







 本文详细介绍了数据库设计的重要性,包括需求分析、逻辑设计和物理设计的步骤。讨论了字段类型选择、长度设定以及数据库优化策略,如范式理论的应用。同时,对比了关系型数据库与非关系型数据库的选择,并提供了实例分析。
本文详细介绍了数据库设计的重要性,包括需求分析、逻辑设计和物理设计的步骤。讨论了字段类型选择、长度设定以及数据库优化策略,如范式理论的应用。同时,对比了关系型数据库与非关系型数据库的选择,并提供了实例分析。
数据库学习笔记(2)
2021/05/26 add 数据库设计
2021/07/20 add 关系型数据库三大范式
2021/09/02 add 需求分析案例
2021/09/06 add ER 图
数据库设计
节选自 imooc 数据库设计那些事儿
数据库设计原则,转载非原创
什么是数据库设计
即根据业务需求,首先进行数据库选型,然后根据选用的 DBMS,位业务构造最优数据模型,并建立好表之间的关联关系的过程。
keywords:
- 有效存储
- 高效访问
常见的关系型数据库?
- MySQL
- Oracle
- SQLServer
- PgSQL
常见的非关系型数据库
- Mongo
- Memcache
- Redis
为什么要进行数据库设计
- 减少数据冗余,节约存储空间
- 避免数据维护异常,为未来有可能的慢查询调优奠定了一定的基础,避免低级错误导致的返工。
- 高效访问
数据库设计步骤
需求分析
举个例子:常常业务方希望把一些日志存储在数据库中,当然从 DBA 的角度看这种方式不推荐,但若必须入库则需要提前定义好归档、清理规则
- 了解系统中所要存储的数据,明确如下问题:
- 实体的属性有哪些
- 哪些属性或者属性的组合能够唯一标识一个实体
- 实体与实体之间的关系(1 对 1,1 对多,多对多)
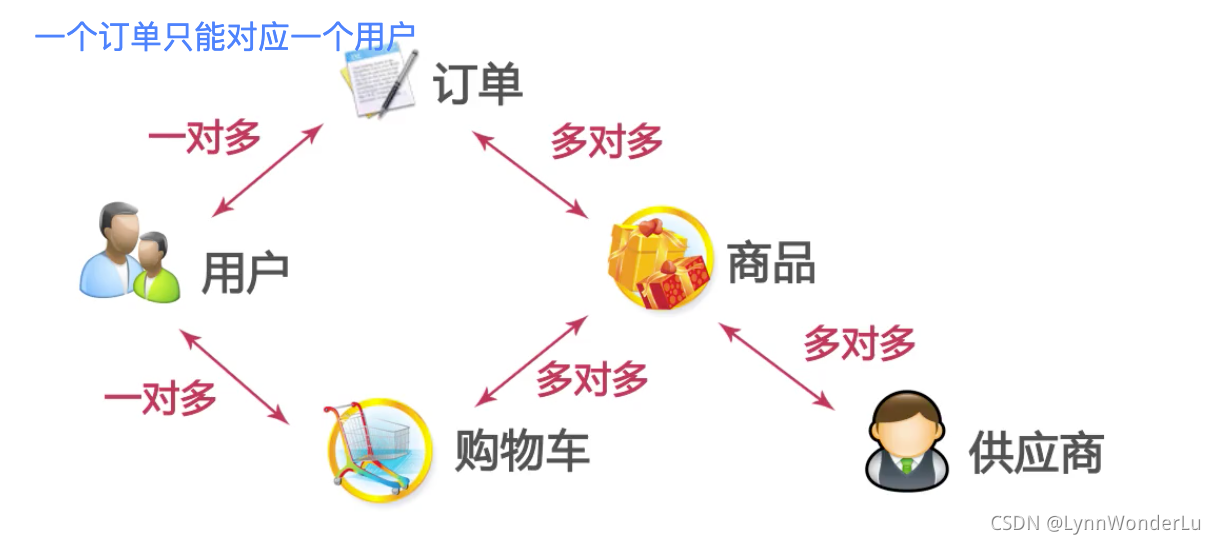
一个案例
一个小型的电商网站由用户模块,商品模块,订单模块,购物车模块,供应商模块组成。
- 用户模块

- 商品模块

- 订单模块

- 购物车模块

- 供应商模块

下面看一下几个实体之间的关系:
逻辑设计
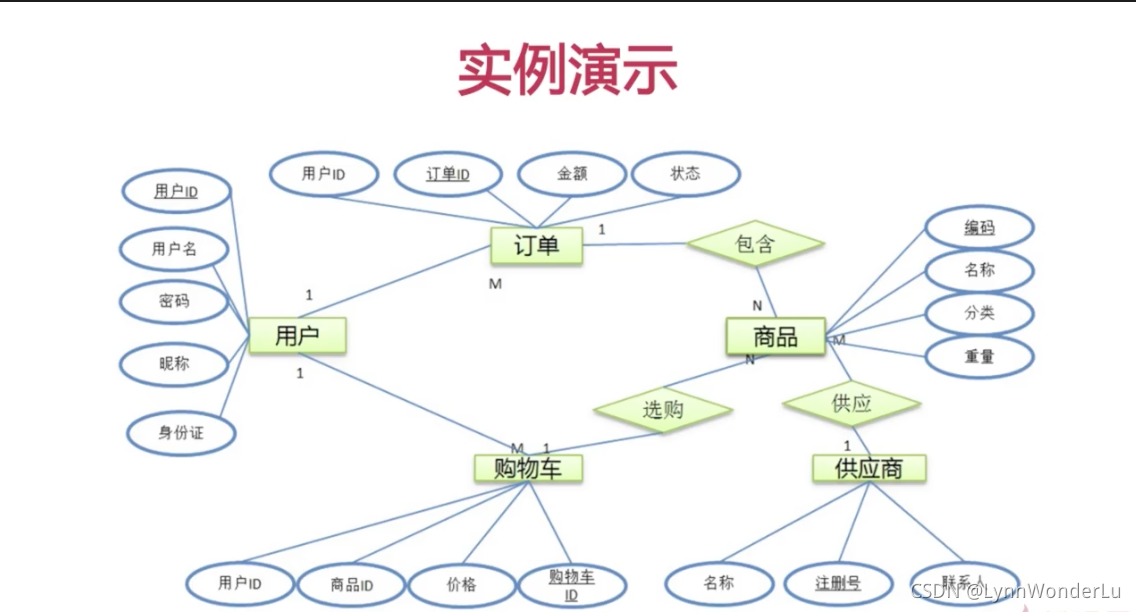
在逻辑设计这一步要做到:
- 画出 ER 图
- 写 ddl

把刚刚的案例转化成 ER 图之后则是:
物理设计
逻辑设计后可以设计表结构,根据数据库的自身特点把逻辑设计转换为物理设计:
- 选择合适的数据库管理系统。比如选择关系型数据库还是非关系型数据库
- 定义数据库、表以及字段的命名规范
- 根据所选的 DBMS 选择合适的字段类型
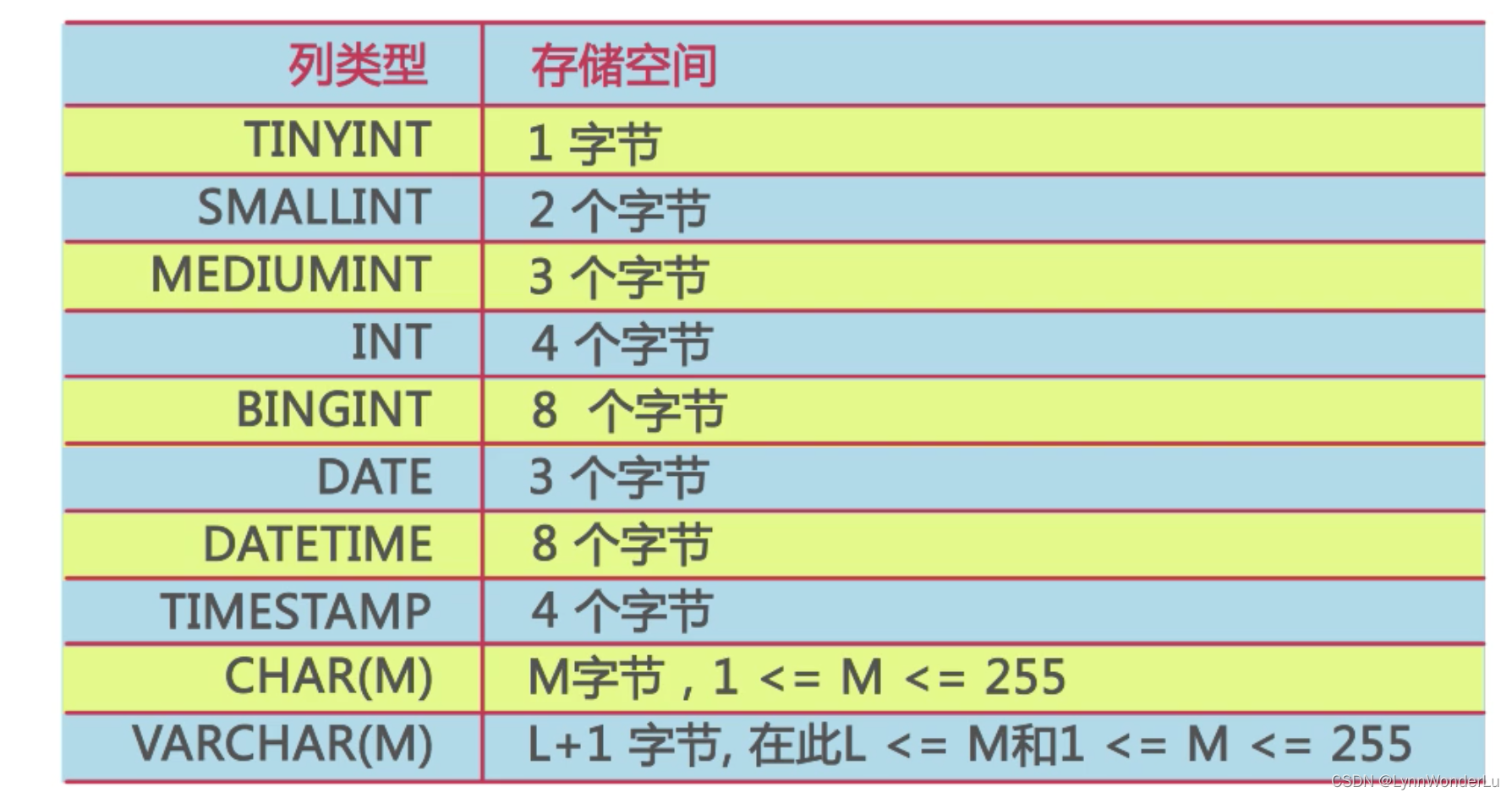
字段类型选择
- varchar 是存储可变长度字符串
- char 是存储固定长度字符串
字段类型选择原则:
- 通常当一个列可以选择多种类型时,优先考虑数字类型,其次是日期或二进制,最后是字符类型
- 对于相同级别的数据类型,优先选择占用空间小的数据类型
原因是:
- 对数据进行查询条件、Join及排序时,同样的数据字符处理比数字慢
- 数据库中,数据处理以页为单位,列的长度越小,利于性能提升,因此就数据库而言最大的瓶颈其实在于磁盘 IO
Q1:char 和 varchar 类型如何进行选择?
原则:
- 如果列中要存储的数据长度是差不多的则选择 char,否则选择 varchar
- 如果列中的最大数据长度小于 50B(byte), 则一般考虑用 char, 如果这个列很少用则基于节省空间和减少 I/O 的考虑,还是可以考虑选择用 varchar
- 一般不宜定义高于 50B 的 char 类型列
Q2: decimal 和 float 类型如何进行选择?
原则:
- decimal 用于存储精确数据,float 用于存储非精确数据,因此像钱这类数据一般使用 decimal
- float 存储空间开销一般要比 decimal 小,因此非精确数据类型优先选择 float 类型
Q3: 时间类型如何进行存储?
- 需要考虑使用 int 存储的优缺点
- 优点:字段长度比 datetime 小
- 缺点:要进行函数转换,且最大只能存储到 2038-1-19 11:14:07 即 2^32
- 需要考虑存储的时间粒度
- 一般来讲如果只存储年则完全可以使用 mysql 的 year 类型 MySQL数据类型–日期和时间类型
Q4: mysql 使用自增主键还是 uuid 做主键比较好
已知选择主键的原则:不使用任何业务相关的字段作为主键因此,身份证号、手机号、邮箱地址这些看上去可以唯一的字段,均不可用作主键。
作为主键最好是完全业务无关的字段,我们一般把这个字段命名为id。常见的可作为id字段的类型有:
- 自增整数类型:数据库会在插入数据时自动为每一条记录分配一个自增整数,这样我们就完全不用担心主键重复,也不用自己预先生成主键;
- 使用自增主键
id bigint unsigned auto_increment comment '主键' primary key,一般不使用 uuid 做主键,原因有三,一是太长其通常占用 16 字节,但是自增 int 一般四个字节就够了如果用 bigint 则是 8 个字节,二是 uuid 无序
- 使用自增主键
- 全局唯一GUID类型:使用一种全局唯一的字符串作为主键,类似
8f55d96b-8acc-4636-8cb8-76bf8abc2f57。GUID算法通过网卡 MAC 地址、时间戳和随机数保证任意计算机在任意时间生成的字符串都是不同的,大部分编程语言都内置了 GUID 算法,可以自己预算出主键。- 使用 uuid 可以不像自增 id 那样由数据库生成,可以自行生成。
- 在使用自增主键的同时可以使用 uuid 作为唯一键,通常自增 id 位数不一样,使用
自定义前缀_shortuuid的格式可以规范数据的唯一键
Q5: MySQL中key 、index 、primary key 、unique key 的区别
- 反范式化设计,相当于增加一些冗余以空间换时间
字段长度设定
- 数据字典编码字段,比如 id,已知 GUID 通常用 32 位的字符串(32 个字符)来表示,其是 128 位的全局唯一标识符,所以我们通常用 varchar(32) 来定义,这样最终 id 即便修改为 UUID 也可以存储。(已知:MySQL 5.7 版本
varchar(N)字段类型中的N是字符数。) - 对于备注类型的字段,一般内容在30个汉字左右,所以推荐设置为100
- 对于类似名称的字段: 如单位名称, 数据字典项目的名称等,最好再大一些,设成 60 位
- 数据库默认定义 varchar(255) 因为小于等于 255 的时候,长度标识位是一个字节而大于 255 的时候是两个字节Why historically do people use 255 not 256 for database field magnitudes?
维护优化
优化中尤其有新需求也要经过前几步来让数据库设计最优,要进行必要的索引优化和大表拆分
关系型数据库三大范式
名词解释:
- 关系: 一个关系对应通常所说的一张表。
- 元组:表中的一行称为一个元组。
- 属性:表中的一列即为一个属性;每个属性都有一个名称,称为属性名。
- 候选码:表中的某个属性组,它可以唯一确定一个元组。
- 主码:一个关系有多个候选码,选定其中一个为主码。
- 域:属性的取值范围。
NF:normal form 数据库范式也分为1NF,2NF,3NF,BCNF,4NF,5NF。一般在我们设计关系型数据库的时候,最多考虑到BCNF就够。符合高一级范式的设计,必定符合低一级范式,例如符合2NF的关系模式,必定符合1NF。
references:
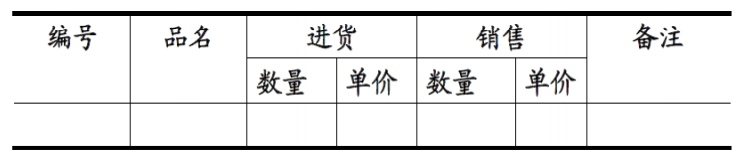
- 1NF: 符合1NF的关系中的每个属性都不可再分。表1所示的情况,就不符合1NF的要求。
换句话说就是数据库中的表都是二维表。
- 2NF: 2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。
码: 假如当 K 确定的情况下,该表除 K 之外的所有属性的值也就随之确定,那么 K 就是码。一张表中可以有超过一个码。(实际应用中为了方便,通常选择其中的一个码作为主码)
非主属性:码中的属性就是主属性,其他就是非主属性。
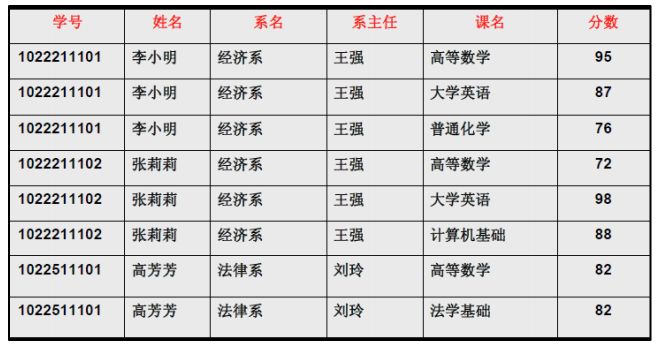
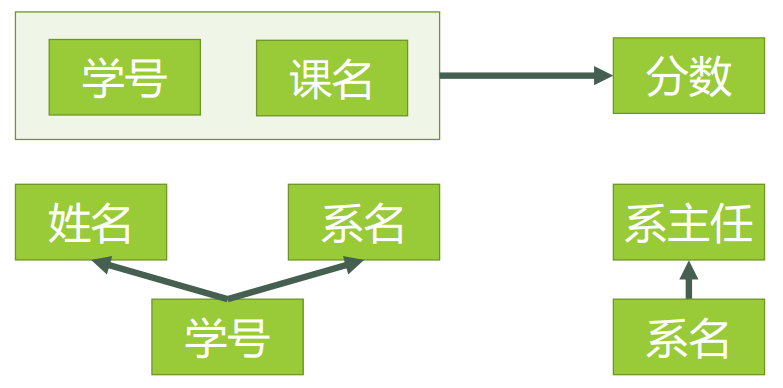
上表中的码是什么呢?我们可以画一下关系图:
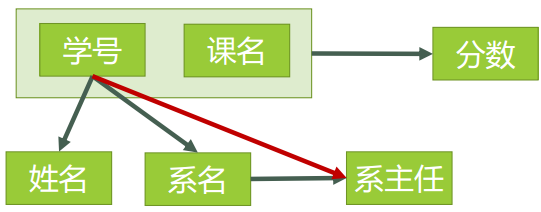
由于存在 学号–>姓名 学号–>系名 学号–>系主任 的非主属性对码的部分函数依赖因此不符合 2NF
另一个例子:
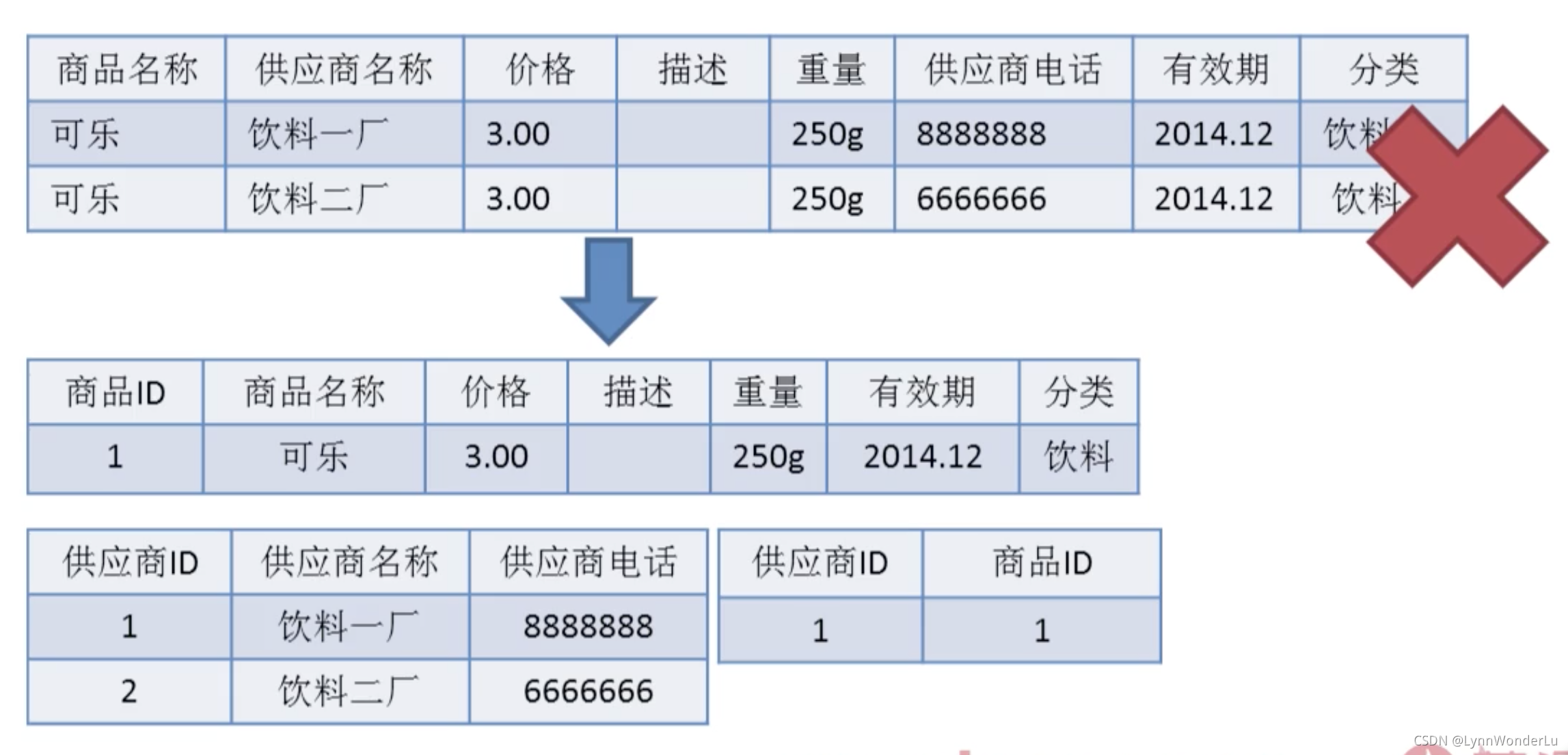
- 3NF:第三范式(3NF) 3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。
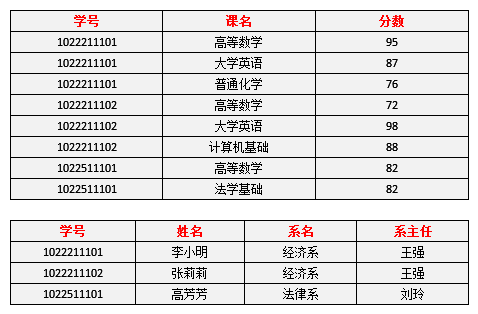
对于学生表,主码为学号,主属性为学号,非主属性为姓名、系名和系主任。因为 学号 → 系名,同时 系名 → 系主任,所以存在非主属性系主任对于码学号的传递函数依赖,所以学生表的设计,不符合3NF的要求。
对于学号课名分数表显然满足 3NF,主属性是学号和课名,非主属性是分数
那么最终什么样是最合适的呢,且先将关系进行分解:
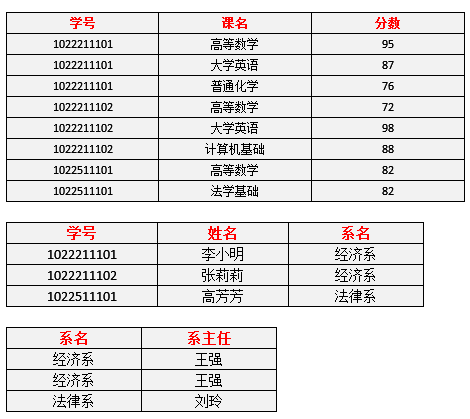
因此也就有了三个表:
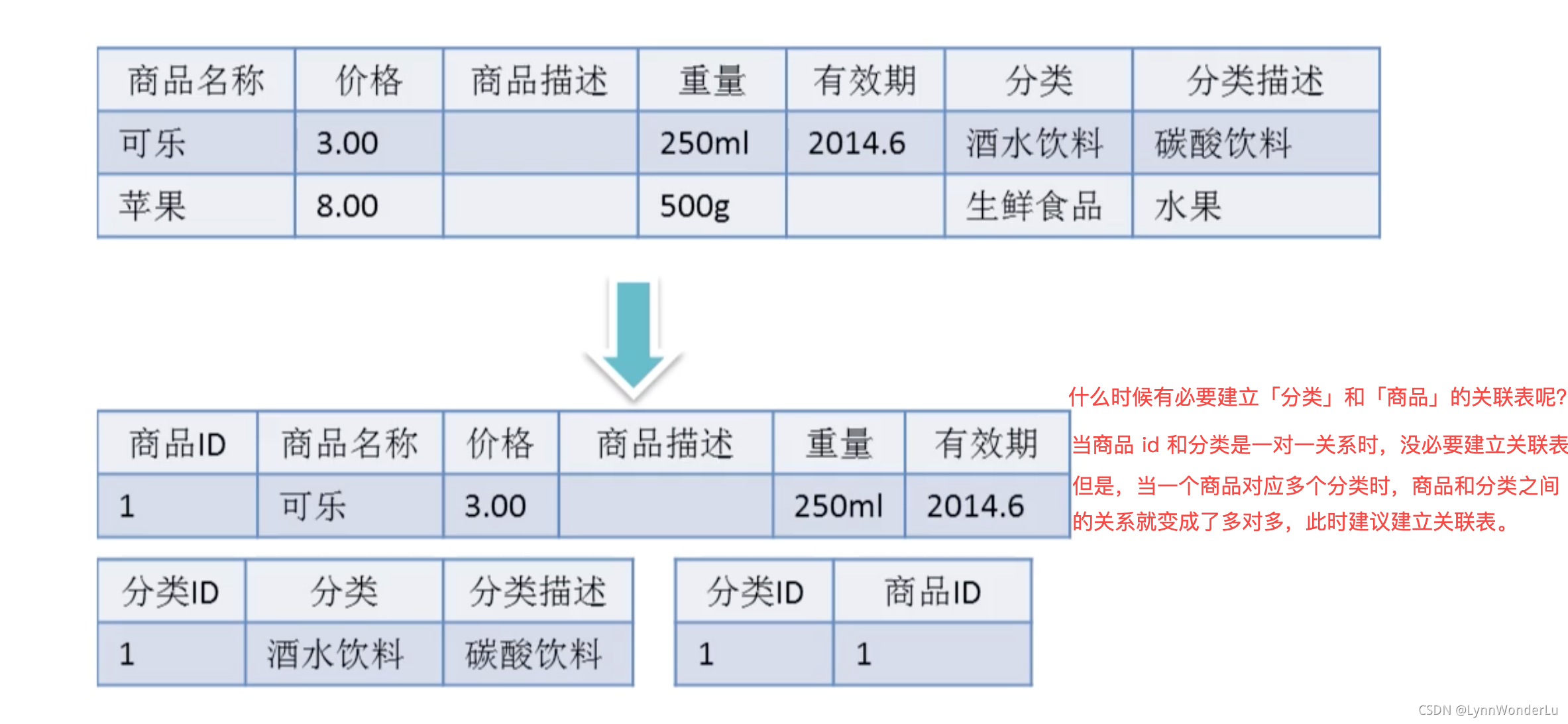
另一个例子:
结论
由此可见,符合3NF要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。当然,在实际中,往往为了性能上或者应对扩展的需要,经常 做到 2NF 或者 1NF,而对 3NF 不做较大的限制,比如有个表字段为:商品、单价、销售量 三个字段,但为了提高查询的效率,我们可能会加入一个「金额」这样的冗余字段。
- BC(Boyce.Codd)范式 在 3NF 的基础之上,消除了主属性对于候选码的部分与传递函数依赖。
或者更通俗的意思是:组合关键字之间不能存在函数依赖关系
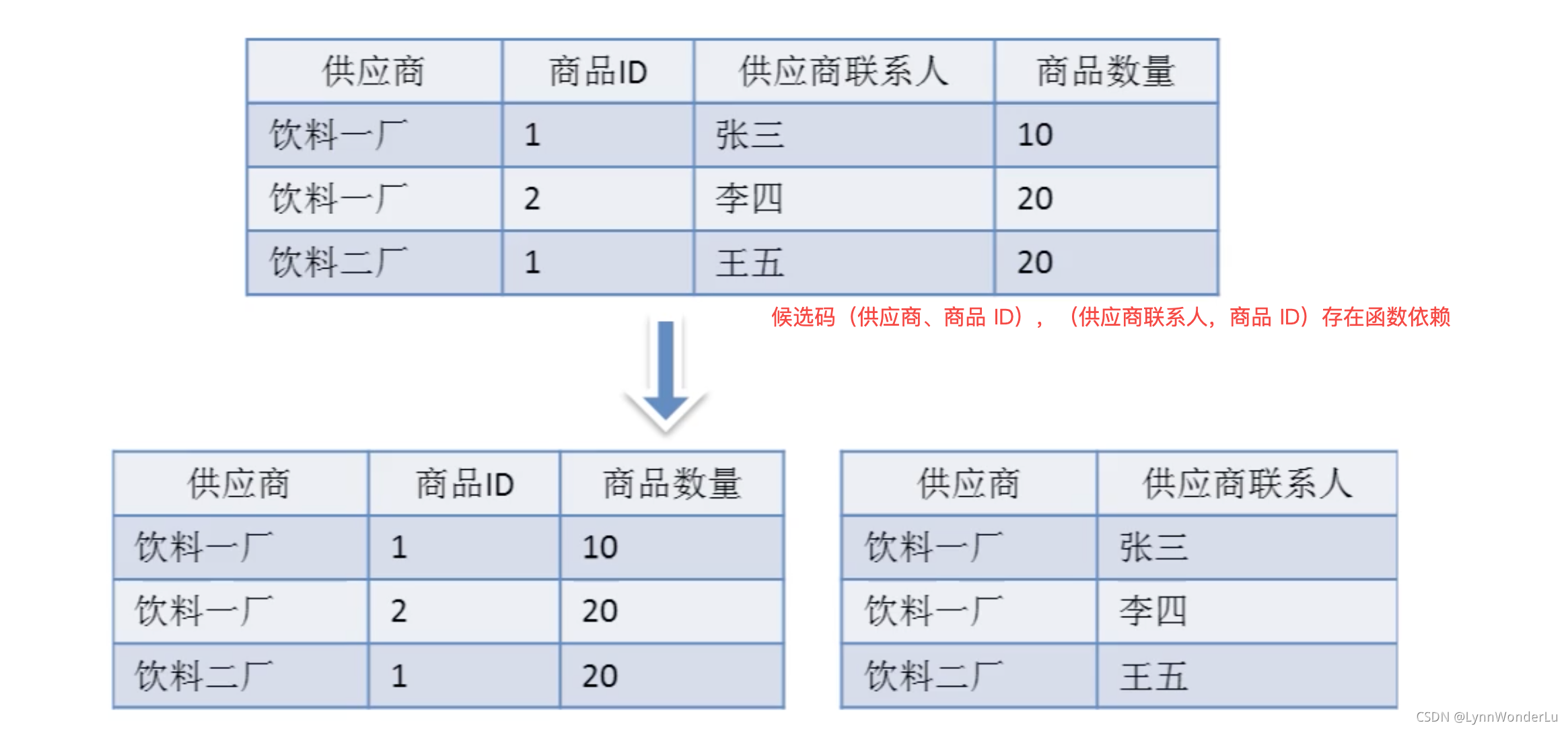
一个案例
这个案例是读了一篇文章MongoDB中的范式与反范式之后的一些理解
范式化:(normalization)是将数据分散到多个不同的集合,不同集合之间可以相互引用数据。(但实际上由于 MongoDB 不支持 join,所以在不同集合之间需要进行多次查询)
优点:
- 数据写入速度快
反范式化(denormalization)与范式化相反:将每个文档所需的数据都嵌入在文档内部。
优点:
- 数据读取速度快
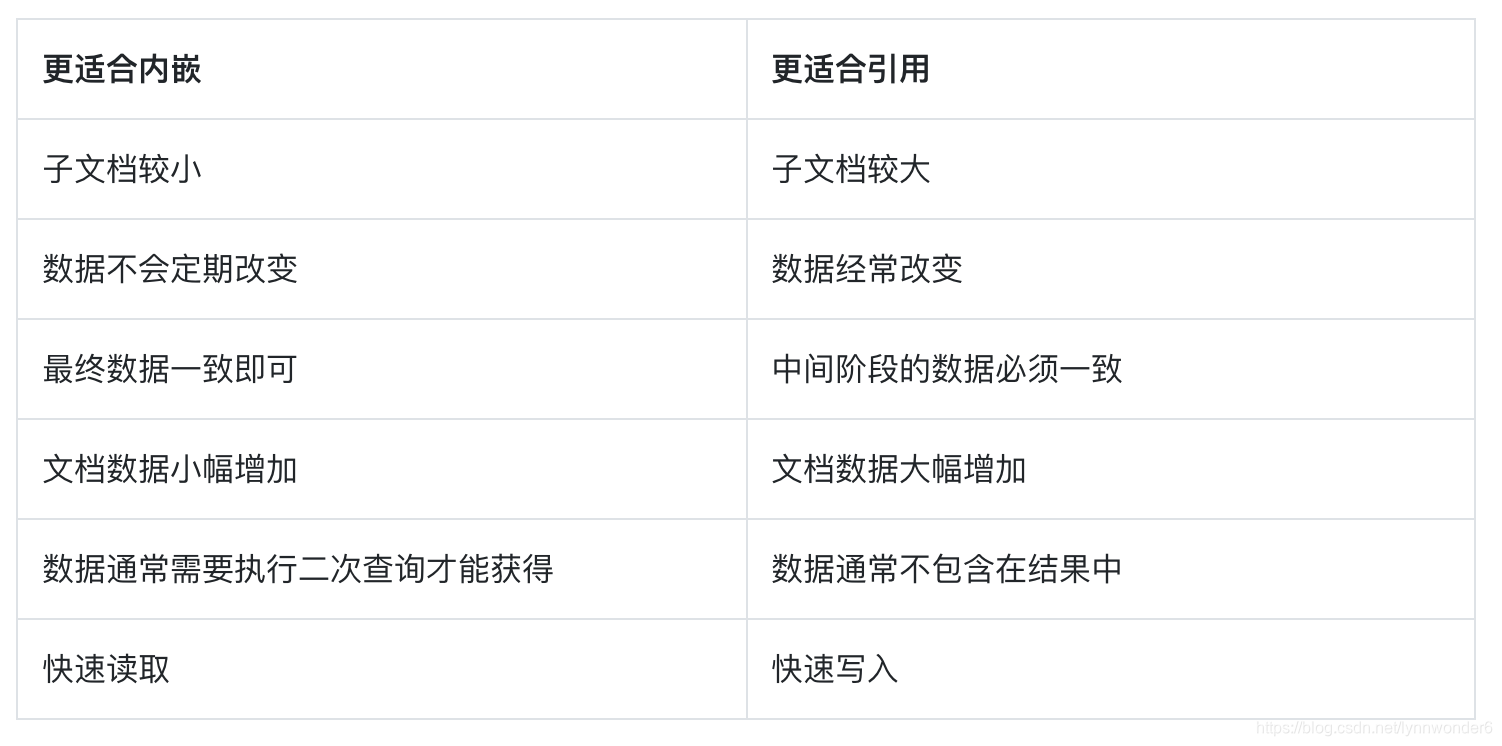
当然文章中举了一些例子之后会发现在 MongoDB 这种 nosql 的数据库中,使用内嵌数据和引用数据相结合的方式是最合适的。那哪些适合内嵌到 document 中,哪些适合另写 collection 呢:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









