






 本文介绍了数据库中的SQL查询技巧,包括单表查询、条件筛选、模糊查询、逻辑运算、范围查询、排序及聚合函数的使用。通过示例详细讲解了like、where、and/or、between、order by、group by以及having子句的用法,帮助理解如何在数据库中高效查询和操作数据。
本文介绍了数据库中的SQL查询技巧,包括单表查询、条件筛选、模糊查询、逻辑运算、范围查询、排序及聚合函数的使用。通过示例详细讲解了like、where、and/or、between、order by、group by以及having子句的用法,帮助理解如何在数据库中高效查询和操作数据。
1.单表查询
我们先来看这样一段数据库中的SQL语句:
create table student(
id char(36) primary key,
name varchar(8) not null,
age int(3) default 0,
mobile char(11),
address varchar(150)
)
insert into student
values ('9b4435ec-372c-456a-b287-e3c5aa23dff4','张三',24,'12345678901','北京海淀');
insert into student
values ('a273ea66-0a42-48d2-a17b-388a2feea244','李%四',10,'98765432130',null);
insert into student
values ('eb0a220a-60ae-47b6-9e6d-a901da9fe355','张李三',11,'18338945560','安徽六安');
insert into student
values ('6ab71673-9502-44ba-8db0-7f625f17a67d','王_五',28,'98765432130','北京朝阳区');
insert into student
values ('0055d61c-eb51-4696-b2da-506e81c3f566','王_五%%',11,'13856901237','吉林省长春市宽平区');
此时我们执行SQL语句就创建好了表,并且表中也已经存入了相应的数据;

下面我们来看一些几种查询方法:
- where:指定查询过滤条件; like:进行数据模糊查询,
1.%:匹配0次或多次
select * from student where name like '张%’;#查询姓张的学生信息
select * from student where name like '%李%’;#查询姓名中含有“李”字的学生信息

2._:只匹配1次
select * from student where name like '张_’;#查询两个字的张姓学生信息

此时的意思是只匹配名字的第一个字是王,且该名字有两个字,只查询出符合这样名字条件的信息,例如,当我们“将王_五”更改为“王刚”时,这时就有:

3.escape:取消%或_字符的通配符特性
#查询姓名中含有%字符的学生信息 select * from student where name like '%#%%' escape ‘#’
#查询姓名中含有%字符的学生信息 select * from student where name like '%$_%' escape ‘$’
#查询姓名以%%结尾的学生信息 select * from student where name like '%_%_%' escape '_’;

上述SQL语句执行时即为查询名字中还有% 的学生信息
- 逻辑条件:and、or
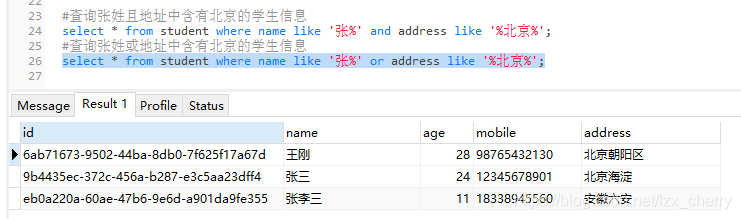
- between 下限 and 上限:等同于"(column_name>=下限) and (column_name<=上限)"
需要注意的是这里的between and 是一个闭区间,含两端,且一定是小数据在前,大数据在后
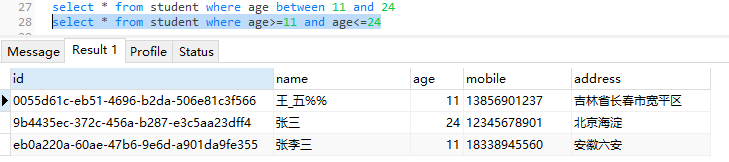
此时这两个语句的执行效果是一样的
- 关系条件:=、!=、<、=<、>、>=等
select * from student where age<28;--查询年龄小于28岁的学生信息

- in(value1,value2,value3......valuen):等同于“ column_name = value1 or column_name = value2 or column_name = value3...... or column_name = valuen ”
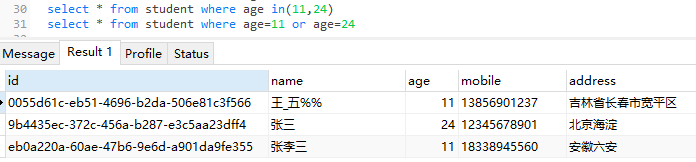
- null :包括is null 和 is not null

需要注意的是:is null不能写成 = null,同样,is not null不能写成!=null
- order by:对查询结果进行排序,必须置于SQL语句的最后,语法:order by {column_name1, column_name2, column_name3, ......column_namen} [asc|desc]
select * from student order by age asc 此时的asc可以省略不写,默认为按照升序排列
select * from student order by age desc 将年龄按照降序排列
#排序之后可以跟多个字段名,即为多重排序,用,间隔 此时是如何排序的 先按照age升序排列,当age相等时,再按照mobile排序
select * from student order by age,mobile 也可年龄按照升序,电话按照降序,如下所示
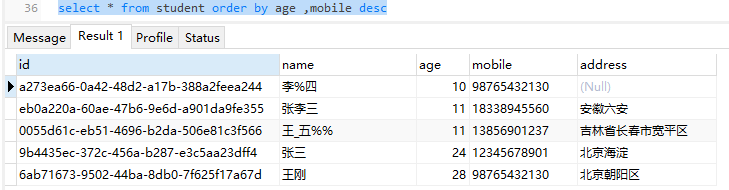
在order by 子句中,不仅可以使用字段,还可以使用字段别名进行排序,例如:
#按照age升序排列 select id,name,age as stu_age,mobile,address from student order by stu_age;
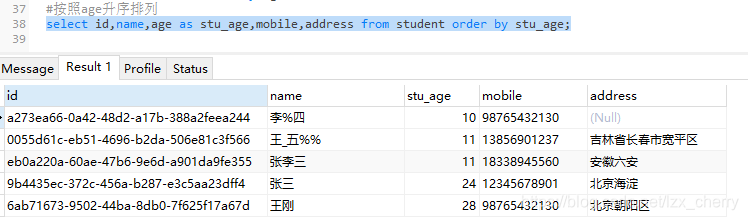
- 聚合函数 用于统计"多条"数据的函数
#count
select count(id) from student
#sum
select sum(age) from student
#avg
select sum(age)/count(id) as age from student
select avg(age) age from student
#max min
select max(age),min(age)from student
- group by 分组函数,一般与聚合函数一起使用
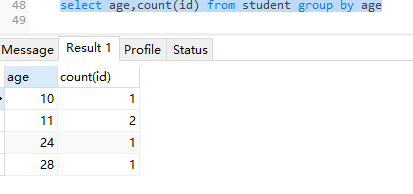
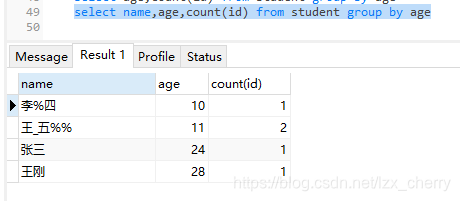
因为count(id)为2的那一栏只显示了一个名字,但是该有对应的两个名字,所以这时候没有显示出来完。所以在这里我们需要注意的一点是:如果使用group by 则select字段列表只能是聚合函数或者分组字段
- having 如何查出哪个姓名重名
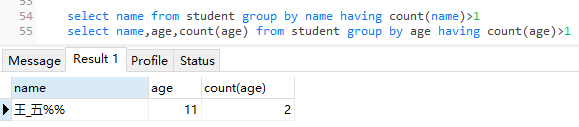
- where 不能与聚合函数一起使用,having可与聚合函数一起使用;在执行SQL语句的过程中,where先执行,再执行group by,再是having,最后是 order by
如此时的student表为:
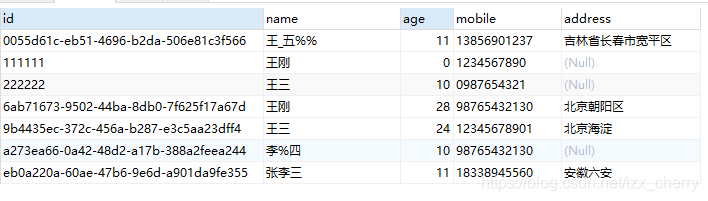
在执行完下面的SQL语句后,可以得到这样的结果:
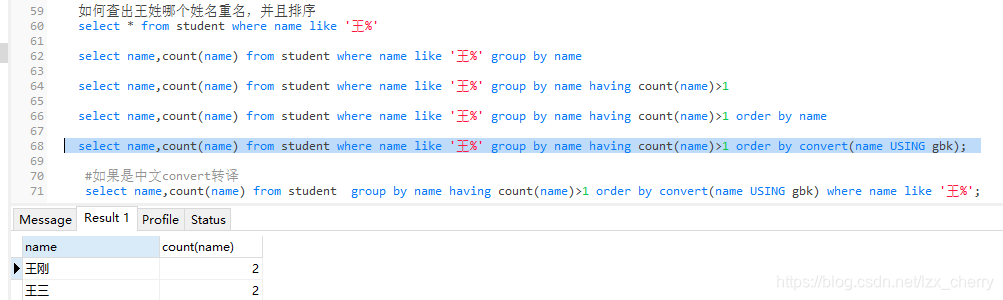
在这里,有如果名字为中文,则需要转译为英文的,即(name USING gbk)

















 3080
3080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









