








作为一名在互联网大厂摸爬滚打十余年的架构师,我深知JVM垃圾回收这个话题对新手的"杀伤力",第一次接触时我也是一脸懵圈,甚至怀疑自己是不是不适合学Java,但坚持下来才发现这些知识构成了我技术实力的重要基石,今天就让我们一起来揭开JVM垃圾回收器的神秘面纱,从小白到大神,一文搞定,
一,为什么需要垃圾回收
记得我刚学编程时,写的是C语言,那时候申请内存和释放内存都需要手动操作,稍不注意就会出现内存泄漏或者野指针问题,简直噩梦,忘记释放一块内存,你的程序可能会慢慢吃掉所有系统资源,最后崩溃,
这就是为什么Java的自动垃圾回收机制如此受欢迎,它让开发者可以专注于业务逻辑实现,而不用考虑内存管理这种底层问题,JVM会自动回收不再使用的对象,释放内存空间,极大提高了开发效率和程序稳定性,
垃圾回收的本质就是找出程序不再使用的对象,并释放它们占用的内存空间,听起来简单,但实现起来相当复杂,不同的垃圾回收器各有特点,适用于不同的应用场景,
二,JVM内存模型基础
在讲垃圾回收器之前,我们先简单回顾一下JVM内存模型,因为垃圾回收器主要工作在堆内存区域,
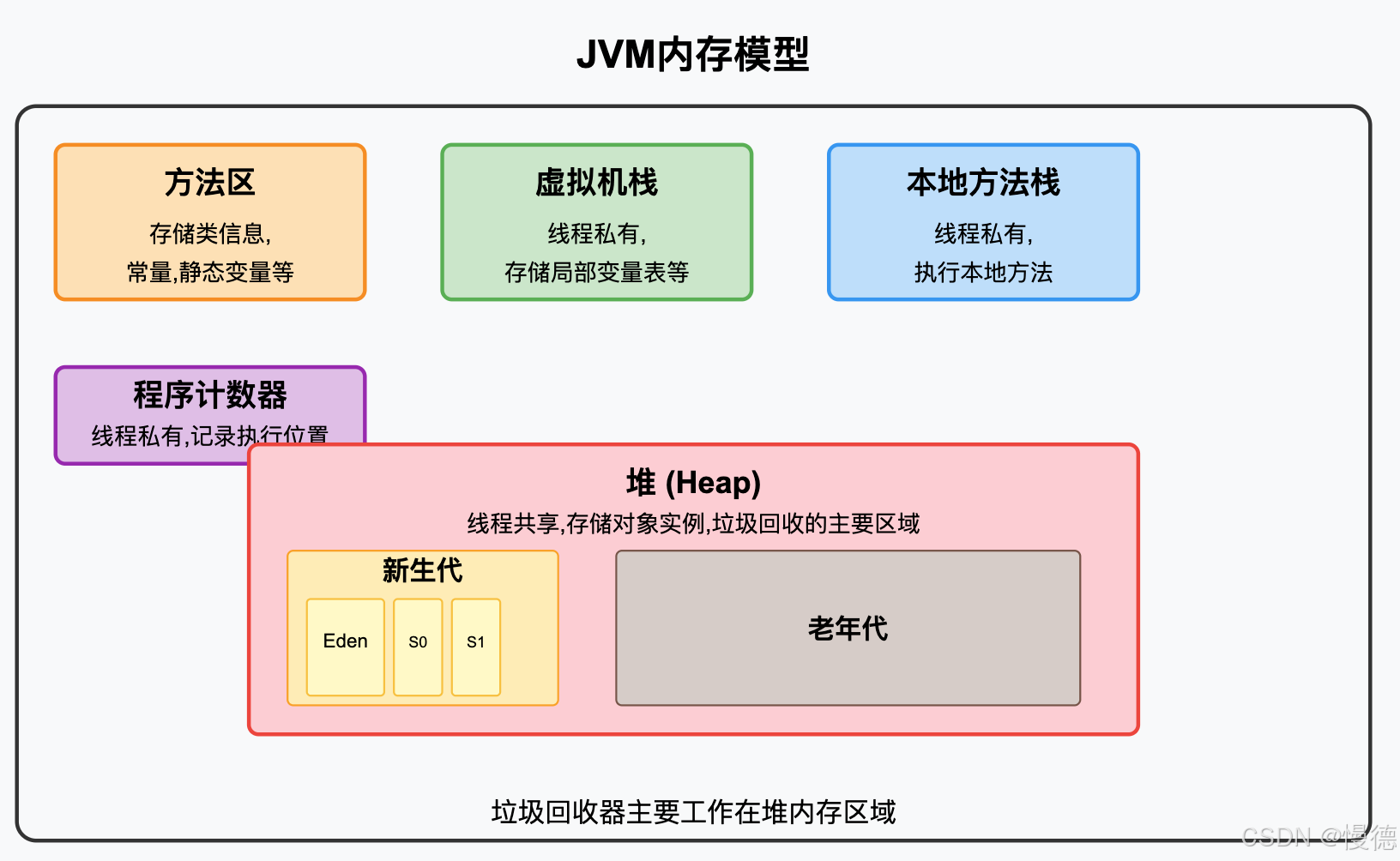
JVM内存主要分为以下几个区域:
- 堆内存(Heap):存储对象实例,是垃圾回收的主要区域,
- 方法区:存储类信息,常量,静态变量等,
- 虚拟机栈:线程私有,存储局部变量表等,
- 本地方法栈:线程私有,执行本地方法,
- 程序计数器:线程私有,记录当前线程执行的位置,
其中,垃圾回收主要工作在堆内存区域,堆内存又分为新生代和老年代,新生代又细分为Eden区和两个Survivor区(通常称为S0和S1或From和To),
三,垃圾回收的基本原理
3.1 如何判断对象是否可回收
在垃圾回收的世界里,首先要解决的问题是:哪些对象是垃圾,我们来看两种主要的判断方法,
引用计数法
最直观的方法是引用计数法:每个对象有一个引用计数器,当有引用指向它时,计数器加1,当引用失效时,计数器减1,当计数器为0时,表示对象不再被使用,可以回收,
这种方法实现简单,判定效率高,但有个致命问题:无法解决循环引用,比如对象A引用对象B,对象B引用对象A,尽管外部没有引用指向A和B,但它们的引用计数都不为0,导致无法回收,
可达性分析
因此,JVM采用可达性分析算法:以一系列"GC Roots"对象作为起点,沿着引用链向下搜索,如果一个对象到GC Roots没有任何引用链相连,则证明该对象不可达,可以回收,
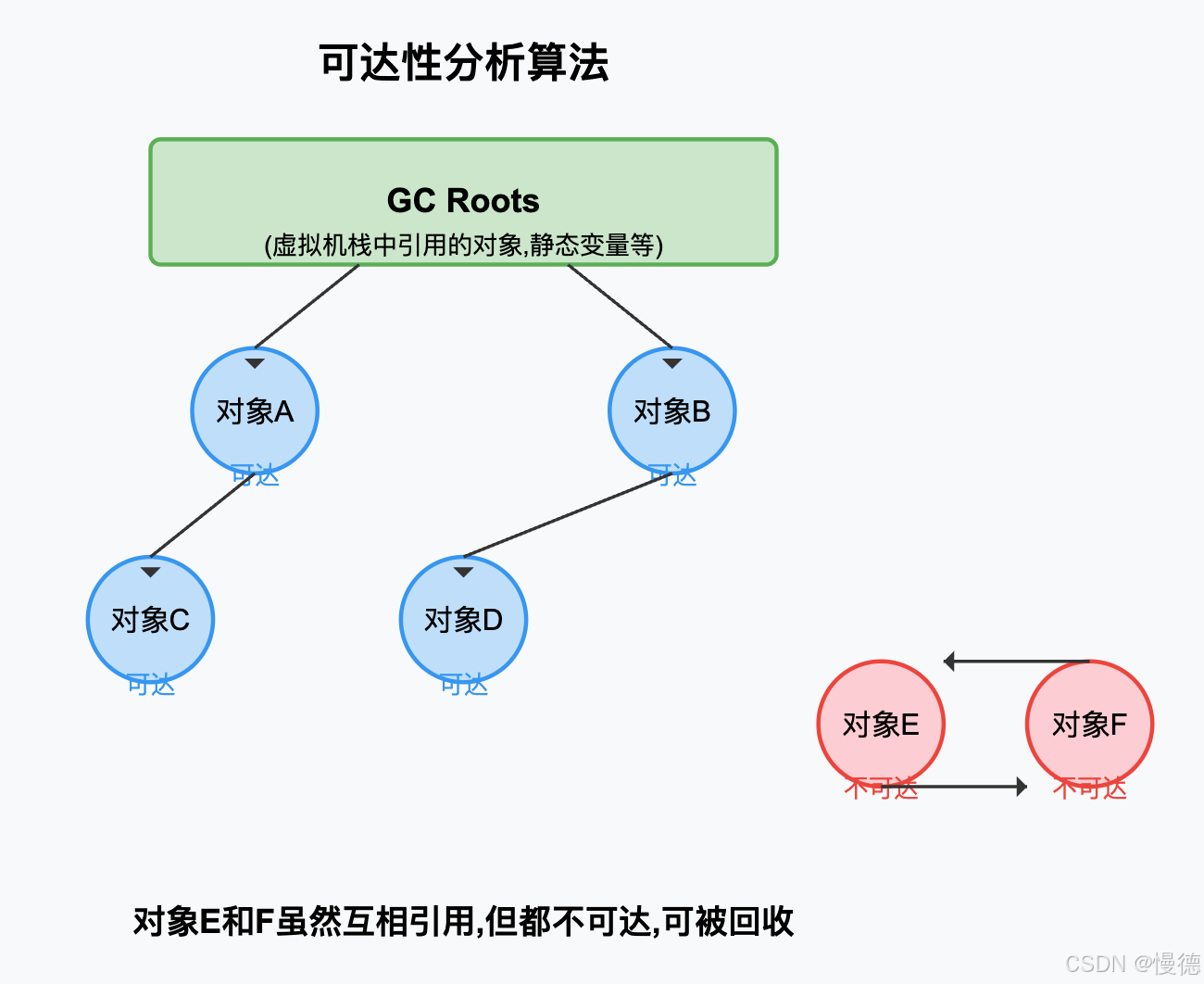
GC Roots主要包括:
- 虚拟机栈中引用的对象,
- 方法区中类静态属性引用的对象,
- 方法区中常量引用的对象,
- 本地方法栈中JNI引用的对象,
在上图中,对象E和对象F虽然互相引用,形成了循环引用,但它们都无法从GC Roots到达,因此会被判定为垃圾对象,这也是可达性分析算法优于引用计数法的地方,
3.2 垃圾回收算法
判断完对象是否可回收后,下一步就是如何高效地回收这些垃圾对象,几种常见的垃圾回收算法如下:
标记-清除算法(Mark-Sweep)
最基础的垃圾回收算法,分为两个阶段:
- 标记阶段:标记出所有需要回收的对象,
- 清除阶段:清除所有被标记的对象,
这种算法的缺点非常明显:一是效率不高,标记和清除两个过程都比较耗时,二是会产生大量不连续的内存碎片,导致无法分配大对象时提前触发另一次垃圾回收,
复制算法(Copying)
为了解决标记-清除算法的效率问题,复制算法将内存分为两块,每次只使用其中一块,当这一块用完了,就将还存活的对象复制到另一块上,然后一次性清理掉已使用过的内存空间,
这种算法实现简单,运行高效,但代价是内存利用率只有一半,所以通常用于新生代垃圾回收,新生代对象存活率较低,复制成本小,
标记-整理算法(Mark-Compact)
标记-整理算法是针对老年代对象存活率高的特点,在标记-清除算法基础上做了改进,标记过程与标记-清除算法一样,但后续不是直接清理对象,而是将所有存活的对象向内存空间一端移动,然后清理掉边界以外的内存,
这种算法避免了内存碎片问题,也不会像复制算法那样浪费内存空间,但移动对象的过程会增加额外开销,
分代收集算法(Generational Collection)
分代收集算法并不是一种具体的算法,而是根据对象的生命周期将内存划分为几块,一般是新生代和老年代,然后根据各个年代的特点采用最适当的收集算法,
通常,新生代使用复制算法,老年代使用标记-整理或标记-清除算法,这也是目前虚拟机使用的算法,
四,JVM垃圾回收器详解
了解了基本原理,我们来看看JVM中实际使用的垃圾回收器,我会按照时间顺序介绍主流的垃圾回收器,包括它们的特点,优缺点及适用场景,
4.1 Serial收集器 - 单线程的稚嫩收集器
Serial收集器是最古老,最简单的收集器,单线程工作,在回收时必须暂停所有用户线程(Stop The World),对于新生代采用复制算法,对老年代采用标记-整理算法,
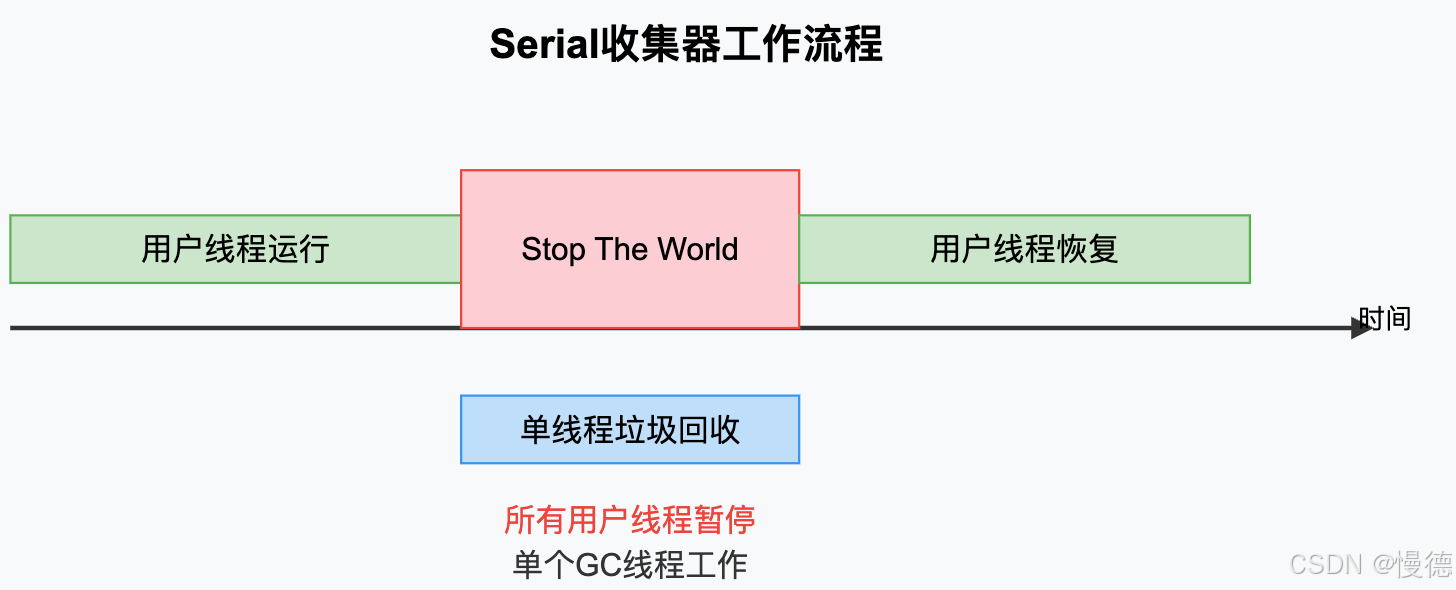
优点:
- 简单高效,没有线程交互的开销,
- 在单CPU环境下表现良好,
缺点:
- 需要Stop The World,暂停所有用户线程,
- 无法利用多核CPU优势,
适用场景:
- 客户端应用,如桌面程序,
- 内存较小,CPU核心数少的场景,
虽然看起来很原始,但Serial收集器依然是虚拟机Client模式下的默认新生代收集器,在单核或者内存受限的环境中仍有一席之地,
4.2 ParNew收集器 - Serial的多线程版本
ParNew收集器实际上是Serial收集器的多线程版本,除了使用多线程进行垃圾回收外,其余行为包括算法,STW,对象分配规则等都与Serial收集器一样,
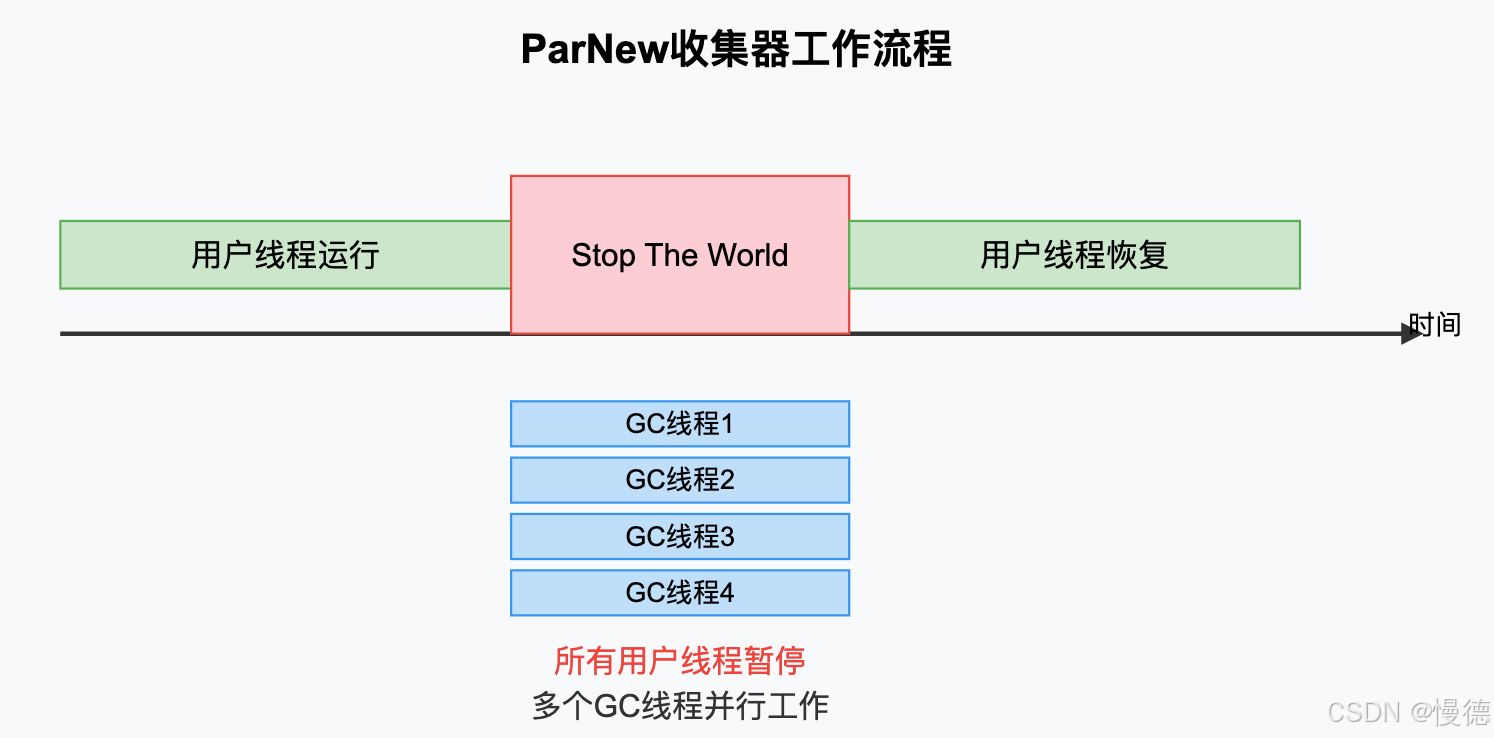
优点:
- 多线程收集,在多核CPU环境下有更好的表现,
- 与CMS收集器搭配使用效果好,
缺点:
- 暂停用户线程(STW),影响应用响应时间,
- 在单核CPU环境中表现不如Serial收集器,
适用场景:
- 多核CPU服务器环境,
- 对吞吐量有一定要求的中小型应用,
多线程垃圾回收是趋势,ParNew收集器是许多运行在Server模式下JVM的首选新生代收集器,特别是搭配CMS收集器时,
4.3 Parallel Scavenge收集器 - 关注吞吐量的收集器
Parallel Scavenge收集器也是一个新生代收集器,同样基于复制算法实现,也是并行的多线程收集器,看起来和ParNew收集器
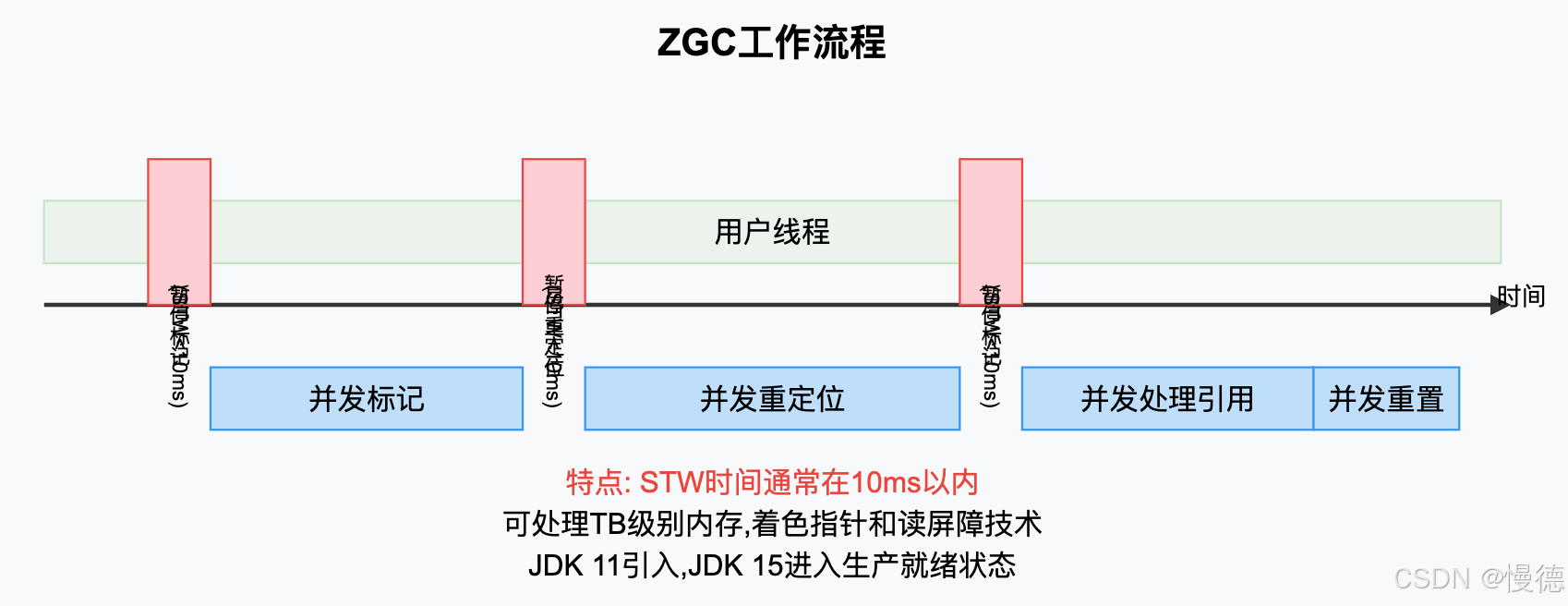
ZGC的几个显著特点:
- 低延迟:STW时间不会随着堆大小或存活对象增加而增加,始终保持在10ms以内,
- 大内存支持:可以高效处理从几百MB到几TB的堆内存,
- 着色指针:在对象指针中存储标记信息,而不是在对象头中,
- 读屏障:在程序读取对象引用时,使用读屏障技术确保引用的有效性,
ZGC只在JDK 11及以上版本支持,并在JDK 15进入生产就绪状态,它主要在Linux/x64平台上工作最佳,
优点:
- 超低延迟,最大停顿时间通常在10ms以内,
- 可扩展到TB级别的堆,且停顿时间不会随堆大小增加,
- 与G1相比有更高的吞吐量,
缺点:
- 吞吐量略低于Parallel GC,
- 支持平台有限制,对CPU架构有要求,
适用场景:
- 对延迟极其敏感的应用,如实时交易系统,
- 超大堆内存应用,
在一个金融交易系统中,我们使用ZGC成功将GC停顿时间从之前的50-100ms降到了稳定的5ms以内,极大改善了用户体验,
Parallel Scavenge收集器也是一个新生代收集器,同样基于复制算法实现,也是并行的多线程收集器,看起来和ParNew收集器很像,但它的关注点与其他收集器不同,Parallel Scavenge收集器的目标是达到一个可控制的吞吐量,
什么是吞吐量,这里简单解释一下:吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间),比如程序运行了100分钟,其中垃圾收集花费1分钟,那么吞吐量就是99%,
Parallel Scavenge提供了两个重要参数:
-XX:MaxGCPauseMillis:控制最大垃圾收集停顿时间,-XX:GCTimeRatio:设置吞吐量大小,
此外,Parallel Scavenge还有一个特点是支持自适应调节策略,通过参数-XX:+UseAdaptiveSizePolicy开启,让虚拟机自己调整新生代大小,Eden与Survivor比例,晋升老年代对象年龄等参数,无需手工指定,
优点:
- 并行多线程收集,吞吐量高,
- 自适应调节策略,易于使用,
缺点:
- 仍然有STW问题,不适合对响应时间有严格要求的应用,
适用场景:
- 后台运算而不需要太多交互的任务,如批量处理,
- 科学计算等计算密集型应用,
Parallel Scavenge在JDK1.8中是server模式下的默认垃圾收集器,特别适合需要高吞吐量而不太关心停顿时间的场景,
4.4 Serial Old收集器 - 老年代单线程收集器
Serial Old是Serial收集器的老年代版本,同样是单线程收集器,使用标记-整理算法,主要用于Client模式下的老年代收集,
在Server模式下,它还有两个用途:一是作为CMS收集器的后备方案,在并发收集发生Concurrent Mode Failure时使用,二是在JDK1.5及之前版本中与Parallel Scavenge收集器搭配使用,
由于是单线程设计,Serial Old在Server模式下性能较弱,已经很少使用,
4.5 Parallel Old收集器 - 老年代并行收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法,在JDK1.6中才开始提供,

在Parallel Old出现之前,Parallel Scavenge收集器只能与Serial Old收集器配合使用,由于老年代Serial Old是单线程的,无法充分发挥出多核优势,所以在JDK1.6推出了Parallel Old收集器,与Parallel Scavenge收集器配合,可以充分利用多核CPU的优势,
优点:
- 并行多线程收集,吞吐量高,
- 与Parallel Scavenge搭配使用,可以充分发挥服务器多核性能,
缺点:
- 仍然存在STW问题,
适用场景:
- 注重吞吐量的服务器应用,
- 可以接受较长停顿时间的批处理任务,
4.6 CMS收集器 - 低延迟的收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,非常适合对响应时间有要求的应用,如互联网站或者B/S系统的服务端,
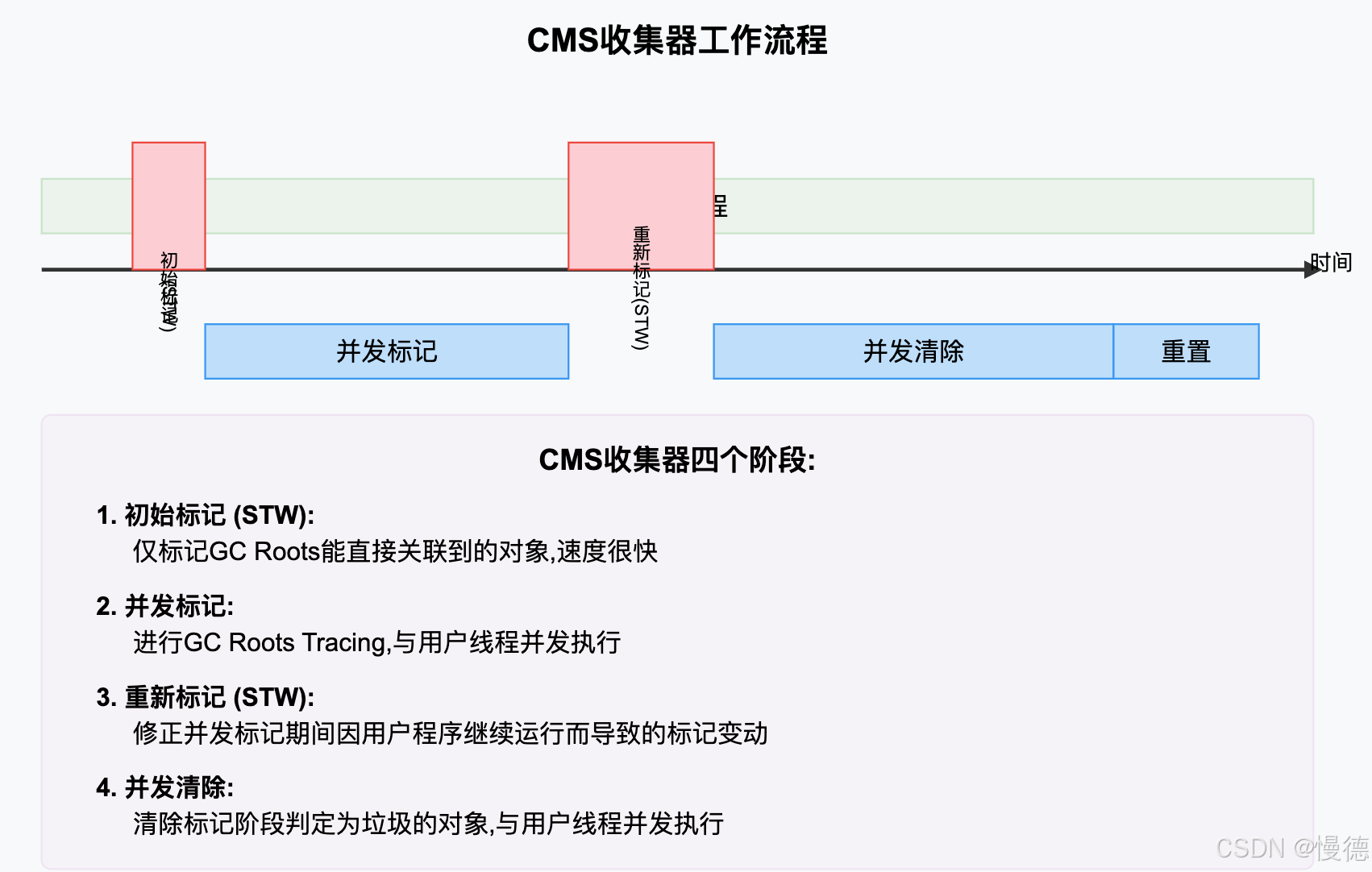
CMS收集器的工作过程相对复杂,分为四个主要阶段:
- 初始标记(STW):仅标记GC Roots直接关联的对象,速度很快,需要STW,
- 并发标记:从GC Roots开始对堆中对象进行可达性分析,耗时较长,但与用户线程并发执行,不需要STW,
- 重新标记(STW):修正并发标记期间因用户程序继续运行而导致的标记变动,需要STW,时间比初始标记长,但远比并发标记短,
- 并发清除:清除已死亡对象,与用户线程并发执行,
优点:
- 并发收集,低停顿,
- 对响应时间要求高的应用友好,
缺点:
- 对CPU资源敏感,在并发阶段会占用一部分线程,导致总吞吐量下降,
- 无法处理浮动垃圾(在清理阶段产生的新垃圾),可能出现Concurrent Mode Failure,
- 使用标记-清除算法,会产生内存碎片,
适用场景:
- 互联网应用或B/S系统服务端,
- 对响应时间有要求的中大型应用,
我在一个电商项目中使用过CMS收集器,能够很好地控制GC停顿时间,保证了购物车结算过程的流畅体验,但同时也不得不配置更多的内存以应对浮动垃圾问题,
4.7 G1收集器 - 全能型收集器
G1(Garbage-First)收集器是JDK 7推出的一款面向服务端应用的垃圾收集器,被设计为旨在取代CMS收集器,在JDK 9中已成为默认垃圾收集器,
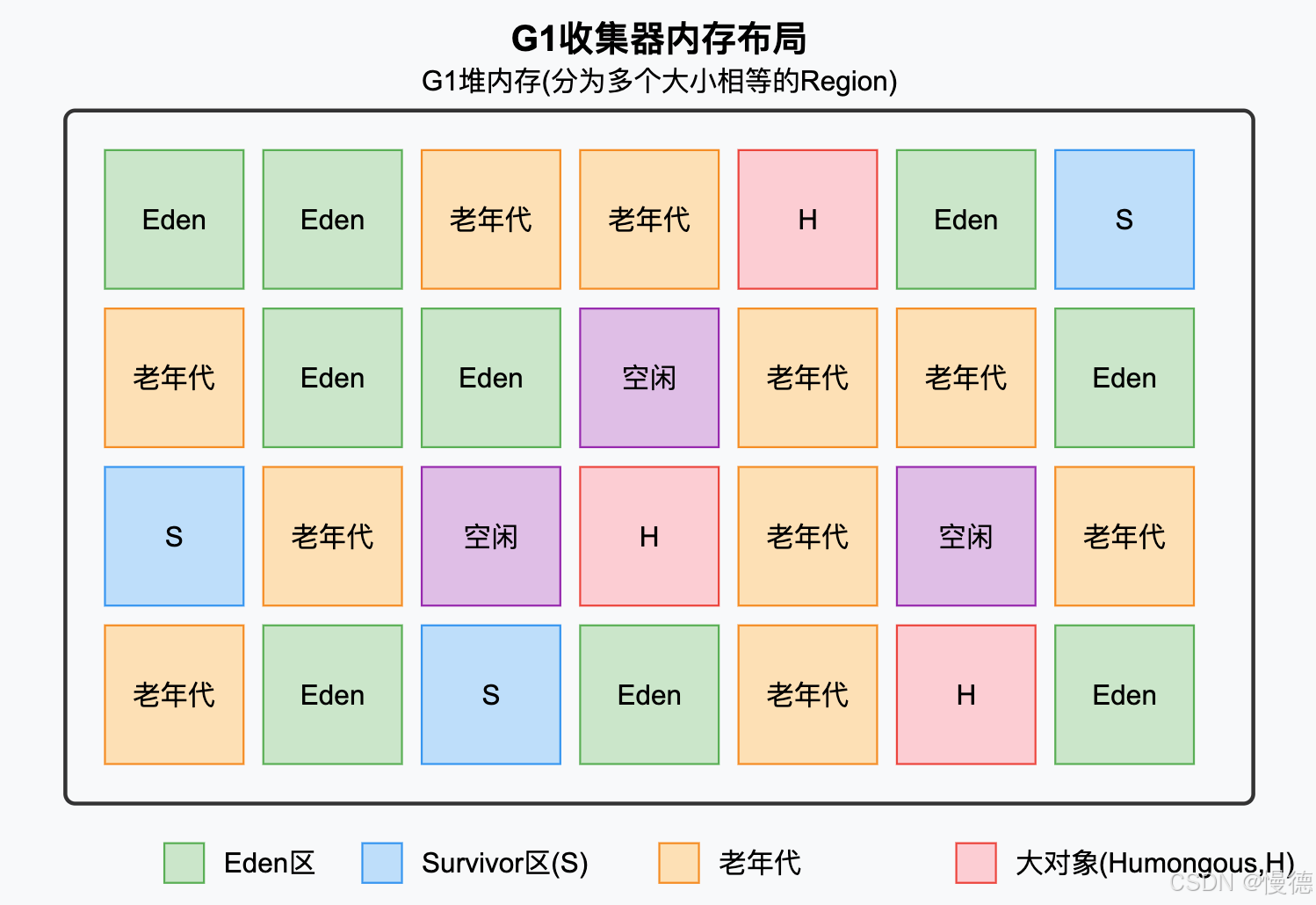
G1收集器有几个鲜明的特点:
- 并行与并发:充分利用多核CPU,缩短STW时间,
- 分代收集:兼顾新生代和老年代,不需要配合其他收集器使用,
- 空间整合:基于标记-整理算法,不会产生内存碎片,
- 可预测的停顿:能够指定期望的停顿时间,
与其他收集器最大的不同是,G1将堆内存划分为多个大小相等的区域(Region),不要求各个Region的连续性,每个Region都可以扮演Eden,Survivor或者老年代的角色,且角色可以随时转换,收集过程中会计算每个Region的回收价值(回收所获得的空间大小和回收所需时间的比值),优先回收价值高的Region,这也是名称"Garbage-First"的由来,
G1的工作过程相对复杂,包括初始标记(STW),并发标记,最终标记(STW),筛选回收(STW)等阶段,
优点:
- 并发收集,低停顿,
- 整体上是标记-整理算法,不会产生空间碎片,
- 可以设定目标停顿时间,更好地控制GC停顿对应用的影响,
缺点:
- 在非常大的堆和高对象分配率的场景下,可能遇到并发模式失败,
- 相比CMS需要更多的内存开销,
适用场景:
- 服务端应用,特别是需要更大堆内存的应用,
- 需要低延迟同时也关注吞吐量的系统,
我在一个大数据处理系统中使用G1收集器,它能够很好地控制GC停顿时间,同时有效处理大量的临时对象,是一个非常均衡的选择,
4.8 ZGC收集器 - 超低延迟收集器
ZGC(Z Garbage Collector)是JDK 11引入的一款低延迟垃圾收集器,旨在将STW时间控制在10ms以内,
4.9 Shenandoah收集器 - 另一种低延迟选择
Shenandoah是Red Hat开发的一款低延迟垃圾收集器,与ZGC类似,目标是降低GC停顿时间,它在JDK 12中被引入,
Shenandoah与ZGC有相似的设计目标,也使用了并发标记和并发整理算法,但实现细节不同,Shenandoah使用Brooks转发指针而非着色指针,
优点:
- 低延迟,大部分工作与应用线程并发执行,
- 停顿时间与堆大小无关,
缺点:
- 对吞吐量有一定影响,
- 内存占用略高,
适用场景:
- 对延迟敏感的应用,
- 可以接受轻微吞吐量下降的场景,
五,垃圾回收器对比与选择
了解了各种垃圾回收器的特点,如何选择适合自己应用的收集器,这里给出一个简单的对比和选择指南,
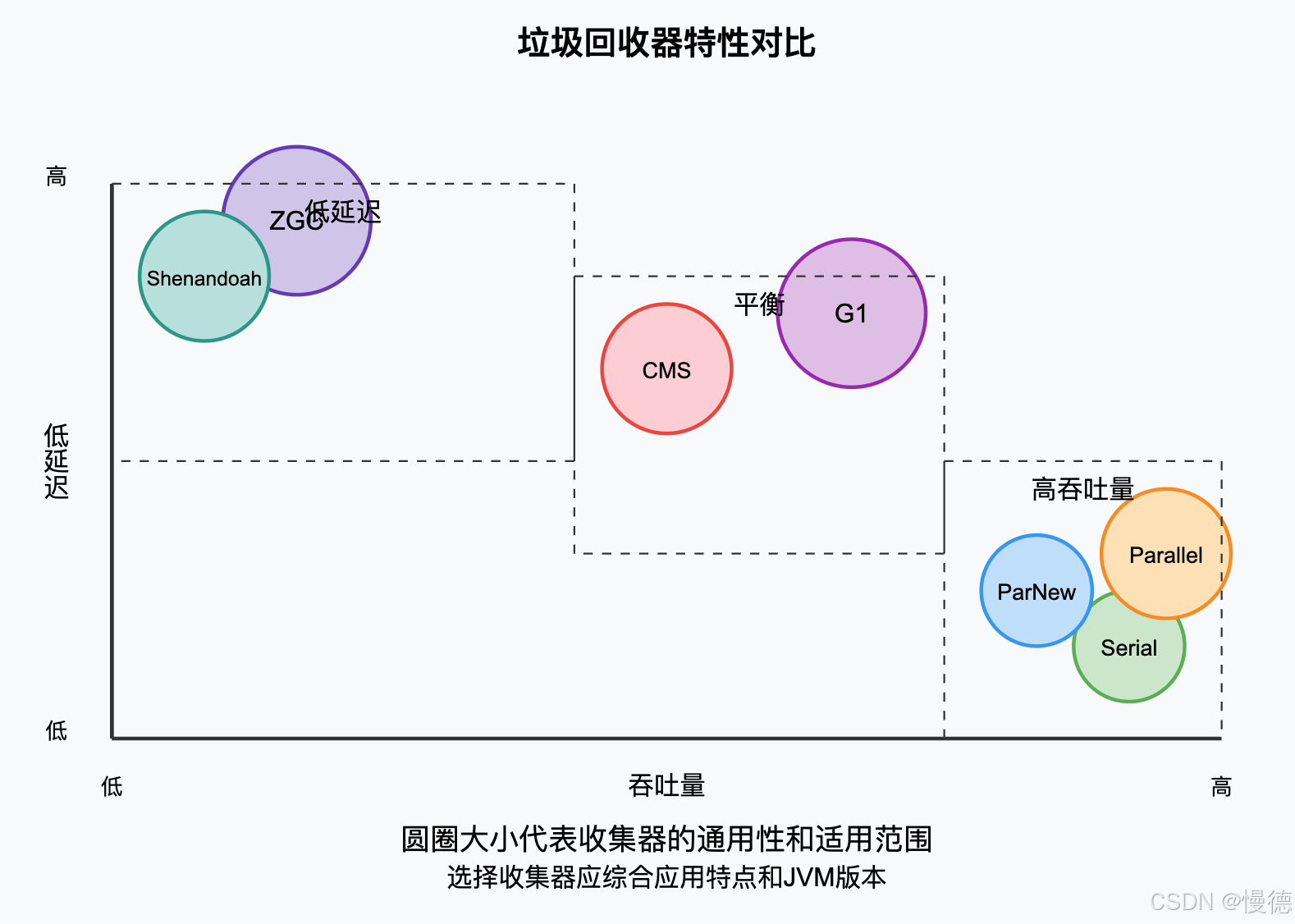
5.1 如何选择合适的垃圾回收器
-
如果应用运行在单CPU或者内存较小的环境中:
- 选择Serial + Serial Old组合,
-
如果是服务端应用,注重吞吐量:
- 选择Parallel Scavenge + Parallel Old组合,
-
如果是服务端应用,注重响应时间:
- JDK 8: 选择ParNew + CMS组合,
- JDK 9+: 使用G1收集器,
-
如果是对延迟极其敏感的应用:
- JDK 11+: 使用ZGC,
- 或者考虑Shenandoah(需要特定JDK版本支持),
-
如果不确定如何选择:
- JDK 8: 使用默认的Parallel收集器或者尝试CMS,
- JDK 9+: 使用默认的G1收集器,
5.2 配置垃圾回收器
垃圾回收器的配置主要通过JVM参数来完成,以下是一些常用的配置参数:
# Serial收集器
-XX:+UseSerialGC # 启用Serial + Serial Old组合
# ParNew + CMS收集器
-XX:+UseConcMarkSweepGC # 启用CMS(自动启用ParNew)
-XX:+UseCMSInitiatingOccupancyOnly # 使用设定的阈值启动CMS,而不是自适应调节
-XX:CMSInitiatingOccupancyFraction=70 # 设定CMS启动阈值为老年代使用70%时
# Parallel收集器
-XX:+UseParallelGC # 启用Parallel Scavenge(新生代)
-XX:+UseParallelOldGC # 启用Parallel Old(老年代)
-XX:ParallelGCThreads=4 # 设置并行收集线程数
-XX:MaxGCPauseMillis=100 # 设置最大停顿时间为100毫秒
-XX:GCTimeRatio=99 # 设置吞吐量目标(1/(1+99)=1%的时间用于GC)
# G1收集器
-XX:+UseG1GC # 启用G1收集器
-XX:MaxGCPauseMillis=200 # 设置最大停顿时间为200毫秒
-XX:G1HeapRegionSize=2m # 设置Region大小为2MB
-XX:InitiatingHeapOccupancyPercent=45 # 设置触发标记周期的Java堆占用率阈值
# ZGC收集器
-XX:+UseZGC # 启用ZGC收集器
-XX:ZCollectionInterval=5 # 设置ZGC周期为5秒
-XX:+UnlockExperimentalVMOptions # 如果是JDK11-14需要添加此选项
-XX:ConcGCThreads=2 # 设置并发GC线程数
# Shenandoah收集器
-XX:+UseShenandoahGC # 启用Shenandoah收集器
-XX:ShenandoahGCHeuristics=adaptive # 设置使用自适应策略
-XX:+UnlockExperimentalVMOptions # 如果是JDK12-14需要添加此选项
# 通用GC参数
-Xms4g # 设置初始堆大小为4GB
-Xmx4g # 设置最大堆大小为4GB
-XX:+HeapDumpOnOutOfMemoryError # 发生OOM时生成堆转储文件
-XX:HeapDumpPath=/path/to/dumps # 设置堆转储文件路径
-XX:+PrintGCDetails # 打印详细GC日志
-XX:+PrintGCDateStamps # 打印GC时间戳
-Xloggc:/path/to/gc.log # 设置GC日志路径(JDK8)
-Xlog:gc*:file=/path/to/gc.log # 设置GC日志路径(JDK9+)
六,垃圾回收调优实战
在实际工作中,垃圾回收调优是一个反复试验和优化的过程,我们来看一个真实的调优案例,
6.1 案例:电商平台订单系统GC优化
问题描述
我曾经负责一个电商平台的订单系统,在促销活动期间,系统经常出现响应延迟高,甚至偶尔会出现超时问题,通过监控发现是GC停顿时间过长导致的,
初始状态
系统使用JDK 8,默认的Parallel GC,配置如下:
-Xms4g -Xmx4g -XX:+UseParallelGC
GC日志显示,每次Full GC停顿时间长达1-2秒,严重影响用户体验,
调优过程
- 第一步:收集数据
首先启用详细GC日志:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/to/gc.log
分析GC日志,发现老年代使用率增长迅速,每隔约10分钟就会触发一次Full GC,
- 第二步:更换CMS收集器
考虑到系统对响应时间敏感,更换为CMS收集器:
-Xms6g -Xmx6g -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70
停顿时间有所改善,但仍然偶尔出现长时间停顿,分析发现是发生了"Concurrent Mode Failure",导致系统退化到使用Serial Old收集器进行Full GC,
- 第三步:调整内存分配
增大堆内存并优化内存分配比例:
-Xms8g -Xmx8g -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:NewRatio=2
"Concurrent Mode Failure"的频率降低了,但还是会出现,同时发现系统中有大量短生命周期的小对象,
- 第四步:优化代码
分析代码,发现系统中存在大量不必要的对象创建,特别是在热点代码路径中,进行了如下优化:
- 使用对象池复用频繁创建的对象,
- 减少字符串拼接操作,优先使用StringBuilder,
- 使用批量操作替代循环中的单条数据库操作,减少中间对象,
代码优化后,对象创建量显著减少,GC压力降低,
- 第五步:升级到G1收集器
最终,我们决定升级JDK版本并使用G1收集器:
-Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=200
优化结果
经过上述调优,系统在促销高峰期的表现得到显著改善:
- GC停顿时间从1-2秒降低到了200ms以内,
- 系统平均响应时间从500ms降低到了150ms,
- 促销期间的订单处理能力提升了约40%,
6.2 垃圾回收调优的一般步骤
-
确定目标
- 是减少停顿时间,还是提高吞吐量,
-
收集GC数据
- 启用GC日志,
- 使用监控工具如JVisualVM,GCViewer等分析GC行为,
-
选择合适的垃圾回收器
- 根据应用特点和目标选择,
-
调整内存大小和比例
- 堆大小(-Xms,-Xmx),
- 新生代与老年代比例(-XX:NewRatio),
- Eden与Survivor比例(-XX:SurvivorRatio),
-
优化代码
- 减少不必要的对象创建,
- 使用对象池,
- 避免过大对象,
-
测试和调整
- 在类生产环境中进行测试,
- 根据结果持续调整参数,
-
持续监控
- 建立监控系统,持续观察GC情况,
- 随着业务变化及时调整参数,
七,常见面试题解析
作为面试官,我经常会问JVM垃圾回收相关的问题,以下是一些高频面试题及答案,
7.1 如何判断对象是否可以被回收
答:主要有两种算法:引用计数法和可达性分析算法,JVM主要使用可达性分析算法,以GC Roots为起点进行搜索,如果对象不可达,则标记为可回收对象,
GC Roots包括:虚拟机栈中引用的对象,方法区中类静态属性引用的对象,方法区中常量引用的对象,本地方法栈中JNI引用的对象,
7.2 垃圾收集算法有哪些
答:主要有三种基本算法:
- 标记-清除算法:标记所有需回收对象,统一回收,缺点是效率低,产生碎片,
- 复制算法:将内存分为两块,每次只用一块,回收时将存活对象复制到另一块,缺点是内存利用率低,
- 标记-整理算法:标记后将存活对象移向一端,然后清理端边界以外的内存,
实际上JVM通常采用分代收集算法,根据对象存活周期的不同将内存划分为几块,新生代使用复制算法,老年代使用标记-整理或标记-清除算法,
7.3 描述下CMS收集器的工作原理
答:CMS(Concurrent Mark Sweep)是一种以获取最短回收停顿时间为目标的收集器,工作分为四个步骤:
- 初始标记:STW,仅标记GC Roots能直接关联的对象,
- 并发标记:耗时最长,并发进行,不会停止用户线程,
- 重新标记:STW,修正并发标记期间因用户程序继续运行而导致的标记变动,
- 并发清除:并发进行,不会停止用户线程,
优点是并发收集,低停顿,缺点是对CPU资源敏感,无法处理浮动垃圾,会产生空间碎片,
7.4 G1收集器的优势在哪里
答:G1 (Garbage-First) 收集器的优势:
- 并发与并行:利用多核CPU,使用并行和并发来减少停顿,
- 分代收集:仍然保留分代概念,但物理上不要求内存连续,
- 空间整合:基于标记-整理算法,不会产生内存碎片,
- 可预测的停顿:能够设定目标停顿时间(-XX:MaxGCPauseMillis),
- Region化内存布局:将堆分成相同大小的区域(Region),回收时可以有选择地回收部分Region,
7.5 ZGC相比于G1有什么改进
答:ZGC相比G1的主要改进:
- 更低的延迟:ZGC的STW时间通常在10ms以内,远低于G1,
- 更大的堆支持:ZGC可以高效处理TB级别的堆,
- 着色指针:ZGC使用64位指针的一些位作为标记位,实现快速对象定位,
- 读屏障:保证线程安全的同时最小化停顿时间,
- 停顿时间不随堆或存活对象数量增加而增加,
不过ZGC目前仅支持JDK 11及以上版本,且主要在Linux/x64平台上工作最佳,
7.6 Major GC和Full GC的区别
答:
- Minor GC:清理新生代,频率较高,时间较短,
- Major GC:清理老年代,通常伴随至少一次Minor GC,
- Full GC:清理整个堆内存,包括新生代,老年代和永久代(JDK 8前)或元空间(JDK 8+),
在CMS等垃圾收集器的上下文中,Major GC和Full GC有时会被混用,但严格来说它们是不同的概念,
7.7 什么情况下会触发Full GC
答:触发Full GC的情况:
- 老年代空间不足,
- 永久代/元空间空间不足,
- 手动调用System.gc()(但实际是否执行取决于JVM实现),
- CMS GC时出现promotion failed和concurrent mode failure,
- 统计信息数据决定需要进行一次Full GC,
- 堆中分配很大的对象,Eden区和两个Survivor区都放不下,
八,总结与展望
JVM垃圾回收技术经历了从单线程到多线程,从串行到并行再到并发,从全堆扫描到分代收集再到区域化收集的演变过程,目标始终是在保证系统稳定运行的前提下,尽可能减少垃圾回收对应用性能的影响,
现在的JVM垃圾回收器已经相当成熟,从Serial,ParNew,Parallel,CMS,到G1,ZGC,Shenandoah,每一代收集器都有其特点和适用场景,我们需要根据应用特性选择合适的收集器,
未来垃圾回收技术的发展方向主要有:
- 进一步减少停顿时间,甚至实现零停顿,
- 自适应学习的智能收集策略,
- 更好的硬件利用,如多核CPU,NUMA架构,非易失性内存等,
- 大数据,云原生时代的内存管理新挑战,
作为Java开发者,我们不需要了解垃圾回收的所有细节,但理解基本原理和各收集器的特点,可以作为Java开发者,可以帮助我们写出更高效的代码,也能在遇到内存问题时更快地定位和解决,
在实际工作中,我发现很多性能问题并非JVM本身的限制,而是由于代码层面的不合理设计导致的,比如创建过多临时对象,内存泄漏,或者对象过大等,因此,良好的编码习惯与合理的GC配置同样重要。
记住,最好的垃圾回收是不需要垃圾回收,编写高效代码,减少不必要的对象创建,才是解决问题的根本之道,



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









