






一、预备知识
流量矩阵的定义:流量矩阵(traffic matrix)反映了一个网络中所有源节点和目的节点对之间的流量需求。它捕获网络流量的全局状态,对于负载均衡、路由优化、流量侦测和网络规划等方面至关重要。由于直接监控代价高,间接观测进行流量矩阵估算成为一个研究热点。
流量矩阵的估算方法:研究中提到了基于RBF(Radial Basis Function)神经网络的流量矩阵估计方法TMRI(Traffic Matrix Recurrence Inference),该方法利用RBF神经网络的建模功能来克服流量矩阵估计问题的病态特性,并通过迭代寻优进一步改善估计的准确性。流量矩阵的表示:流量矩阵的行对应于OD对(起源和目的地对),列对应于不同时刻的流量需求。矩阵A是一个0-1矩阵,表示如果OD对之间的流量经过链路,则相应位置为1;否则为0。流量矩阵、路由矩阵和链路负载之间的关系可以表示为Y=AX,其中Y是链路流量值,X是OD对的流量矩阵。
深度Q学习(Deep Q-Learning,简称DQN):
是指基于深度学习的Q-Learing算法。Q-Learing算法维护一个Q-table,使用表格存储每个状态s下采取动作a获得的奖励,即状态-价值函数Q(s,a),这种算法存在很大的局限性。在现实中很多情况下,强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情况就不能再使用表格的方式存储价值函数。
为了解决这个问题,我们可以用一个函数Q(s,a;w)来近似动作-价值Q(s,a),称为价值函数近似Value Function Approximation,我们用神经网络来生成这个函数Q(s,a;w),称为Q网络(Deep Q-network),w是神经网络训练的参数。
参考:https://blog.youkuaiyun.com/niulinbiao/article/details/133690617
经验回放:DQN使用经验回放来存储和重用过去的经验,这有助于打破样本之间的相关性,并提高数据的利用率。
目标网络:为了稳定学习过程,DQN维护两个Q网络——一个是在线网络(用于决策),另一个是目标网络(用于生成目标Q值)。目标网络的参数定期从在线网络复制,这有助于减少训练过程中的不稳定性。
二、论文部分
题目:DRSIR:软件定义网络中路由的深度强化学习方法
创新点:
在SDN中增加了知识平面;采用路径状态指标(如路径带宽、延迟、丢包率);设计含拓扑、监测、处理、路由和安装模块的 DRL 路由架构
Abstract
DRSIR考虑路径状态度量来产生主动、高效和智能的路由,以适应动态流量变化。
1 Introduction
2 Related Works
3 Method
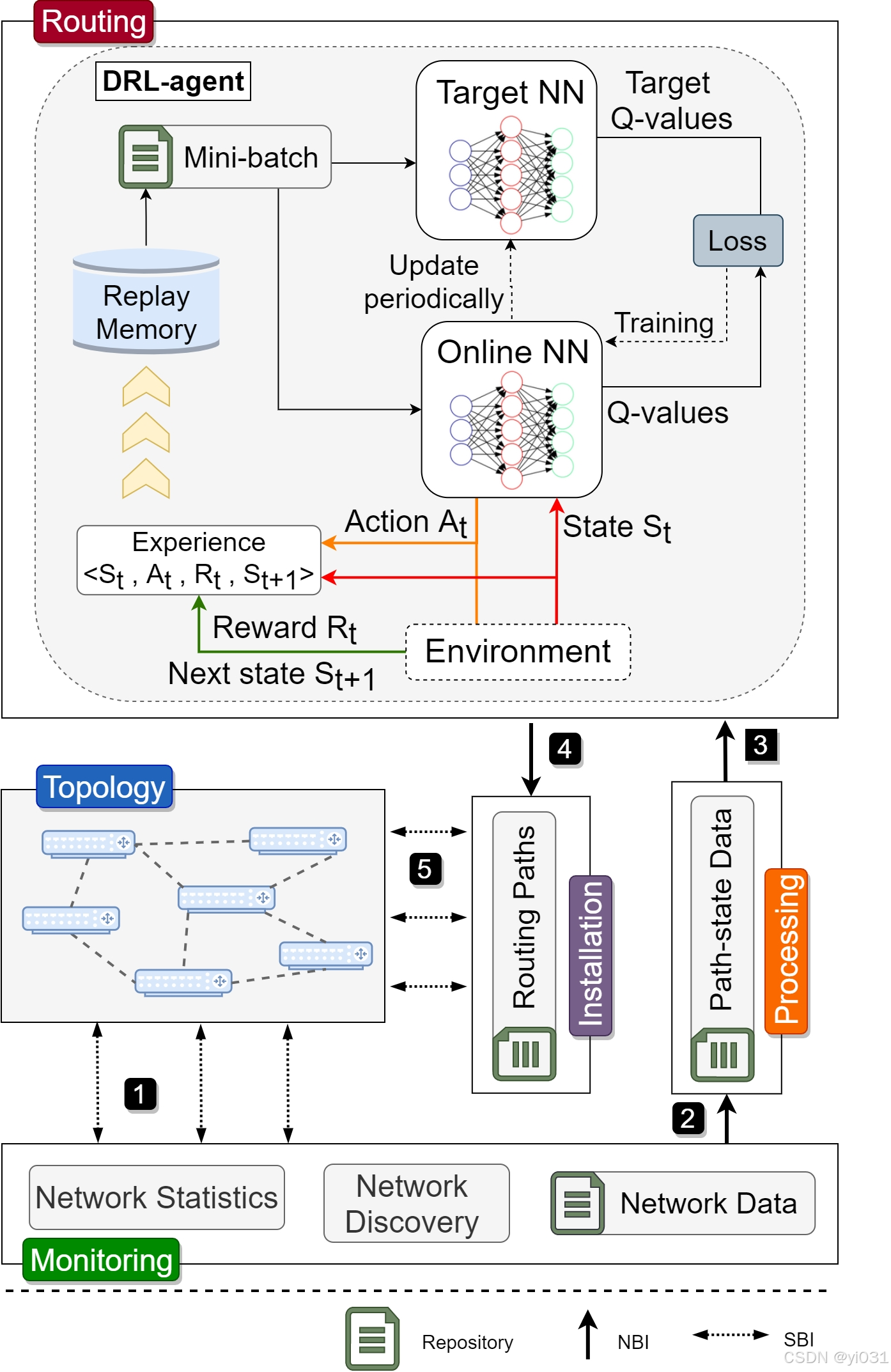
核心:
- 使用深度Q网络(DQN)作为DRL代理,包括在线神经网络(Online NN)、目标神经网络(Target NN)和经验回放记忆(Replay Memory)。
- 通过ε-greedy方法进行探索和利用,以平衡探索新路径和利用已知信息
拓扑模块(Topology Module):
- 这个模块代表了网络中的物理设备,如交换机和路由器。
- 它响应查询请求,并提供网络的统计信息,如端口状态和链路信息。
- 这些信息被用来构建网络的拓扑图,这是网络中设备和连接的物理布局。
监控模块(Monitoring Module):
- 负责收集网络的实时统计数据,如流量负载和链路状态。
- 通过定期发送和接收状态消息,监控网络的拓扑变化,如新增或失效的链路。
处理模块(Processing Module):
- 从监控模块接收原始数据,并计算路径状态度量(path-state metrics),如路径带宽、延迟和丢包率。
- 这些度量被用作DRL代理的输入特征,帮助代理学习网络的行为并做出路由决策。
路由模块(Routing Module):
- 包含DRL代理,该代理使用深度Q网络(DQN)来学习网络状态和选择最优路径。
- 代理通过与环境的交互来学习,目标是最小化路径成本,这通常包括最大化带宽利用率、最小化延迟和丢包率。
安装模块(Installation Module):
- 负责将路由模块计算出的最优路径转换成流表项,并在网络中的设备上安装这些流表项。
- 这个模块确保网络流量按照计算出的最优路径进行转发。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









