







 本文分享了一次恢复Oracle RAC数据库的经历,针对控制文件损坏导致的ORA-00600错误及后续一系列问题提供了详细的解决方案,包括重建控制文件、解决ORA-01248错误等。
本文分享了一次恢复Oracle RAC数据库的经历,针对控制文件损坏导致的ORA-00600错误及后续一系列问题提供了详细的解决方案,包括重建控制文件、解决ORA-01248错误等。
前不久帮助某客户恢复了6套 Oracle RAC,均为 ASM,而且版本均为10.2.0.4。熬夜好几天,差点吐血了。
这里以其中一套库的恢复进行简单说明,跟大家分享。
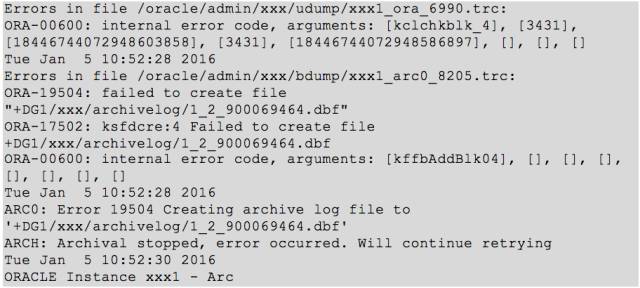
其中几套基本上都遇到了如下的 ORA-00600 错误:

对于该错误,其实很简单,主要是因为控制文件损坏,通过重建控制文件或者利用备份的控制文件进行 restore 即可进行 mount;甚至于我们利用控制文件快照都可以进行数据库 mount;然后接着进行恢复操作。在恢复的过程中还遇到了如下的错误:
上述的 ORA-00600 错误其实很简单,主要是数据块 SCN 的问题。这里以其中一套库的恢复进行大致说明,因为在恢复该库的过程中,遇到了一件十分神奇的事情。
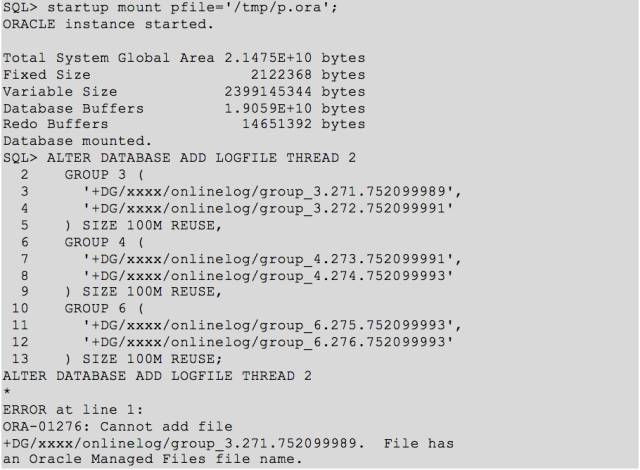
由于是 ORACLE RAC,因此重建控制文件之后,是需要添加 redo logfile 的;然而 add logfile 发现报上述错误。根据 Oracle metalink 的一些方法均不能成功,都报上面的错误,确实很怪异。
有些人看上述的错误,可能会认为是设置了 OMF 的参数,其实这里并不是,我将相关参数全部修改之后,错误依旧。
这里实际上添加 logfile 时,只写磁盘组名称就行了,不需要写绝对路径。
接着在进行 recover 后进行 open resetlogs 打开时,报错 ORA-01248,如下:
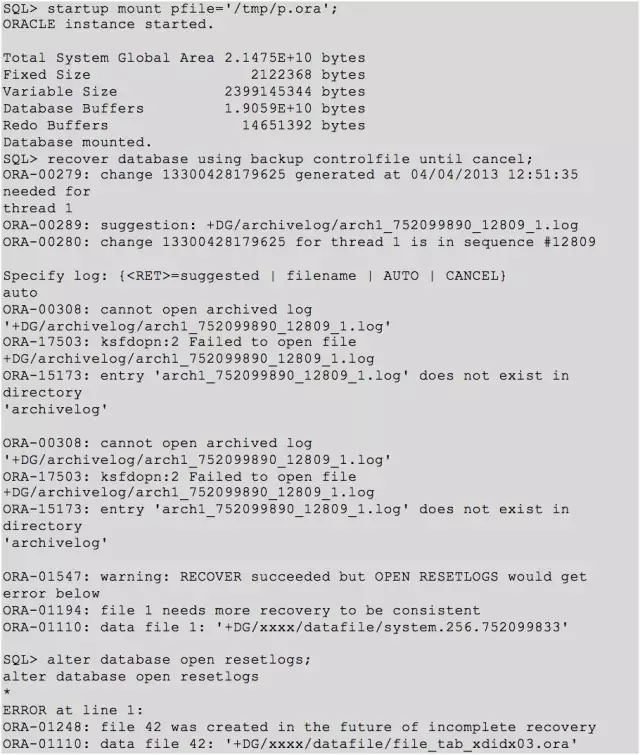
这个错误还是比较少见,实际上网上那些说法,以及 Oracle mos 提供的解决方法我发现都不行。
无奈只能先将其 offline ,然后再进行恢复。再进行 open 之前我查询了当前的 checkpoint scn 如下:
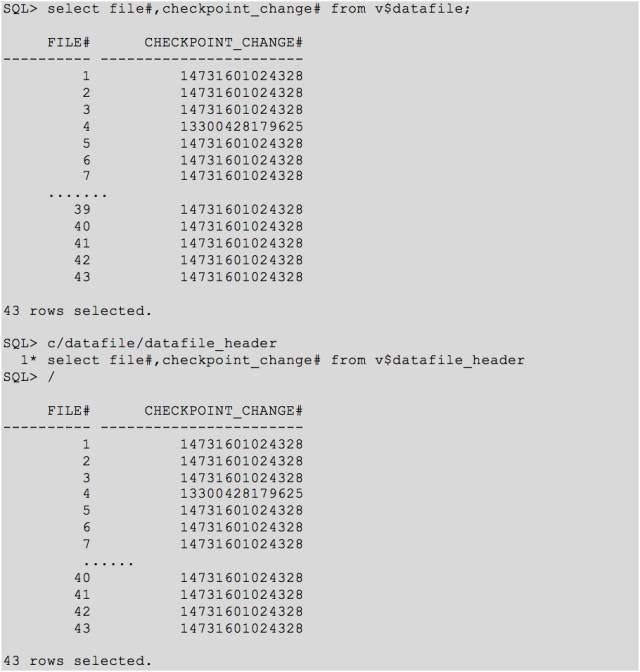
由于 open 失败,这里我想着是不是这2个文件有问题,又用之前的快照控制文件进行 recover 一把,然后再次用重建的控制文件起来数据库进行 recover,发现神奇的事情出现了:
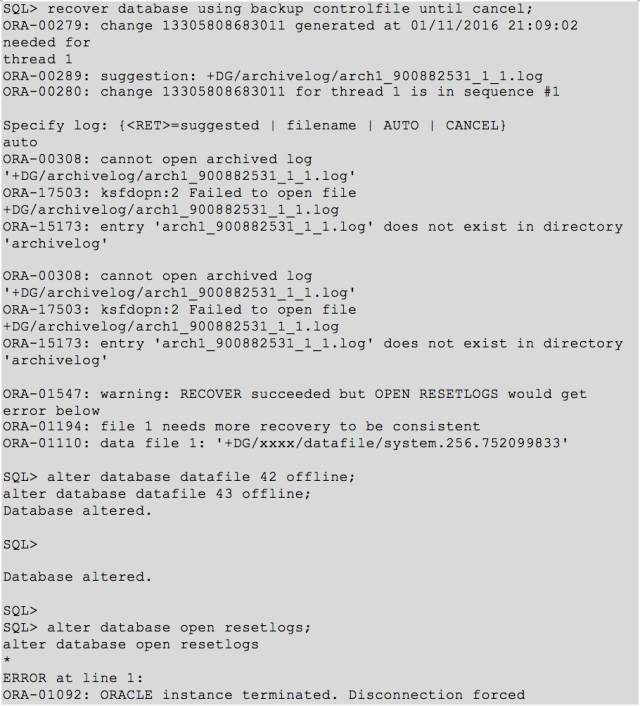
我们可以看到 open 失败了,对于open 失败的情况,我们首先是看 alert log,接着 10046trace.
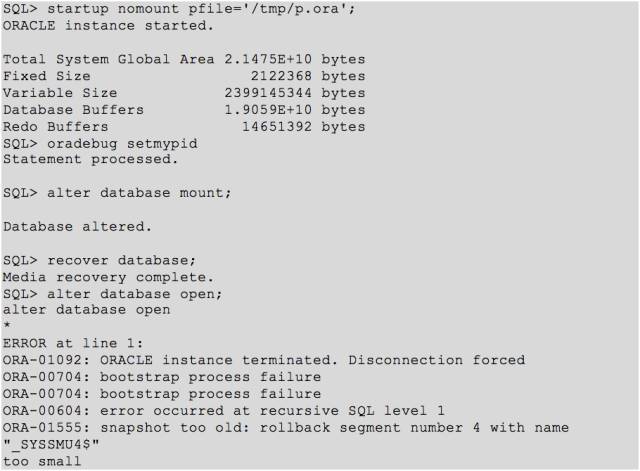
这里我又屏蔽了undo 相关的参数。再次尝试发现错误依旧。再次启动,神奇的事情出现了,SCN 居然倒退了?
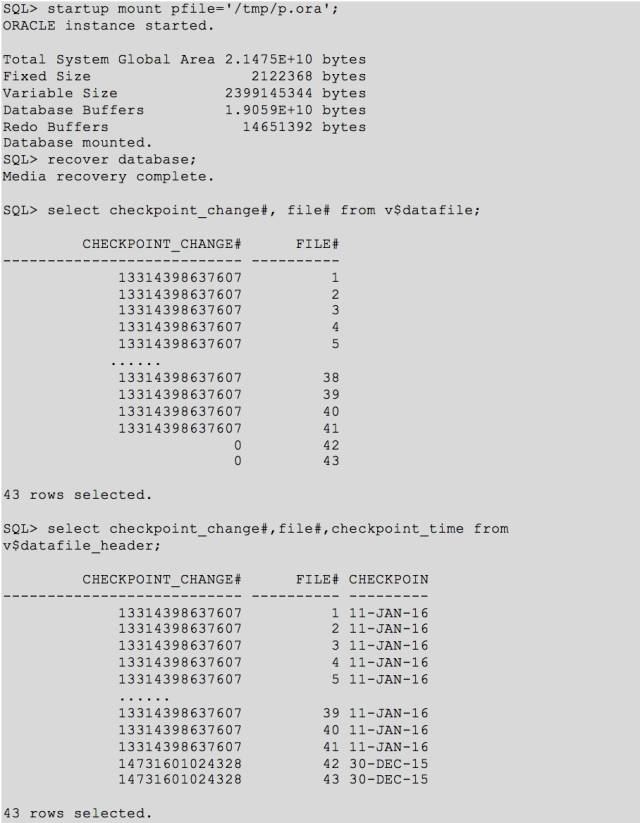
很明显,这个133的 scn 回退到了过去2年前了,出现时空穿越了。。。。当然,open 肯定还是报错:

这里先不管为啥连数据文件头的 SCN 都倒退了(之前被 offline 的2个文件 scn 是 OK 的)。 通过10046trace 得到如下内容:
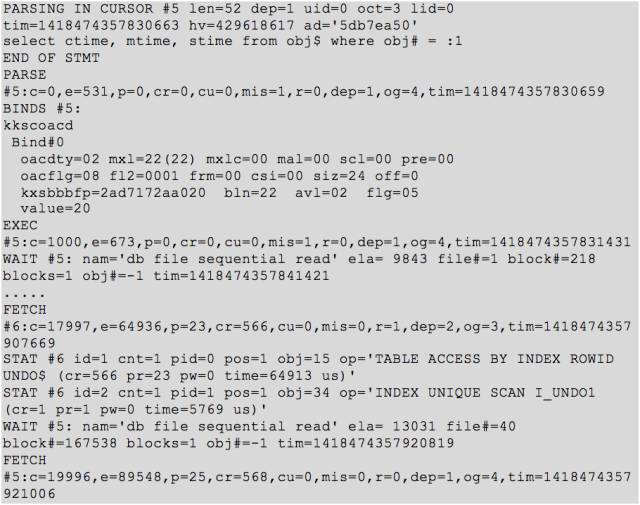
我们这里可以看到,这里报错的 SQL 读取了 file 1 block 218,以及 file40 block 167538。
对于 file 1 block 218,我 dump 发现没有活动事务;而 file 40 block 167538 则为 undo 块。

同时 dump 了这个 undo 块,发现确实感觉有些异常,如下所示:
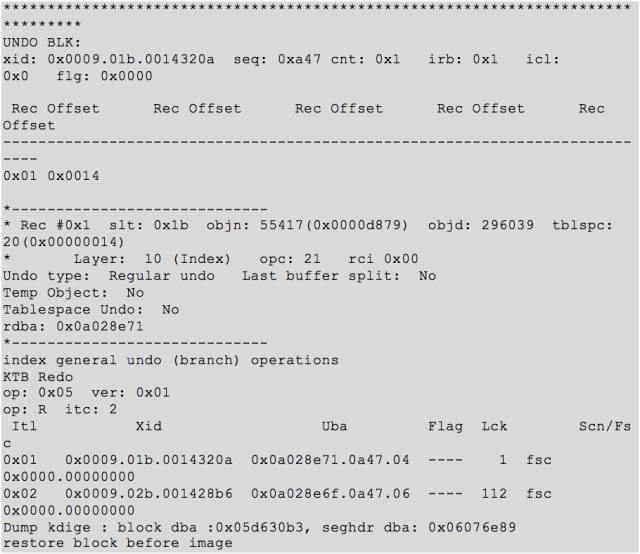
由于所有的文件头 SCN 都倒退了,正常 open 都报错,只能推进 SCN,而且 SCN 必须要比这个 undo block 的最大 SCN 还要大一些才行,通过在 pfile 文件中加入参数*._minimum_giga_scn 即可。
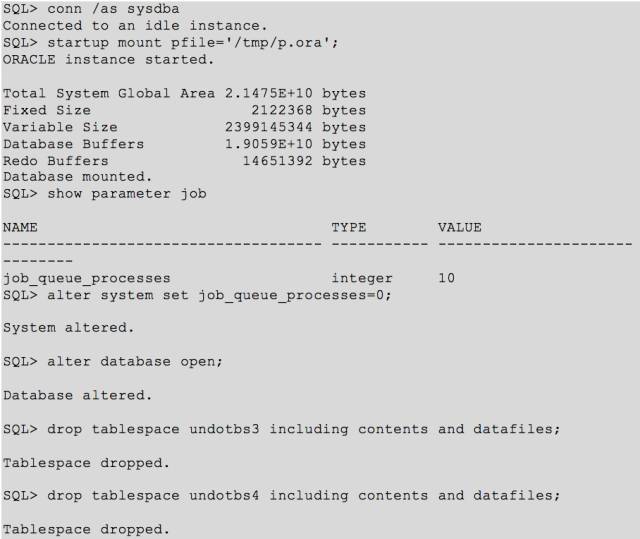
顺利打开数据库之后,立即将原有的 undo 表空间进行 drop 并重建。
虽然数据库是打开了,然而其中有2个数据文件之前被我们 offline 了,而且中间进行了 resetlogs 操作,因此现在无法进行正常 online 了。
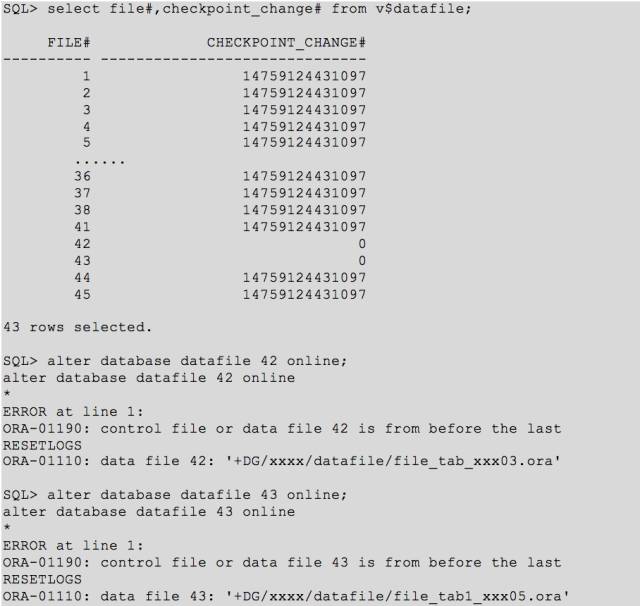
这里用 bbed 将上面2个文件头相关信息修改掉,然后进行 recover,可以顺利 online 文件。
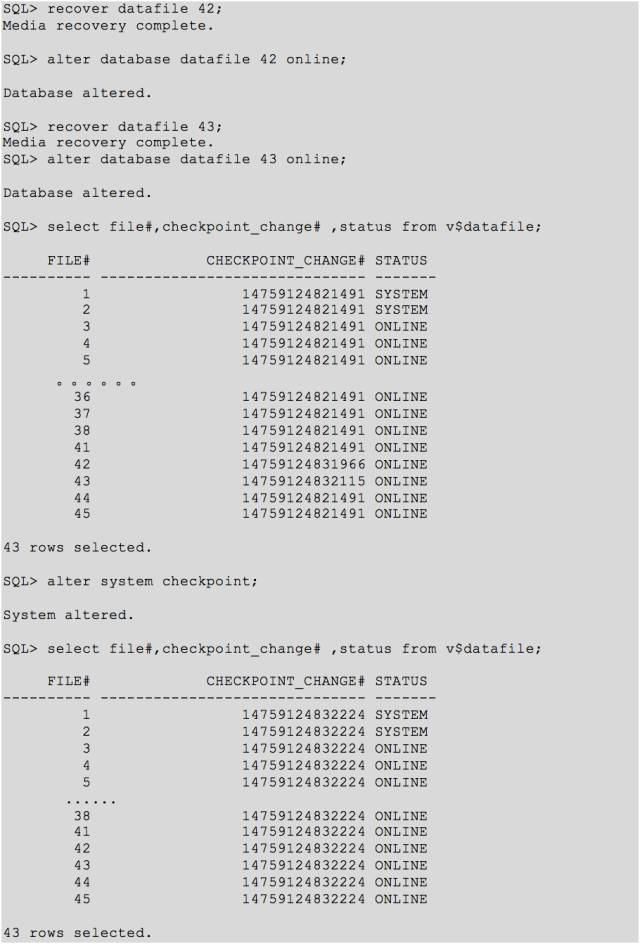
最后建议将数据库 expdp 导出并重建。到此告一段落!

















 6542
6542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









