









《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》是李飞飞团队在2016年发表于ECCV的文章。我近几年的工作中,所训练的模型都离不开感知损失。不得不感慨,大佬之所以是大佬,就是因为他们开创性的工作很多年后依然为人津津乐道。
本文将言简意赅的重温下感知损失的原理和作用。
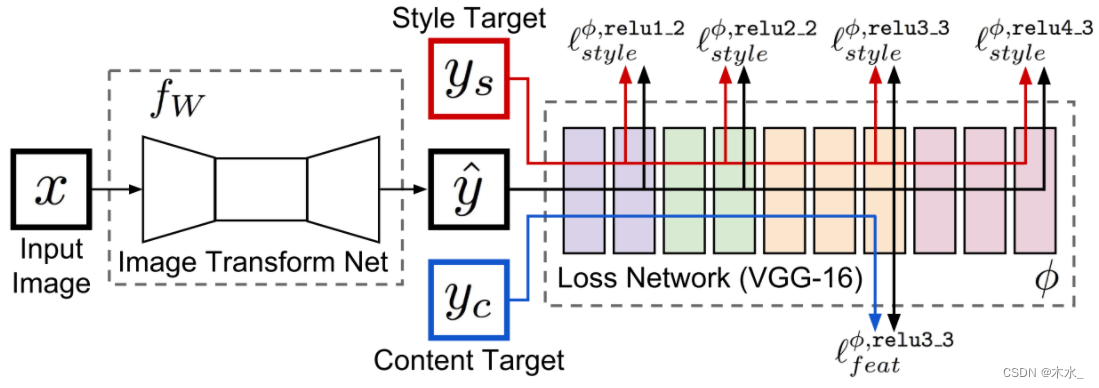
1. 网络层越深提取的特征越抽象越高级。较浅层通常提取边缘、颜色、亮度等低频信息,再深一些提取一些细节纹理等高频信息,更深一点的网络层则提取一些具有辨别性的抽象关键特征。
2. 让 Ground Truth 和 Prediciton 经过一个预训练的 VGG 网络,通过计算 VGG 网络中间层输出特征的 Loss,来让 Prediciton 逼近 Ground Truth 的视觉感官。
3. 上图中的 Content target 用作计算 Feature Reconstruction Loss,偏向实质性内容,比方纹理、边缘、色彩、亮度等等;Style target 用作 Style Reconstruction Loss,偏向抽象性内容,是图像表达的一种风格。
4. Feature Reconstruction Loss 计算的时候,采用 L1 这种常见损失直接计算;Style Reconstruction Loss 计算的时候,VGG 中间输出特征先经过 Gram matrix(格拉姆矩阵:n维欧式空间中任意k个向量之间两两的内积所组成的矩阵)计算获得内积矩阵,再对该矩阵计算 L1。
实验结果1:Feature Reconstruction 随着 VGG 的特征加深而产生的变化。

实验结果2:Style Reconstruction 随着 VGG 的特征加深而产生的变化。
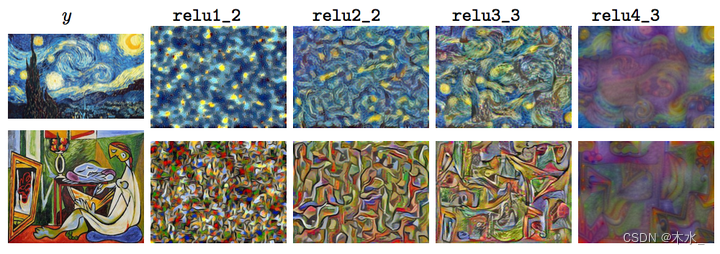
小结,如果是需要做一些很精细化的超分,比方人脸,追求真实自然性,那么用 Feature Reconstruction Loss 就够了,用了 Style Reconstruction Loss 容易出现一些偏色、不自然条纹等问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









