 优化条码识别:速度与精度提升的实战
优化条码识别:速度与精度提升的实战





 博主通过深度预处理和OpenCV+ZXing技术,解决了一款商业收费条码识别库的低识别率和慢速问题,成功提升31张图片的识别率至40毫秒,展示了技术改进的成果和优化潜力。
博主通过深度预处理和OpenCV+ZXing技术,解决了一款商业收费条码识别库的低识别率和慢速问题,成功提升31张图片的识别率至40毫秒,展示了技术改进的成果和优化潜力。
引言
好友跟我说有些不能识别的条码,我对这个很感兴趣,因为我知道除了条码图像本身质量问题,有些条码不能识别是因为预处理的原因,做好预处理,还可以提升一波识别率的,另外一个吐槽的地方就是识别的时间特别漫长,一张图需要1秒多,它们每张图的大小是2736x2736,所以我让他把不能识别的图像都发我一些,他总计给了我 54张。这里要特别交代一下它们用的库是一个国内的商业收费条码识别库!

所以这个事情面临两个问题:一个是识别率不满意,二个速度慢,第三个还得花钱!
提升方法效果
先看一下数据,截图如下:

然后我一波疯狂预处理变成这样:

看到那些二值化之后的白色区域了吗?它就是条码所在区域,只要获取条码所在区域,然后扔到ZXing的decode方法中就会有结果了?理论上是这样,先要把条码区域扣出来,这个就涉及到二值图像分析的轮廓处理,经过一番轮廓分析之后,我得到了每张图上每个可疑条码所在区域,然后我就送到ZXing解码函数中,完成解码,这段代码如下:
types.push_back(CODE_TYPE::DATA_MATRIX);types.push_back(CODE_TYPE::MAXICODE);types.push_back(CODE_TYPE::QR_CODE);types.push_back(CODE_TYPE::AZTEC);types.push_back(CODE_TYPE::CODABAR);types.push_back(CODE_TYPE::CODE_128);types.push_back(CODE_TYPE::CODE_39);types.push_back(CODE_TYPE::CODE_93);reader.initConfig(types, cv::Mat());reader.decode_ver2(image, txtInfo, 5, true);
然后从txtInfo中接受返回结果:
txtInfo.status 返回0表示识别,-1表示未识别txtInfo.code 返回识别字符串
运行结果如下:
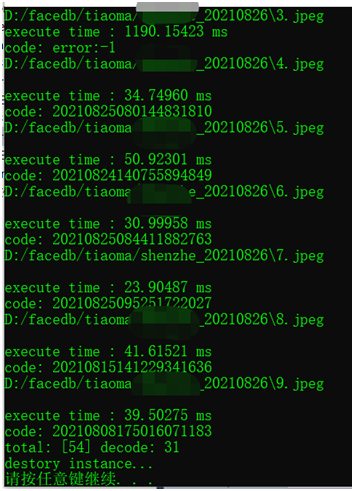
54张商业库不能识别的,我们成功识别出31张!关键是速度平均都在40毫秒左右!实现了速度、识别率双提升!这个就是我用OpenCV+ZXing给出的初步结果,我看了图像,发现还有继续优化预处理的空间!有些还应该被识别!
后记:
由于各种原因不能发原图,就发一些缩略图!源码,我到底要不要放出来?大家说吧!

















 1045
1045







 到【灌水乐园】发言
到【灌水乐园】发言







