







 本文详细介绍Oozie调度框架的安装配置、测试使用及高级特性。包括工作流定义、定时任务配置、并行处理及任务编排。适用于希望利用Oozie进行复杂Hadoop作业调度的开发者。
本文详细介绍Oozie调度框架的安装配置、测试使用及高级特性。包括工作流定义、定时任务配置、并行处理及任务编排。适用于希望利用Oozie进行复杂Hadoop作业调度的开发者。
文章目录
一、Hadoop常见调度框架
- Linux Crontab:Linux自带的任务调度计划,在任务比较少的情况下,可以使用这种方式,直接执行脚本,例如添加一个执行计划:
0 12 * hive -f xxx.sql - Azkaban:
- Oozie:Cloudera公司开源
- Zeus:阿里开源
- Dolphinscheduler
1.Work Flow流程图:
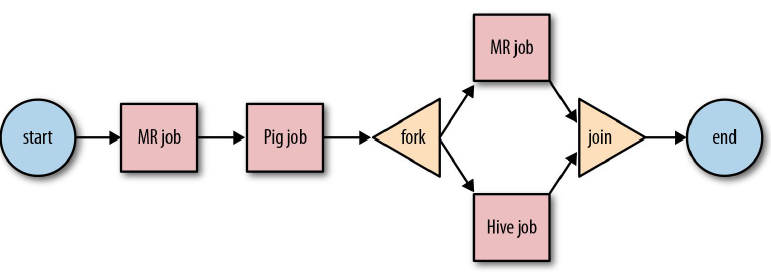
Oozie是一个开源的工作流调度系统,它能够管理逻辑复杂的多个Hadoop作业,按照指定的顺序将其协同运行起来。例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
- 通过Hadoop先将原始数据同步到HDFS上;
- 借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储到多张Hive表中;
- 需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive大表;
- 将明细数据进行复杂的统计分析,得到排序后的报表信息;
- 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
上述过程可以通过工作流系统来编排任务,最终生成一个工作流实例,然后每天定时启动运行这个实例即可。在这种依赖于Hadoop存储和处理能力要求的应用场景下,Oozie可能能够简化任务调度和执行。
Oozie是管理Hadoop作业的工作流调度系统。Oozie定义了控制流节点和动作节点。
2.Oozie有几个主要概念:
- workflow :工作流 ,顺序执行流程节点,支持fork(分支多个节点),join(合并多个节点为一个)。
- coordinator :多个workflow可以组成一个coordinator,可以把前几个workflow的输出作为后一个workflow的输入,也可以定义workflow的触发条件,来做定时触发。
- bundle: 是对一堆coordinator的抽象, 可绑定多个coordinator。
- job.properties:定义环境变量。
在Oozie中,工作流的状态可能存在如下几种:
| 状态 | 含义说明 |
|---|---|
| PREP | 一个工作流Job第一次创建将处于PREP状态,表示工作流Job已经定义,但是没有运行。 |
| RUNNING | 当一个已经被创建的工作流Job开始执行的时候,就处于RUNNING状态。它不会达到结束状态,只能因为出错而结束,或者被挂起。 |
| SUSPENDED | 一个RUNNING状态的工作流Job会变成SUSPENDED状态,而且它会一直处于该状态,除非这个工作流Job被重新开始执行或者被杀死。 |
| SUCCEEDED | 当一个RUNNING状态的工作流Job到达了end节点,它就变成了SUCCEEDED最终完成状态。 |
| KILLED | 当一个工作流Job处于被创建后的状态,或者处于RUNNING、SUSPENDED状态时,被杀死,则工作流Job的状态变为KILLED状态。 |
| FAILED | 当一个工作流Job不可预期的错误失败而终止,就会变成FAILED状态。 |
上述各种状态存在相应的转移(工作流程因为某些事件,可能从一个状态跳转到另一个状态),其中合法的状态转移有如下几种,如下表所示:
| 转移前状态 | 转移后状态集合 |
|---|---|
| 未启动 | PREP |
| PREP | RUNNING、KILLED |
| RUNNING | SUSPENDED、SUCCEEDED、KILLED、FAILED |
| SUSPENDED | RUNNING、KILLED |
二、Oozie安装
Oozie不需要设置OOZIE_HOME环境变量(系统自行计算),推荐使用单独的用户(而不是root)来安装Oozie。
1.编译源码,解压压缩包:
可参考:http://oozie.apache.org/docs/4.0.0/DG_QuickStart.html
如果需要对Oozie个性化修改,可以自行修改源代码并编译,这里直接使用官网编译好的版本oozie-4.1.0-cdh5.5.2.tar.gz:
[hadoop@h71 ~]$ tar -zxvf oozie-4.1.0-cdh5.5.2.tar.gz
以下配置添加到core-site.xml文件(使用用户和hostname替换文档中内容):
[hadoop@h71 ~]$ vi $HADOOP_HOME/etc/hadoop/core-site.xml
<!-- OOZIE -->
<property>
<name>hadoop.proxyuser.natty.hosts</name>
<value>h71</value>
</property>
<property>
<name>hadoop.proxyuser.natty.groups</name>
<value>*</value>
</property>
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ vi $OOZIE_HOME/conf/oozie-site.xml
<property>
<name>oozie.service.HadoopAccessorService.hadoop.configurations</name>
<value>*=/home/hadoop/hadoop-2.6.0-cdh5.5.2/etc/hadoop</value>
<description>
Comma separated AUTHORITY=HADOOP_CONF_DIR, where AUTHORITY is the HOST:PORT of
the Hadoop service (JobTracker, HDFS). The wildcard '*' configuration is
used when there is no exact match for an authority. The HADOOP_CONF_DIR contains
the relevant Hadoop *-site.xml files. If the path is relative is looked within
the Oozie configuration directory; though the path can be absolute (i.e. to point
to Hadoop client conf/ directories in the local filesystem.
</description>
</property>
在解压oozie二进制发行包的目录中,解压hadooplibs发行包,也就是oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz,这样,oozie的安装目录多了一个hadooplibs目录。:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ tar -zxvf oozie-hadooplibs-4.1.0-cdh5.5.2.tar.gz
2.详细配置:
启动应该使用oozied.sh脚本,并添加start、stop、run等参数。
在oozie的解压目录下创建libext目录。并将hadooplibs下的jar包拷贝到这个目录里,需要注意的是hadooplibs目录下有个文件夹hadooplib-2.6.0-cdh5.5.2.oozie-4.1.0-cdh5.5.2,hadooplib-2.6.0-mr1-cdh5.5.2.oozie-4.1.0-cdh5.5.2;后者对应于mapreduce1,所以我们拷贝第一个文件夹下的jar包即可。还要将ext-3.0.0.zip的压缩包上传到libext目录,所需的ext-3.0.0.zip我已经上传oozie所需的js包文件
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ mkdir libext
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ cp hadooplibs/hadooplib-2.6.0-cdh5.5.2.oozie-4.1.0-cdh5.5.2/* libext/
$ cp ext-3.0.0.zip /home/hadoop/ooozie-4.1.0-cdh5.5.2/libext/
$ unzip ext-3.0.0.zip
安装mysql数据库,并生成相关表(oozie是一个web系统,需要自己的知识库),所以,我们需要mysql connector驱动包,拷贝到$oozie_home/libext下。
$ cp mysql-connector-java-5.1.33-bin.jar /home/hadoop/ooozie-4.1.0-cdh5.5.2/libext/
(1)生成mysql数据表(oozie所需要的):
我们可以使用 bin/oozie-setup.sh 命令的db create参数,来操作mysql数据库创建相应的库和表。但在使用这个命令前,需要先给oozie关联上mysql。下面先做关联操作:修改oozie的配置文件($oozie_home/conf/oozie-site.xml),配置driver、url、username、password:
<!-- Oozie Related Mysql -->
<property>
<name>oozie.service.JPAService.jdbc.driver</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.url</name>
<value>jdbc:mysql://h71:3306/oozie?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.username</name>
<value>hadoop</value>
</property>
<property>
<name>oozie.service.JPAService.jdbc.password</name>
<value>123456</value>
</property>
(2)关联好mysql之后,通过脚本创建mysql的库表:
注意:在创建库表之前要在MySQL中做如下操作:
mysql> grant all privileges on *.* to hadoop@'h71' identified by '123456';
mysql> flush privileges;
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ bin/oozie-setup.sh db create -run oozie.sql
setting CATALINA_OPTS="$CATALINA_OPTS -Xmx1024m"
Validate DB Connection
DONE
Check DB schema does not exist
DONE
Check OOZIE_SYS table does not exist
DONE
Create SQL schema
DONE
Create OOZIE_SYS table
DONE
Oozie DB has been created for Oozie version '4.1.0-cdh5.5.2'
The SQL commands have been written to: /tmp/ooziedb-8197609038028550269.sql
执行成功之后,登陆到mysql验证数据库表的创建情况:
mysql> use oozie;
mysql> show tables;
+------------------------+
| Tables_in_oozie |
+------------------------+
| BUNDLE_ACTIONS |
| BUNDLE_JOBS |
| COORD_ACTIONS |
| COORD_JOBS |
| OOZIE_SYS |
| OPENJPA_SEQUENCE_TABLE |
| SLA_EVENTS |
| SLA_REGISTRATION |
| SLA_SUMMARY |
| VALIDATE_CONN |
| WF_ACTIONS |
| WF_JOBS |
+------------------------+
12 rows in set (0.00 sec)
(3)下面生成war包,供tomcat访问:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ bin/oozie-setup.sh prepare-war
# 命令执行成功后,会提示war包已经生成在webapps目录下:New Oozie WAR file with added 'JARs' at /home/hadoop/oozie-4.1.0-cdh5.5.2/oozie-server/webapps/oozie.war
(4)上传sharelib压缩包到HDFS上:
在$oozie_home下,有2个sharelib压缩包,分别是oozie-sharelib-4.1.0-cdh5.5.2.tar.gz和oozie-sharelib-4.1.0-cdh5.5.2-yarn.tar.gz,很明显,我们必须拷贝第二个带yarn的压缩包(前边的是1.0版本的,不带yarn的)。
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ bin/oozie-setup.sh sharelib create -fs hdfs://h71:9000 -locallib oozie-sharelib-4.1.0-cdh5.5.2-yarn.tar.gz
# 会报错:
setting CATALINA_OPTS="$CATALINA_OPTS -Xmx1024m"
the destination path for sharelib is: /user/hadoop/share/lib/lib_20170317224413
Error: User: hadoop is not allowed to impersonate hadoop
Stack trace for the error was (for debug purposes):
--------------------------------------
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoop is not allowed to impersonate hadoop
at org.apache.hadoop.ipc.Client.call(Client.java:1466)
at org.apache.hadoop.ipc.Client.call(Client.java:1403)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:752)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:256)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:104)
at com.sun.proxy.$Proxy15.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:2095)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1214)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1210)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1210)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1409)
at org.apache.hadoop.fs.FileUtil.checkDest(FileUtil.java:499)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:351)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:341)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1944)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1912)
at org.apache.oozie.tools.OozieSharelibCLI.run(OozieSharelibCLI.java:166)
at org.apache.oozie.tools.OozieSharelibCLI.main(OozieSharelibCLI.java:57)
--------------------------------------
解决:在core-site.xml添加如下属性,其中hadoop.proxyuser.hadoop.groups中的hadoop是用户,value里面的hadoop是group
[hadoop@h71 hadoop-2.6.0-cdh5.5.2]$ vi etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>hadoop</value>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>h71</value>
<description>The superuser can connect only from host1 and host2 to impersonate a user</description>
</property>
然后重启hadoop:
[hadoop@h71 hadoop-2.6.0-cdh5.5.2]$ sbin/stop-all.sh
[hadoop@h71 hadoop-2.6.0-cdh5.5.2]$ sbin/start-all.sh
3.启动oozie和测试:
启动oozie,使用oozied.sh脚本:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ bin/oozied.sh start
启动后,访问网址http://h71:11000/oozie/

三、Oozie测试和使用(执行官方example实例)
Oozie官方提供了一个样例包,我们后边的开发都以这个example实例为模板进行。解压Oozie主目录下的example包:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ tar zxf oozie-examples.tar.gz
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ cd examples/apps/
apps目录下存放了我们需要配置的作业内容:
[hadoop@h71 apps]$ ls
aggregator bundle cron cron-schedule custom-main datelist-java-main demo distcp hadoop-el hcatalog
hive hive2 java-main map-reduce no-op pig shell sla spark sqoop sqoop-freeform ssh streaming subwf
在目录中可以看到,有关于map-reduce、sqoop、hive等很多类型的作业的配置的实例。下面,我以map-reduce作业为例来说明,oozie作业的配置方法。在map-reduce目录中有三个重要的内容:
- job.properties:定义job相关的属性,比如输入输出目录、namenode节点等。定义了workflow.xml文件的位置。
- workflow.xml:定义工作流相关的配置,start 、 end 、kill等。
- lib文件夹:存放job任务需要的jar包。
注意:配置作业需要修改job.properties和workflow.xml两个文件。
配置job.properties:
nameNode=hdfs://h71:9000
jobTracker=h71:8032
queueName=default
examplesRoot=examples
user.name=hadoop
# 配置我们文件上传到hdfs的保存路径 实际上就是在hdfs上的/user/hadoop/examples/apps/map-reduce这个路径下,没有所说目录的话先创建hadoop fs -mkdir -p /user/hadoop/examples/apps/map-reduce
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/map-reduce/workflow.xml
outputDir=map-reduce
注:jobTracker配置的是ResourceManager的端口。需要一定注意,我们的ResourceManager配置在senior02主机上,并且端口是8032(不是8088,8088端口是web界面查看的端口)
配置workflow.xml:
<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/hadoop/${examplesRoot}/output-data/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/hadoop/${examplesRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/hadoop/${examplesRoot}/output-data/${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
上传examples目录到HDFS的/user/natty/路径:
[hadoop@h71 ~]$ hadoop fs -put oozie-4.1.0-cdh5.5.2/examples/ /user/hadoop
运行example应用:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ bin/oozie job -oozie http://h71:11000/oozie -config examples/apps/map-reduce/job.properties -run
job: 0000000-170317232542282-oozie-hado-W
杀掉job:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ bin/oozie job -oozie http://h71:11000/oozie -kill 0000000-170317232542282-oozie-hado-W
参考:
Oozie介绍
oozie 安装过程总结
Oozie4.2 安装部署、以及example测试
Oozie 快速入门
四、hql语句的定时调度 ( coordinator )
1.配置 oozie-site.xml 文件:oozie 时区
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ vim conf/oozie-site.xml
# 添加。修改时区为东八区区时
<property>
<name>oozie.processing.timezone</name>
<value>GMT+0800</value>
</property>
注意:如果不修改这里的话job.properties中的时间得写成这样的start=2021-09-30T16:30Z,否则报错:

2.修改 js 框架中的关于时间设置的代码:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ vim oozie-server/webapps/oozie/oozie-console.js
# 修改如下:
function getTimeZone() {
Ext.state.Manager.setProvider(new Ext.state.CookieProvider());
return Ext.state.Manager.get("TimezoneId","GMT+0800");
}
3.重启 oozie 服务,并重启浏览器(一定要注意清除缓存):
bin/oozied.sh stop
bin/oozied.sh start
4.参考官方模板配置文件夹:cron 文件夹和 hive2 文件夹:
拷贝hive的案例模板:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ cp -ra examples/apps/hive2/ oozie_works/
编辑job.properties:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ vim oozie_works/job.properties
nameNode=hdfs://h71:8020
jobTracker=h71:8032
queueName=default
jdbcURL=jdbc:hive2://h71:10000/datawarehouse_dws
examplesRoot=oozie_works
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/hive2
# start:必须设置为未来时间,否则任务失败
start=2021-09-30T16:30+0800
end=2021-09-30T16:40+0800
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/hive2
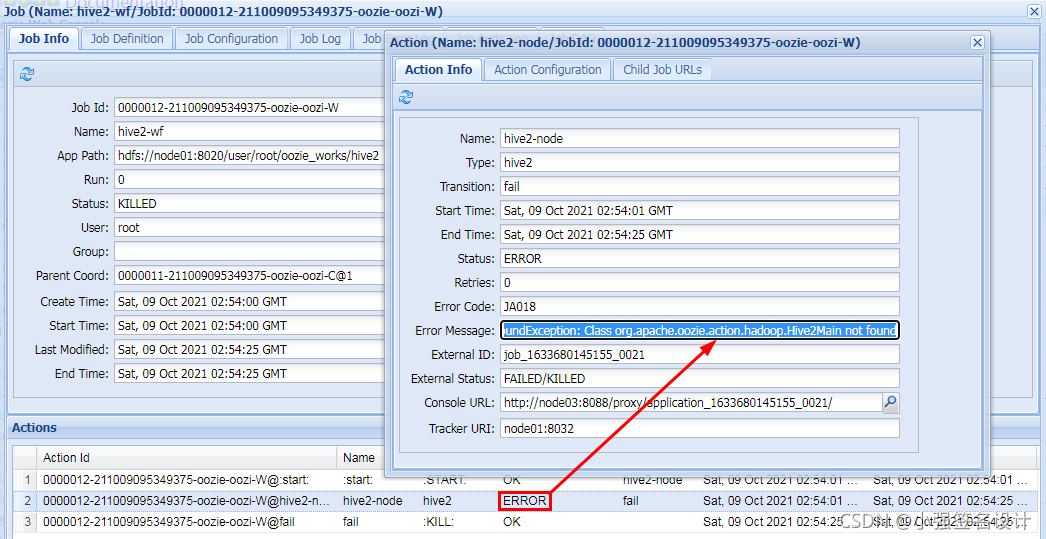
# 这行也得有,否则报错java.lang.ClassNotFoundException: Class org.apache.oozie.action.hadoop.Hive2Main not found
oozie.use.system.libpath=true
配置文件 coordinator.xml ( 时间相关 ):
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ vim oozie_works/coordinator.xml
<coordinator-app name="cron-coord" frequency="${coord:minutes(5)}" start="${start}" end="${end}" timezone="GMT+0800" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
编辑hql语句文件 script.q:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ vim oozie_works/script.q
create table if not exists member_reg_num_day_tmp as
select
*
from
datawarehouse_dwd.dwd_rongrong_us_user;
配置文件 workflow.xml:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ vim oozie_works/workflow.xml
<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.5" name="hive2-wf">
<start to="hive2-node"/>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/>
<mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script.q</script>
<param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param>
<param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param>
</hive2>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
5.上传配置:
# 注:job.properties文件可不传,其他的文件需要上传到hdfs中
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ hdfs dfs -put oozie_works/* /user/root/oozie_works/hive2
6.启动任务:
[hadoop@h71 oozie-4.1.0-cdh5.5.2]$ bin/oozie job -oozie http://h71:11000/oozie -config oozie_works/job.properties -run
job: 0000000-210930171154420-oozie-oozi-C
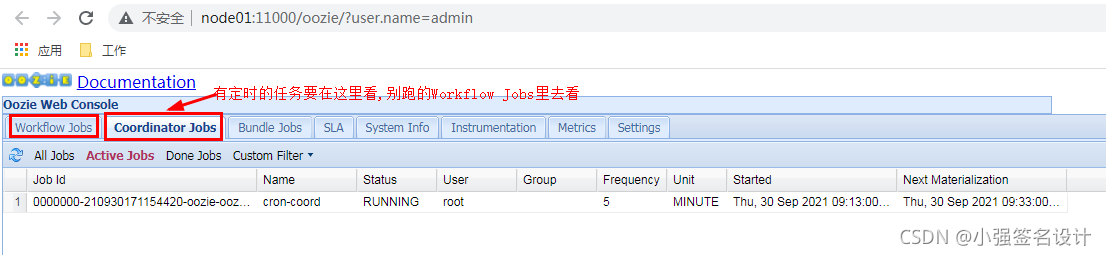
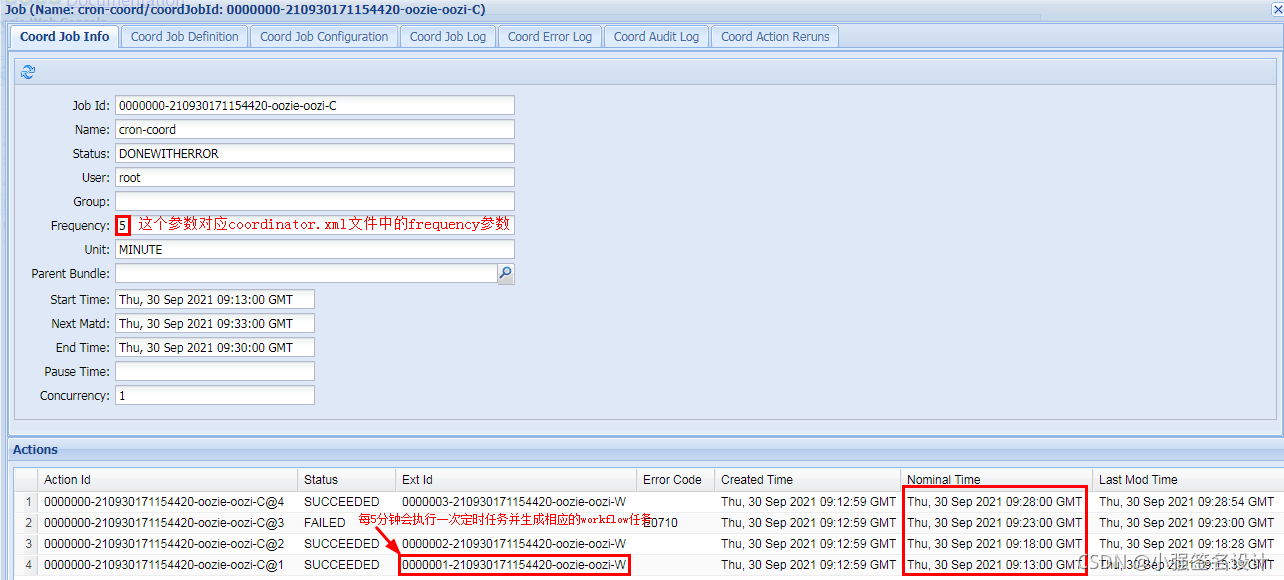
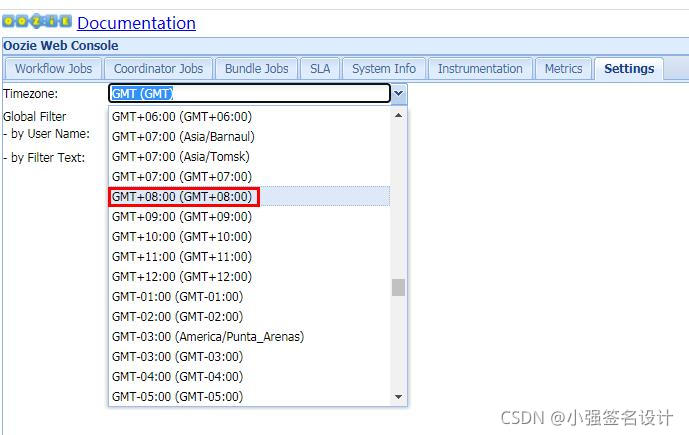
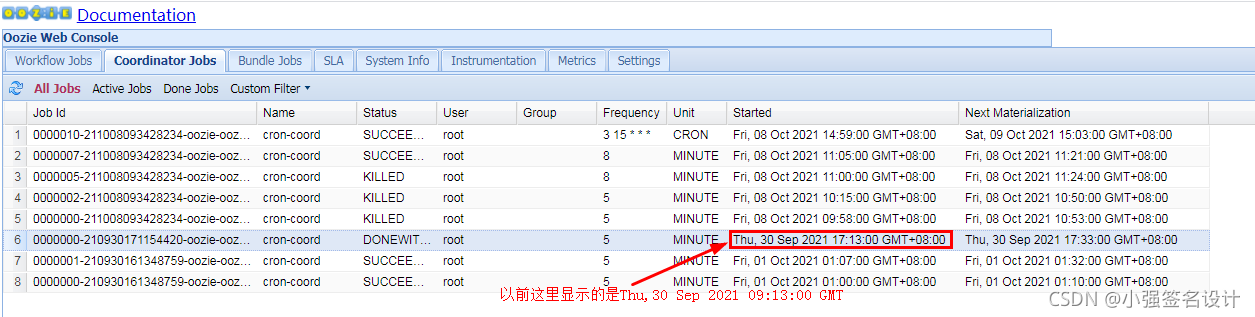
页面在Setting中把Timezone改为GMT+08:00 (GMT+08:00),否则任务显示的时间为GMT
7.关于定时方式:
| EL Constant | Value | Example |
|---|---|---|
| ${coord:minutes(int n)} | n | ${coord:minutes(45)} |
| ${coord:hours(int n)} | n * 60 | ${coord:hours(3)} |
| ${coord:days(int n)} | variable | ${coord:days(2)} |
| ${coord:months(int n)} | variable | ${coord:months(1)} |
| ${cron syntax} | variable | 0,10 15 * * 2-6 --> a job that runs every weekday at 3:00pm and 3:10pm UTC time |
注意:错误提示:Error: E1003 : E1003: Invalid coordinator application attributes, Coordinator job with frequency [2] minutes is faster than allowed maximum of 5 minutes (oozie.service.coord.check.maximum.frequency is set to true)
错误原因:开启了检查频率,导致5分钟以内的频率运行失败。
解决:关闭频率检查功能 配置oozie-site.xml文件。
<property>
<name>oozie.service.coord.check.maximum.frequency</name>
<value>false</value>
</property>
五、fork和join结点
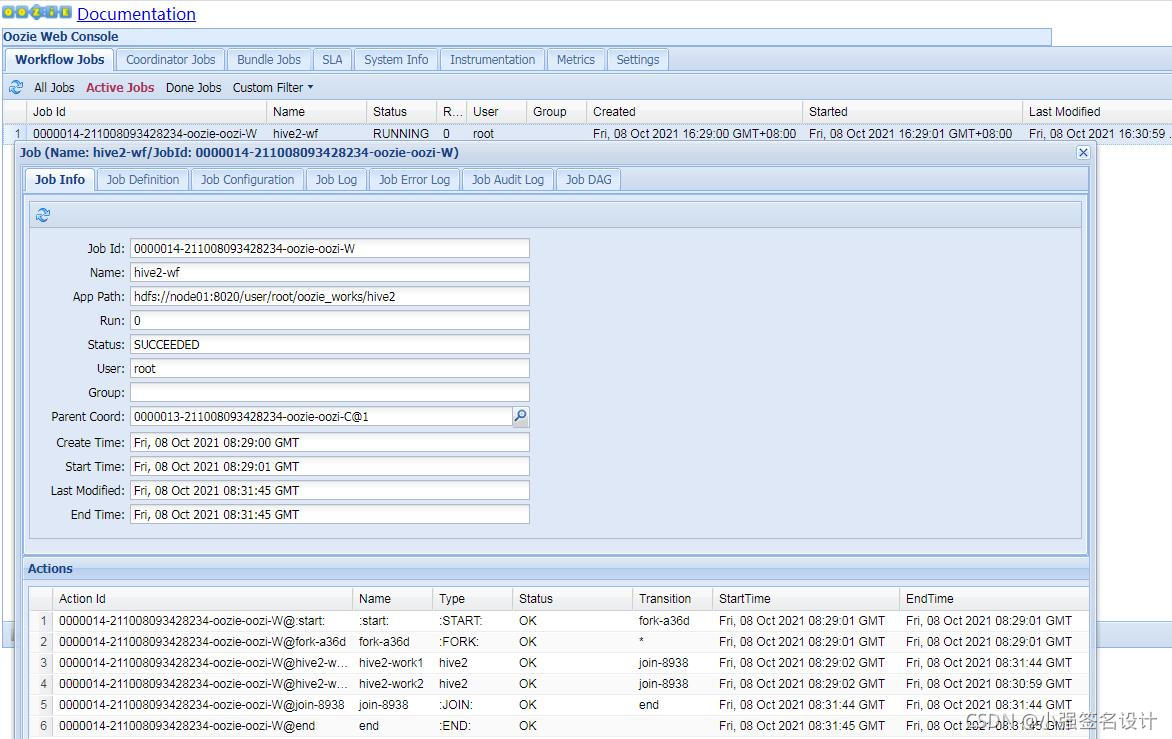
oozie可以用fork和join节点进行多任务并行处理,fork和join也是同时出现,缺一不可。fork节点把任务切分成多个并行任务,join则合并多个并行任务。fork和join节点必须是成对出现的。join节点合并的任务,必须是通一个fork出来的子任务才行。
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<fork name="[FORK-NODE-NAME]">
<path start="[NODE-NAME]" />
...
<path start="[NODE-NAME]" />
</fork>
...
<join name="[JOIN-NODE-NAME]" to="[NODE-NAME]" />
...
</workflow-app>
再创建一个script2.q脚本,修改前面的workflow.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.5" name="hive2-wf">
<start to="fork-a36d"/>
<action name="hive2-work1">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/>
<mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script.q</script>
<param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param>
<param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param>
</hive2>
<ok to="join-8938"/>
<error to="fail"/>
</action>
<action name="hive2-work2">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/>
<mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script2.q</script>
<param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param>
<param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param>
</hive2>
<ok to="join-8938"/>
<error to="fail"/>
</action>
<fork name="fork-a36d">
<path start="hive2-work1" />
<path start="hive2-work2" />
</fork>
<join name="join-8938" to="end"/>
<kill name="fail">
<message>Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>


六、Bundle组件
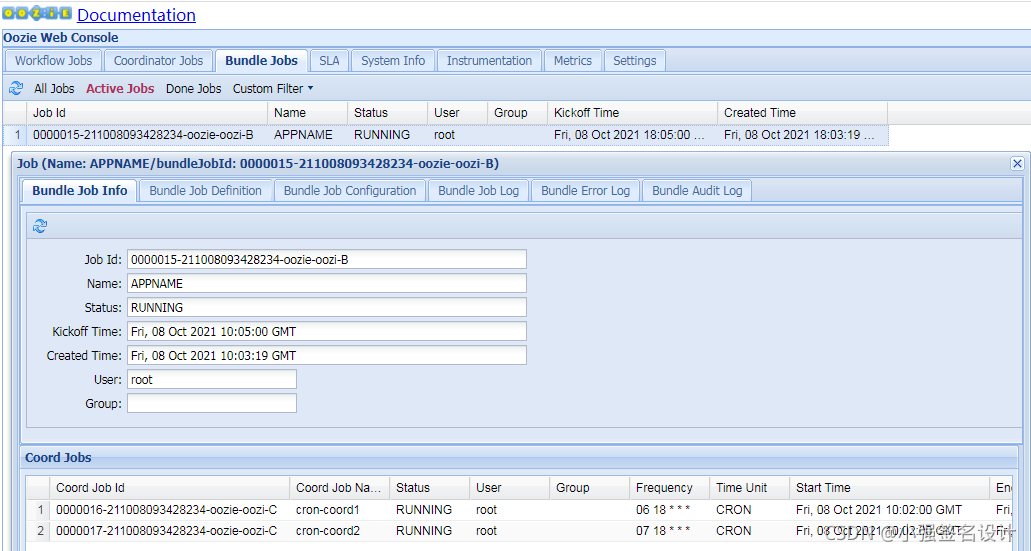
Bundle 是Oozie任务组织架构中higher-level的组织形式,在技术实现上,它是coordinator应用的一个集合,在业务上用户可以将多个coordinator 应用组合起来形成一个数据管道,在Bundle内的coordinator没有上下依赖关系,用户可以通过coordinator的依赖数据来将coordinator组织成一个数据管道流向。
编辑bundle.xml文件:
<bundle-app name='APPNAME' xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance' xmlns='uri:oozie:bundle:0.1'>
<controls>
<kick-off-time>${kickOffTime}</kick-off-time>
</controls>
<coordinator name='cron-coord1' >
<app-path>${appPath1}</app-path>
<configuration>
<property>
<name>startTime1</name>
<value>${start}</value>
</property>
<property>
<name>endTime1</name>
<value>${end}</value>
</property>
</configuration>
</coordinator>
<coordinator name='cron-coord2' >
<app-path>${appPath2}</app-path>
<configuration>
<property>
<name>startTime2</name>
<value>${start}</value>
</property>
<property>
<name>endTime2</name>
<value>${end}</value>
</property>
</configuration>
</coordinator>
</bundle-app>
注意:bundle.xml文件名称不可以修改,job.properties文件名称可以修改,比如改为job_tjfx.properties,只要最后启动任务的时候-config参数后指定正确的配置文件名称就可以.
修改job.properties文件:
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
jdbcURL=jdbc:hive2://node01:10000/datawarehouse_dws
examplesRoot=oozie_works
oozie.bundle.application.path=${nameNode}/user/${user.name}/${examplesRoot}/hive2
kickOffTime=2021-10-08T18:05+0800
start=2021-10-08T18:02+0800
end=2021-10-08T19:20+0800
workflowpath1=${nameNode}/user/${user.name}/${examplesRoot}/hive2/workflow1.xml
workflowpath2=${nameNode}/user/${user.name}/${examplesRoot}/hive2/workflow2.xml
appPath1=${nameNode}/user/${user.name}/${examplesRoot}/hive2/coordinator1.xml
appPath2=${nameNode}/user/${user.name}/${examplesRoot}/hive2/coordinator2.xml
oozie.use.system.libpath=true
修改workflow.xml和coordinator.xml文件:
[root@node01 oozie_works]# vim workflow1.xml
<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.5" name="hive2-wf">
<start to="hive2-node"/>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/>
<mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script.q</script>
<param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param>
<param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param>
</hive2>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
[root@node01 oozie_works]# vim workflow2.xml
<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.5" name="hive2-wf">
<start to="hive2-node"/>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/>
<mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script2.q</script>
<param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param>
<param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param>
</hive2>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
[root@node01 oozie_works]# vim coordinator1.xml
<coordinator-app name="cron-coord1" frequency="06 18 * * *" start="${start}" end="${end}" timezone="GMT+0800" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowpath1}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
[root@node01 oozie_works]# vim coordinator2.xml
<coordinator-app name="cron-coord2" frequency="07 18 * * *" start="${start}" end="${end}" timezone="GMT+0800" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowpath2}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>



















 4174
4174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











