







🧩 什么是Token?文字版的乐高积木
想象你在玩文字乐高:
- Token = 文字积木块(可以是完整的词、字,甚至是半个字)
- 中文例子:“机器学习” → 可能拆成 [“机器”, “学习”] 或 [“机”, “器”, “学”, “习”]
- 英文例子:“unbelievable” → 拆成 [“un”, “believ”, “able”]
📏 模型对话长度揭秘
当看到"GPT-3.5-16K"时:
🌍 不同模型的"积木套装"
中文 vs 英文模型对比
| 模型类型 | Token数量 | 特点说明 |
|---|---|---|
| 纯英文模型 | 300-500 | 只有字母+标点,像儿童积木 |
| 中英混合模型 | 3万+ | 包含汉字/单词/符号,像豪华套装 |
| GPT系列 | 30亿+ | 宇宙级积木库,什么组合都能拼 |
💡 中文更复杂:一个"安徽省"可能占3个Token,而英文"California"只占1个
📖 模型的"拼装说明书"——词表
"vocab": {
# 开头是一些特殊符号
"<unk>": 0,
"<|startoftext|>": 1,
"<|endoftext|>": 2,
"<|Human|>": 3,
"<|Assistant|>": 4,
...
# 这是字节token,如果出现不在词表中的特殊符号会回退到字节表示
"<0x00>": 305,
"<0x01>": 306,
"<0x02>": 307,
"<0x03>": 308,
"<0x04>": 309,
...
# 下面是正常的英文token,有_的表示是单词的开头,没有的是单词中间
"ct": 611,
"▁re": 612,
"ve": 613,
"am": 614,
"▁e": 615,
...
# 有中文token出现
"安徽省": 28560,
"▁aliens": 28561,
"▁imagery": 28562,
"▁squeeze": 28563,
"子和": 28564,
...
}
- “▁re”: 612 # 单词开头
- “ve”: 613 # 单词中间
🔍 词表冷知识
- <0x00> 这类表示特殊符号(就像乐高里的异形件)
- ▁ 符号代表空格(区分单词开头)
🔮 AI预测的魔法原理
- 初级版:查字典猜词

- 局限性:遇到新词如"唱跳Rap"就会懵逼 😵
- 进阶版:文字变数学坐标
- 把每个Token变成数字向量(就像GPS坐标)
- 计算坐标之间的"距离亲密值"
- 选最亲密的下一个Token
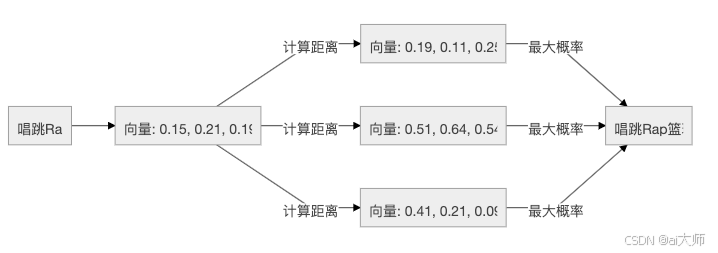
❓ 常见问题解答
- Q:为什么不同模型Token不一样?
- 就像不同品牌的乐高:
- 基础版:500块标准积木
- 豪华版:3000块+特殊形状
- Q:Token越多越好吗?
- 能理解更复杂的表达
- 需要更强的计算能力
- 处理速度可能变慢
🎯 重点总结
- Token是AI理解文字的基本单元
- 词表就像模型的"文字字典"
- 预测机制从查表升级到数学计算
- 中文处理比英文更复杂
💡 小测试:试着把这句话拆成Token → “深度学习真有趣!”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











