




最近,伴随着DeepSeek的火爆,「模型蒸馏」这个专业名词,也频繁出现在大众视野。
什么是模型蒸馏呢?
“模型蒸馏”就是把大模型学到的本领,用“浓缩”的方式教给小模型的过程,在保证一定精度的同时,大幅降低运算成本和硬件要求。
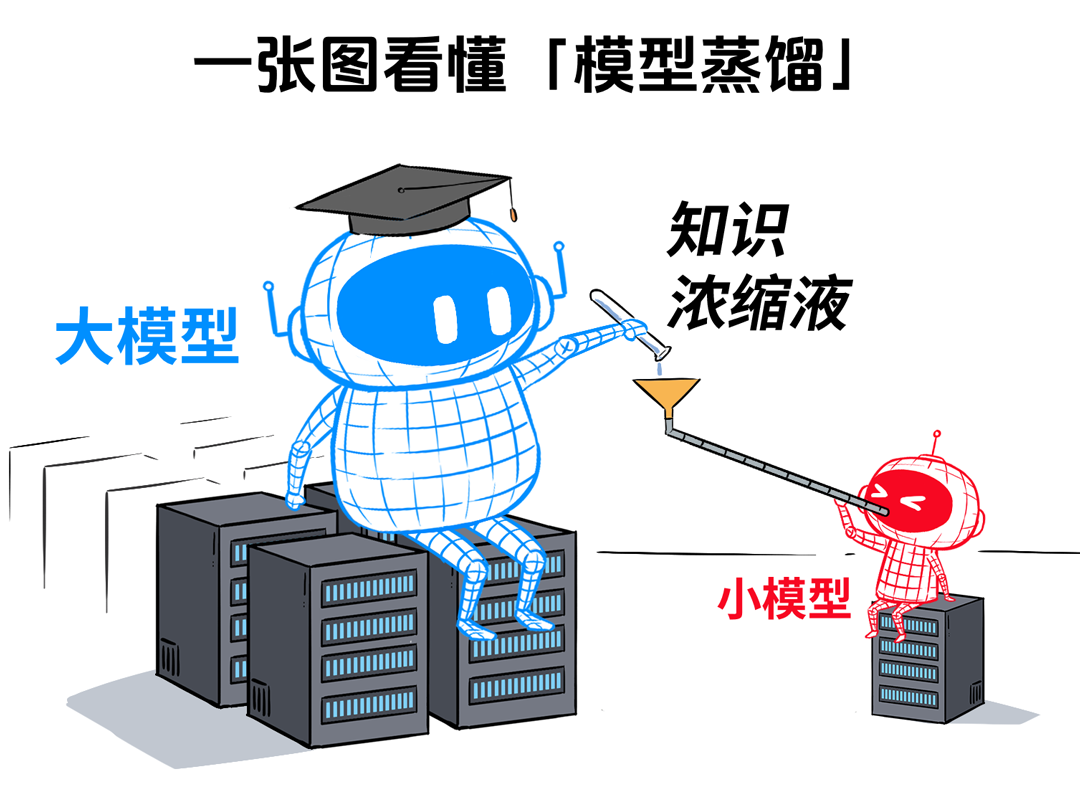
大模型:像一位见多识广、知识储备庞大的“大教授”,无所不知,但是“供养”他很贵。
不仅培养他的过程很耗时耗力(训练成本高),请他过来讲课成本也很高,要有很大一笔安家费(部署模型的硬件基础设施,甚至数据中心),还要支付超高的课时费(推理成本高)。

小模型:相当于一枚小学生,知识面非常有限,但是胜在没教授那么大谱,给个板凳坐着就够了(部署成本低,推理成本低)。

小模型想要拥有跟大模型完全一样的能力是不现实的,毕竟一分钱一分货。
但是我们可以让大模型教小模型一些基本的解题思路,让学生和老师一样思考问题。
教授会100种解题思路,挑两三种不错的教给小学生,让小学生照葫芦画瓢。
这个解题思路转移的过程,其实就是模型蒸馏。

以DeepSeek发布的六个蒸馏模型为例,满血版671B参数量的DeepSeek R1就是“教授模型”。
而教授模型针对不同尺寸的学生模型进行知识蒸馏,这些学生模型包括↓
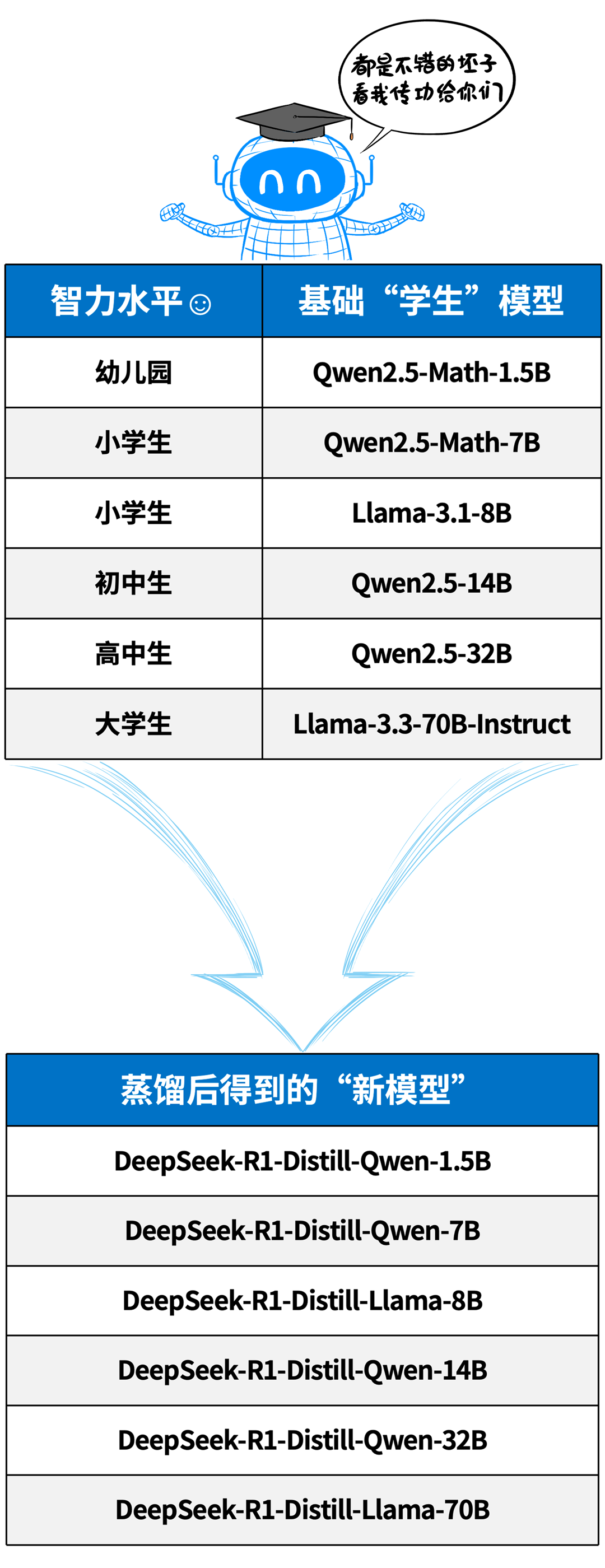
看,前几天让大家本地安装的那些模型,其实就是从DeepSeek R1这个老师蒸馏得到的,每个学生都从老师身上学到了些“三脚猫”功夫。
因为学生模型的初始资质不同,所以得到的蒸馏模型能力也不同。
总之,脑容量越大(权重数/参数量),能力就越强,就越接近老师的水平。

那么,模型蒸馏具体是怎么干的呢?
简单说,就是老师做一遍,学生跟着学。
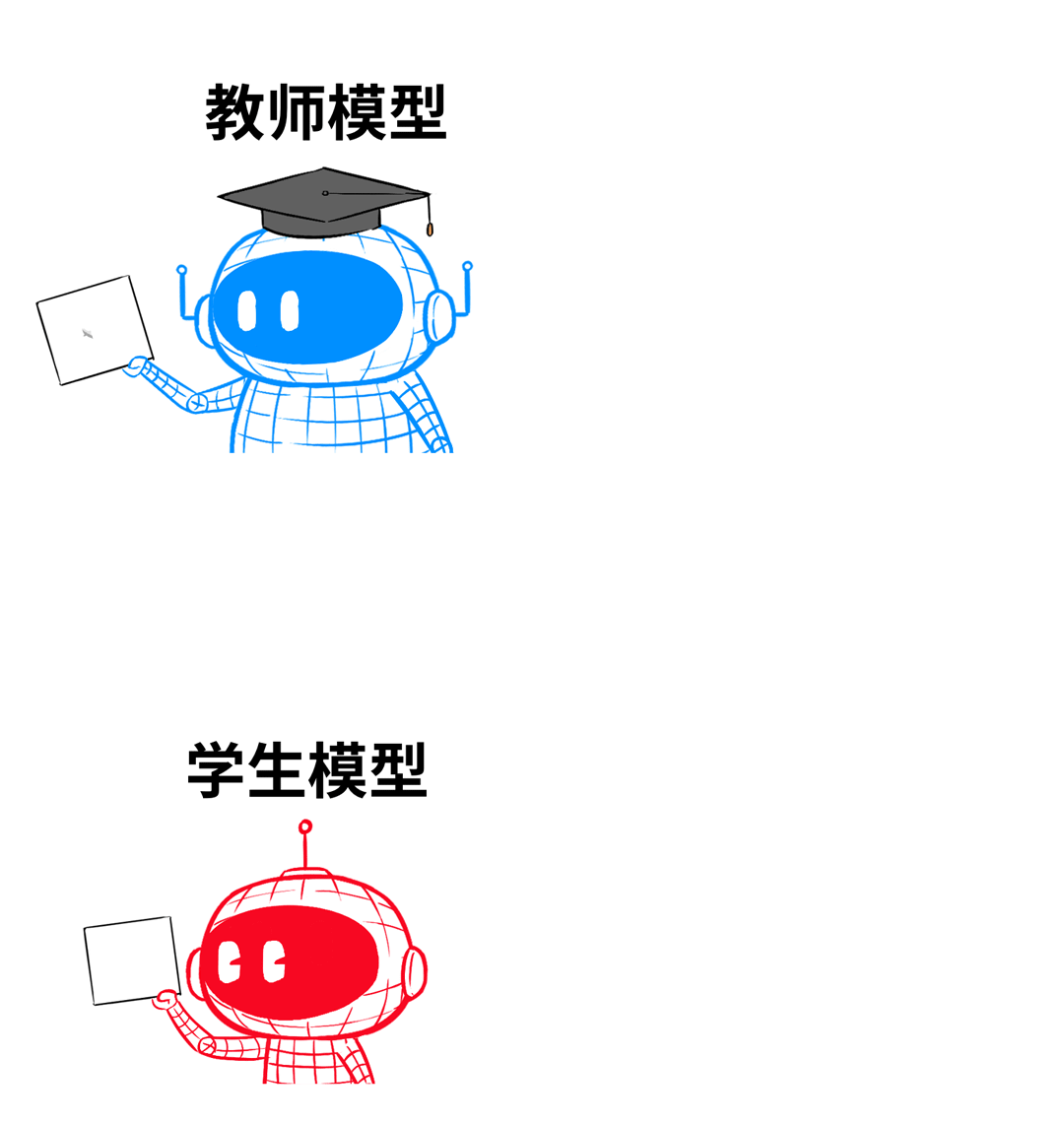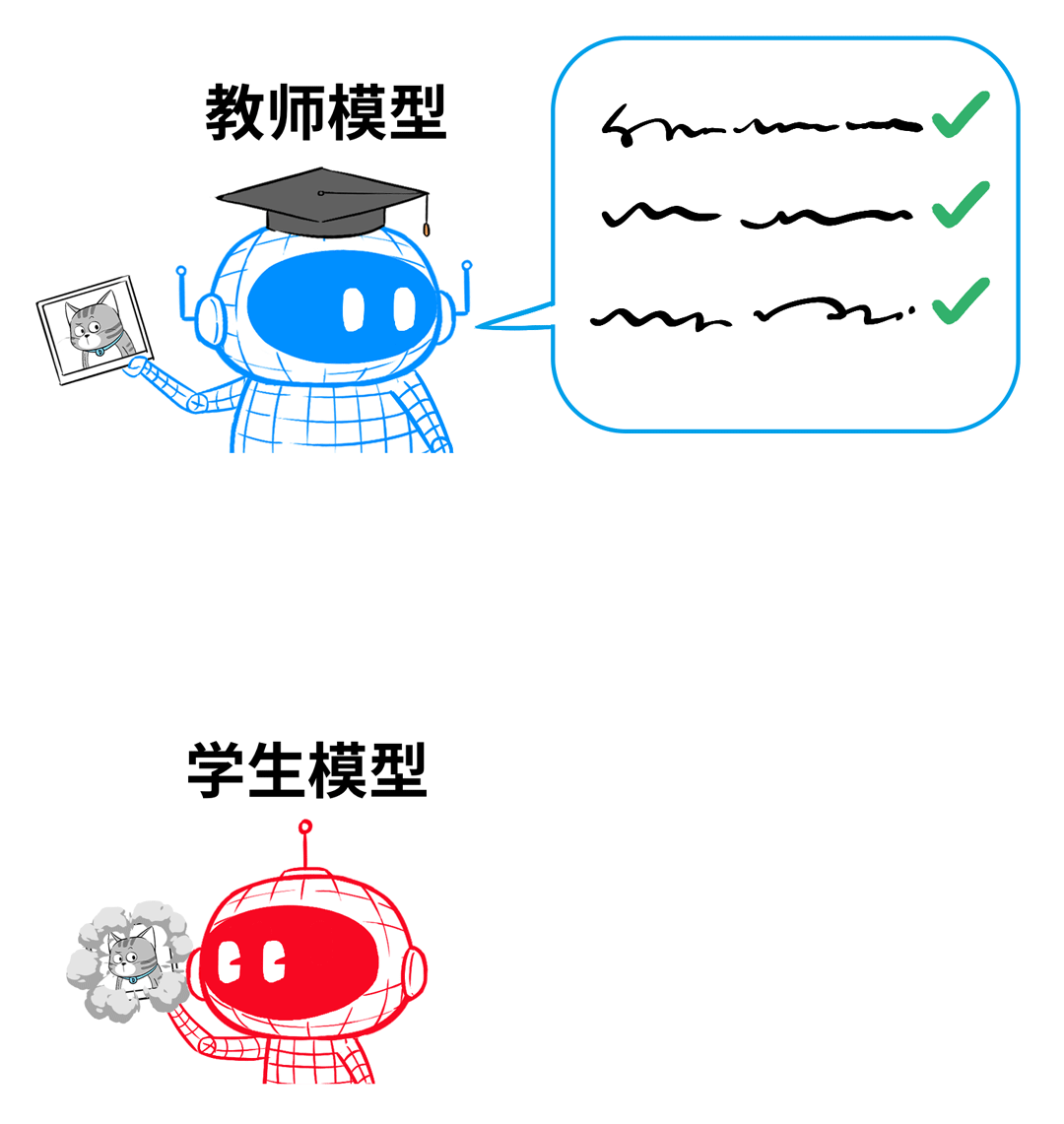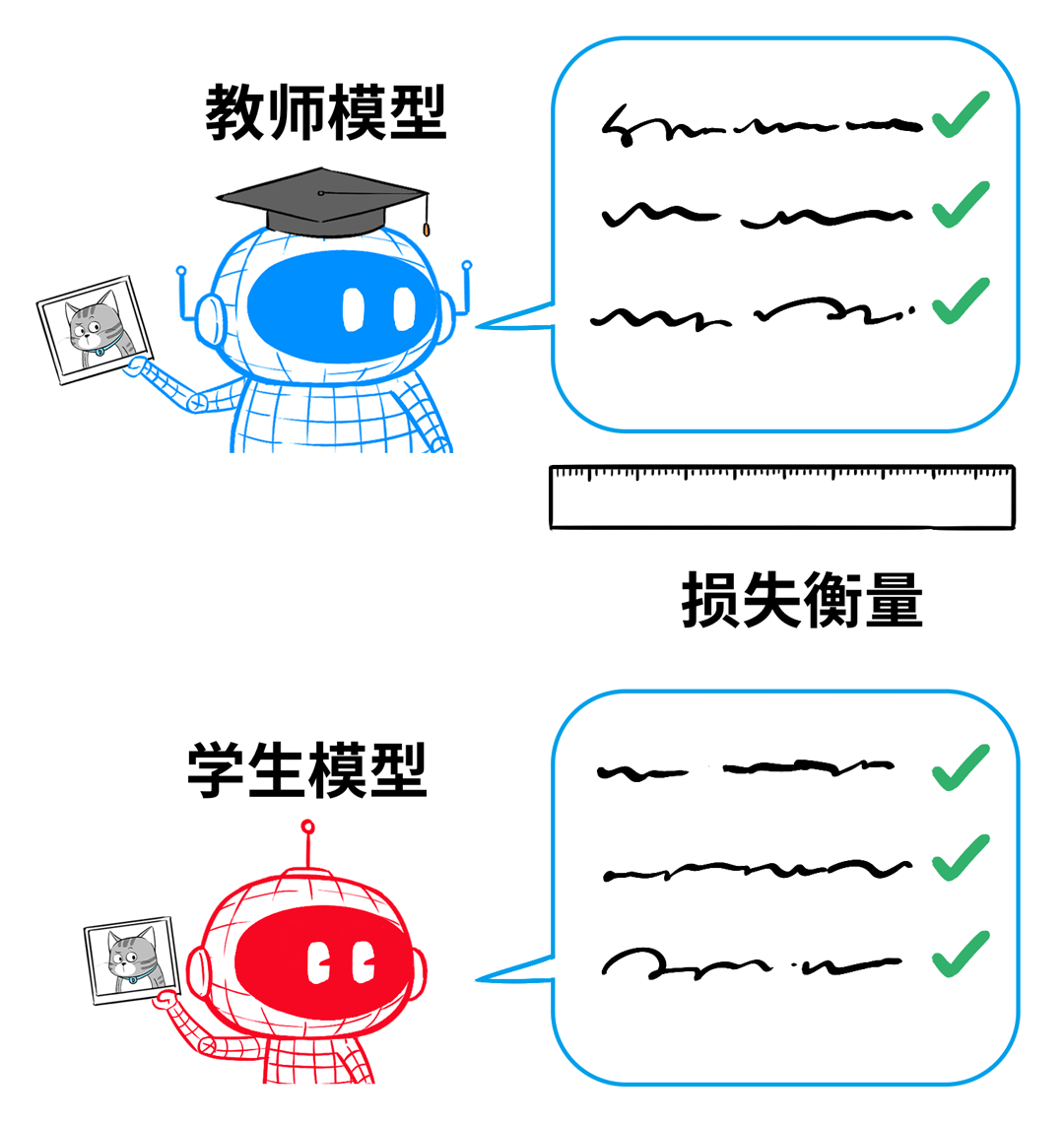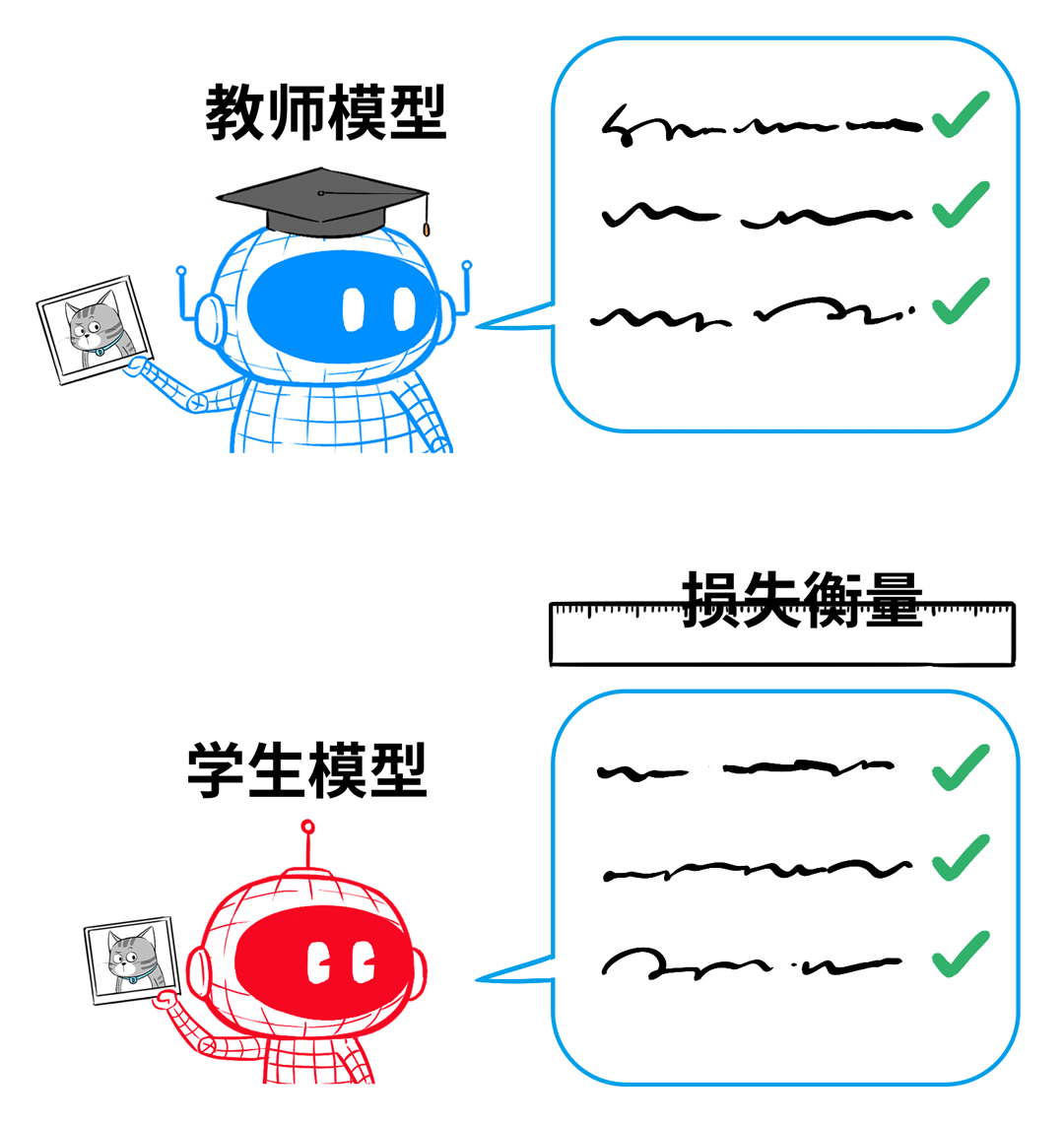
但针对每个输入的问题,老师不会直接给出确定答案,而是给出解题思路(俗称软标签)。
比如,输入一张猫的照片给老师模型,老师不会直接给出答案:这是猫,而是给出一组概率分布,告诉学生,这张图可能是什么。
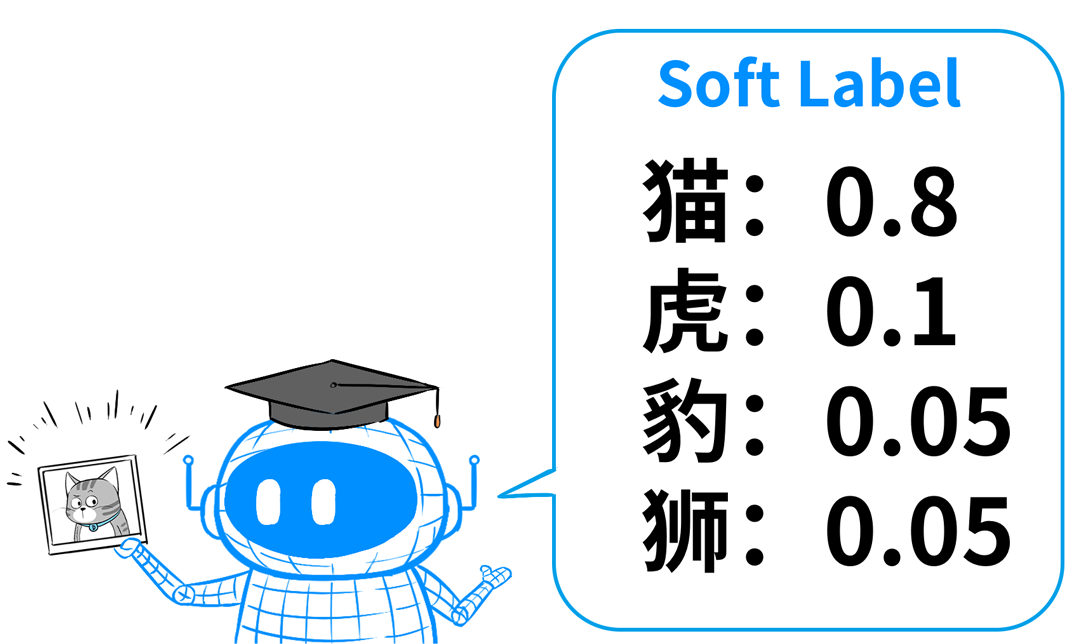
老师这么干,就是为了让学生具备举一反三、触类旁通的能力,用概率分布来对应各种类别的相似程度。
如果只告诉学生这是猫,学生就不知道它和老虎有多少差别。通过这种有概率分布的软标签,学生就知道了老师是如何判断、如何区分。

接下来,需要建立小模型的学习标准(综合损失函数)。
老师虽然NB,但小模型在学习的时候,并不会完全照搬老师的思路。
它会结合自己原有数据集中的硬标签(猫就是猫、狗就是狗),再参考老师的答案,最终给出自己的判断。
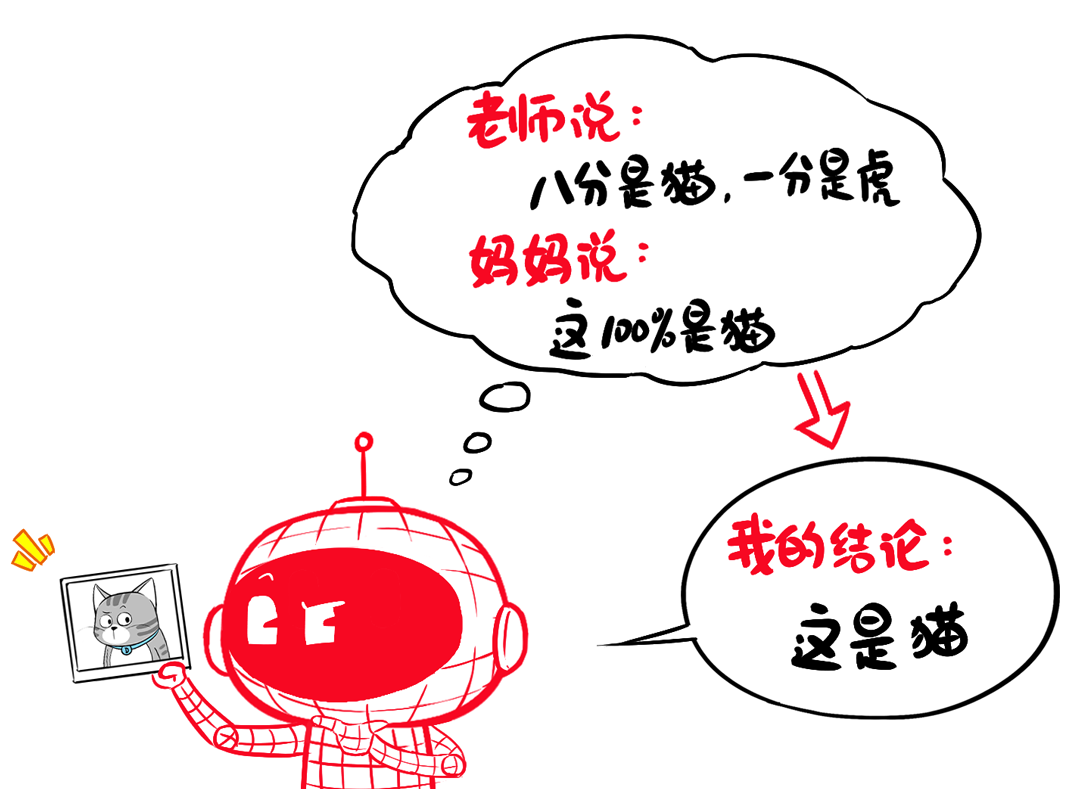
所以,学生模型既要参考“教授给的学习笔记”(软标签),又要结合“妈妈给的判断”(原有监督学习中的硬标签)。
实操中,用“蒸馏损失”来衡量学生模型与教授模型输出结果的差异。用“真实监督损失”来衡量学生模型对基本是非问题的判断。
然后,再设定一个平衡系数(α)来调节这两种损失,达到一个最优效果。
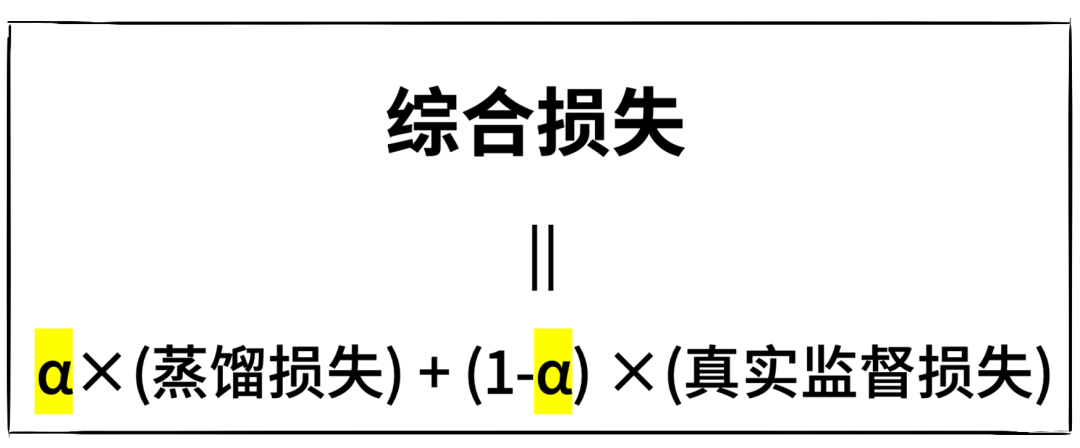
说白了,学生模型要尽量模仿教授模型的行为,蒸馏损失越小越好,但是又不能学傻了,基本的是非问题都答不对。

标准确定后,就可以进入正式的蒸馏训练了。
❶把同一批训练样本分别输入到学生模型和教授模型;
❷根据硬标签和软标签,对比结果,结合权重,得到学生模型最终的损失值;
❸对学生模型进行参数更新,以得到更小的损失值。
不断重复这个过程❶→❷→❸,就相当于反复刷题,每刷一轮,就找找学生答案和老师答案的差距,及时纠正。
经过多轮以后,学生的知识就会越来越扎实。
最终,蒸馏得到的小模型,尽量复制大模型的智慧,同时保持自己身轻如燕的优势。
这样,学生模型就可以作为课代表,独立带班,不需要教授坐镇了。

扩展阅读
一、关于不同的蒸馏路线
前面讲的这种模型蒸馏,只是最常见、最通用的一种方式,叫做知识蒸馏,也叫输出层蒸馏。
相当于老师直接告诉你最后的答案,学生只需要抄作业,模仿老师的答案就行。
这种方式操作起来最简单,即便教师模型不开源,你拿不到教师模型,只要能调用他的API,看到老师的知识输出,就可以模仿他,蒸馏出自己的小模型。
所以,有些模型比如GPT4,是明确声明不允许知识蒸馏的,但只要你能被调用,就没法避免别人偷师。
坊间传闻,业界大模型厂商之间,都存在互相蒸馏的操作,正所谓“互相模仿、共同进步”

。

除了输出层蒸馏,还有中间层蒸馏(也叫特征层蒸馏),不仅学到最终判断的结论,还学习老师对图像/文本的内部理解,更深入地继承老师的“知识结构”。
相当于学生不光看老师的最终答案,还要看老师的解题过程或中间步骤,从而更全面地学到思考方法。
但这种蒸馏方案,操作难度较高,通常需要教师模型允许,甚至主动配合,适用定制化的项目合作。
不过现在也可以通过一些手段来获取教师模型的推理轨迹(Reasoning Traces),比如使用特殊构造的提示词来诱导老师逐步返回推理,得到推理轨迹。
同时随着各种推理模型的推出,有些推理模型的API本身就支持返回推理轨迹,比如Google Gemini2.0 Flash,DeepSeek等等。
二、关于蒸馏、微调和RAG
这三种方法,都是优化的大模型的手段,但是实现路径和应用场景不同。
蒸馏:是学生通过模仿老师的解题思路,达到和老师相似的知识水平。
适用于将大模型的能力迁移到小模型上,以适配更低端的算力环境。(比如在企业私有云、个人电脑甚至手机、边缘终端上)

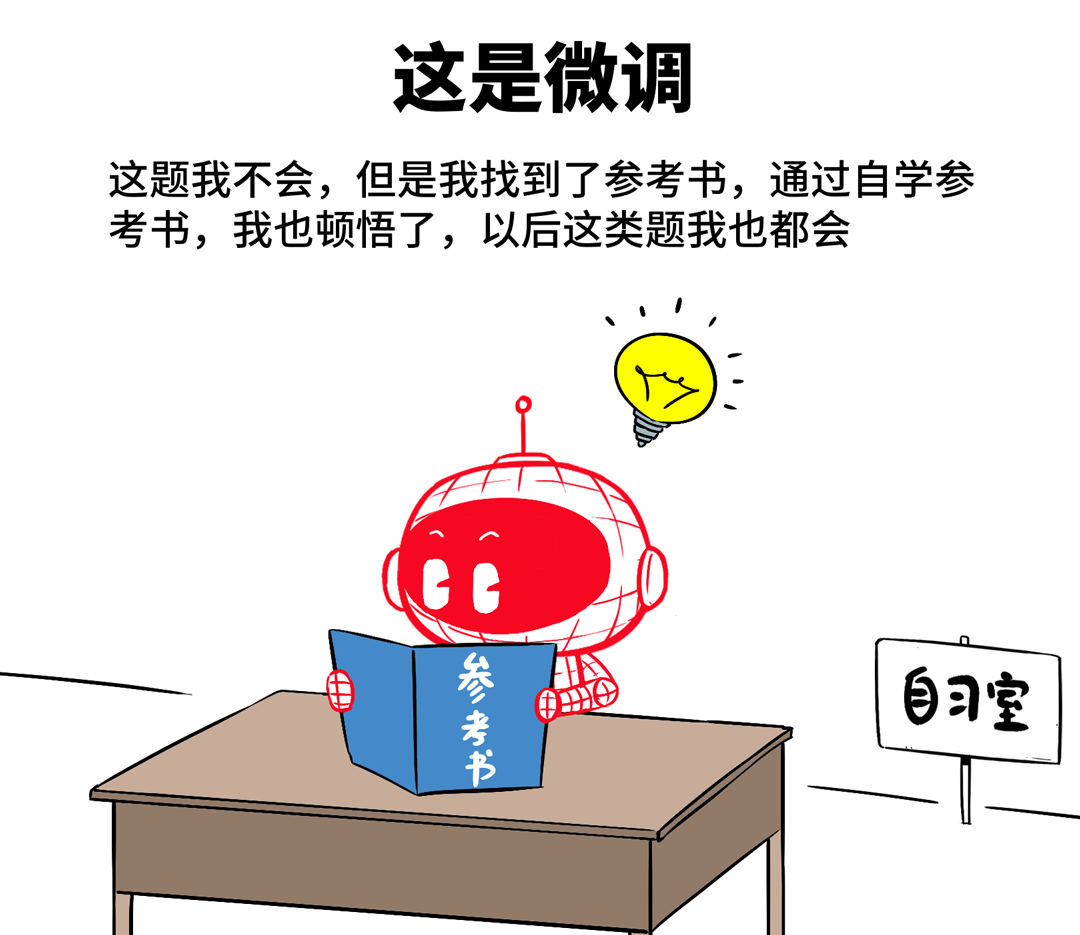
微调:又叫精调,相当于学生意识到自己某门课有短板,然后自己找参考书恶补了一下,从而补上短板。
适用于特定场景下,用特定数据集对通用模型进行小规模训练。比如通用基础模型对医疗不大懂,就用医疗数据集给它开小灶,让他变身医疗专家模型。
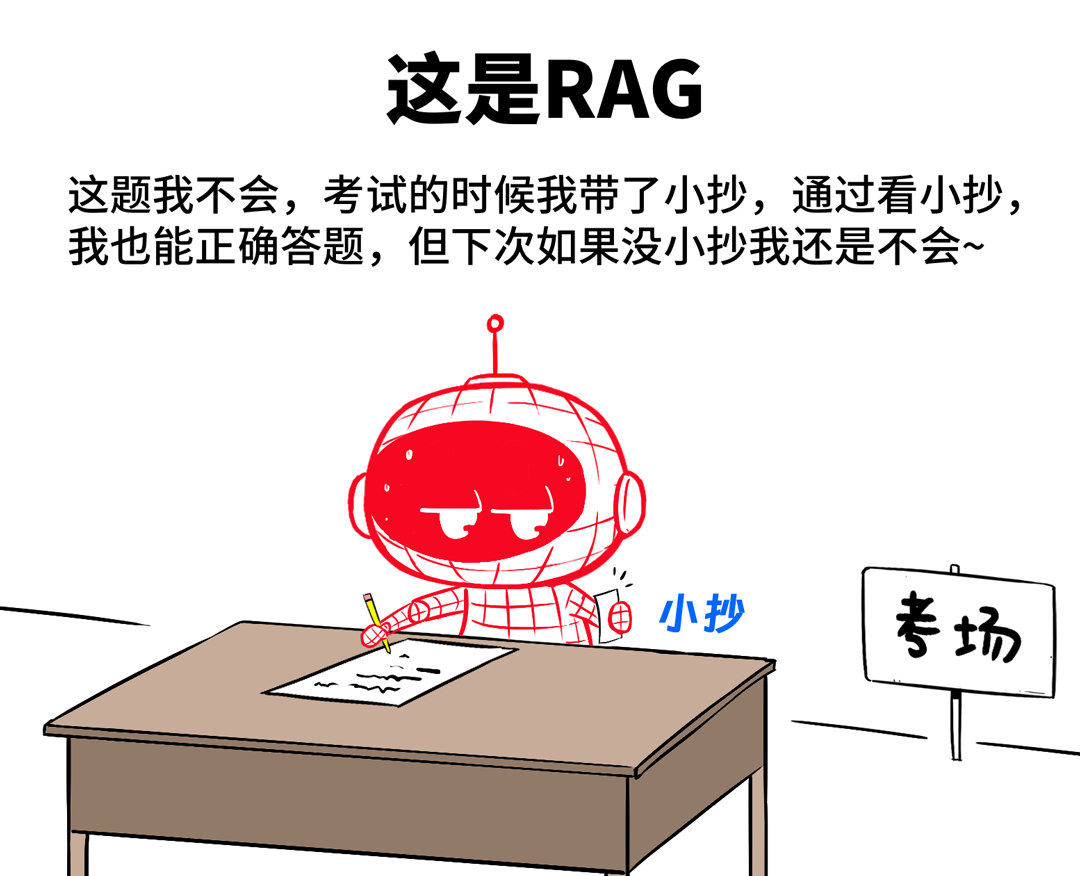
RAG:直译过来叫做“检索增强生成”。相当于这题我不会,但是我有“小抄”,我回答的时候,就看一眼小抄,然后再综合我脑子里的已有知识,进行回答。
RAG,不是训练,不改变大模型的“脑回路”,但可以作为外挂,提升大模型回答问题的精准性。适用于企业自身积累了大量知识库文档,通过RAG的方式,与大模型关联。
这样,大模型在回答问题的时候,会先检索知识库,进行精准回答。
三、举两个现实的例子
举个例子,现在特大号公众号后台的自动回复,其实就是腾讯混元大模型,通过RAG的方式,连接了特大号所有的历史文章,作为知识库使用。
当你提问的时候,它就会检索这些历史文章,然后再回答问题。
再举个例子,前几天被热传的李飞飞团队仅花费50美元,就训练出一个比肩ChatGPT o1和DeepSeek R1的模型,其实是一种误读。
李飞飞团队的s1模型,其实是基于通义的开源模型Qwen2.5-32B进行的微调,而微调所用的数据集,其中一部分蒸馏自Google Gemini 2.0 Flash Thinking。
所以,这个模型的诞生,是先通过知识蒸馏,从Gemini API获取推理轨迹和答案,辅助筛选出1000个高质量的数据样本。
然后,再用这个数据集,对通义Qwen2.5-32B进行微调,最终得到性能表现不错的s1模型。
这个微调过程,消耗了50美元的算力费用,但这背后,却是Gemini和Qwen两大模型无法估量的隐形成本。
这就好比,你“偷了”一位名师解题思路,给了一个学霸看,学霸本来就很NB,现在看完“思路”,变得更NB了。
严格来讲,Gemini 2.0作为闭源商业模型,虽然支持获得推理轨迹,但原则上是不允许用作蒸馏的,即便蒸馏出来也不能商用。不过如果仅是发发论文、做做学术研究、博博眼球,倒也无可厚非。
当然,不得不说,李的团队为我们打开了一种思路:我们可以站在巨人的肩膀上,用四两拨千斤的方法,去做一些创新。
比如,DeepSeek是MIT开源授权,代码和权重全开放,而且允许蒸馏(且支持获取推理轨迹)。
那么对于很多中小企业来讲,无异于巨大福利,大家可以轻松通过蒸馏和微调,获得自己的专属模型,还能商用。
GenAI的普惠革命时代,恐怕真的来了。

参考来源: 漫画趣解:一口气搞懂模型蒸馏!


















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









