



1、Ollama简介
Ollama 是一款开源的大型语言模型(LLM)服务工具,旨在简化大语言模型的本地部署和使用流程。它支持在 Windows、Linux 和 macOS 上运行,能够快速部署包括 Llama、Falcon、Qwen 等在内的 1700+ 大语言模型,满足不同用户的需求。Ollama 提供了丰富的功能,包括本地运行、多模型支持、自定义模型配置、多 GPU 并行推理以及兼容 OpenAI 接口等。用户可以通过简单的命令行操作或图形界面进行模型的下载、启动和管理,同时还可以利用其 API 接口将模型集成到各种应用程序中。
2、Ollama安装
(1)下载
通过Ollama官网下载链接选择自己的需要的系统进行下载
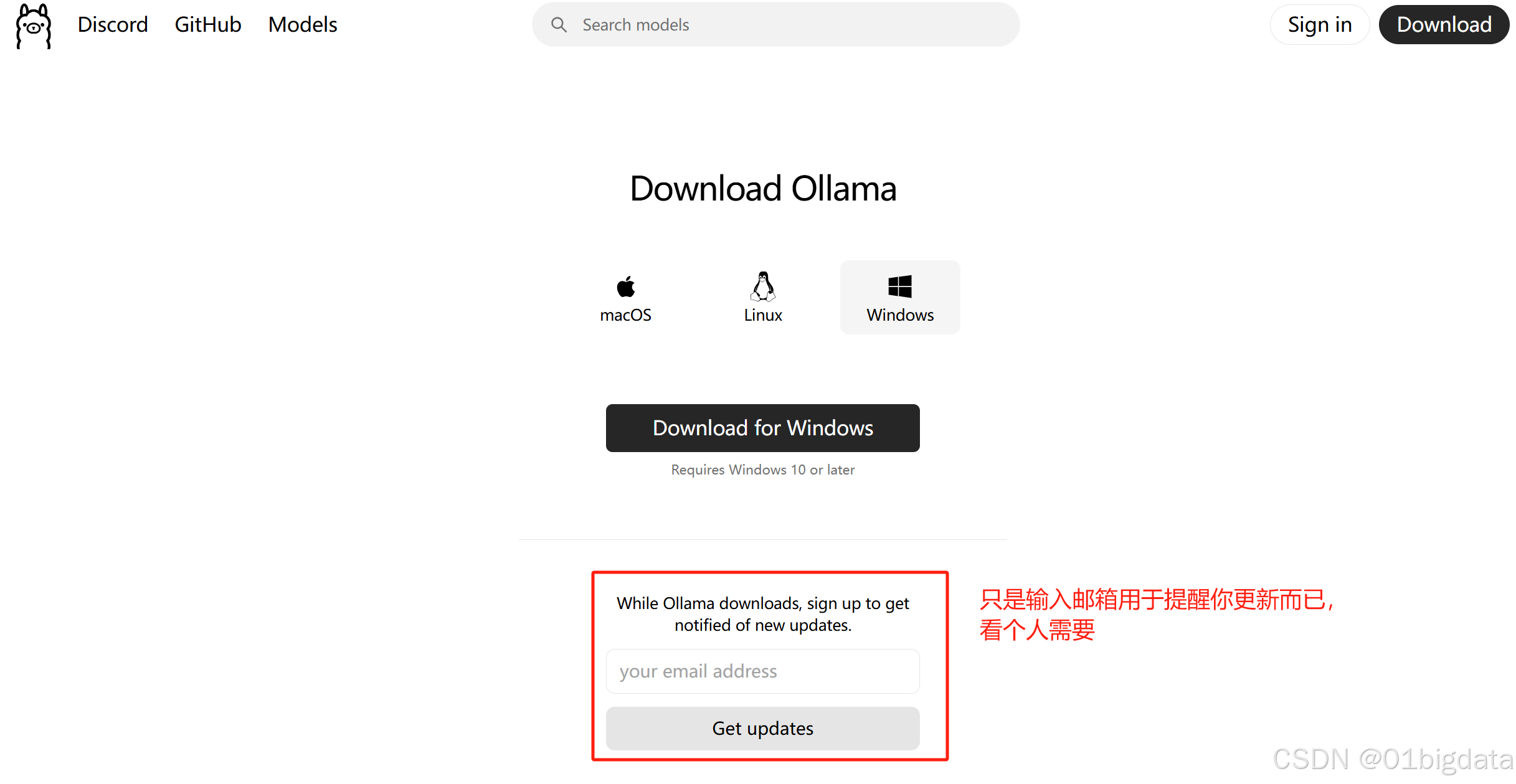
(2)安装
在安装的时候,默认是会下载系统目录上,
(可选择步骤)如果想把Ollama下载到别的盘上,打开cmd(Win键+R键),
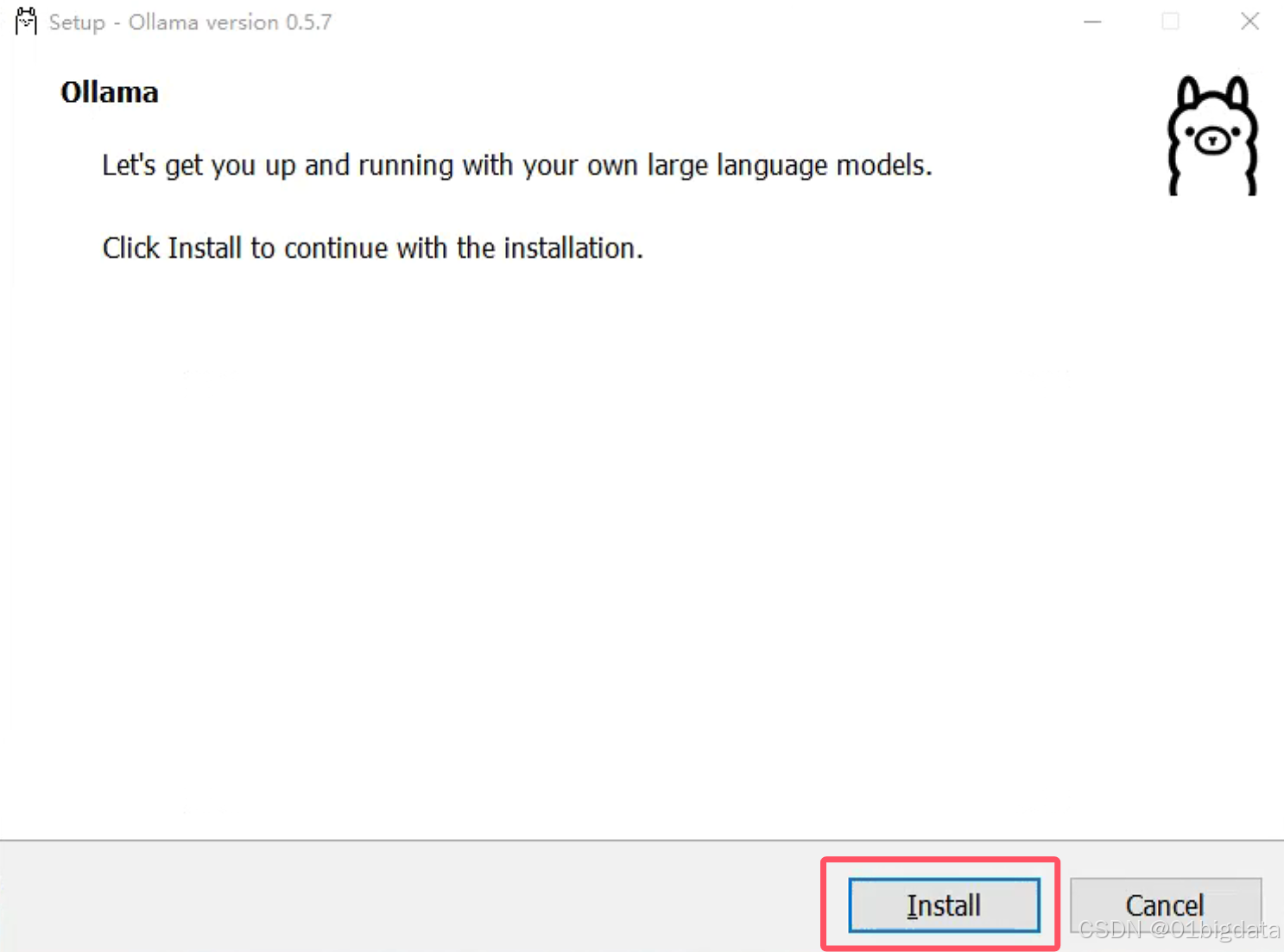
先进到你下载的OllamaSetup.exe的目录上(这里例子是:C:\Users\Administrator\Downloads,根据你的实际需要更改)
cd C:\Users\Administrator\DownloadsOllamaSetup.exe /DIR="d:\ollama"之后跳出来安装页面,点击Install,等待一段时间后就安装好啦
同时要更改你下载模型的位置,要记得编辑一下系统环境变量(文档里好像是说可以用账户,但是没做过,待大佬解答)
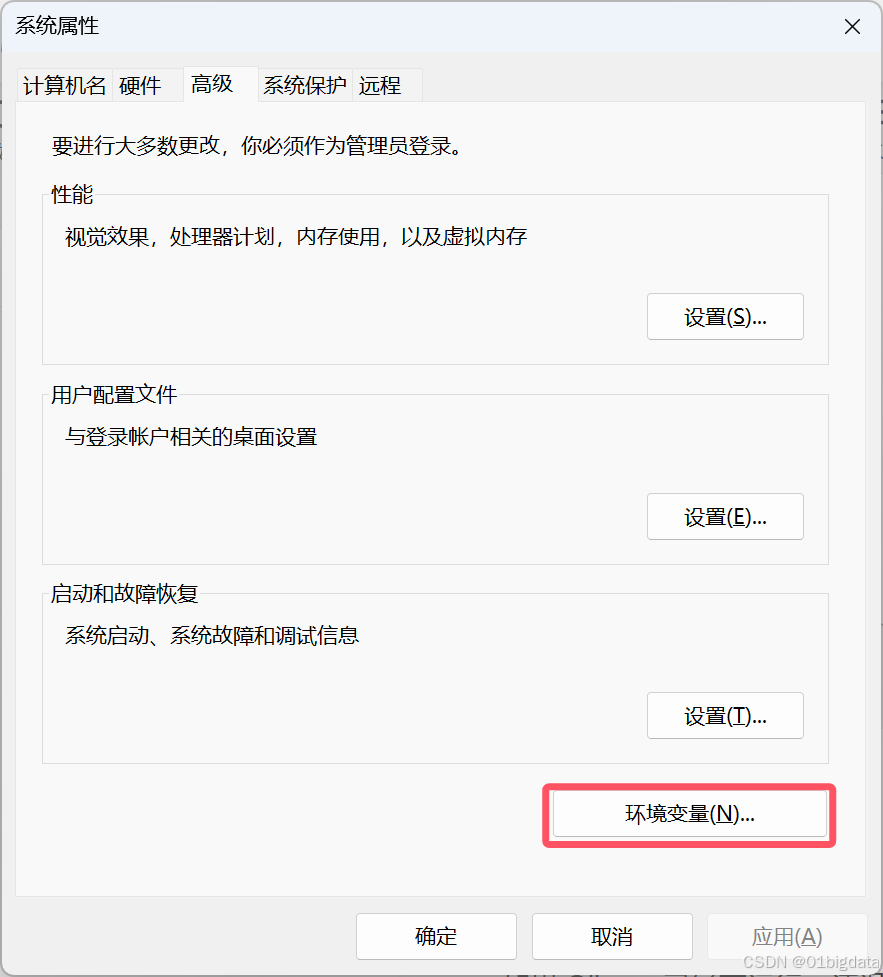
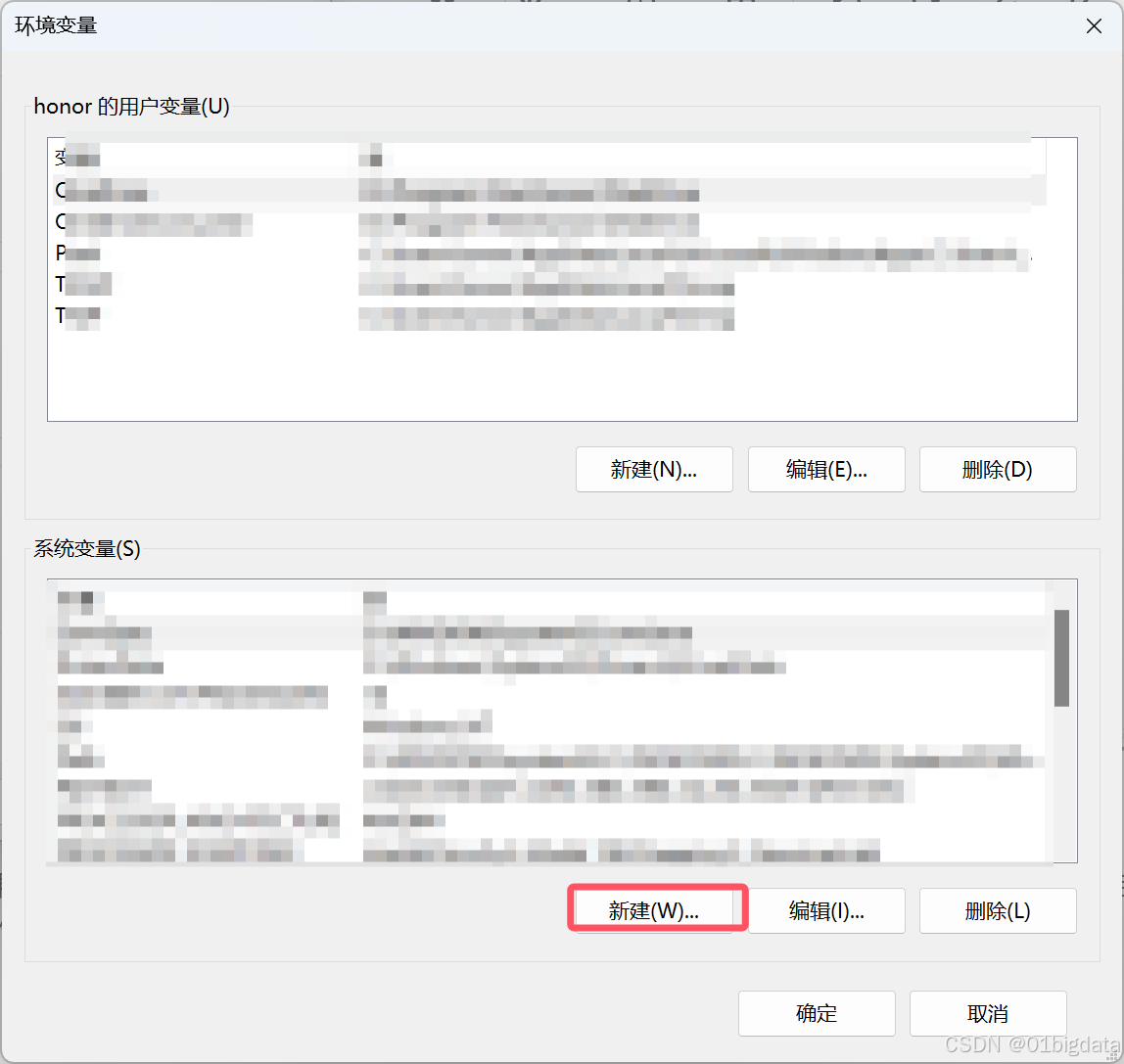
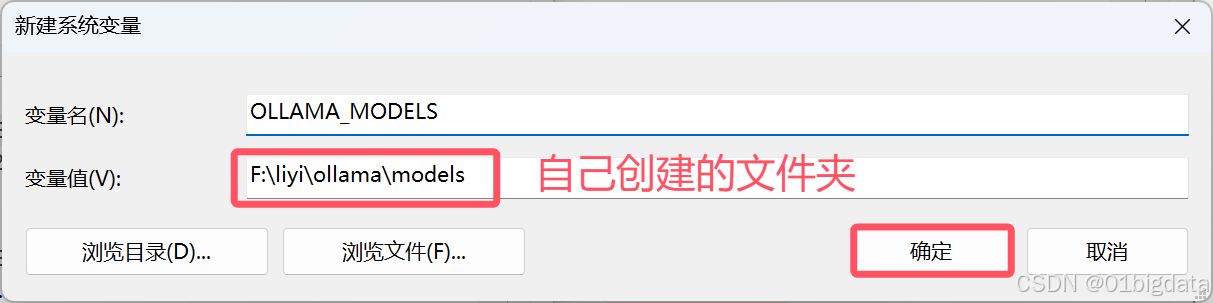
记得要确定保存一下
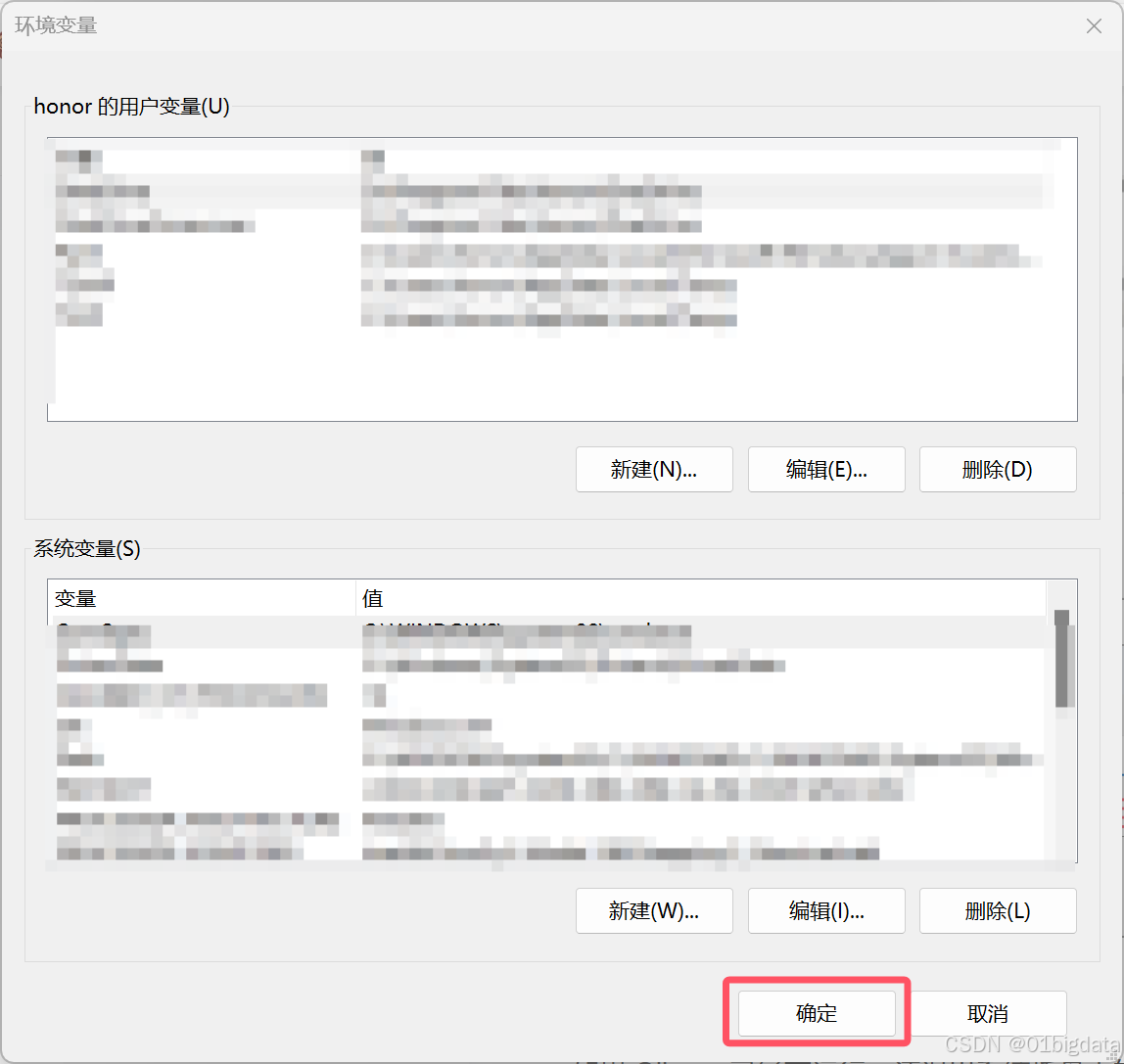
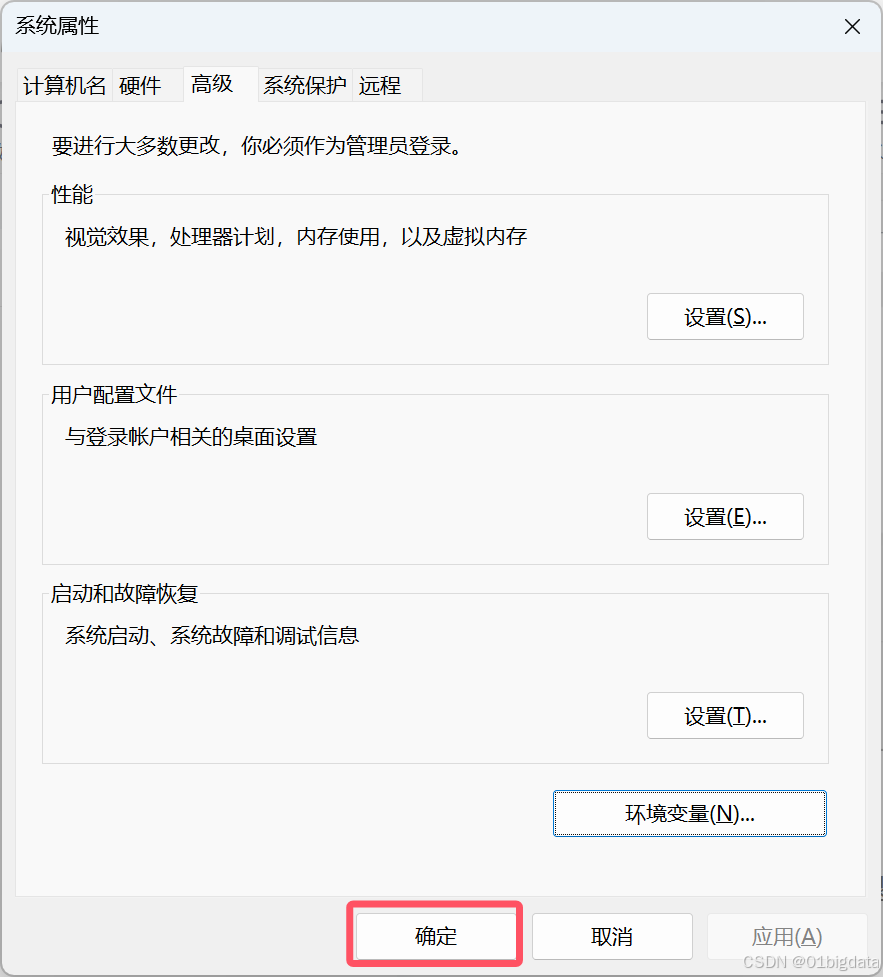
如果 Ollama 已经在运行,请退出系统托盘中的应用程序,然后从开始菜单或在保存环境变量后启动的新终端中重新启动它。
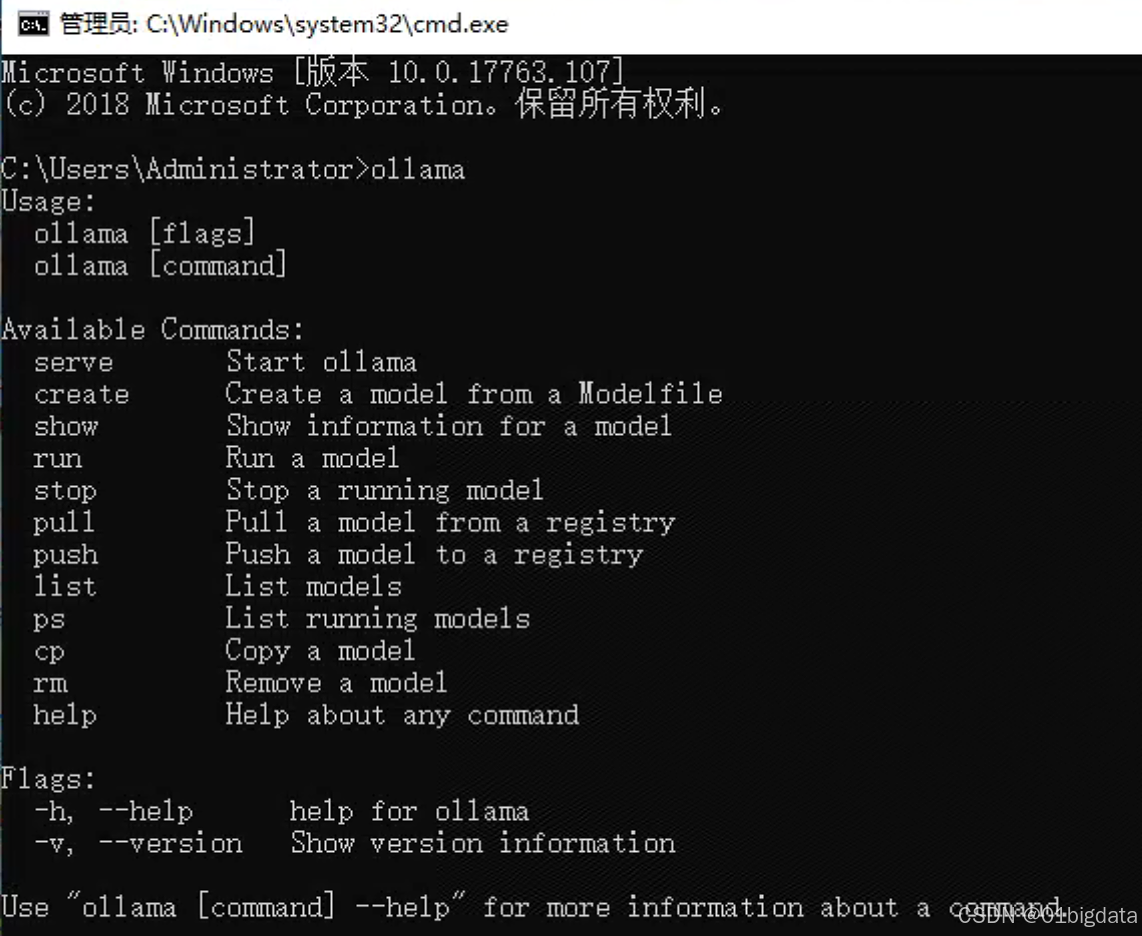
(3)验证安装
安装完成后,打开命令提示符(cmd)并输入ollama来验证Ollama是否安装成功。如果安装成功,你将看到Ollama的启动界面。
3、导入模型
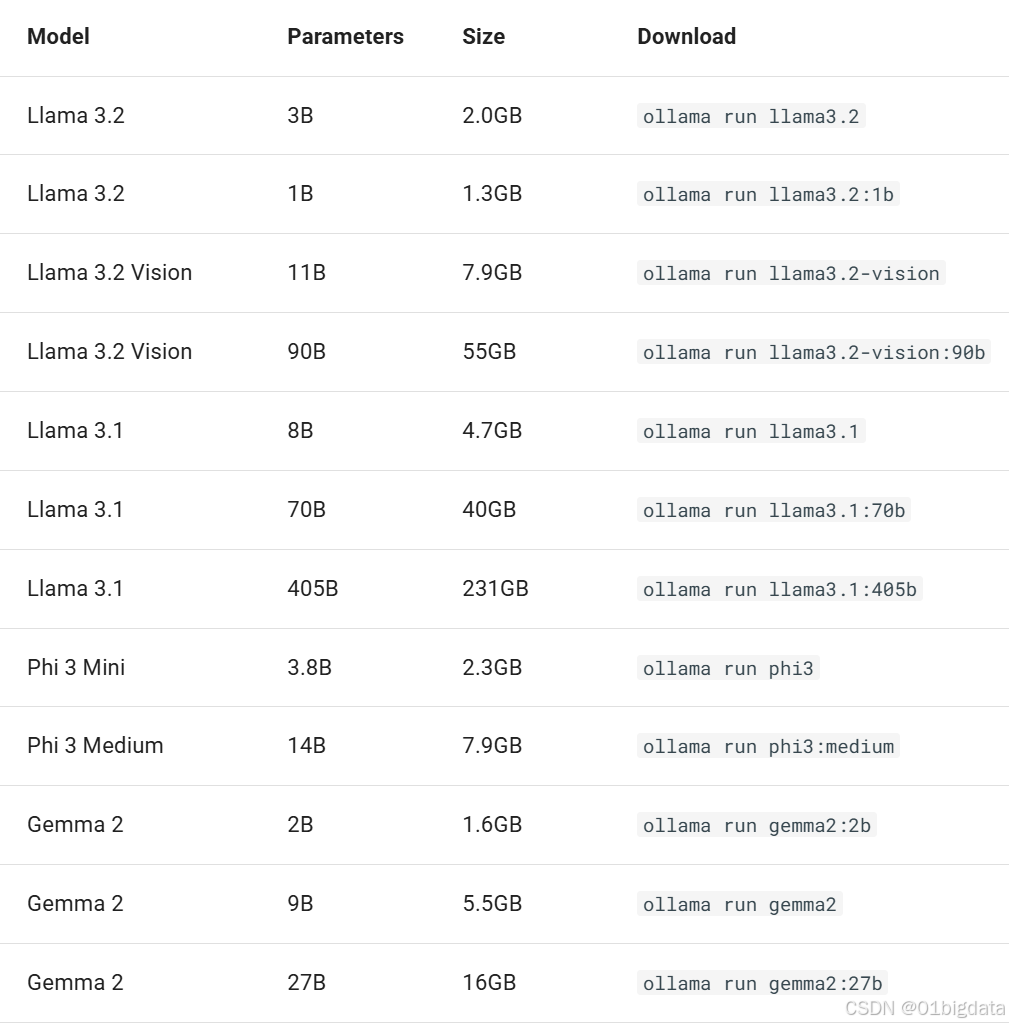
Ollama 支持在Ollama模型库上提供的模型列表。(下面表格是从中文文档上截图的)
本文采用的是deepseek-r1模型,读者也可以选择其他的模型进行下载
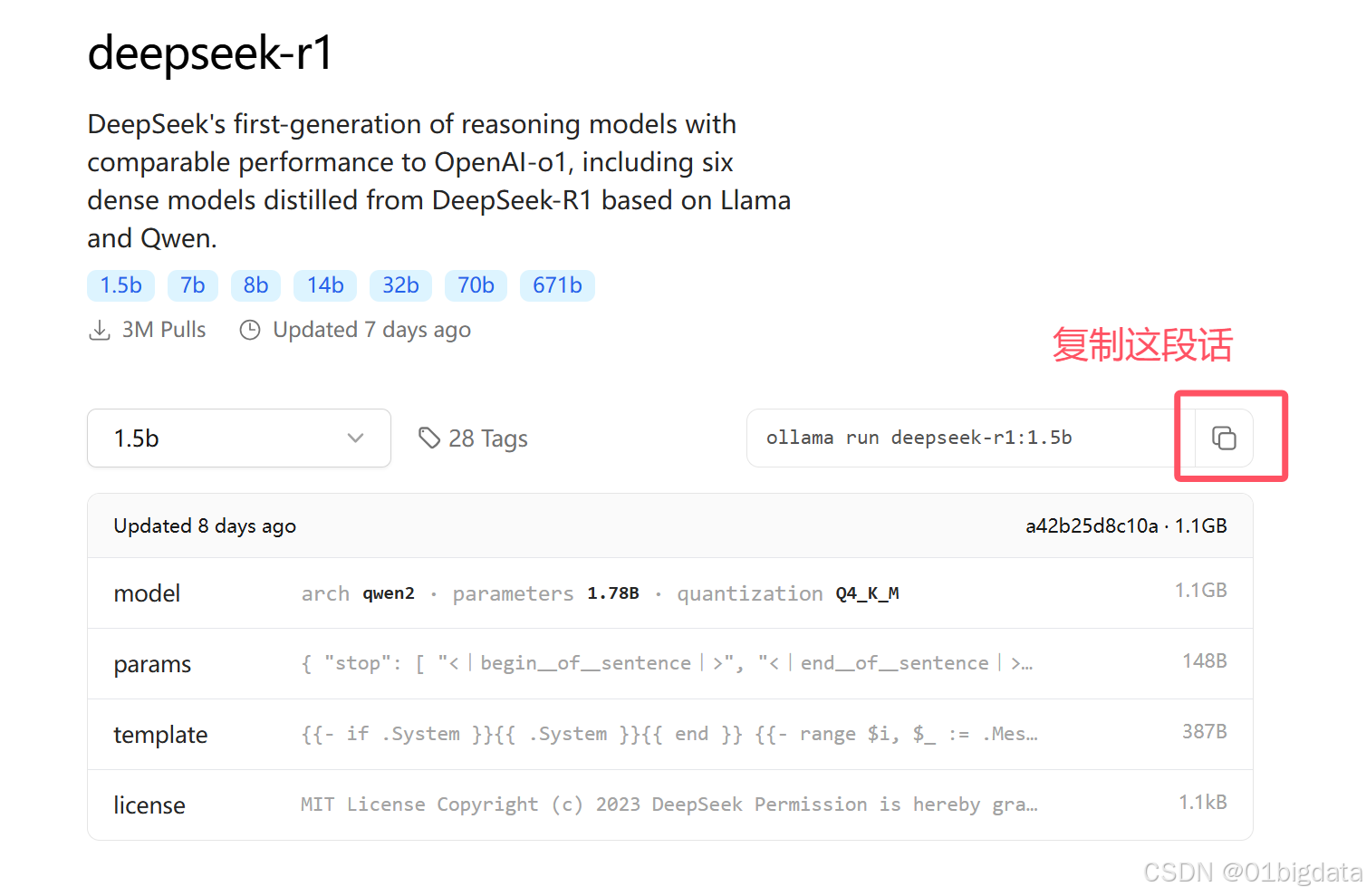
再次打开cmd,粘贴上去
ollama run deepseek-r1:1.5b等待下面导入好
就可以开始对话啦


4、python库导入
(1)安装python库
打开你的终端输入下面的代码,进行安装
pip install ollama安装好了以后,下面是简单的示例代码
1)示例代码
from ollama import chat
from ollama import ChatResponse
#model是可更改的,根据你的实际需要进行修改
response: ChatResponse = chat(model='deepseek-r1:1.5b', messages=[
{
'role': 'user',
'content': '人工智能是什么', #你的问题
},
])
print(response['message']['content'])
# or access fields directly from the response object
#print(response.message.content)输出的结果如下图所示

查看属性还有一些其他的参数,如模型、产生时间、是否完成等等,但是最主要的还是回应的内容

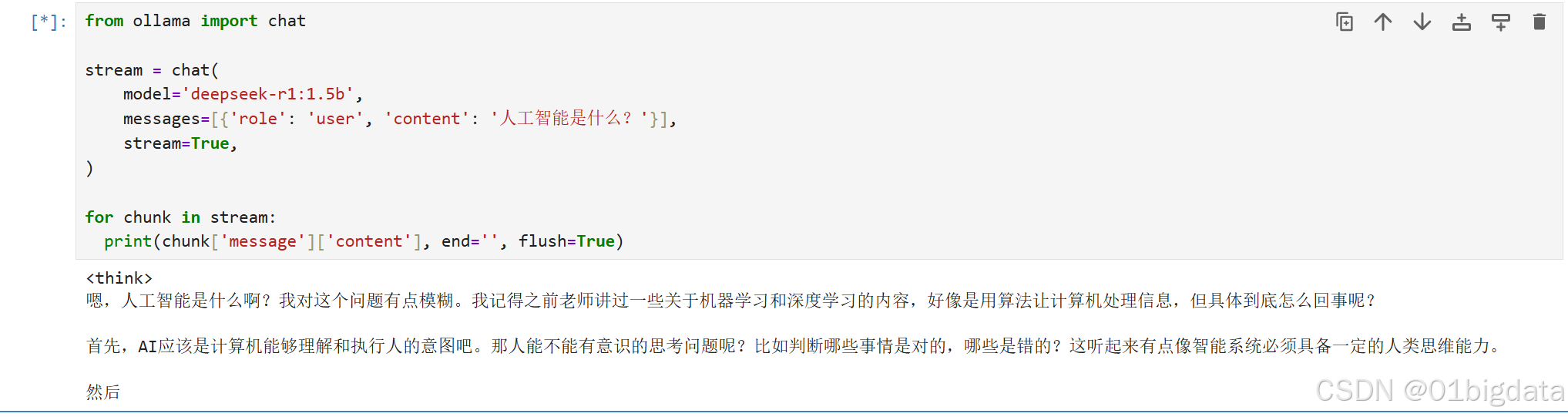
2)流式回应
个人认为流式回应就是一个字一个字的输出,而不是像上面的代码一样,直接全部一起输出,在终端里问问题,模型回应的时候就是用流式输出
from ollama import chat
stream = chat(
model='deepseek-r1:1.5b',
messages=[{'role': 'user', 'content': '人工智能是什么?'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)输出:
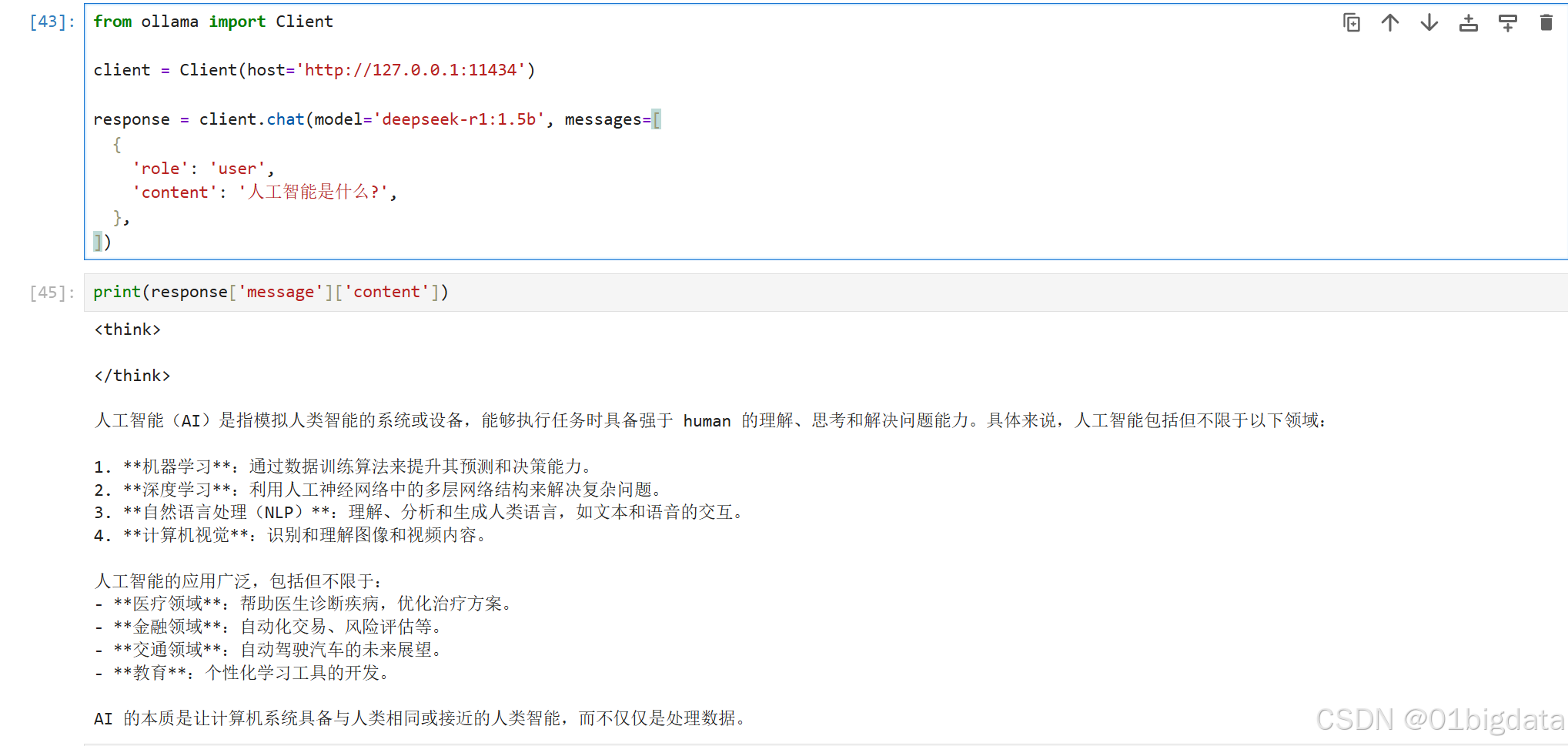
3) Client客户端
可以通过从 ollama 实例化 Client 或 AsyncClient 来创建自定义客户端
所有额外的关键字参数都传递到httpx.Client中
from ollama import Client
client = Client(host='http://127.0.0.1:11434')
response = client.chat(model='deepseek-r1:1.5b', messages=[
{
'role': 'user',
'content': '人工智能是什么?',
},
])输出:
如果访问是503,需要重启ollama,在终端输入
ollama serve直到如下图所示启动

(2)使用API
前面的3)方法,实际上也是通过api进行访问
1)ollama serve运行
import requests
import json
# API的URL
url = 'http://127.0.0.1:11434/api/chat'
input_text = "人工智能是什么?"
# 要发送的数据
data = {
"model": "deepseek-r1:1.5b",
"messages": [
{"role": "user","content": " "}
],
"stream": False
}
# 找到role为user的message
for message in data["messages"]:
if message["role"] == "user":
# 将输入文本添加到content的开头
message["content"] = input_text
# 将字典转换为JSON格式的字符串
json_data = json.dumps(data)
# 发送POST请求
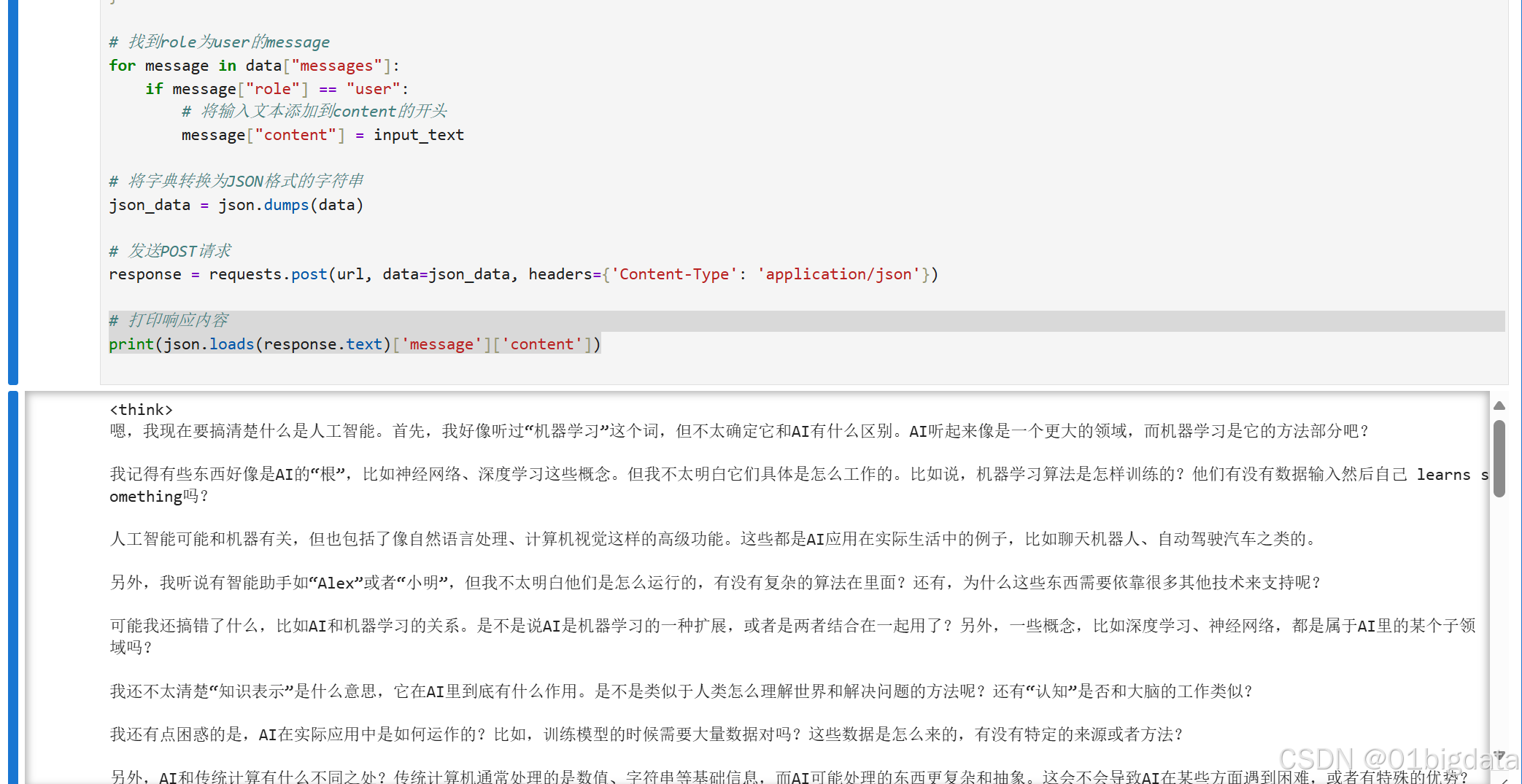
response = requests.post(url, data=json_data, headers={'Content-Type': 'application/json'})
# 打印响应内容
print(json.loads(response.text)['message']['content'])
输出:
在参考连接的快速入门 - Ollama 中文文档里有api的参考,可以通过这个,来进行更多的互动,在多模态的大模型中也可以传入图片
(文章后续还会进行更新,针对文档推荐的UI,大家感兴趣可以取看看GitHub或者我下面给的中文文档)
参考链接:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











