







文章目录
一、科学计数法转成字符串
在 Java 中,可以使用 Double.toString(double) 方法将科学计数法的 double 类型转换成字符串。这个方法会根据数值的大小自动选择是否使用科学计数法表示。
以下是一个简单的例子:
public class ScientificNotationConverter {
public static void main(String[] args) {
double scientificNotation = 1.23e10;
String decimalString = Double.toString(scientificNotation);
System.out.println(decimalString); // 输出可能是123000000000,而不是1.23e10
}
}
在这个例子中,如果你希望无论是否是科学计数法都以常规数值形式表示,可以先转换为 BigDecimal,然后调用 toPlainString() 方法。
public class ScientificNotationConverter {
public static void main(String[] args) {
double scientificNotation = 1.23e10;
BigDecimal bd = new BigDecimal(scientificNotation);
String decimalString = bd.toPlainString();
System.out.println(decimalString); // 输出12300000000
}
}
这样可以确保无论数值是否较大,都以常规的十进制数值形式表示。
二、List 空指针异常
错误解决:直接使用 list.isEmpty()
解决方式一:当集合不为null,但是没有元素时,也看做是空的。
if (null != strList && !strList.isEmpty()) {
// ...
}
解决方式二:第三方工具类,hutool 中 CollUtil 工具类
if (!CollUtil.isEmpty(strList)) {
// ...
}
三、string 数组去重
实现方法一:使用HashSet
public String[] removeDuplicates(String[] arr) {
Set<String> set = new HashSet<>();
for (String str : arr) {
set.add(str);
}
return set.toArray(new String[set.size()]);
}
衍生:判断重复项
import java.util.HashSet;
public class FindDuplicates {
public static void main(String[] args) {
int[] nums = {1, 2, 3, 4, 4, 5, 6, 7, 7, 8, 9, 9};
HashSet<Integer> set = new HashSet<>();
for (int num : nums) {
if (!set.add(num)) {
System.out.println("重复项:" + num);
}
}
}
}
实现方法二:使用LinkedHashSet(保留原有顺序)
public String[] removeDuplicates(String[] arr) {
Set<String> set = new LinkedHashSet<>();
Collections.addAll(set, arr);
return set.toArray(new String[set.size()]);
}
实现方法三:使用Stream API
public String[] removeDuplicates(String[] arr) {
return Arrays.stream(arr)
.distinct()
.toArray(String[]::new);
}
四、获取 ResultSet 总行数
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONCUR_UPDATABLE);
ResultSet rset = stmt.executeQuery("select * from yourTableName");
rset.last();
int rowCount = rset.getRow(); //获得ResultSet的总行数
参考:ResultSet:java中ResultSet获得总行数
4.1、判断 ResultSet 集合是否为空
ResultSet rs;
if(rs != null && rs.next()){}
// 执行返回不为null并且指针能下移
注意:rs.next() 使用一次便会被下移一次,如果使用两次第二次可能会有获取不到数据的情况。。。
五、字符串包含子串出现次数
方法1:使用 String 类的 indexOf() 和 substring() 方法
public class SubstringCount {
public static int countSubstring(String str, String sub) {
int count = 0;
int index = 0;
while ((index = str.indexOf(sub, index)) != -1) {
count++;
index += sub.length(); // 移动到子串之后的位置,以避免重复计数
}
return count;
}
public static void main(String[] args) {
String text = "hello world, hello java";
String sub = "hello";
System.out.println("Substrin出现次数: " + countSubstring(text, sub)); // 输出2
}
}
方法2:使用正则表达式
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class SubstringCount {
public static int countSubstring(String str, String sub) {
Pattern pattern = Pattern.compile(Pattern.quote(sub)); // 使用quote避免正则表达式特殊字符的问题
Matcher matcher = pattern.matcher(str);
int count = 0;
while (matcher.find()) {
count++;
}
return count;
}
public static void main(String[] args) {
String text = "hello world, hello java";
String sub = "hello";
System.out.println("Substrin出现次数: " + countSubstring(text, sub)); // 输出2
}
}
方法3:使用 split() 方法(对于简单情况)
public class SubstringCount {
public static int countSubstring(String str, String sub) {
return str.length() - str.replace(sub, "").length(); // 计算替换前后字符串长度的差值即为子串数量(不考虑重叠)
}
public static void main(String[] args) {
String text = "hello world, hello java";
String sub = "hello";
System.out.println("Substrin出现次数: " + countSubstring(text, sub)); // 输出2,但不考虑重叠情况
}
}
对于重叠的子串计数,第一种和第二种方法更合适。第三种方法虽然简单,但不适用于所有情况(特别是当子串重叠时)。在大多数需要精确计数的场景中,推荐使用第一种或第二种方法。
六、java.sql.Date
Java 中有两个 Date 类,一个是 java.util.Date 通常情况下用它获取当前时间或构造时间,另一个是 java.sql.Date 是针对 SQL 语句使用的,它只包含日期而没有时间部分。两个类型的时间可以相互转化。
util.Date 转 sql.Date:
Date utilDate = new Date();//util.Date
System.out.println("utilDate : " + utilDate);
//util.Date转sql.Date
java.sql.Date sqlDate = new java.sql.Date(utilDate.getTime());
System.out.println("sqlDate : " + sqlDate);
运行结果:
utilDate : Fri Jan 03 15:13:41 CST 2025
sqlDate : 2025-01-03
从运行结果看到 util.date 转成 sql.date 之后,只有年月日,没有时分秒。下面给大家看点东西就知道为什么会这样了
java.sql包下给出三个与数据库相关的日期时间类型:
Date:表示日期,只有年月日,没有时分秒。会丢失时间;
Time:表示时间,只有时分秒,没有年月日。会丢失日期;
Timestamp:表示时间戳,有年月日时分秒,以及毫秒。
代码:
Date utilDate = new Date();//util utilDate
System.out.println("utilDate : " + utilDate);
Timestamp sqlDate = new Timestamp(utilDate.getTime());//uilt date转sql date
System.out.println("sqlDate : " + sqlDate);
运行结果:
utilDate : Fri Jan 03 15:15:54 CST 2025
sqlDate : 2025-01-03 15:15:54.677
这样就有时分秒了,sql.Date 转 util.Date,触类旁通,就直接上代码了
System.out.println("*********util.Date转sql.Date*********");
Date utilDate = new Date();//util.Date
System.out.println("utilDate : " + utilDate);
Timestamp sqlDate = new Timestamp(utilDate.getTime());//util.Date转sql.Date
System.out.println("sqlDate : " + sqlDate);
System.out.println("*********sql.Date转util.Date*********");
System.out.println("sqlDate : " + sqlDate);
Date date = new Date(sqlDate.getTime());//sql.Date转util.Date
/*
java.util.Date date = new java.util.Date(sqlDate.getTime());
*/
System.out.println("utilDate : " + date);
运行结果:
*********util.Date转sql.Date*********
utilDate : Fri Jan 03 15:17:00 CST 2025
sqlDate : 2025-01-03 15:17:00.514
*********sql.Date转util.Date*********
sqlDate : 2025-01-03 15:17:00.514
utilDate : Fri Jan 03 15:17:00 CST 2025
同时 util.Date 和 sql.Date 都可以用 SimpleDateFormat 格式化
Date utilDate = new Date();//uilt.Date
System.out.println("utilDate : " + utilDate);
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("format : " + format.format(utilDate));
System.out.println("**********************************************");
Timestamp sqlDate = new Timestamp(utilDate.getTime());//uilt.Date转sql.Date
System.out.println("sqlDate : " + sqlDate);
System.out.println("format : " + format.format(sqlDate));
运行结果:
utilDate : Fri Jan 03 15:18:20 CST 2025
format : 2025-01-03 15:18:20
**********************************************
sqlDate : 2025-01-03 15:18:20.627
format : 2025-01-03 15:18:20
七、赋值运算符(+=、-=、*=、/=)
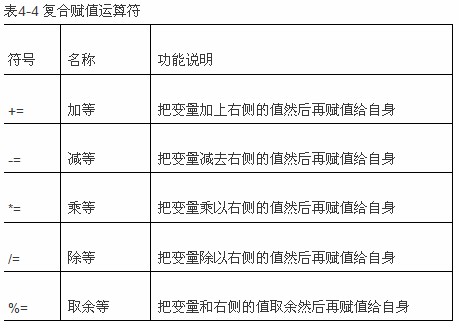
参考:Java赋值运算符(+=、-=、*=、/=)使用中遇到的一些问题
# 返回 -8 的绝对值
Math.abs(-8)
# 9 的平方根
Math.sqrt(9)
# 27 的三次根号
Math.cbrt(27)
# 2 的 3 次方
Math.pow(2,3)
八、文件操作
1. 删除 Linux 上的文件夹:
import java.io.File;
// 删除临时目录
File directory = new File("/mnt/xiaoqiang");
// 获取目录下子文件
File[] filestmp = directory.listFiles();
// 遍历该目录下的文件对象
for (File f : filestmp) {
if (f.getName().endsWith(".parquet") || f.getName().endsWith(".crc")) {
// 删除文件
f.delete();
}
}
directory.delete();
System.out.println("/mnt/xiaoqiang" + " 临时目录已删除");
2. 遍历目录下的文件:
方法一:使用递归
import java.io.File;
public class FileTraversal {
public static void main(String[] args) {
File folder = new File("目标目录的路径");
traverseFolder(folder);
}
public static void traverseFolder(File folder) {
if (folder.isDirectory()) {
File[] files = folder.listFiles();
if (files != null) {
for (File file : files) {
if (file.isDirectory()) {
traverseFolder(file);
} else {
System.out.println(file.getAbsolutePath());
}
}
}
} else {
System.out.println(folder.getAbsolutePath());
}
}
}
方法二:使用栈
import java.io.File;
import java.util.Stack;
public class FileTraversal {
public static void main(String[] args) {
File folder = new File("目标目录的路径");
traverseFolder(folder);
}
public static void traverseFolder(File folder) {
Stack<File> stack = new Stack<>();
stack.push(folder);
while (!stack.isEmpty()) {
File currentFile = stack.pop();
if (currentFile.isDirectory()) {
File[] files = currentFile.listFiles();
if (files != null) {
for (File file : files) {
stack.push(file);
}
}
} else {
System.out.println(currentFile.getAbsolutePath());
}
}
}
}
方法三:使用队列
import java.io.File;
import java.util.LinkedList;
import java.util.Queue;
public class FileTraversal {
public static void main(String[] args) {
File folder = new File("目标目录的路径");
traverseFolder(folder);
}
public static void traverseFolder(File folder) {
Queue<File> queue = new LinkedList<>();
queue.offer(folder);
while (!queue.isEmpty()) {
File currentFile = queue.poll();
if (currentFile.isDirectory()) {
File[] files = currentFile.listFiles();
if (files != null) {
for (File file : files) {
queue.offer(file);
}
}
} else {
System.out.println(currentFile.getAbsolutePath());
}
}
}
}
上述是几种不同的方法来遍历目录下的文件,包括递归、栈和队列。通过递归的方法,可以在遇到子文件夹时自动进入子文件夹继续遍历;而栈和队列的方法通过维护一个待处理的文件集合,不断处理集合中的文件,可以实现相同的效果。这些方法都可以正确地遍历目录下的文件。
3. 文件重命名:
import java.io.File;
public class RenameFileExample {
public static void main(String[] args) {
// 创建File对象指向旧文件
File oldFile = new File("oldFileName.txt");
// 创建File对象指向新文件名
File newFile = new File("newFileName.txt");
// 使用renameTo方法进行重命名
boolean renamed = oldFile.renameTo(newFile);
// 输出结果
if (renamed) {
System.out.println("文件重命名成功!");
} else {
System.out.println("文件重命名失败,确保文件未被打开且路径正确。");
}
}
}
请确保在调用 renameTo 方法之前,旧文件存在,并且没有其他进程正在使用该文件。同时,确保应用程序有足够的权限去更改文件名,并且目标路径存在。如果重命名操作失败,renameTo 方法会返回false。
4. hdfs 文件重命名:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class RenameHdfsFile {
public static void main(String[] args) throws Exception {
// 假设 HDFS 的 URI 是 "hdfs://namenode:8020",需要根据实际情况进行修改
String hdfsUri = "hdfs://namenode:8020";
String oldFileName = "/path/to/oldfile.txt";
String newFileName = "/path/to/newfile.txt";
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(URI.create(hdfsUri), conf);
// 使用FileSystem的rename方法重命名文件
boolean renamed = hdfs.rename(new Path(oldFileName), new Path(newFileName));
if (renamed) {
System.out.println("文件重命名成功!");
} else {
System.out.println("文件重命名失败!");
}
hdfs.close();
}
}
确保在运行此代码之前,已经设置好Hadoop的相关配置,并且有权限对HDFS上的文件进行操作。此外,需要有一个编译Java的环境,并且确保已经添加了Hadoop的相关依赖库。
5. hdfs 文件上传:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.net.URI;
public class HdfsUpload {
public static void main(String[] args) throws Exception {
// 检查并设置参数
if (args.length != 2) {
System.err.println("Usage: <source> <destination>");
System.exit(1);
}
String localFile = args[0];
String hdfsFile = args[1];
// 配置HDFS
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:8020"); // HDFS的URI
// 创建FileSystem实例
FileSystem fileSystem = FileSystem.get(conf);
// 上传文件
fileSystem.copyFromLocalFile(new Path(localFile), new Path(hdfsFile));
System.out.println("File uploaded successfully");
}
}
6. 获取 hdfs 文件大小:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FileStatus;
import java.net.URI;
public class HdfsFileSize {
public static void main(String[] args) throws Exception {
// HDFS路径
String hdfsPath = "hdfs://namenode:8020/path/to/your/file";
// 获取配置和文件系统实例
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(URI.create(hdfsPath), conf);
// 获取文件状态
FileStatus fileStatus = hdfs.getFileStatus(new Path(hdfsPath));
// 打印文件大小
long fileSize = fileStatus.getLen();
System.out.println("File size: " + fileSize + " bytes");
// 关闭文件系统
hdfs.close();
}
}
7. hdfs 遍历目录下的文件:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
public class HdfsTraversal {
public static void main(String[] args) throws IOException {
// HDFS路径
String hdfsPath = "hdfs://namenode:8020/your/hdfs/path";
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(URI.create(hdfsPath), conf);
// 调用递归遍历方法
traverseHdfs(hdfs, new Path(hdfsPath));
hdfs.close();
}
private static void traverseHdfs(FileSystem hdfs, Path path) throws IOException {
FileStatus[] files = hdfs.listStatus(path);
for (FileStatus file : files) {
if (file.isDirectory()) {
traverseHdfs(hdfs, file.getPath());
// 如果需要处理子目录,可以在这里添加代码
} else {
// 这里处理文件
System.out.println(file.getPath());
}
}
}
}


















 2689
2689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











