







 本文深入探讨了Java编程中的各种技巧和最佳实践,包括三目运算符的高效使用、Map集合操作、多线程编程、MD5加密实现、JSON处理、文件操作以及常见问题的解决方案。
本文深入探讨了Java编程中的各种技巧和最佳实践,包括三目运算符的高效使用、Map集合操作、多线程编程、MD5加密实现、JSON处理、文件操作以及常见问题的解决方案。
文章目录
- 1.java三目判断运算:
- 2.如何取得map里key得最大值:
- 3.对map集合进行排序:
- 4.多线程写法样例:
- 5.Java MD5加密:
- 6.循环遍历JSONObject的一种方法:
- 7.判断json字符串是JSONObject还是JSONArray:
- 8.避免json、map对象串用:
- 9.jdk弃用API:
- 10.处理json的时候尽量不使用org.codehaus.jettison包:
- 11.java占位符使用:
- 12.判断一个字符串是否包含某个字符:
- 13.将ResultSet结果集遍历到List中:
- 14.获取文件大小:
- 15.equalsIgnoreCase() 方法:
- 16.使用split对.分割的时候需要转义:
- 17.神奇的特殊字符导致的数据问题:
1.java三目判断运算:
以后简单的判断可以直接用这个三目运算符,可以减少代码量让别人看的也会感觉你有经验
“(a<b)?a:b"是一个"条件表达式”,它是这样执行的: 如果a<b为真,则表达式取a值,否则取b值.
如:
int topCount=fields.containsKey("topCount") ? fields.get("topCount").value() : 1024;
private String isrepeat(String userId,String subjectName) {
Query query = new Query();
query.addCriteria(new Criteria().and("userId").is(userId).and("subjectName").is(subjectName));
List<CreateSubject> createSubjects = secondMongo.find(query, CreateSubject.class);
return createSubjects.size() >= 1 ? "1":"0";
}
扩展:三个值求最大值:
方法一:使用 if 语句比较三个数的大小,找出最大值。
public int getMax(int a, int b, int c) {
int max = a;
if (b > max) {
max = b;
}
if (c > max) {
max = c;
}
return max;
}
方法二:使用 Math 类的 max 方法比较三个数的大小,找出最大值。
import java.lang.Math;
public int getMax(int a, int b, int c) {
return Math.max(Math.max(a, b), c);
}
方法三:使用三元运算符比较三个数的大小,找出最大值。
public int getMax(int a, int b, int c) {
return (a > b) ? ((a > c) ? a : c) : ((b > c) ? b : c);
}
2.如何取得map里key得最大值:
方法一:
将Map中的key存放至set集合中,进行排序,排序后的set中第一个值即为最小,最后一个即为最大
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class test {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
map.put(1, 8);
map.put(3, 53);
map.put(5, 12);
System.out.println(getMaxKey(map));
System.out.println(getMaxValue(map));
}
/**
* 求Map<K,V>中Key(键)的最大值
*/
public static Object getMaxKey(Map<Integer, Integer> map) {
if (map == null)
return null;
Set<Integer> set = map.keySet();
Object[] obj = set.toArray();
Arrays.sort(obj);
return obj[obj.length - 1];
}
/**
* 求Map<K,V>中Value(值)的最大值
*/
public static Object getMaxValue(Map<Integer, Integer> map) {
if (map == null)
return null;
Collection<Integer> c = map.values();
Object[] obj = c.toArray();
Arrays.sort(obj);
return obj[obj.length - 1];
}
}
运行结果:
5
53
方法二:可以直接使用TreeSet和TreeMap,最后一个为最大值,第一个为最小值
补充:
TreeMap是Map接口的常用实现类,而TreeSet是Set接口的常用实现类。虽然 TreeMap和TreeSet实现的接口规范不同,但TreeSet底层是通过TreeMap来实现的(如同HashSet底层是是通过HashMap来实现的一样),因此二者的实现方式完全一样。而TreeMap的实现就是红黑树算法。
相同点:
TreeMap和TreeSet都是有序的集合,也就是说他们存储的值都是排好序的。
TreeMap和TreeSet都是非同步集合,因此他们不能在多线程之间共享,不过可以使用方法Collections.synchroinzedMap()来实现同步
运行速度都要比Hash集合慢,他们内部对元素的操作时间复杂度为O(logN),而HashMap/HashSet则为O(1)。
不同点:
最主要的区别就是TreeSet和TreeMap分别实现Set和Map接口
TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value(仅仅key对象有序)
TreeSet中不能有重复对象,而TreeMap中可以存在
Set<Integer> a=new HashSet<Integer>();
// 等效于
HashSet<Integer> b = new HashSet<Integer>();
Set<Integer> c=new TreeSet<Integer>();
// 等效于
TreeSet<Integer> d = new TreeSet<Integer>();
a.add(5);
Set是接口,HashSet和TreeSet是实现类
Hashset顾名思义里面是哈希表结构
TreeSet就是树结构
1、TreeSet 是二叉树实现的,Treeset中的数据是自动排好序的,不允许放入null值。
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。存取速度比较快
注:由于HashSet储存数据都是无序的,所以不能用get(i);来获取具体对象。所以我们必须通过遍历来得到HashSet的各个数据,由于是没有索引的。所以不能使用普通类型的for来遍历它。HashSet只能通过增强型for和迭代器来遍历它
public static void main(String[] args) {
HashSet<Integer> a = new HashSet<Integer>();
a.add(5);
a.add(4);
a.add(3);
for(Integer n : a) {
System.out.println(n);
}
Iterator<Integer> it = a.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
3.对map集合进行排序:
参考:https://www.cnblogs.com/chenssy/p/3264214.html
map是键值对的集合接口,它的实现类主要包括:HashMap,TreeMap,Hashtable以及LinkedHashMap等。其中这四者的区别如下:
- HashMap:我们最常用的Map,它根据key的HashCode 值来存储数据,根据key可以直接获取它的Value,同时它具有很快的访问速度。HashMap最多只允许一条记录的key值为Null(多条会覆盖);允许多条记录的Value为 Null。非同步的。
- TreeMap: 能够把它保存的记录根据key排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
- Hashtable: 与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
- LinkedHashMap: 保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的。
TreeMap默认是升序的,如果我们需要改变排序方式,则需要使用比较器:Comparator。
Comparator可以对集合对象或者数组进行排序的比较器接口,实现该接口的public compare(T o1,To2)方法即可实现排序,该方法主要是根据第一个参数o1,小于、等于或者大于o2分别返回负整数、0或者正整数。如下:
public class TreeMapTest {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>(
new Comparator<String>() {
public int compare(String obj1, String obj2) {
// 降序排序
return obj2.compareTo(obj1);
// 升序排序
// return obj1.compareTo(obj2);
}
});
map.put("a", "ddddd");
map.put("d", "ccccc");
map.put("c", "bbbbb");
map.put("b", "aaaaa");
Set<String> keySet = map.keySet();
Iterator<String> iter = keySet.iterator();
while (iter.hasNext()) {
String key = iter.next();
System.out.println(key + ":" + map.get(key));
}
}
}
上面例子是对根据TreeMap的key值来进行排序的,但是有时我们需要根据TreeMap的value来进行排序。对value排序我们就需要借助于Collections的sort(List<T> list, Comparator<? super T> c)方法,该方法根据指定比较器产生的顺序对指定列表进行排序。但是有一个前提条件,那就是所有的元素都必须能够根据所提供的比较器来进行比较。如下:
public class TreeMapTest {
public static void main(String[] args) {
Map<String, String> map = new TreeMap<String, String>();
map.put("a", "ddddd");
map.put("d", "ccccc");
map.put("c", "bbbbb");
map.put("b", "aaaaa");
//这里将map.entrySet()转换成list
List<Map.Entry<String,String>> list = new ArrayList<Map.Entry<String,String>>(map.entrySet());
//然后通过比较器来实现排序
Collections.sort(list,new Comparator<Map.Entry<String,String>>() {
public int compare(Map.Entry<String, String> o1,
Map.Entry<String, String> o2) {
//升序排序
return o1.getValue().compareTo(o2.getValue());
//降序排序
//return o2.getValue().compareTo(o1.getValue());
}
});
for(Map.Entry<String,String> mapping:list){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}
}
}
我们都知道HashMap的值是没有顺序的,他是按照key的HashCode来实现的。对于这个无序的HashMap我们要怎么来实现排序呢?参照TreeMap的value排序,我们一样的也可以实现HashMap的排序。
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("c", "ccccc");
map.put("a", "aaaaa");
map.put("b", "bbbbb");
map.put("d", "ddddd");
List<Map.Entry<String,String>> list = new ArrayList<Map.Entry<String,String>>(map.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,String>>() {
//升序排序
public int compare(Entry<String, String> o1,
Entry<String, String> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
for(Map.Entry<String,String> mapping:list){
System.out.println(mapping.getKey()+":"+mapping.getValue());
}
}
}
其他方法:
public static void main(String[] args) {
Map<String, Integer> unsortMap = new HashMap<>();
unsortMap.put("a", 6);
unsortMap.put("d", 20);
unsortMap.put("c", 99);
unsortMap.put("b", 2);
System.out.println(unsortMap);
// 按value排序
Map<String, Integer> result1 = unsortMap.entrySet().stream()
// 正排
// .sorted(Map.Entry.comparingByValue())
// 倒排
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue,
(oldValue, newValue) -> oldValue, LinkedHashMap::new));
System.out.println(result1);
Map<String, Integer> result2 = new LinkedHashMap<>();
unsortMap.entrySet().stream()
// 正排
// .sorted(Map.Entry.<String, Integer>comparingByValue())
// 倒排
.sorted(Map.Entry.<String, Integer>comparingByValue().reversed())
// 或者
// .sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.forEachOrdered(x -> result2.put(x.getKey(), x.getValue()));
System.out.println(result2);
// 按key排序
Map<String, Integer> result3 = unsortMap.entrySet().stream()
// 正排
.sorted(Map.Entry.comparingByKey())
// 倒排
// .sorted(Map.Entry.comparingByKey(Comparator.reverseOrder()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue,
(oldValue, newValue) -> oldValue, LinkedHashMap::new));
System.out.println(result3);
Map<String, Integer> result4 = new LinkedHashMap<>();
unsortMap.entrySet().stream()
// 正排
.sorted(Map.Entry.comparingByKey())
// 倒排
// .sorted(Map.Entry.comparingByKey(Comparator.reverseOrder()))
// 或者
// .sorted(Map.Entry.<String, Integer>comparingByKey().reversed())
.forEachOrdered(x -> result4.put(x.getKey(), x.getValue()));
System.out.println(result4);
}
运行结果:
{a=6, b=2, c=99, d=20}
{c=99, d=20, a=6, b=2}
{c=99, d=20, a=6, b=2}
{a=6, b=2, c=99, d=20}
{a=6, b=2, c=99, d=20}
4.多线程写法样例:
ExecutorService executorService = Executors.newFixedThreadPool(5);
this.thredExecute(executorService, createSubject);
private void thredExecute(ExecutorService threadPool,CreateSubject createSubject) {
Thread thread = new Thread( () -> {
try {
characterAnalysisService.saveCharacterLeader(createSubject);
} catch (Exception e1) {
e1.printStackTrace();
}
} );
Thread thread2 = new Thread( () -> {
try {
characterAnalysisService.saveIntenetLeader(createSubject);
} catch (Exception e) {
e.printStackTrace();
}
});
Thread thread3 = new Thread( () -> {
try {
emotionAnalysisService.saveAllTypeEmotion(createSubject);
} catch (Exception e) {
e.printStackTrace();
}
});
threadPool.execute(thread);
threadPool.execute(thread2);
threadPool.execute(thread3);
// 关闭线程池
threadPool.shutdown();
threadPool = null;
System.gc();
}
5.Java MD5加密:
参考:https://www.cnblogs.com/maohuidong/p/7967257.html
导入maven依赖:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.3.2</version>
</dependency>
MD5使用代码:
import org.apache.commons.codec.digest.DigestUtils;
/**
* MD5通用类
* @author 浩令天下
* @since 2017.04.15
* @version 1.0.0_1
*/
public class BizCashSettingController {
/**
* MD5方法
* @param text 明文
* @param key 密钥
* @return 密文
* @throws Exception
*/
public static String md5(String text, String key) throws Exception {
// 加密后的字符串
String encodeStr = DigestUtils.md5Hex(text + key);
System.out.println("MD5加密后的字符串为:encodeStr=" + encodeStr);
return encodeStr;
}
/**
* MD5验证方法
* @param text 明文
* @param key 密钥
* @param md5 密文
* @return true/false
* @throws Exception
*/
public static boolean verify(String text, String key, String md5) throws Exception {
// 根据传入的密钥进行验证
String md5Text = md5(text, key);
if (md5Text.equalsIgnoreCase(md5)) {
System.out.println("MD5验证通过");
return true;
}
return false;
}
}
6.循环遍历JSONObject的一种方法:
public static void main(String[] args) {
JSONObject obj = new JSONObject();
obj.put("key1", "a");
obj.put("key2", "b");
obj.put("key3", "c");
for(Object str : obj.keySet()){
System.out.println(str + ":" +obj.get(str));
}
System.out.println(obj.keySet());
}
7.判断json字符串是JSONObject还是JSONArray:
public static String jsontype(String text) {
Object obj = JSON.parse(text);
if (obj instanceof JSONObject) {
// System.out.println("JSONObject");
return "JSONObject";
}
if (obj instanceof JSONArray) {
// System.out.println("JSONArray");
return "JSONArray";
}
return "啥也不是";
}
8.避免json、map对象串用:
import net.sf.json.JSONObject;
public class haha{
public static void main(String[] args){
// 问题
JSONObject aa = new JSONObject();
aa.put("1", "a");
JSONObject bb = aa;
bb.put("2", "b");
System.out.println(aa);
// 解决
JSONObject cc = new JSONObject();
cc.put("1", "a");
JSONObject dd = JSONObject.fromObject(cc.toString());
dd.put("2", "b");
System.out.println(cc);
// Map
Map<Integer, String> mapInsertdata = new HashMap<Integer, String>();
Map<Integer, String> mapInsertdataTmp = new HashMap<Integer, String>();
// mapInsertdataTmp = mapInsertdata ; // 错误做法
mapInsertdataTmp.putAll(mapInsertdata); // 正确做法
}
}
9.jdk弃用API:
来自:https://www.cnblogs.com/IcanFixIt/p/7234054.html
import java.io.File;
/**
* The class consists of static methods that can be used to
* copy files and directories.
*
* @deprecated Deprecated since 1.4. Not safe to use. Use the
* <code>java.nio.file.Files</code> class instead. This class
* will be removed in a future release of this library.
*
* @since 1.2
*/
@Deprecated
public class FileCopier {
// No direct instantiation supported.
private FileCopier() {
}
/**
* Copies the contents of src to dst.
* @param src The source file
* @param dst The destination file
* @return true if the copy is successfully,
* false otherwise.
*/
public static boolean copy(File src, File dst) {
// More code goes here
return true;
}
// More methods go here
}
总结:
Java中的弃用是提供有关API生命周期的信息的一种方式。 弃用API会告诉用户迁移,因为API有使用的危险,更好的替换存在,否则将在以后的版本中被删除。 使用弃用的API会生成编译时弃用警告。
@deprecated Javadoc标签和@Deprecated注解一起用于弃用API元素,如模块,包,类型,构造函数,方法,字段,参数和局部变量。 在JDK 9之前,注解不包含任何元素。 它在运行时保留。
JDK 9为注解添加了两个元素:since和forRemoval。 since元素默认为空字符串。 其值表示弃用的API元素的API版本。forRemoval元素的类型为boolean,默认为false。 其值为true表示API元素将在以后的版本中被删除。
JDK 9编译器根据@Deprecated注解的forRemoval元素的值生成两种类型的弃用警告:forRemoval = false时为普通的弃用警告,forRemoval = true时为最终的删除警告。
在JDK 9之前,可以通过使用@SuppressWarnings(“deprecation”)注解标示已弃用的API的使用场景来抑制弃用警告。 在JDK 9中,需要使用@SuppressWarnings(“deprecation”)来抑制普通警告,@SuppressWarnings(“removal”)来抑制删除警告,而@SuppressWarnings({“deprecation”, “removal”}可以抑制两种类型的警告。
在JDK 9之前,使用import语句导入弃用的构造会生成编译时弃用警告。 JDK 9省略了这样的警告。
10.处理json的时候尽量不使用org.codehaus.jettison包:
今天遇到了个问题,就是传参是数组,咋么都强转不成List类型
传参:
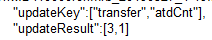
使用处理org.codehaus.jettison处理:
List<String> updateKey = (List<String>) params.get("updateKey");
报错:
java.lang.ClassCastException: org.codehaus.jettison.json.JSONArray cannot be cast to java.util.List
后来替换成net.sf.json.JSONObject就不报错。。。
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
备注:最后一行需要保留,有两个jdk版本的实现:json-lib-2.1-jdk13.jar和json-lib-2.1-jdk15.jar
11.java占位符使用:
第一种:使用%s占位,使用String.format转换
public static void main(String[] args) {
String url = "我叫%s,今年%s岁。";
String name = "小明";
String age = "28";
url = String.format(url,name,age);
System.out.println(url);
}
实际使用:n位数补零
String.format("%0nd", num);
这里%0nd中的0是占位符(不写时会以空格补足),n是位数,d代表数字类型;
例:String.format("%05d", 77); -->结果为00077
第二种:使用{1}占位,使用MessageFormat.format转换
public static void main(String[] args) {
String url02 = "我叫{0},今年{1}岁。";
String name = "小明";
String age = "28";
url02 = MessageFormat.format(url02,name,age);
System.out.println(url02);
}
12.判断一个字符串是否包含某个字符:
一、contains方法:
String str = "abc";
boolean status = str.contains("a");
if(status){
System.out.println("包含");
}else{
System.out.println("不包含");
}
二、indexOf方法:
String str1 = "abcdefg";
int result1 = str1.indexOf("a");
if(result1 != -1){
System.out.println("字符串str中包含子串“a”"+result1);
}else{
System.out.println("字符串str中不包含子串“a”"+result1);
}
13.将ResultSet结果集遍历到List中:
private static List convertList(ResultSet rs) throws SQLException{
List list = new ArrayList();
ResultSetMetaData md = rs.getMetaData();//获取键名
int columnCount = md.getColumnCount();//获取行的数量
while (rs.next()) {
Map rowData = new HashMap();//声明Map
for (int i = 1; i <= columnCount; i++) {
rowData.put(md.getColumnName(i), rs.getObject(i));//获取键名及值
}
list.add(rowData);
}
return list;
}
14.获取文件大小:
public static void main(String[] args) {
File f= new File("F:\\hehe.json");
if (f.exists() && f.isFile()){
System.out.println("文件大小:" + String.valueOf(f.length()) + "字节(Byte)");
}else{
System.out.println("file doesn't exist or is not a file");
}
}
15.equalsIgnoreCase() 方法:
equalsIgnoreCase() 方法用于将字符串与指定的对象比较,不考虑大小写。equals() 会判断大小写区别,equalsIgnoreCase() 不会判断大小写区别:
public class Test {
public static void main(String args[]) {
String Str1 = new String("runoob");
String Str2 = Str1;
String Str3 = new String("runoob");
String Str4 = new String("RUNOOB");
boolean retVal;
retVal = Str1.equals( Str2 );
System.out.println("返回值 = " + retVal );
retVal = Str3.equals( Str4);
System.out.println("返回值 = " + retVal );
retVal = Str1.equalsIgnoreCase( Str4 );
System.out.println("返回值 = " + retVal );
}
}
以上程序执行结果为:
返回值 = true
返回值 = false
返回值 = true
16.使用split对.分割的时候需要转义:
String[] hahas = "t2.columns".split(".");
for (String haha : hahas) {
System.out.println("1-->" + haha);
}
String[] hehes = "t2.columns".split("\\.");
for (String hehe : hehes) {
System.out.println("2-->" + hehe);
}
String[] qies = "t2,columns".split(",");
for (String qie : qies) {
System.out.println("3-->" + qie);
}
// 注意:而replace却必须是.而不能是\\.
System.out.println("t2,columns".replace("\\.", ":"));
System.out.println("t2,columns".replace(".", ":"));
// 输出结果:
2-->t2
2-->columns
3-->t2
3-->columns
t2.columns
t2:columns
17.神奇的特殊字符导致的数据问题:
今天遇到了个神奇的问题,就是从前端传过来的参数去mongdb库中搜索却搜不到数据(mongdb库中有该数据),后来用手动输的就好使。
db.getCollection('newsKey').find({"medianame" : "人民网"})
db.getCollection('newsKey').find({"medianame" : "人民网"})
上面这两个语句上面那个能搜到相应的数据,而下面的却不可以,虽然你肉眼看这两个语句一模一样,但是你把鼠标移动到双引号和人之间,再按键盘上的←或→键,你会发现下面的语句得按两下才可以移动到“人”字的后面,而上面的语句按一下就可以了,这说明下面的语句双引号和人字中间存在某种字符却没有显示。我的解决方式是
System.out.println("人民网".length()); //打印结果是4,如果不存在那个隐藏字符的话打印结果应该是3
System.out.println("人民网".replaceAll("", "").length());
在替换方法里看的好像是空替换成了空,实则是将那个隐藏的字符替换成了空(将双引号和“人”字之间的东西Ctrl+C复制到替换方法里的第一个双引号中)。
备注:该神奇的特殊字符的Unicode码是\ufeff
拓展: utf-8与utf-8-sig两种编码格式的区别:
As UTF-8 is an 8-bit encoding no BOM is required and anyU+FEFF character in the decoded Unicode string (even if it’s the firstcharacter) is treated as a ZERO WIDTH NO-BREAK SPACE.
UTF-8以字节为编码单元,它的字节顺序在所有系统中都是一様的,没有字节序的问题,也因此它实际上并不需要BOM(“ByteOrder Mark”)。但是UTF-8 with BOM即utf-8-sig需要提供BOM。
可参考:https://www.cnblogs.com/chongzi1990/p/8694883.html
几个概念性的东西:
ANSCII:
标准的 ANSCII 编码只使用7个比特来表示一个字符,因此最多编码128个字符。扩充的 ANSCII 使用8个比特来表示一个字符,最多也只能 编码 256 个字符。
UNICODE:
使用2个甚至4个字节来编码一个字符,因此可以将世界上所有的字符进行统一编码。
UTF:
UNICODE编码转换格式,就是用来指导如何将 unicode 编码成适合文件存储和网络传输的字节序列的形式 (unicode -> str)。像其他的一些编码方式 gb2312, gb18030, big5 和 UTF 的作用是一样的,只是编码方式不同。
可参考:https://www.cnblogs.com/mjiang2017/p/8431977.html
不能被复制的字符/u0000:
场景:在用springboot程序把Oracle中的数据插入到gauss时insert语句中有一行总是报错咋也插不进去,在Linux打印的日志中为不可见字符,如下图:
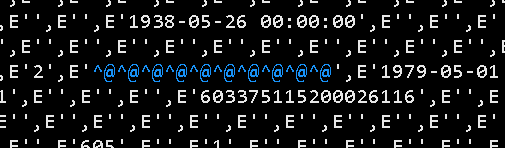
导出到Windows中用Visual Studio Code打开也是乱码,如下图:

更神奇的是我在Visual Studio Code中把这行有问题的数据想粘贴到一个临时文件中排查下,结果乱码后面的内容无法粘贴。最后用idea编写java代码去读这个文件并且定位到这个乱码的位置然后再转换为Unicode码后发现是10个Unicode码为/u0000的字符。读取的文件为:

代码为:
省略部分io流读取代码。。。
char[] c = line.toCharArray();
for(int i = 0;i<c.length;i++){//输出字节数组每个元素的Unicode值
System.out.println(Character.codePointAt(c,i)+",");
}
输出结果为:
69,
39,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
39,
测试代码:
public static void main(String[] args) {
String a = String.valueOf('\u0000'); //控制台输出的是空格,\u0000 表示的是Unicode值
System.out.println("a的Unicode值:" + Integer.toHexString(a.charAt(0)));// \u0000
String b = " "; // 空格字符串
String c = ""; //空字符串
String d = null; //没有任何指向的字符串引用
String e = "null"; //null字符串,这个null是常量池里的
System.out.println(a + ";" + b + ";" +c + ";" + d + ";" + e + ";");
System.out.println("a.equals(c):" + a.equals(c)); // false
System.out.println("a.equals(b):" + a.equals(b)); // false
System.out.println("a == c:" + (a == c)); // false
System.out.println("a == d:" + (d == a)); // false
System.out.println("a.equals(e):" + a.equals(e)); // false
}
输出结果:
a的Unicode值:0
; ;;null;null;
a.equals(c):false
a.equals(b):false
a == c:false
a == d:false
a.equals(e):false
总结:
1、/u0000 是一个空的字符,虽然它转换为字符串输出为空格,但是它与空格、空字符串、NULL和"null"都不同,所以无法找到能够描述它的符号;
2、我们知道,Character类定了最小值 MIN_VALUE = ‘\u0000’,这也是ASCII表的最小值,这样描述:空字符(NUL);
3、该字符在输出后还不能够复制粘贴,如果一个字符串中含有该字符那么,它后面的所有字符串都不会被复制粘贴;
4、通过request.setAttribute 在前台得到的是既不是""也不是null的“空”,不占位置;
5、通过response.getWriter().write()方法向客户端传递数据时,如果字符串含有/u0000,那么在该字符后的所有字符串都不会被传递过去。
处理:
所以在数据含有该字符的时候需要处理一下:str.replace(“/u0000”,“”);将该字符替换成""就行了。
这种情况很少见,之前我也从来没遇到过,这次由于我处理的数据是由oracle库抽出来的数据,很不规范,那些数据录入的时候怎么录得控制不了,所以出现问题的时候还是要考虑到这种情况的。
备注:提供两个转码工具的连接:http://www.bejson.com/ 和 https://www.sojson.com/ascii.html


















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











