







 本文介绍了SQL中的ROW_NUMBER() OVER函数,主要用于解决分组排序问题。文中通过四个查询示例,详细解释了如何使用该函数,包括无分组排序、分组查询、选择每组第一条数据以及按条件和排序筛选数据。
本文介绍了SQL中的ROW_NUMBER() OVER函数,主要用于解决分组排序问题。文中通过四个查询示例,详细解释了如何使用该函数,包括无分组排序、分组查询、选择每组第一条数据以及按条件和排序筛选数据。
文章来源 直接拷贝的人的文章,只是自己写一下增进记忆
语法格式:row_number() over(partition by 分组列 order by 分组列 desc)
描述:函数主要解决分组排序功能
🖤注意:在使用row_number() over () 函数的时候,over()里头的分组以及排序的执行晚于 where 、group by、order by 的执行
表数据:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
select * from TEST_ROW_NUMBER_OVER t;
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,1800);
执行结果:
第一次查询:查询所有,按照薪资排序(无分组)
SELECT t.*,row_number()over( ORDER BY salary desc) rn FROM test_row_number_over t 查询结果:
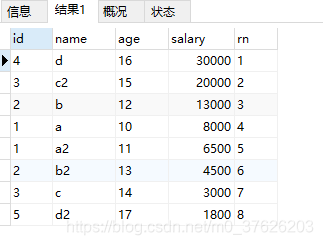
🖤: 此处的别名rn 与原文中的相同,但是在原文中后边的别名会用rank。rank是关键字。
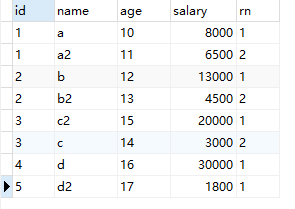
第二次查询:根据id,进行分组查询
SELECT t.*,row_number()over(PARTITION BY id ORDER BY salary desc) rn FROM test_row_number_over t 查询结果:
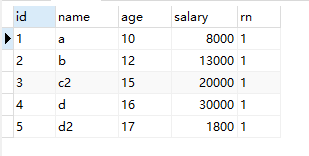
第三次查询:找出每一组中序号为一 的数据
SELECT * FROM (SELECT t.*,row_number()over(PARTITION BY id ORDER BY salary desc) rn FROM test_row_number_over t ) t1
WHERE t1.rn = 1查询结果:
第四次查询:找出年龄在13岁到16岁数据,按salary 排序:
SELECT id,name,age,salary,row_number()over(ORDER BY salary DESC) rn FROM test_row_number_over t WHERE t.age BETWEEN 13 and 16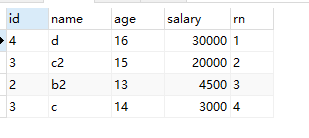
原文中,例二 没有表,没有数据就算了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









