







本文目录
DML (Data Manipulation Language) 数据定义语言。DML 操作是指对数据库中表记录的操作,主要包括表记录的插入(insert)、更新(update)、删除(delete),是开发人员日常使用最频繁的操作。
在 Hive 中,DML 操作只包括插入(insert)、删除(delete)。HDFS数据支持插入、删除,虽然也支持数据的更新,但是 HDFS 并不建议这么做,故此处不做更新介绍。
向 HDFS 中插入数据,本文通过导入数据的方式介绍
1.导入数据
Ⅰ.导入数据的三种方式
向 HDFS 中写入数据,一共有3种方式
- 通过 Hive,使用
insert方式插入; - 使用 HDFS 的
put命令,将文件直接写入到 Hive 指定表文件夹下的方式; - 使用 Hive 提供的
load命令,将数据导入(推荐使用)。
此处标题命名为
导入数据,而非插入数据。是因为大数据环境下,数据量非常大。
1. Hive 中使用 insert 方式一条一条插入有些不合理,太慢了;
2. HDFS 的 put 命令,将文件直接上传至 HDFS ,因为put 方式不会改变元数据信息,所以会导致 Hive 在 select count(*) 时出错;
3. Hive 的 load 命令,将文件通过 hive 方式导入至 HDFS中。load 方式会修改元数据,从而在 select count(*) 时,由于元数据变化,导致 count(*) 计算会走 MR,得出正确的数据条数
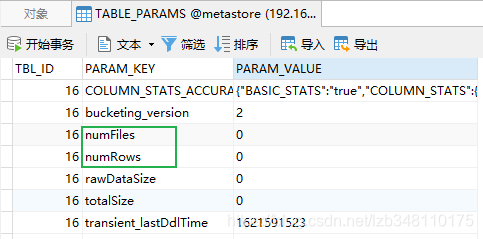
load为什么count(*)会走MR?
在元数据库中,有个TABLE_PARAMS表,表中存储着每个表的一些关键字段。表中存储着numFIles和numRows两个字段。在 Hive 执行 select count(*) 时,如果元数据没有变化,则直接获取 numRows 的数值,此时查询就不会走 MR,直接通过元数据库返回;
put 方式上传文件,并不会修改 Hive 的元数据信息,所以在 select count(*) 时会出错。
采用Hive 提供的 load 上传文件,此时 Hive 是知道上传几个文件的,但是不知道文件中有多少数据,此时元数据中的 numFiles 会被修改,numRows不会变化。然后在执行 select count(*) 时,由于元数据信息有变动,便不会读取 numRows 的数据,转而通过 MR 去重新计算
Ⅱ.load 命令:向表中装载数据
语法:
load data [local] inpath'数据的 path'[overwrite] into table table_name [partition (partcol1=val1,…)];
字段介绍:
load data: 表示加载数据
local: 表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表中
inpath: 表示加载数据的路径
overwrite: 表示覆盖表中已有的数据,否则表示追加
into table: 表示将数据加载到哪张表
table_name: 表名。将数据加载到具体哪张表(也支持 库名.表名)
partition: 表示将数据上传到指定的分区
说明:
load 方式,如果文件在 hdfs 上,load 上传会对文件进行移动;如果文件在本机,load 上传会对数据文件进行拷贝。【数据在 hdfs 上移动是非常快的,因为只需要将 namenode 中文件的路径修改即可,实际文件并未做任何变动】
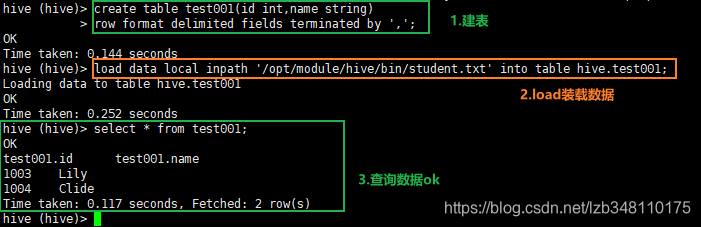
load 示例:
1.创建表
create table test001(id int,name string) row format delimited fields terminated by',';
2.load加载数据
load data local inpath'/xxx/xxx/xxx/student.txt'into tabledefault.student;
Ⅲ.通过查询语句向表中插入数据(insert)
需求:
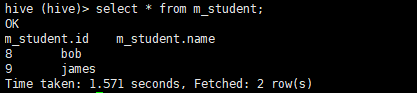
创建表 m_user 和 m_student,m_user插入数据,使用insert方式,将 id > 5 的数据插入至 m_student 表中
1.创建表m_user
create table m_user(id int,name string) row format delimited fields terminated by ',';
2.m_user表插入数据
insert into table m_user values(1,'lili'),(2,'lucy'),(8,'bob'),(9,'james');
3.创建表m_student
create table m_student like m_user;
4.将id>5的数据,采用insert方式插入m_student表中
insert into m_student select id,name from m_user where id > 5;

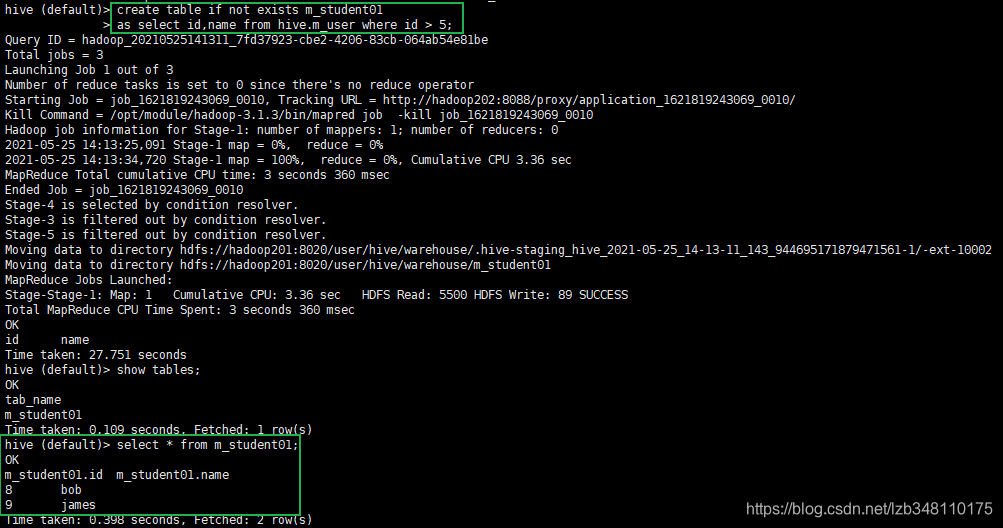
Ⅳ.查询语句中创建表并加载数据(As Select)
语句:
create table if not exists m_student
as select id,name from m_user where id > 5;
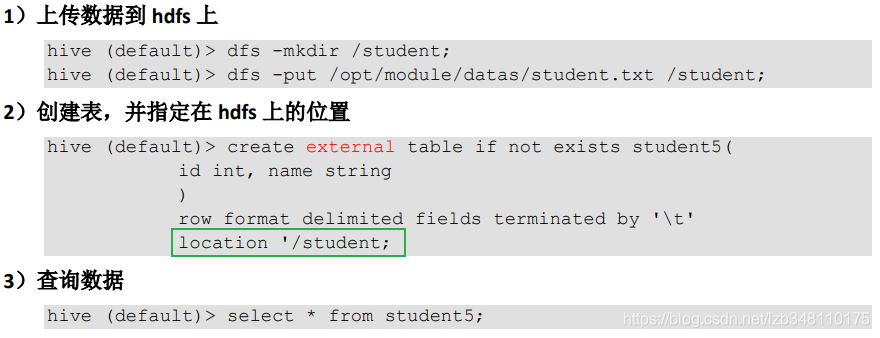
Ⅴ. 创建表时通过 Location 指定加载数据路径
Ⅵ.Import 数据到指定 Hive 表中
提示:不常用,了解即可
注意:使用import方式,需要先用 export 导出后,再将数据导入 (参考:2.数据导出—Ⅳ.export 导出到 HDFS 上)
hive (default)>import table student2 from '/user/hive/warehouse/export/student';
2.数据导出
Ⅰ.insert 导出
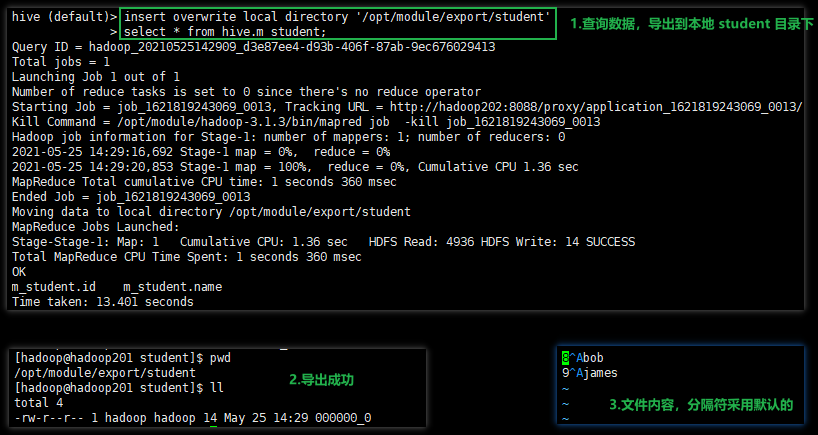
1.将查询的结果导出到本地
(请看下面第二种格式化后导出到本地,不格式化不知道分隔符是啥,不方便后期其他项目的使用,建议格式化)
insert overwrite local directory '/opt/module/export/student'
select * from hive.m_student;
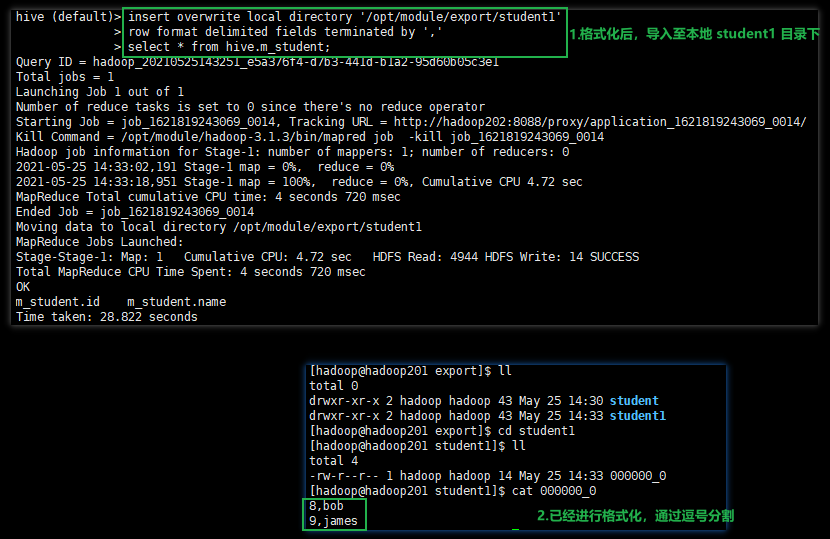
2.将查询的结果,格式化后,导出到本地
insert overwrite local directory '/opt/module/export/student1'
row format delimited fields terminated by ','
select * from hive.m_student;
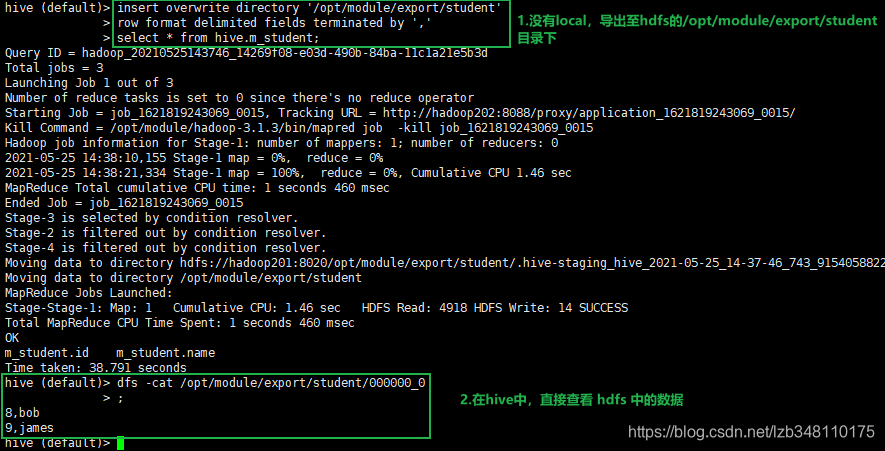
3.将查询的结果导出到 HDFS (去掉local即可)
insert overwrite directory '/opt/module/export/student1'
row format delimited fields terminated by ','
select * from hive.m_student;
Ⅱ.Hadoop 命令导出到本地
将hdfs中的数据student.txt,通过Hadoop导出方式导出至本地
hive (default)> dfs -get/user/hive/warehouse/student/student.txt/opt/module/data/export/student3.txt;
Ⅲ.Hive Shell 命令导出
基本语法:
hive -e/-f 执行脚本或者语句 > file
将hive -e 执行的结果,直接写入到本地文件
[hadoop@hadoop201 bin]$ hive -e'select * from default.student;'>/opt/module/hive/data/export/student4.txt;
Ⅳ.export 导出到 HDFS 上
提示:不常用,了解即可
(配合1.数据导入-------Ⅵ.Import 数据到指定 Hive 表中,一起使用)
hive (default)>exporttable default.student to'/user/hive/warehouse/export/student';
注意:
export 和 import 主要用于两个 Hadoop 平台集群之间 Hive 表迁移
Ⅴ.Sqoop 导出
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
待补充
3.删除数据
Ⅰ.清除表中数据(truncate)
注意:truncate 只能删除管理表,不能删除外部表中数据
hive (default)>truncatetable student;
Ⅱ.通过删表方式删除数据(drop)
注意:drop 只能删除管理表的数据,不能删除外部表中数据
hive (default)>droptable student;
博主写作不易,加个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
我不能保证所写的内容都正确,但是可以保证不复制、不粘贴。保证每一句话、每一行代码都是亲手敲过的,错误也请指出,望轻喷 Thanks♪(・ω・)ノ


















 7564
7564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











