



 联邦学习是一种在保证数据隐私安全和合法合规的前提下,通过分布式机器学习技术实现共同建模,提升AI模型效果的方法。它主要分为横向、纵向和联邦迁移学习三种类型,分别针对不同数据分布的场景,旨在解决数据量不足、数据质量差以及隐私保护等问题。
联邦学习是一种在保证数据隐私安全和合法合规的前提下,通过分布式机器学习技术实现共同建模,提升AI模型效果的方法。它主要分为横向、纵向和联邦迁移学习三种类型,分别针对不同数据分布的场景,旨在解决数据量不足、数据质量差以及隐私保护等问题。
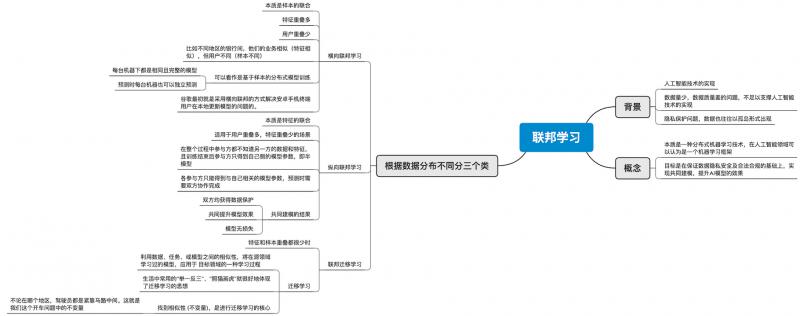
联邦学习
背景
人工智能技术的实现
数据量少,数据质量差的问题,不足以支撑人工智能技术的实现
隐私保护问题,数据也往往以孤岛形式出现
概念
本质是一种分布式机器学习技术,在人工智能领域可以认为是一个机器学习框架
目标是在保证数据隐私安全及合法合规的基础上,实现共同建模,提升AI模型的效果
根据数据分布不同分三个类
横向联邦学习
本质是样本的联合
特征重叠多
用户重叠少
比如不同地区的银行间,他们的业务相似(特征相似),但用户不同(样本不同)
可以看作是基于样本的分布式模型训练
- 每台机器下都是相同且完整的模型
- 预测时每台机器也可以独立预测
谷歌最初就是采用横向联邦的方式解决安卓手机终端用户在本地更新模型的问题的。
纵向联邦学习
本质是特征的联合
适用于用户重叠多,特征重叠少的场景
在整个过程中参与方都不知道另一方的数据和特征,且训练结束后参与方只得到自己侧的模型参数,即半模型
各参与方只能得到与自己相关的模型参数,预测时需要双方协作完成
共同建模的结果
- 双方均获得数据保护
- 共同提升模型效果
- 模型无损失
联邦迁移学习
特征和样本重叠都很少时
迁移学习
利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于 目标领域的一种学习过程
生活中常用的“举一反三”、“照猫画虎”就很好地体现了迁移学习的思想
找到相似性 (不变量),是进行迁移学习的核心
- 不论在哪个地区,驾驶员都是紧靠马路中间。这就是我们这个开车问题中的不变量
- 不论在哪个地区,驾驶员都是紧靠马路中间。这就是我们这个开车问题中的不变量

















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









