




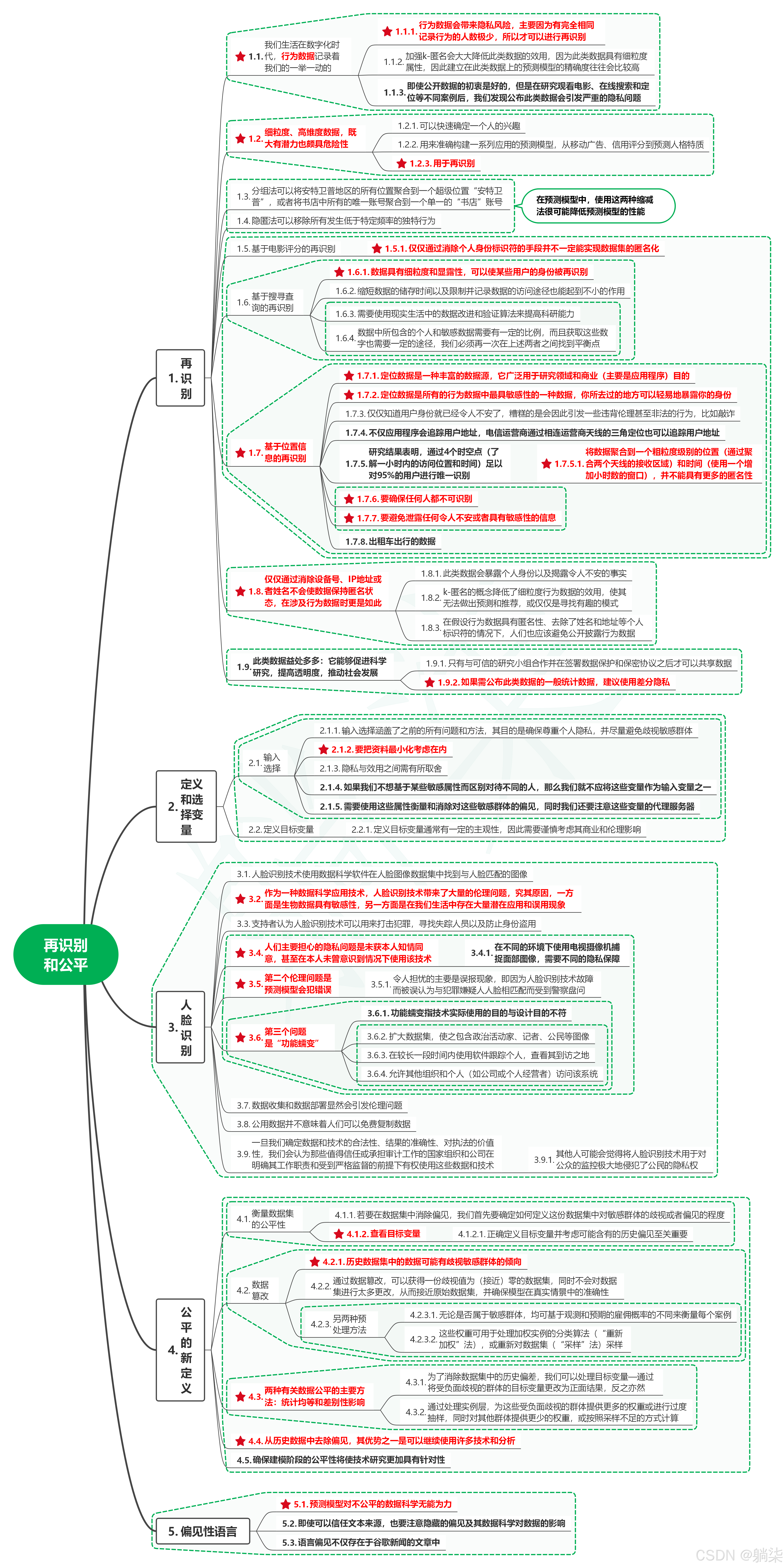
1. 再识别
1.1. 我们生活在数字化时代,行为数据记录着我们的一举一动的
-
1.1.1. 行为数据会带来隐私风险,主要因为有完全相同记录行为的人数极少,所以才可以进行再识别
-
1.1.2. 加强k-匿名会大大降低此类数据的效用,因为此类数据具有细粒度属性,因此建立在此类数据上的预测模型的精确度往往会比较高
-
1.1.3. 即使公开数据的初衷是好的,但是在研究观看电影、在线搜索和定位等不同案例后,我们发现公布此类数据会引发严重的隐私问题
1.2. 细粒度、高维度数据,既大有潜力也颇具危险性
-
1.2.1. 可以快速确定一个人的兴趣
-
1.2.2. 用来准确构建一系列应用的预测模型,从移动广告、信用评分到预测人格特质
-
1.2.3. 用于再识别
1.3. 分组法可以将安特卫普地区的所有位置聚合到一个超级位置“安特卫普”,或者将书店中所有的唯一账号聚合到一个单一的“书店”账号
1.4. 隐匿法可以移除所有发生低于特定频率的独特行为
1.5. 在预测模型中,使用这两种缩减法很可能降低预测模型的性能
1.6. 基于电影评分的再识别
- 1.6.1. 仅仅通过消除个人身份标识符的手段并不一定能实现数据集的匿名化
1.7. 基于搜寻查询的再识别
-
1.7.1. 数据具有细粒度和显露性,可以使某些用户的身份被再识别
-
1.7.2. 缩短数据的储存时间以及限制并记录数据的访问途径也能起到不小的作用
-
1.7.3. 需要使用现实生活中的数据改进和验证算法来提高科研能力
-
1.7.4. 数据中所包含的个人和敏感数据需要有一定的比例,而且获取这些数字也需要一定的途径,我们必须再一次在上述两者之间找到平衡点
1.8. 基于位置信息的再识别
-
1.8.1. 定位数据是一种丰富的数据源,它广泛用于研究领域和商业(主要是应用程序)目的
-
1.8.2. 定位数据是所有的行为数据中最具敏感性的一种数据,你所去过的地方可以轻易地暴露你的身份
-
1.8.3. 仅仅知道用户身份就已经令人不安了,糟糕的是会因此引发一些违背伦理甚至非法的行为,比如敲诈
-
1.8.4. 不仅应用程序会追踪用户地址,电信运营商通过相连运营商天线的三角定位也可以追踪用户地址
-
1.8.5. 研究结果表明,通过4个时空点(了解一小时内的访问位置和时间)足以对95%的用户进行唯一识别
- 1.8.5.1. 将数据聚合到一个粗粒度级别的位置(通过聚合两个天线的接收区域)和时间(使用一个增加小时数的窗口),并不能具有更多的匿名性
-
1.8.6. 要确保任何人都不可识别
-
1.8.7. 要避免泄露任何令人不安或者具有敏感性的信息
-
1.8.8. 出租车出行的数据
1.9. 仅仅通过消除设备号、IP地址或者姓名不会使数据保持匿名状态,在涉及行为数据时更是如此
-
1.9.1. 此类数据会暴露个人身份以及揭露令人不安的事实
-
1.9.2. k-匿名的概念降低了细粒度行为数据的效用,使其无法做出预测和推荐,或仅仅是寻找有趣的模式
-
1.9.3. 在假设行为数据具有匿名性、去除了姓名和地址等个人标识符的情况下,人们也应该避免公开披露行为数据
1.10. 此类数据益处多多:它能够促进科学研究,提高透明度,推动社会发展
-
1.10.1. 只有与可信的研究小组合作并在签署数据保护和保密协议之后才可以共享数据
-
1.10.2. 如果需公布此类数据的一般统计数据,建议使用差分隐私
2. 定义和选择变量
2.1. 输入选择
-
2.1.1. 输入选择涵盖了之前的所有问题和方法,其目的是确保尊重个人隐私,并尽量避免歧视敏感群体
-
2.1.2. 要把资料最小化考虑在内
-
2.1.3. 隐私与效用之间需有所取舍
-
2.1.4. 如果我们不想基于某些敏感属性而区别对待不同的人,那么我们就不应将这些变量作为输入变量之一
-
2.1.5. 需要使用这些属性衡量和消除对这些敏感群体的偏见,同时我们还要注意这些变量的代理服务器
2.2. 定义目标变量
- 2.2.1. 定义目标变量通常有一定的主观性,因此需要谨慎考虑其商业和伦理影响
3. 人脸识别
3.1. 人脸识别技术使用数据科学软件在人脸图像数据集中找到与人脸匹配的图像
3.2. 作为一种数据科学应用技术,人脸识别技术带来了大量的伦理问题,究其原因,一方面是生物数据具有敏感性,另一方面是在我们生活中存在大量潜在应用和误用现象
3.3. 支持者认为人脸识别技术可以用来打击犯罪,寻找失踪人员以及防止身份盗用
3.4. 人们主要担心的隐私问题是未获本人知情同意,甚至在本人未曾意识到情况下使用该技术
- 3.4.1. 在不同的环境下使用电视摄像机捕捉面部图像,需要不同的隐私保障
3.5. 第二个伦理问题是预测模型会犯错误
- 3.5.1. 令人担忧的主要是误报现象,即因为人脸识别技术故障而被误认为与犯罪嫌疑人人脸相匹配而受到警察盘问
3.6. 第三个问题是“功能蠕变”
-
3.6.1. 功能蠕变指技术实际使用的目的与设计目的不符
-
3.6.2. 扩大数据集,使之包含政治活动家、记者、公民等图像
-
3.6.3. 在较长一段时间内使用软件跟踪个人,查看其到访之地
-
3.6.4. 允许其他组织和个人(如公司或个人经营者)访问该系统
3.7. 数据收集和数据部署显然会引发伦理问题
3.8. 公用数据并不意味着人们可以免费复制数据
3.9. 一旦我们确定数据和技术的合法性、结果的准确性、对执法的价值性,我们会认为那些值得信任或承担审计工作的国家组织和公司在明确其工作职责和受到严格监督的前提下有权使用这些数据和技术
- 3.9.1. 其他人可能会觉得将人脸识别技术用于对公众的监控极大地侵犯了公民的隐私权
4. 公平的新定义
4.1. 衡量数据集的公平性
-
4.1.1. 若要在数据集中消除偏见,我们首先要确定如何定义这份数据集中对敏感群体的歧视或者偏见的程度
-
4.1.2. 查看目标变量
- 4.1.2.1. 正确定义目标变量并考虑可能含有的历史偏见至关重要
4.2. 数据篡改
-
4.2.1. 历史数据集中的数据可能有歧视敏感群体的倾向
-
4.2.2. 通过数据篡改,可以获得一份歧视值为(接近)零的数据集,同时不会对数据集进行太多更改,从而接近原始数据集,并确保模型在真实情景中的准确性
-
4.2.3. 另两种预处理方法
-
4.2.3.1. 无论是否属于敏感群体,均可基于观测和预期的雇佣概率的不同来衡量每个案例
-
4.2.3.2. 这些权重可用于处理加权实例的分类算法(“重新加权”法),或重新对数据集(“采样”法)采样
-
4.3. 两种有关数据公平的主要方法:统计均等和差别性影响
-
4.3.1. 为了消除数据集中的历史偏差,我们可以处理目标变量—通过将受负面歧视的群体的目标变量更改为正面结果,反之亦然
-
4.3.2. 通过处理实例层,为这些受负面歧视的群体提供更多的权重或进行过度抽样,同时对其他群体提供更少的权重,或按照采样不足的方式计算
4.4. 从历史数据中去除偏见,其优势之一是可以继续使用许多技术和分析
4.5. 确保建模阶段的公平性将使技术研究更加具有针对性
5. 偏见性语言
5.1. 预测模型对不公平的数据科学无能为力
5.2. 即使可以信任文本来源,也要注意隐藏的偏见及其数据科学对数据的影响
5.3. 语言偏见不仅存在于谷歌新闻的文章中

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









