







前置工作
课程文档:Llama3-Tutorial/docs/hello_world.md at main · SmartFlowAI/Llama3-Tutorial · GitHub
1.安装vscode
2.安装vscode插件
- Remote SSH
3.配置 VSCode 远程连接开发机
- ssh连接开发机

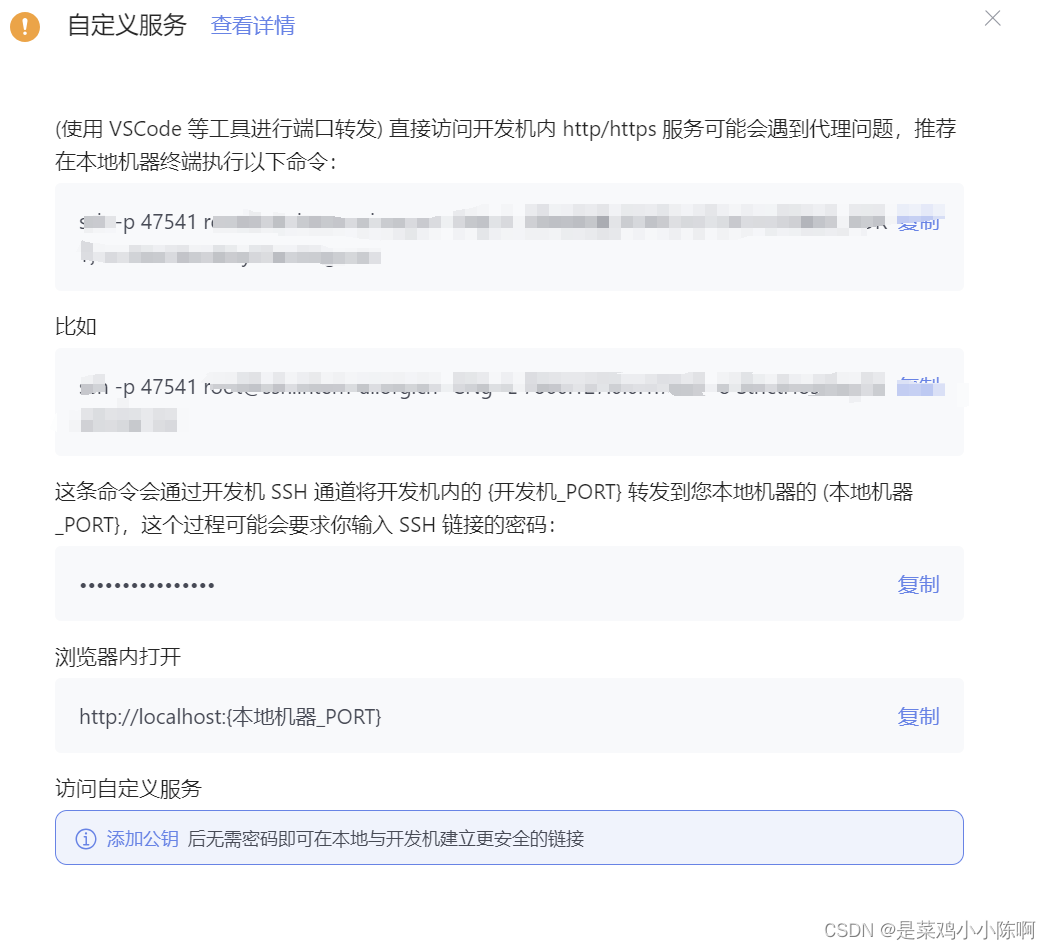
- 进行端口映射
在开发机控制台中点击自定义服务,复制命令粘贴到本机的 powershell 中
一.本地 Web Demo 部署
1.环境配置
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
2.模型下载
mkdir -p ~/model
cd ~/model
安装 git-lfs 依赖
# 如果下面命令报错则使用 apt install git git-lfs -y
conda install git-lfs
git-lfs install
InternStudio软连接
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
3.Web Demo 部署
下载 Llama3-Tutorial
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
安装 XTuner
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .
运行 web_demo.py
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .


















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









