







 本文深入探讨了Kotlin如何通过编译过程支持Java不具备的特性,如类型推断、高阶函数、扩展函数、内联函数、可空性检查。同时,详细介绍了Kotlin的函数式编程特性,如函数式编程概念、闭包、柯里化、尾递归优化,以及在Kotlin中如何应用这些概念。通过对元数据解析的理解,揭示了Kotlin如何保证与其他JVM语言互操作性。
本文深入探讨了Kotlin如何通过编译过程支持Java不具备的特性,如类型推断、高阶函数、扩展函数、内联函数、可空性检查。同时,详细介绍了Kotlin的函数式编程特性,如函数式编程概念、闭包、柯里化、尾递归优化,以及在Kotlin中如何应用这些概念。通过对元数据解析的理解,揭示了Kotlin如何保证与其他JVM语言互操作性。
都是编译成字节码,为什么 Kotlin 能支持 Java 中没有的特性?
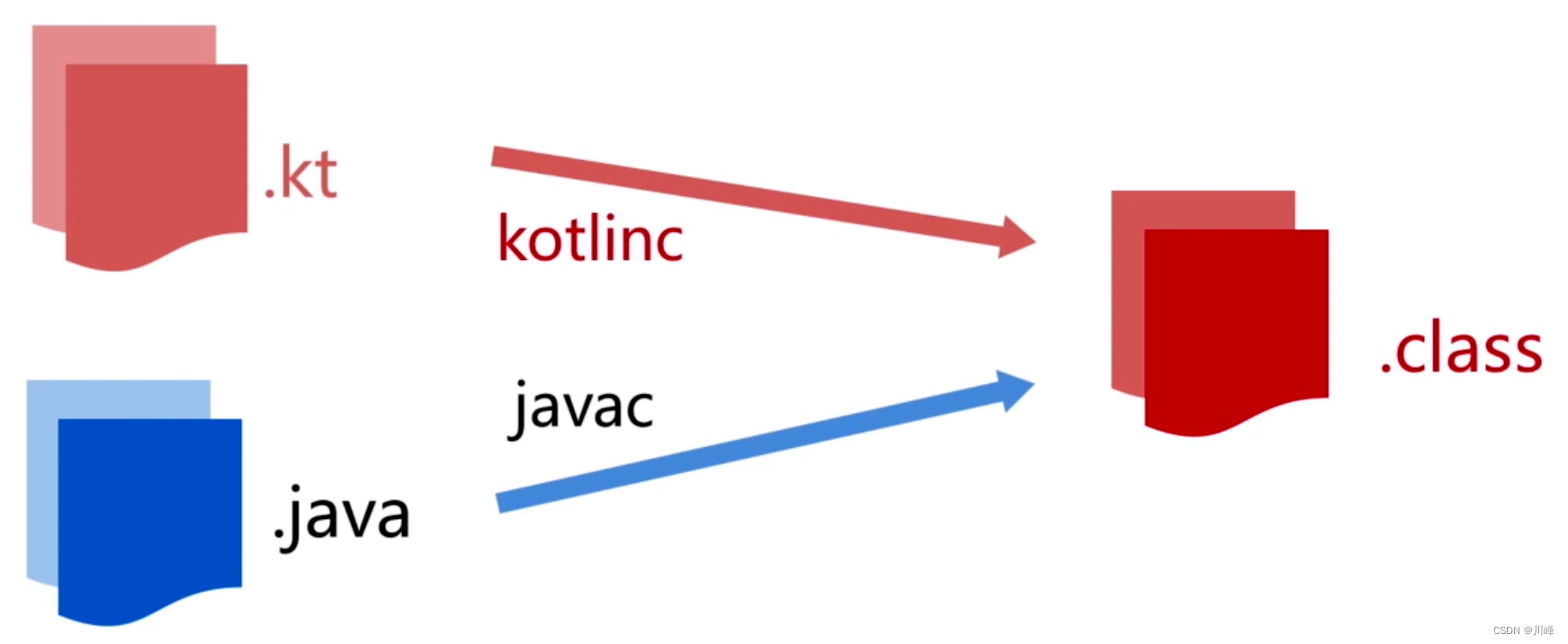
kotlin 有哪些 Java 中没有的特性:
- 类型推断、可变性、可空性
- 自动拆装箱、泛型数组
- 高阶函数、DSL
- 顶层函数、扩展函数、内联函数
- 伴生对象、数据类、密封类、单例类
- 接口代理、internal、泛型具体化
- … …
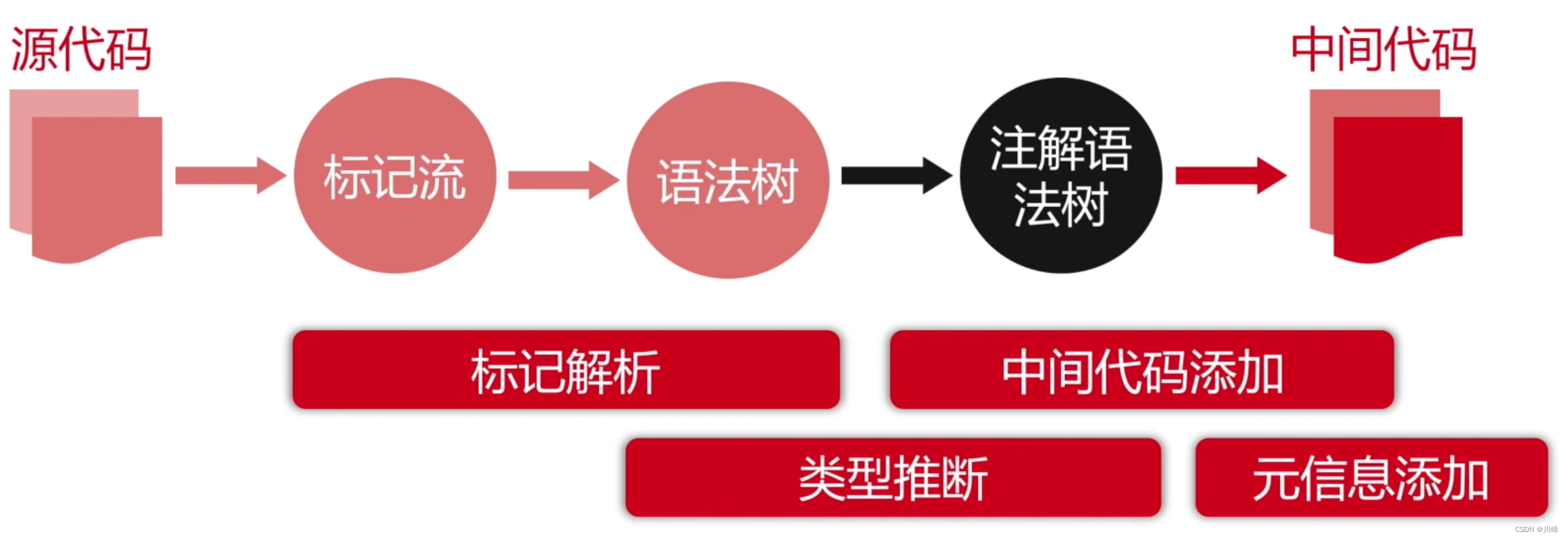
语言的编译过程
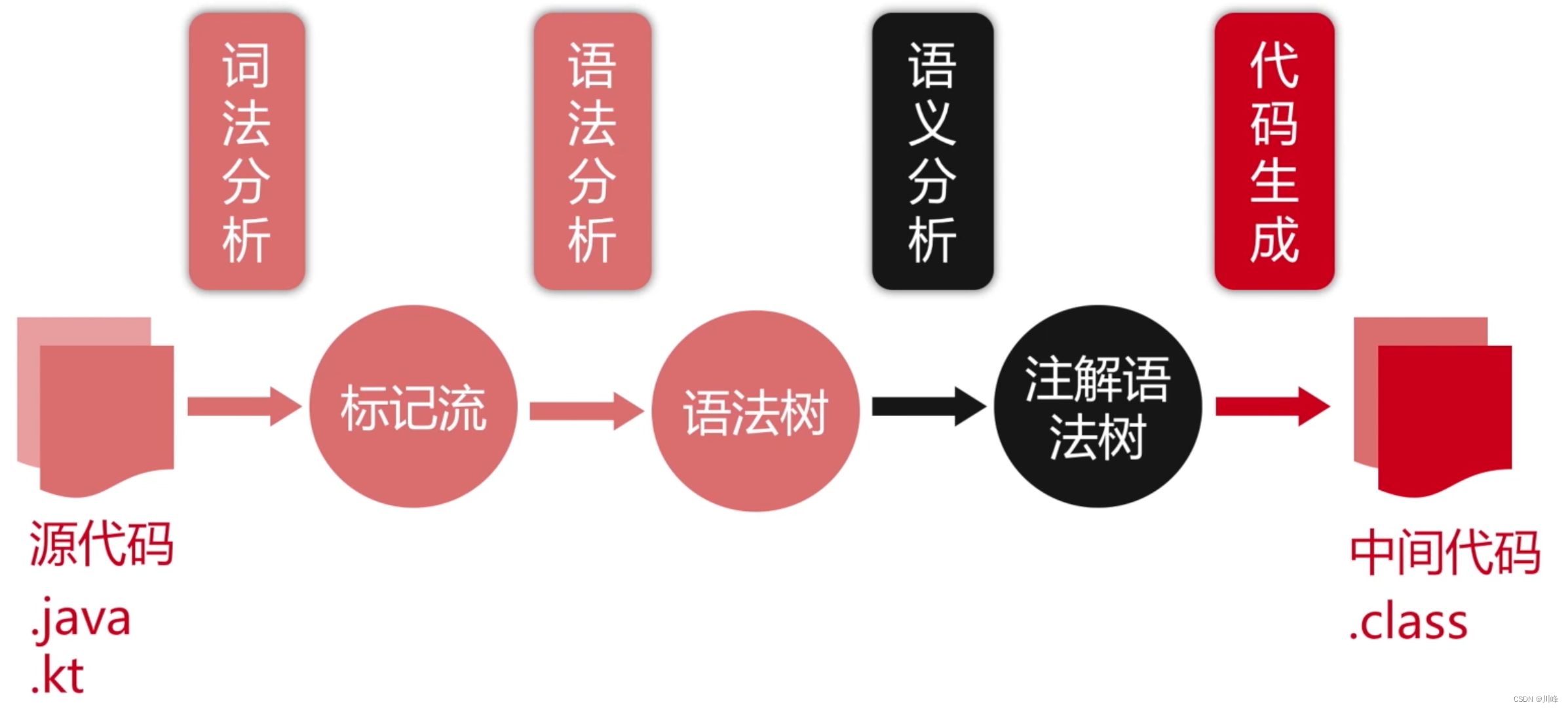
词法分析:
语法分析:
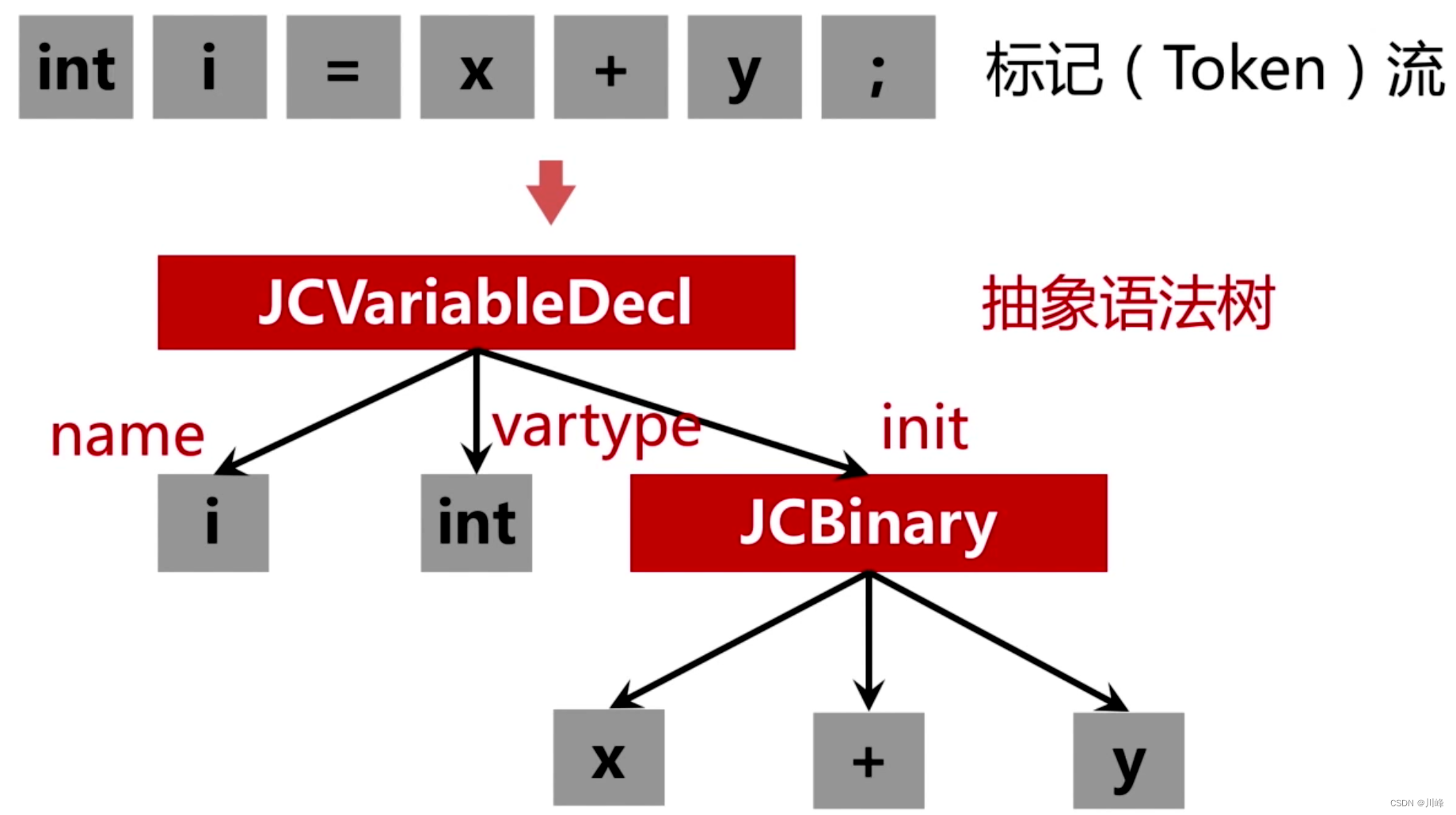
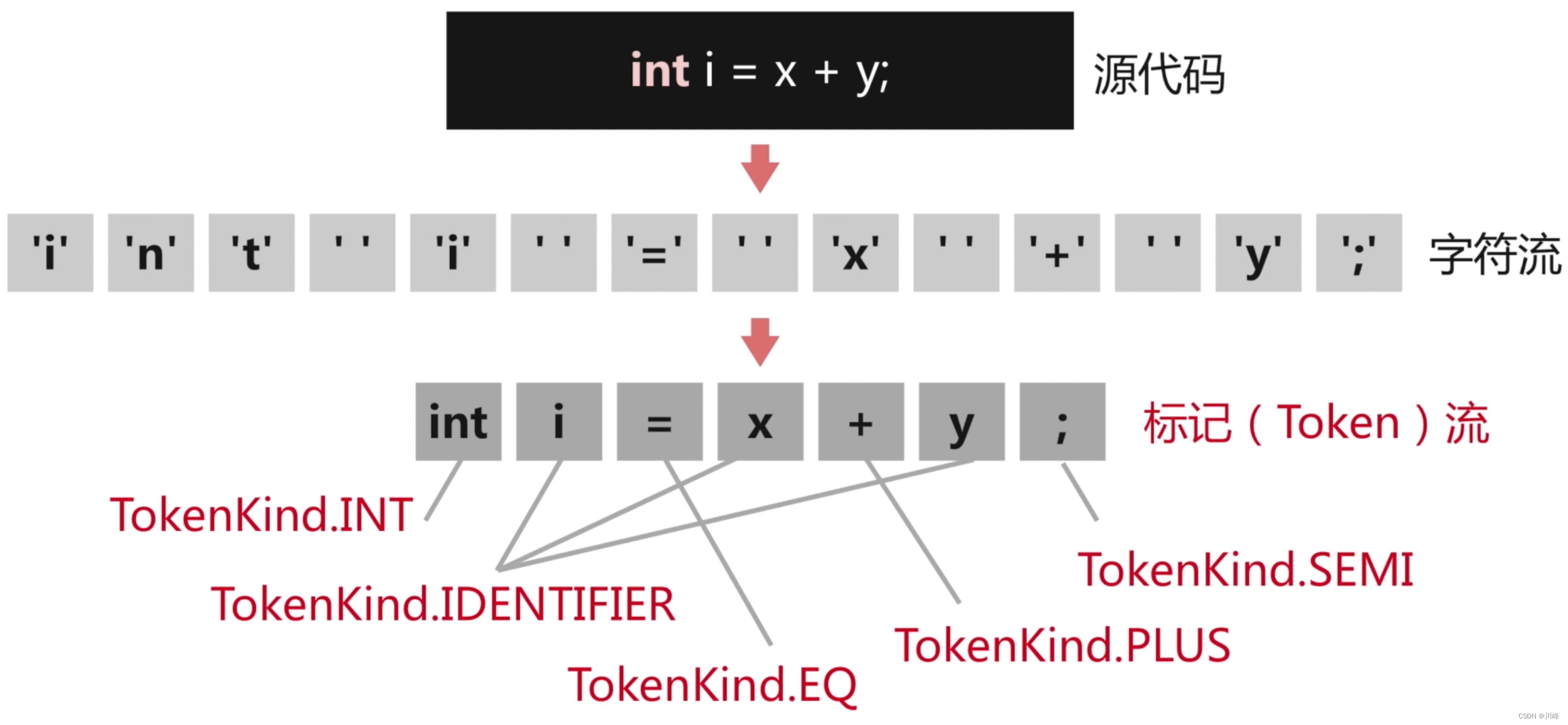
- 词法分析:把源码的字符流,转化成标记(Token)序列,标记是语言的最小语义单位,包括关键字、标识符、运算符、常数等;
- 语法分析:把标记序列,组合成各类语法短句,判断标记序列在语法结构上,是否正确,输出树形结构的抽象语法树;
- 语义分析:结合上下文,检查每一个语法短句,语义是否正确,是否符合语言规范。(数据类型匹配、重复定义检测、访问合法性、静态分派、受检异常、语句可达性、展开语法糖…)
Kotlin 的类型推断
- 类型推断并不是不确定数据类型,相反是从上下文推断出一个明确的数据类型;
- 类型推断的意义在于,去掉代码中的冗余信息,提升研发效率;

- 类型推断主要发生在语法分析和语义分析阶段,这个功能主要是通过编译器来实现的。
Kotlin 的拆装箱
// Java 的拆装箱
Integer x = 1; // 自动装箱
int y = x; // 自动拆箱
// kotlin 的拆装箱
var i : Int = 0 // 对应 Java 中的 int
var i : Int? = null // 对应 Java 中的 Integer
i = 0 // 对应 Java 中的 Integer.valueOf()
// kotlin 的拆装箱
val list = mutableListOf<Int>()
list.add(0) // Integer.valueOf()
Kotlin的装箱类型数组:
val ids : Array<Int> = arrayOf()
- 支持泛型类型,所以默认不具备协变性,字节码实现对应
anewarray,相当于 Java 的Integer[]。
val ids : IntArray = IntArrayOf()
- 字节码实现对应
newarray,相当于 Java 的int[],性能较好。
Kotlin中的隐式装箱类总结:
- 可空的基本数据类型,会被编译成装箱类;
- 泛型中基本数据类型,在使用时,会自动拆装箱;
- 泛型数组,使用的是装箱类型。
由于自动拆装箱有性能损耗,出于性能考虑,在Kotlin中,应当尽量避免使用可空的基本数据类型,以及泛型数组; 尽量使用非可空类型。
Kotlin 中的高阶函数
高阶函数:在数学中,对应算子的概念,也就是对函数本身进行操作;在计算机语言中,高阶函数作为语言的一等公民,函数本身可以作为函数的输入,或是返回;高阶函数是函数式编程的基础条件。
高阶函数示例代码:
fun login(user: User, onFailed: (Int) -> Unit) : Boolean {
val stateCode = checkUser(user)
if (stateCode == SUCCESS) {
return true
} else{
onFailed(stateCode)
return false
}
}
val success = login(user) {
code ->
// TODO 展示错误状态
}
当 lambda 当作函数参数进行传递时,它本质上是一个函数对象,最终要将上述代码翻译成 Java 的字节码,而在 Java 中是没有函数对象这种东西的,那么怎么办呢?所以为了应对这种情况,Kotlin 中定义了一系列的 “类函数” 的接口:Function0、Function1、Function2、…、Function22 总共有22个,定义如下:
public interface Function<out R>
public interface Function0<out R> : Function<R> {
public operator fun invoke():
}
public interface Function1<in P1, out R> : Function<R> {
public operator fun invoke(p1: P1):R
}
public interface Function2<in P1, in P2, out R> : Function<R> {
public operator fun invoke(p1: P1, p2: P2): R
}
......
public interface Function22<in P1, in P2, in P3, ......, in P22, out R> : Function<R> {
public operator fun invoke(p1: P1, p2: P2, p3: P3,....., p22: P22): R
}
所以对于前面的高阶函数示例代码,本质上实际长这样:
fun login(user: User, onFailed: Function1<Int, Unit>) : Boolean {
val stateCode = checkUser(user)
if (stateCode == SUCCESS) {
return true
} else{
onFailed.invoke(stateCode)
return false
}
}
val success = login(user, object: Function1<Int, Unit> {
override fun invoke(p1: Int) {
// TODO 展示错误状态
}
})
即便传入的是普通的函数引用,最终也会以object匿名内部类对象的形式进行传递。例如:
fun showFailedState(state: Int) {
// TODO 展示错误状态
}
val success = login(user, ::showFailedState)
上面代码实际长下面这样:
fun showFailedState(state: Int) {
// TODO 展示错误状态
}
val success = login(user, object: Function1<Int, Unit> {
override fun invoke(p1: Int) {
showFailedState(p1)
}
})
高阶函数的真实面目:
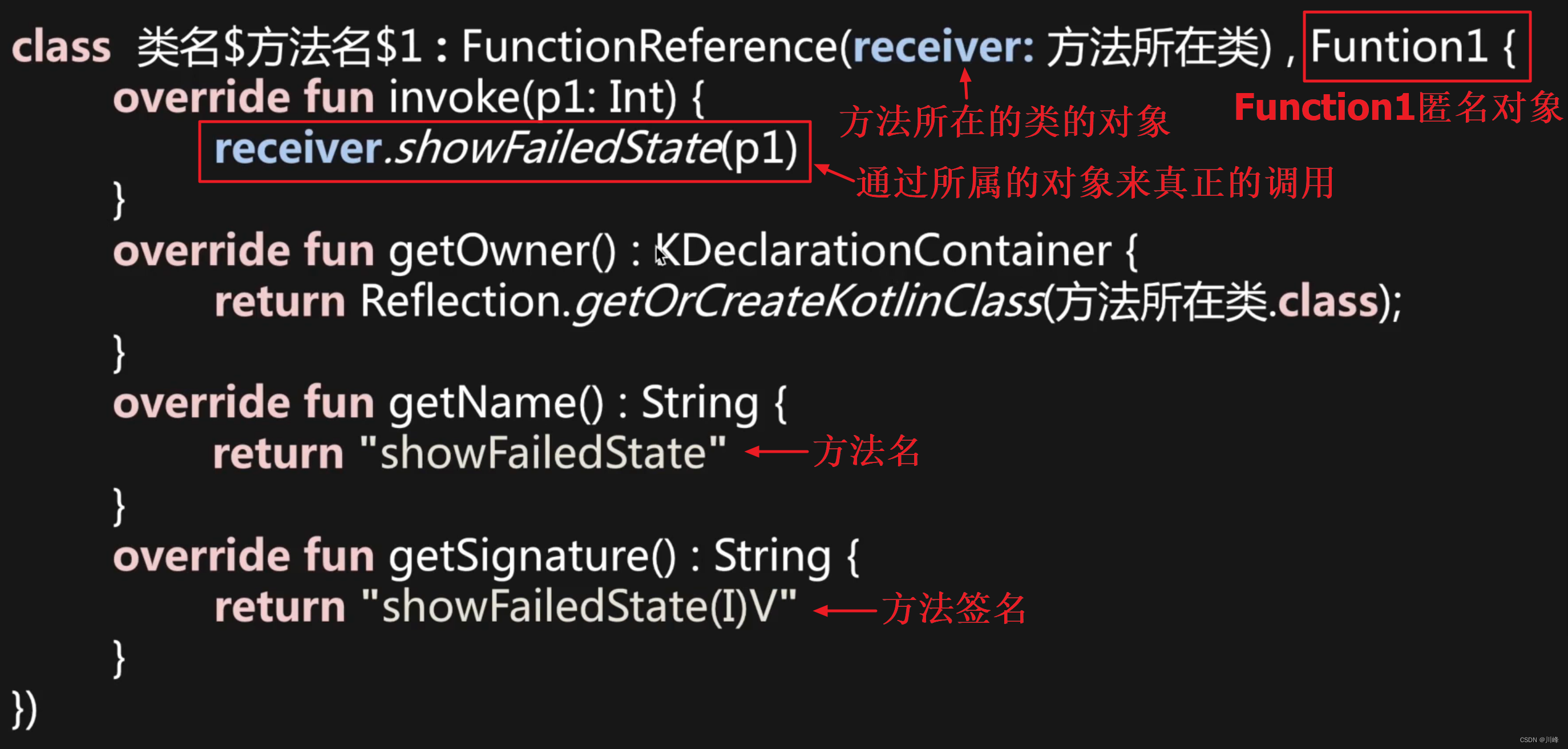
所以 Kotlin 中的高阶函数本质上是通过各种函数类型的对象进行桥接:
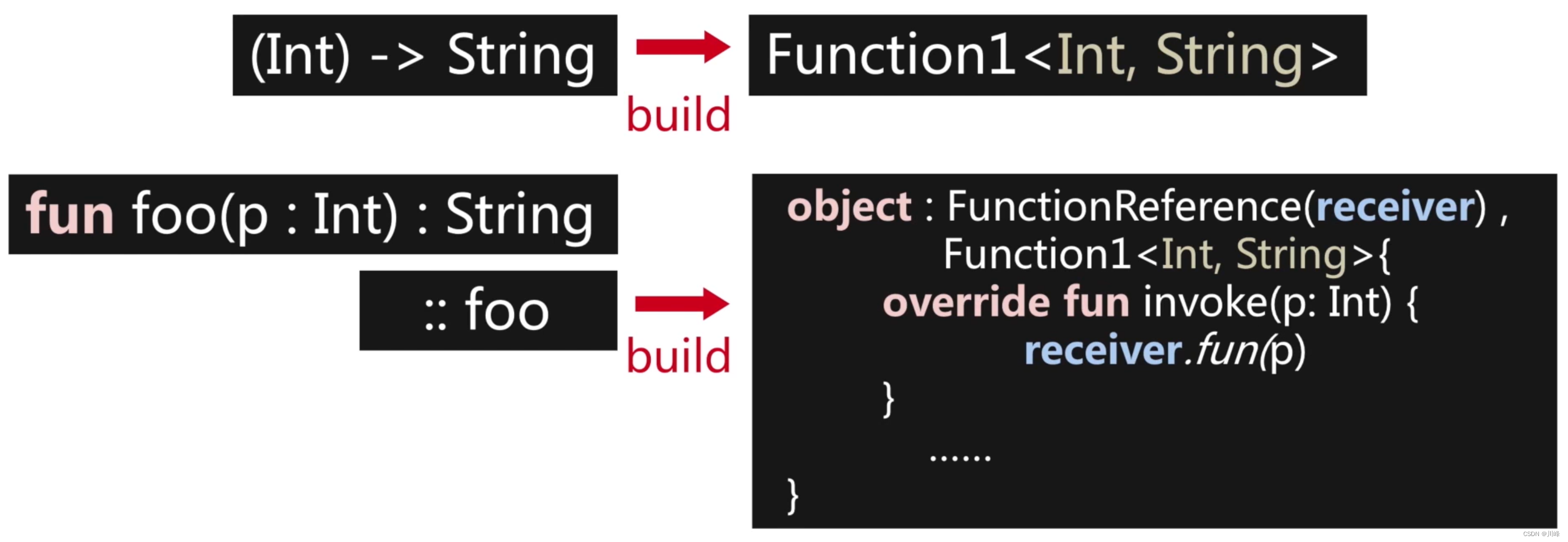
现在我们知道 Kotlin 中的高阶函数主要是通过中间代码添加手段来生成的:
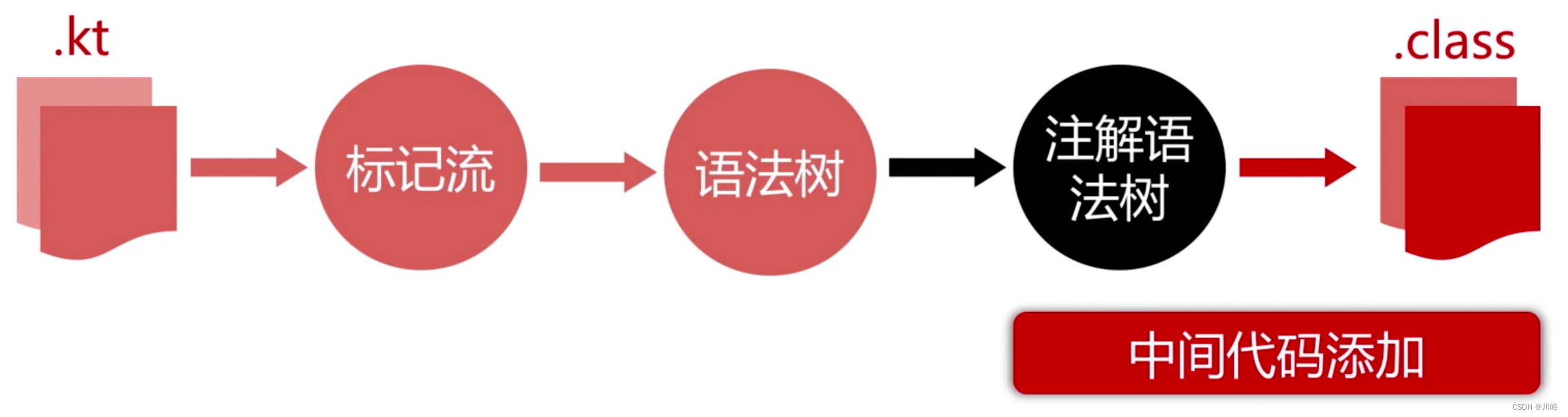
- 从性能上讲,高阶函数要创建实例,所以开销会增大。
- Kotlin 的匿名内部类,在和外部类有互动的时候,也会持有外部类的引用,存在一定的、潜在的内存泄漏的风险。
Kotlin 中的顶层函数
- Java 中的函数,必须在类的内部定义;
- 而 Kotlin 中允许在类的外部,定义文件级别的顶层函数以及变量。
// TimeUtils.kt
fun printTime() {
......// 打印当前时间
}
// Main.kt
import com.utils.printTime
fun main() {
printTime()
}
Kotlin 中的顶层函数翻译到 Java 字节码时,会自动生成一个以【文件名 + Kt】为命名的 Java 类来包装这个顶层函数,将其作为这个 Java 类的静态函数:
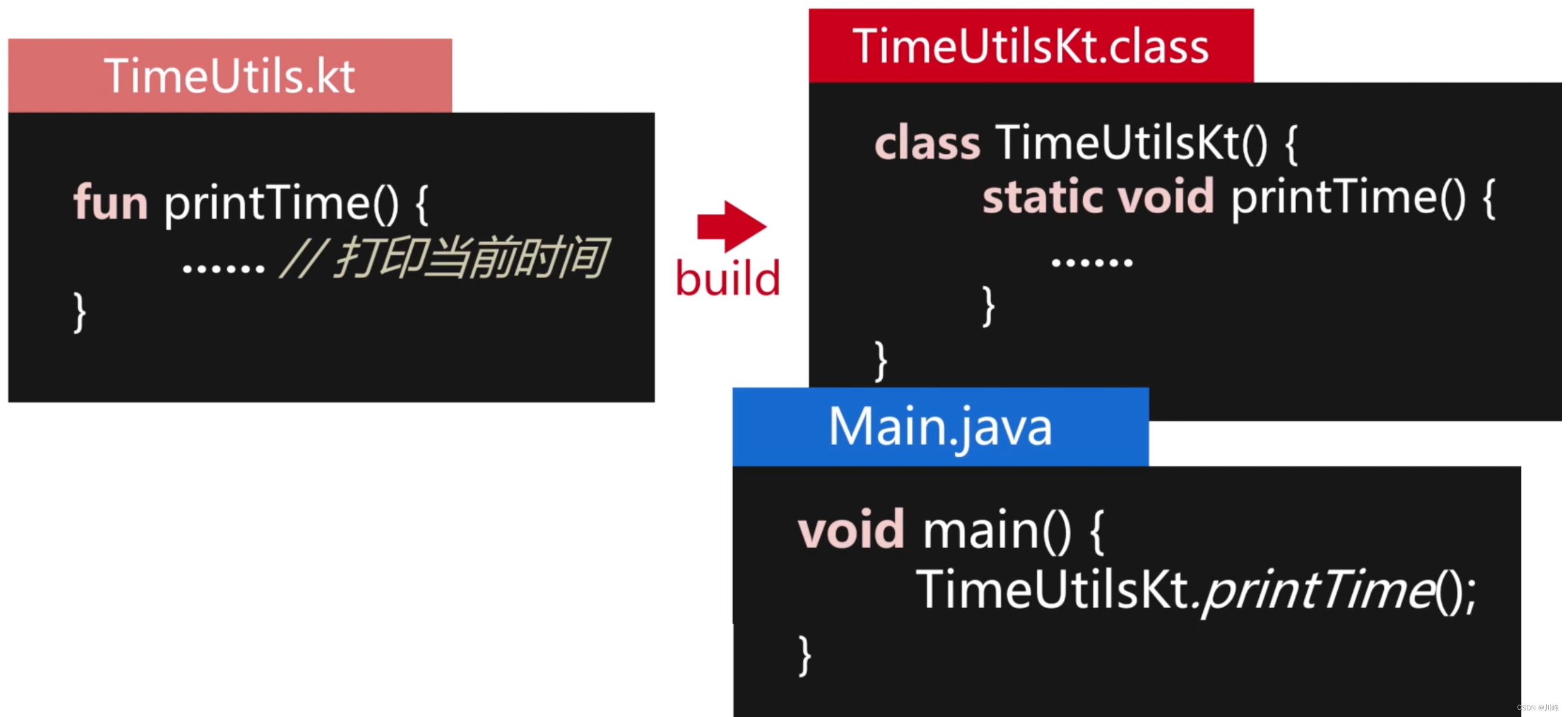
现在我们知道 Kotlin 中的顶层函数也是通过中间代码添加手段来生成的:
- 从字节码层面来说,所有的函数和变量都必须在类的内部;
- Kotlin 编译器在生成字节码时,会给顶层的函数及变量,创建一个所属的类,类名默认规则是文件名+
Kt; - Java 代码,可以通过这些以
Kt结尾的类,调用到这些在 Kotlin 中定义的顶层函数和变量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1335
1335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











