




 本文档详细介绍了如何在Ubuntu16.04环境下进行Spark的伪分布式安装,包括Scala的安装、Spark的下载与配置,以及启动和检查进程的步骤。在安装前,需要确保已安装了与Spark版本对应的Hadoop。
本文档详细介绍了如何在Ubuntu16.04环境下进行Spark的伪分布式安装,包括Scala的安装、Spark的下载与配置,以及启动和检查进程的步骤。在安装前,需要确保已安装了与Spark版本对应的Hadoop。
环境:Ubuntu16.04
在伪分布式安装spark之前,首先需要伪分布式安装配置Hadoop,这个就不做详细介绍了,可以参看博主的另一篇博客:
https://blog.youkuaiyun.com/lyc0424/article/details/101078489
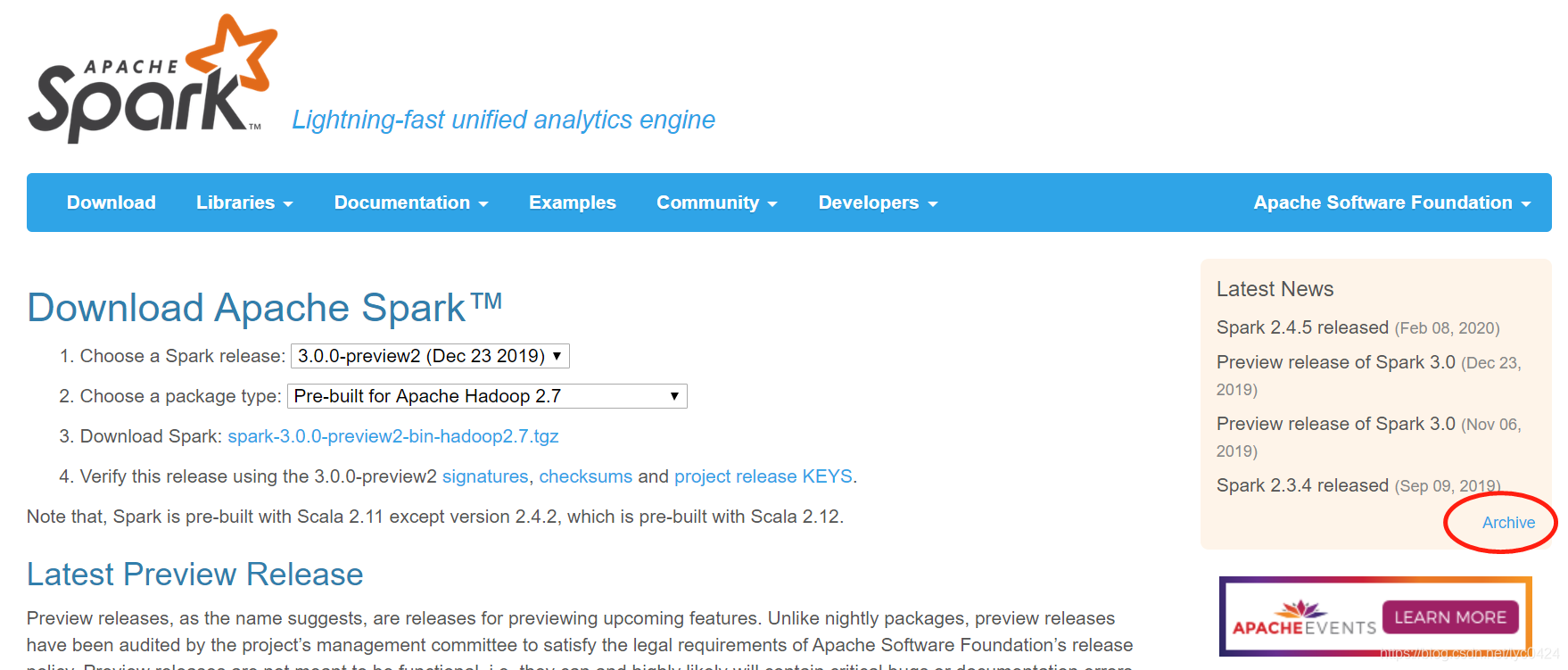
spark下载地址:http://spark.apache.org/downloads.html
注意:安装的spark版本需要与之前安装的hadoop版本对应,由于我之前安装的hadoop版本是2.6.0,所以此处我下载的安装包需要对应hadoop2.6.0这个版本,此处我下载的是spark-2.3.4-bin-hadoop2.6.tgz
要安装旧版本的spark可以点击下图中红圈处去寻找
Scala安装:
下载地址:https://www.scala-lang.org/download/2.11.8.html
使用管理员权限解压scala
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









