



spark介绍及框架原理
https://www.cnblogs.com/liuliliuli2017/p/6809094.html
https://blog.youkuaiyun.com/swing2008/article/details/60869183
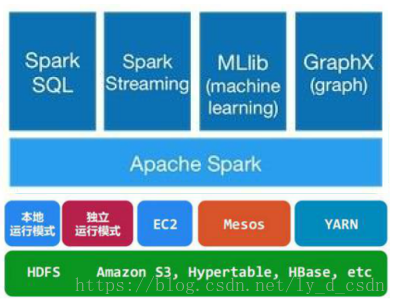
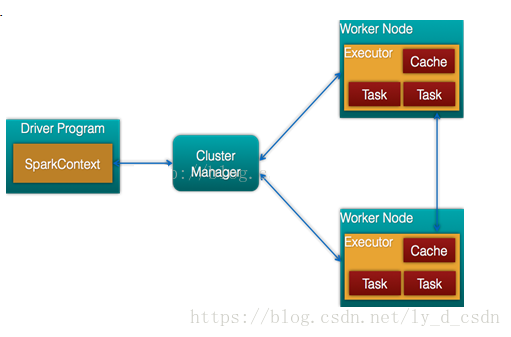
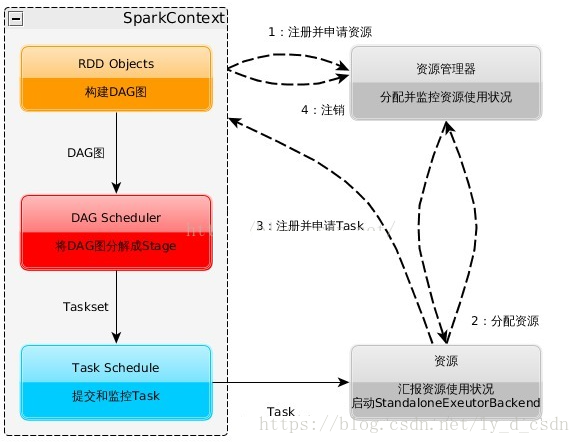
spark参数配置
https://blog.youkuaiyun.com/guohecang/article/details/52088117
spark RDD
https://blog.youkuaiyun.com/guohecang/article/details/51736572
spark 与 MapReduce 性能提升的原因
https://www.cnblogs.com/deadend/p/6710468.html
这俩根本没啥可比的,能够单MR做完的任务,Spark未必比MR快。至于迭代不迭代的并不是关键,其实你在Mapper里对数据做N个操作基本等价于N个窄依赖RDD的连接。
所以说真要比,也是多个MR组成的复杂Job来和Spark比。
MR由于其计算粒度的设计问题,在进行需要多次MR组合的计算时,每次MR除了Shuffle的磁盘开销外,Reduce之后也会写到磁盘。
而Spark的DAG实质上就是把计算和计算之间的编排变得更为细致紧密,使得很多MR任务中需要落盘的非Shuffle操作得以在内存中直接参与后续的运算,并且由于算子粒度和算子之间的逻辑关系使得其易于由框架自动地优化(换言之编排得好的MR其实也可以做到)。
另外在进行复杂计算任务的时候,Spark的错误恢复机制在很多场景会比MR的错误恢复机制的代价低,这也是性能提升的一个点。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









