







背景
上周一个业务排查处理死锁的时候的时候,先tail -n200 mysql-error.log,处理过
死锁的小伙伴都知道,show engine innodb status\G只能看到最近一次的死锁信息,
而对于历史的死锁信息需要开启innodb_print_all_deadlocks_output这个参数,
一旦数据库开启了这个参数,就会将所有的历史死锁信息输出到MySQL的error log。
而一条死锁如果锁定的行数或者记录很多的话,一条死锁记录可能就会几百行,
所以当时一直看不到想要的信息,就直接vim打开查看了一下,结果直接就卡住了,
(后来恢复了,看了一下当时的那个error log居然18GB)紧接着就收到报警信息,主库MySQL进程时间运行少于10min,然后就从库也报警IO
线程停掉了。
解决排查过程
1.遇到报警第一瞬间上去修复主从复制,还好该库不是一个核心业务而且是在业务低峰期,
qps非常低,所以主从自己重新连接上,恢复正常。
2.查看数据情况,数据
3接下来进入问题排查过程,查看监控,监控如下:
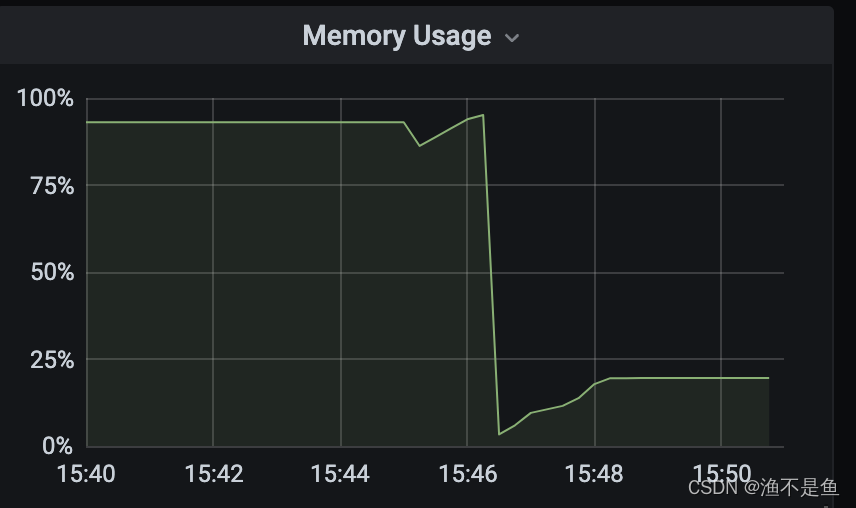
可以看到监控图内存使用率到一个点掉了下来,看起来是OOM导致的问题,
4.查看系统日志,查找元凶。

这里可以看到确实发生了OOM,但是可以看到是因为filebeat导致的,思考一下,肯定是因为
当时vim的时已经出发到边界了,但是filebeat刚好在临界值又去tail slow log刚好到达了OOM的触发条件,引发了OOM
继续往下看发现了问题:
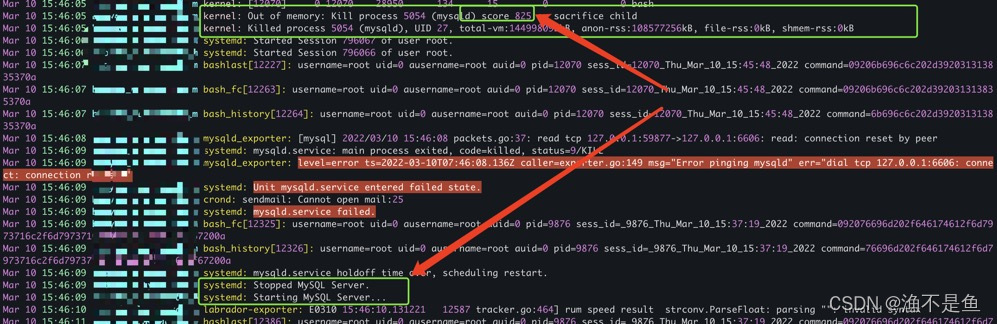
可以看到这里kernel选择杀死了分数最高的mysqld进程
PS: 这里说一下为什么,在OOM的时候,kernal杀掉了mysqld进程,在OOM的情况下,系统会有一个打分策略,会kill掉分数最高的进程、
#关于OOM
linux OOM是由系统参数vm.overcommit_memory控制的.
#查看方式:
$ sysctl -a| grep vm.overcommit
vm.overcommit_kbytes = 0
vm.overcommit_memory = 0
vm.overcommit_ratio = 50
#vm.overcommit_memory的取值
#简单总结
0--用之前先申请,申请不到足够空间抛出OOM(默认值)
1--不申请直接使用,过载使用内存,不触发OOM
2--不允许过载使用内存,不触发OOM
#kernel score如何计算的,主要是通过下面值计算出来的
oom_score
oom_score_adj
#就是下面这两个文件/proc/进程号/下
$ ls -l /proc/197543/oom_score*
-r--r--r-- 1 mysql mysql 0 9月 15 18:40 /proc/197543/oom_score
-rw-r--r-- 1 mysql mysql 0 9月 15 18:40 /proc/197543/oom_score_adj
感兴趣的可以继续深入研究
所以可以看到我们在OOM并不是内存使用率达到100%的时候才会抛出OOM异常,像我们监控的时候95%就OOM了
5万幸的是这次挂掉的是一个qps非常低的非核心业务库,由于重启速度也很快,在1s之内完成,所以业务几乎无任何影响
后续改进措施
既然问题发生了,解决了,那么作为一个合格的DBA,接下来就应该去考虑如何去做优化,以及避免这种问题发生:
针对这次的问题,整理了以下的措施:
优化告警策略,明明平常内存使用已经很高了,但是没有报警提示vim的时候注意,vim的时候一定要注意文件大小定时归档日志文件,定时分割拆分清理错误日志,慢查询日志合理分配数据库使用buffer,如果这台机器还有其他业务,比如canal,filebeat考虑调小buffer pool size大小重要进程保证不会被oom-killer kill掉,实现方式,可以把对应进程的oom_score_adj文件内容调成一个比较小的负数,注意会有范围的,在范围之内调小,然后使其在OOM的时候拿到一个比较低的分数,避免被kill掉。



















 1567
1567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











