







昇腾 AI 处理器
本文将会介绍华为昇腾 AI 处理器的架构与卷积加速原理。昇腾 AI 处理器是华为基于达芬奇架构专为AI计算加速而设计的处理器,它支持云边端一体化的全栈全场景解决方案,具有高能效比和强大的 3D Cube 矩阵计算单元,支持多种计算模式和混合精度计算。
昇腾 AI 处理器的架构包括了 AI Core、AI CPU、多层级片上缓存/缓冲区和数字视觉预处理模块 DVPP,这些组件通过 CHI 协议的环形总线实现数据共享和一致性而组成的 SoC。此外,本节还将探讨卷积加速原理,即昇腾 AI 处理器如何通过软硬件优化实现高效的卷积计算加速,包括矩阵计算单元和数据缓冲区的高效组合以及灵活的数据通路设计,以满足不同神经网络的计算要求。
昇腾 AI 处理器
华为公司针对 AI 领域专用计算量身打造了“达芬奇架构”,并于 2018 年推出了基于“达芬奇架构”的昇腾 AI 处理器,开启了华为的AI之旅。
从基础研究出发,立足于自然语言处理、机器视觉、自动驾驶等领域,昇腾 AI 处理器致力于打造面向云边端一体化的全栈全场景解决方案,同时为了配合其应用目标,打造了异构计算架构 CANN(Computer Architecture for Nerual Network),为昇腾 AI 处理器进行加速计算。全栈指技术方面,包括 IP、芯片、加速计算、AI 框架、应用使能等的全栈式设计方案。全场景包括公有云、私有云、各种边缘计算、物联网行业终端及消费者终端设备。围绕全栈全场景,华为正以昇腾 AI 处理器为核心,以算力为驱动,以工具为抓手,全力突破 AI 发展的极限。
自 2018 年伊始,如图所示昇腾 AI 处理器的训练和推理系列型号陆续推出。推理系列的处理器则是面向移动计算场景的强算力 AI 片上系统(SoC,System on Chip)。训练系列的处理器主要应用于云端,可以为深度学习的训练算法提供强大算力。

在设计上,昇腾 AI 处理器意图突破目前 AI 芯片功耗、运算性能和效率的约束,目的是极大提升能效比。昇腾 AI 处理器采用了华为自研的达芬奇架构,专门针对神经网络运算特征而量身定做,以高性能的 3D Cube 矩阵计算单元为基础,实现针对张量计算的算力和能效比大幅度提升。每个矩阵计算单元可以由一条指令完成 4096 次乘加计算(如图所示),并且处理器内部还支持多维计算模式,如标量、矢量、矩阵等,打破了其它 AI 专用芯片的局现象,增加了计算的灵活度。同时支持多种类混合精度计算,在实现推理应用的同时也强力支持了训练的数据精度要求。

达芬奇架构的统一性体现在多个应用场景的良好适配上,覆盖高、中、低全场景,一次开发可支持多场景部署、迁移和协同。从架构上提升了软件效率。功耗优势也是该架构的一个显著特点,统一的架构可以支持从几十毫瓦到几百瓦的芯片,可以进行多核灵活扩展,在不同应用场景下发挥出芯片的能耗优势。
达芬奇架构指令集采用了 CISC 指令且具有高度灵活性,可以应对日新月异、变化多端的新算法和新模型。高效的运算密集型 CISC 指令含有特殊专用指令,专门为神经网络打造,助力 AI 领域新模型的研发,同时帮助开发者更快速的实现新业务的部署,实现在线升级,促进行业发展。昇腾 AI 处理器在全业务流程加速方面,采用场景化视角,系统性设计,内置多种硬件加速器。昇腾 AI 处理器拥有丰富的 IO 接口,支持灵活可扩展和多种形态下的加速卡设计组合,很好应对云端、终端的算力和能效挑战,可以为各场景的应用强劲赋能。
AI 处理器架构
昇腾 AI 处理器本质上是一个片上系统(System on Chip,SoC),主要可以应用在和图像、视频、语音、文字处理相关的应用场景。上图是早期昇腾其处理器的逻辑架构,其主要的架构组成部件包括特制的计算单元、大容量的存储单元和相应的控制单元。无论是训练还是推理的芯片以及上层的硬件型号,基于基于 DaVinci AI 技术架构如图所示。
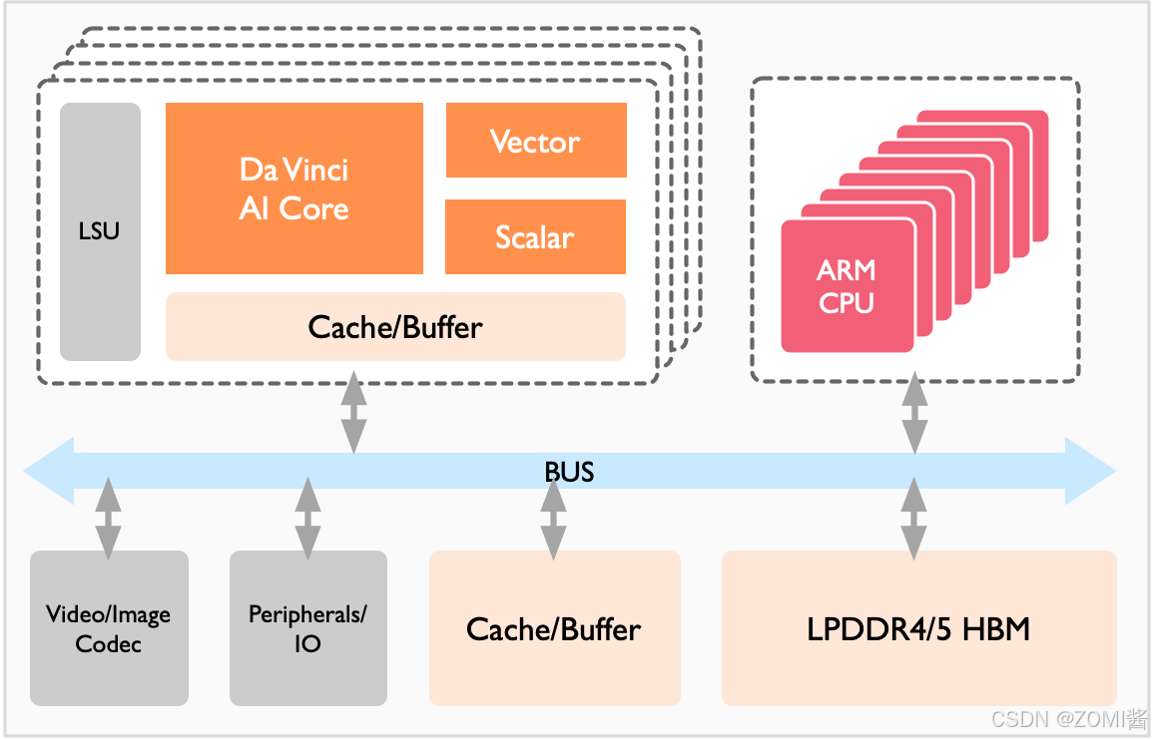
该处理器大致可以划为:芯片系统控制 CPU(Control CPU),AI 计算引擎(包括 AI Core 和 AI CPU),多层级的片上系统缓存(Cache)或缓冲区(Buffer),数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等。芯片可以采用 LPDDR4 高速主存控制器接口,价格较低。目前主流 SoC 芯片的主存一般由 DDR(Double Data Rate)或 HBM(High Bandwidth Memory)构成,用来存放大量的数据。HBM 相对于 DDR 存储带宽较高,是行业的发展方向。其它通用的外设接口模块包括 USB、磁盘、网卡、GPIO、I2C 和电源管理接口等。
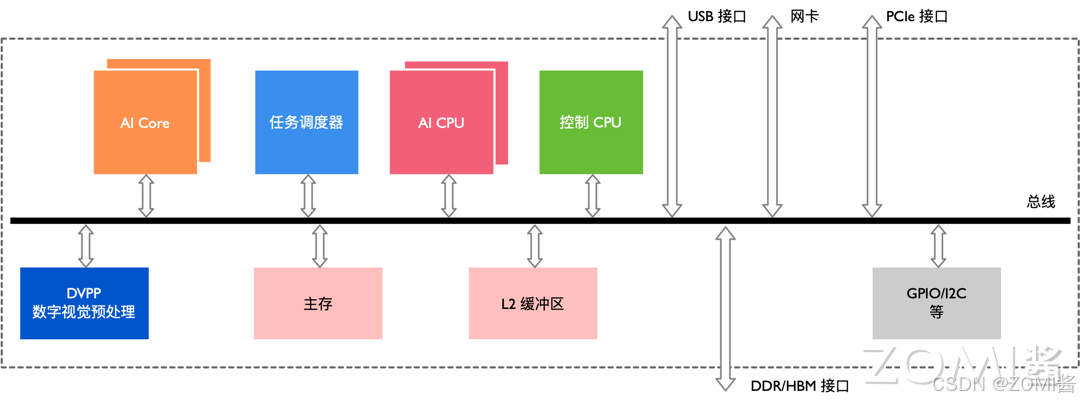
当该处理器作为计算服务器的加速卡使用时,会通过 PCIe 总线接口和服务器其它单元实现数据互换。以上所有这些模块通过基于 CHI 协议的片上环形总线相连,实现模块间的数据连接通路并保证数据的共享和一致性。
昇腾 AI 处理器集成了多个 ARM 架构的 CPU 核心,每个核心都有独立的 L1 和 L2 缓存,所有核心共享一个片上 L3 缓存。集成的 CPU 核心按照功能可以划分为专用于控制芯片整体运行的主控 CPU 和专用于承担非矩阵类复杂计算的 AI CPU。两类任务占用的 CPU 核数可由软件根据系统实际运行情况动态分配。
除了 CPU 之外,该处理器真正的算力担当是采用了达芬奇架构的 AI Core。AI Core 通过特别设计的架构和电路实现了高通量、大算力和低功耗,特别适合处理深度学习中神经网络必须的常用计算如矩阵相乘等。目前该处理器能对整数或浮点数提供强大的乘加计算力。由于采用了模块
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









