和预测坐标格式相同,论文公式如下:
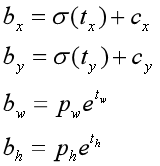
但在实际代码中为了进行归一化,还对其进行了一些操作,如下:
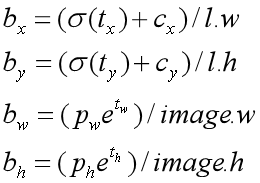
其中l.w和l.h分别是yolo层特征图的宽和高,所以计算坐标损失时需要对标签做一些转换如下

其中truthx,truthy,truthw,truthhf分别是标签框的中心坐标和宽高; int(truthx* l.w)和int(truthy* l.h)就是上个公式中的cx和cy,根据上一个公式可以计算出其中心坐标的偏移量;同理根据公式得出实际标签框的宽和高的偏移;
1、计算坐标损失
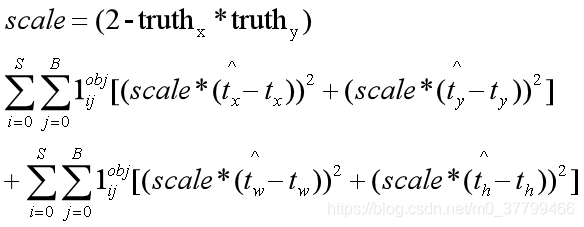
公式中的scale表示定位损失的前项权值,与yolo1不同,其大小是随着标签框大小变化的;而且其宽高不再使用平方根;S表示yolo层的网格数,B表示一个网格内预测几个框,只有当真实标签框有目标同时与该预测框对应时才会计算定位损失;
2、计算置信度损失
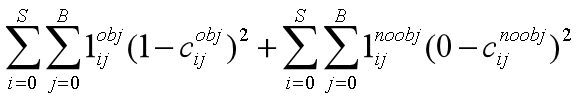
在代码中实际运行过程如下:
(1)首先会遍历该yolo层上所有的预测框,得到每一个预测框的置信度,然后先假设所有的预测框中都没有目标,就是公式中的第二项;
(2)对每一个预测框都遍历所有标签框,与其计算交并比,选择交并比最大的作为该预测框的标签框,使得每一个预测框都对应了一个标签框,然后使用预设的阈值(论文中为0.5)与交并比对比,当交并比小于阈值,说明该预测框与对应标签框的重合太少,不能预测该标签框,即该预测框中没有目标,其置信度损失保存之前假设的那样;当交并比大于阈值,此时说明该预测框与对应标签框重合度足够大,虽然还不能确定其是否用于预测该标签框,但不能再说其内没有目标了,故先将其置信度损失设置为0;其表示了两种类型:一种是其预测框内有目标,则会在后续将其计入有目标的置信度损失;第二种就是其内虽然有目标,但其与标签框重合不是最大的,还有其他预测框与他对应相同标签框,且比他重合度高,此时其不计入有目标的置信度损失也不计入无目标的置信度损失,可以说将其忽略了;
(3)遍历所有的标签框,当然这里会先排除掉多余的标签框,因为我们设置了一幅图上有90个标签框,但是实际上不会有这么多,装填标签时会将不够的补零,此时就是去除补零的标签,留下真正的标签;然后为每一个标签框遍历所有的anchor框,选择与其交并比最大那个作为与其对应的anchor框;这里就是选择yolo层的过程了,因为每一个yolo层中的anchor尺寸都不同;
(4)确定该真实标签对应的anchor在哪个yolo层,然后选择该yolo层,根据之前计算的该标签框所对应的grid cell和对应anchor索引得出最终负责预测它的预测框,计算出该预测框的置信度,最后使用1减去它的置信度就是该预测框的置信度损失了。
3、类别损失
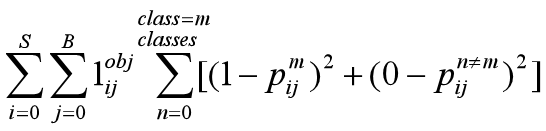
这里表示了class=m表示了该标签框的类别为m,当预测框类别为m时,则计算损失为1减去类别概率,不为m时,则使用0减去类别概率;
l.backward = backward_yolo_layer;
//将该层误差传入上一层delta中
void backward_yolo_layer(const layer l, network net)
{
axpy_cpu(l.batch*l.inputs, 1, l.delta, 1, net.delta, 1);
}
void axpy_cpu(int N, float ALPHA, float *X, int INCX, float *Y, int INCY)
{
int i;
for(i = 0; i < N; ++i) Y[i*INCY] += ALPHA*X[i*INCX];
}

















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









