









 本文介绍如何使用Hadoop MapReduce框架实现学生分数的最大值和总成绩统计。通过Mapper将输入文件中的数据按姓名和分数进行拆分,Reducer则负责计算每个学生的最高分和总分。
本文介绍如何使用Hadoop MapReduce框架实现学生分数的最大值和总成绩统计。通过Mapper将输入文件中的数据按姓名和分数进行拆分,Reducer则负责计算每个学生的最高分和总分。
文件内容:
Bob 684
Alex 265
Grace 543
Henry 341
Adair 345
Chad 664
Colin 464
Eden 154
Grover 630
Bob 340
Alex 367
Grace 567
Henry 367
Adair 664
Chad 543
Colin 574
Eden 663
Grover 614
Bob 312
Alex 513
Grace 641
Henry 467
Adair 613
Chad 697
Colin 271
Eden 463
Grover 452
Bob 548
Alex 285
Grace 554
Henry 596
Adair 681
Chad 584
Colin 699
Eden 708
Grover 345
最高成绩
代码实现:
1.Mapper
package com.lj.max4;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class MaxMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
context.write(new Text(split[0]), new LongWritable(Long.parseLong(split[1])));
}
}
2.Reduce
package com.lj.max4;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class MaxReduce extends Reducer<Text, LongWritable, Text, LongWritable> {
public void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long max = 0;
for (LongWritable val : values) {
if(max < val.get())
max = val.get();
}
context.write(key, new LongWritable(max));
}
}
3.Driver
package com.lj.max4;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MaxDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(com.lj.max4.MaxDriver.class);
// TODO: specify a mapper
job.setMapperClass(MaxMapper.class);
// TODO: specify a reducer
job.setReducerClass(MaxReduce.class);// TODO: specify output types
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);// TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(job, new Path("hdfs://lj02:9000/txt/score2.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://lj02:9000/4max"));if (!job.waitForCompletion(true))
return;
}}
结果:
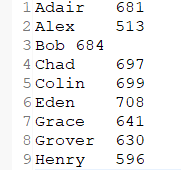
总成绩
代码实现:
1.Mapper
package com.lj.total5;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class TatalMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arr = value.toString().split(" ");
context.write(new Text(arr[0]), new LongWritable(Long.parseLong(arr[1])));
}
}
2.Reduce
package com.lj.total5;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class TotalReduce extends Reducer<Text, LongWritable, Text, LongWritable> {
public void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
// process values
long total = 0;
for (LongWritable val : values) {
total += val.get();
}
context.write(key, new LongWritable(total));
}
}
3.Driver
package com.lj.total5;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class TotalDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(com.lj.total5.TotalDriver.class);
// TODO: specify a mapper
job.setMapperClass(TatalMapper.class);
// TODO: specify a reducer
job.setReducerClass(TotalReduce.class);// TODO: specify output types
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);// TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(job, new Path("hdfs://lj02:9000/txt/score2.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://lj02:9000/5total"));if (!job.waitForCompletion(true))
return;
}}
结果: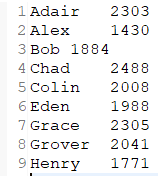


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









