








 本文深入讲解Python中的列表切片[::-1]使用技巧,演示如何高效处理DataFrame对象进行数据统计与运算,包括应用apply()和applymap()方法进行数据处理,以及正则表达式的使用。
本文深入讲解Python中的列表切片[::-1]使用技巧,演示如何高效处理DataFrame对象进行数据统计与运算,包括应用apply()和applymap()方法进行数据处理,以及正则表达式的使用。
NLP资料PDF链接

python 中的[::-1]
for value in rang(10)涉及的数字倒序输出:
for value in rang(10)[::-1]涉及的数字倒序输出:
二、详解
这个是python的slice notation的特殊用法。
a = [0,1,2,3,4,5,6,7,8,9]
b = a[i:j] 表示复制a[i]到a[j-1],以生成新的list对象
b = a[1:3] 那么,b的内容是 [1,2]
当i缺省时,默认为0,即 a[:3]相当于 a[0:3]
当j缺省时,默认为len(alist), 即a[1:]相当于a[1:10]
当i,j都缺省时,a[:]就相当于完整复制一份a了
b = a[i:j:s]这种格式呢,i,j与上面的一样,但s表示步进,缺省为1.
所以a[i:j:1]相当于a[i:j]
当s<0时,i缺省时,默认为-1. j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。
计算字符串中出现频次最多的字符

我们经常会对DataFrame对象中的某些行或列,或者对DataFrame对象中的所有元素进行某种运算或操作,我们无需利用低效笨拙的循环,DataFrame给我们分别提供了相应的直接而简单的方法,apply()和applymap()。其中apply()方法是针对某些行或列进行操作的,而applymap()方法则是针对所有元素进行操作的。
我们给出具体的例子看这两个方法是怎么工作的,代码入下。首先我们构造一个(3,4)的DataFrame对象df1,然后我们想对每列进行求和,便可以利用apply()方法结合匿名函数lambda实现。apply()方法中的第一个参数是函数,这里我们传递了一个匿名函数给apply(),当然我们还可以通过axis参数指定轴,比如这里我们可以令axis=1,则就会返回每行的求和,这里默认axis=0。
然后如果我们想对df1中的每个元素进行操作,比如这个例子中我们是想让每个元素只保留两位小数,那么可以通过applymap()方法实现。applymap()方法就是针对元素级的方法,比如在in[20]中,我们通过给applymap()方法传递一个格式化表达的匿名函数,通过applymap()方法将这个函数应用到每个元素上以实现我们的目标。这里之所以叫applymap()方法,是因为在Series中有一个对元素级操作的map()方法,参数也为函数。
当然,一些常用的运算和统计方法,DataFrame都是自己定义了的,因此我们不用自己再构造匿名函数。但是一般的,DataFrame自己的运算方法都是针对所有的行或所有列的,具体是行还是列可以通过axis参数指定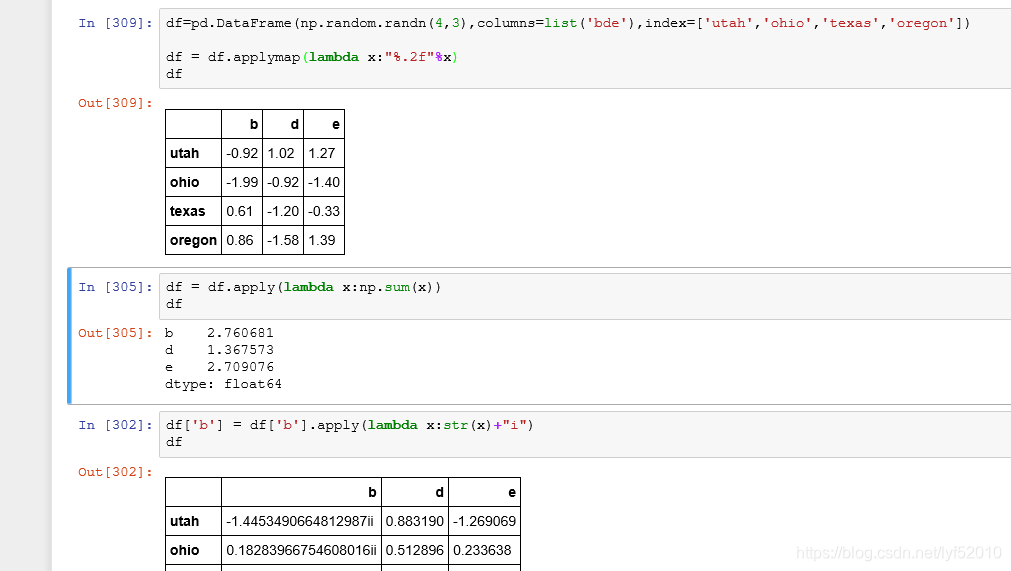
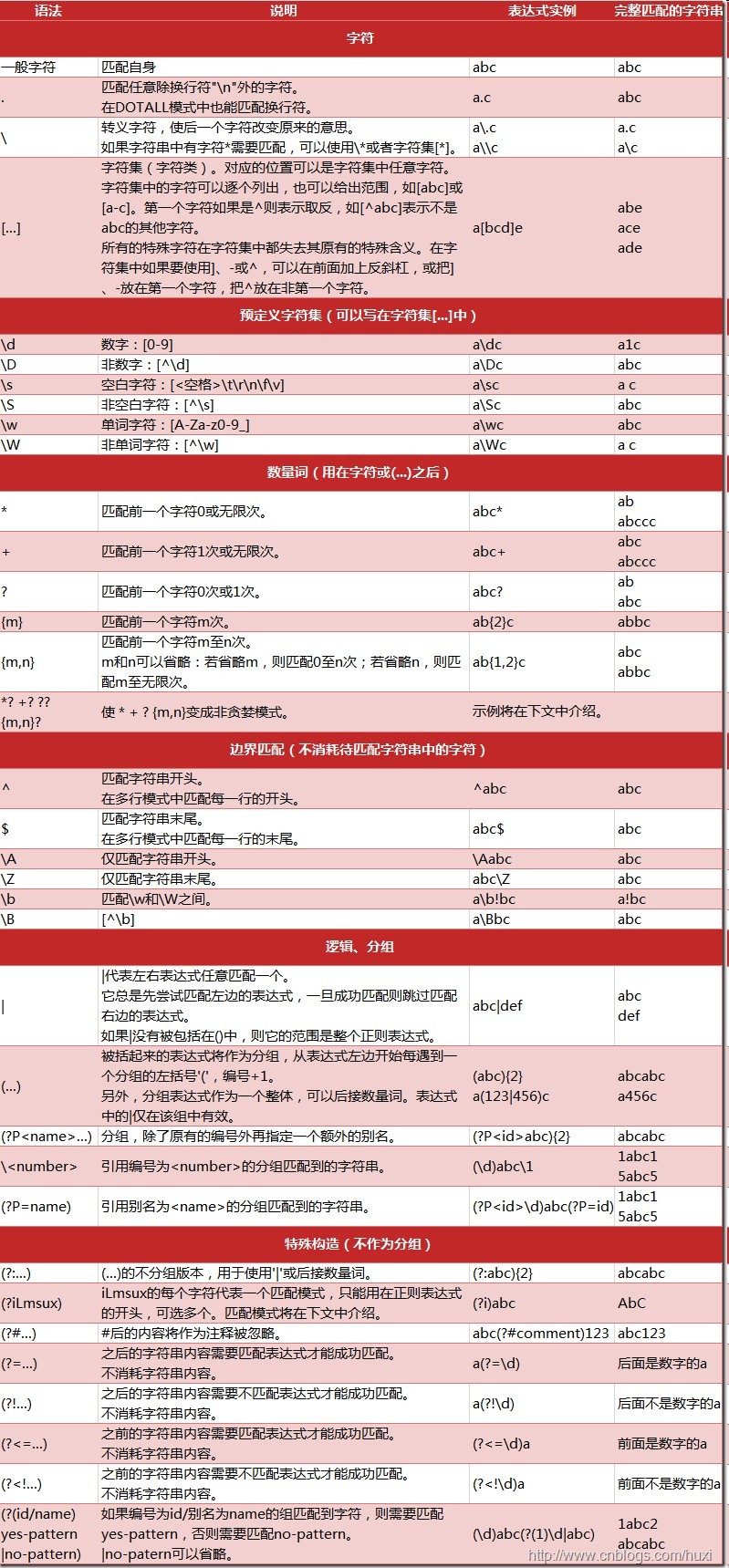
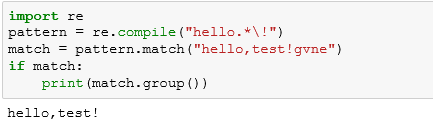
正则表达式
***************************


















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









