







分布式事务,这个看似高深的技术术语,其实是现代互联网架构中必不可少的一环。我第一次接触分布式事务时,就像是误入了一片迷雾森林,各种概念和方案如同藤蔓般缠绕在一起,让人望而生畏。
经过多年实战和踩坑,今天把这些经验毫无保留地分享给大家。
什么是分布式事务
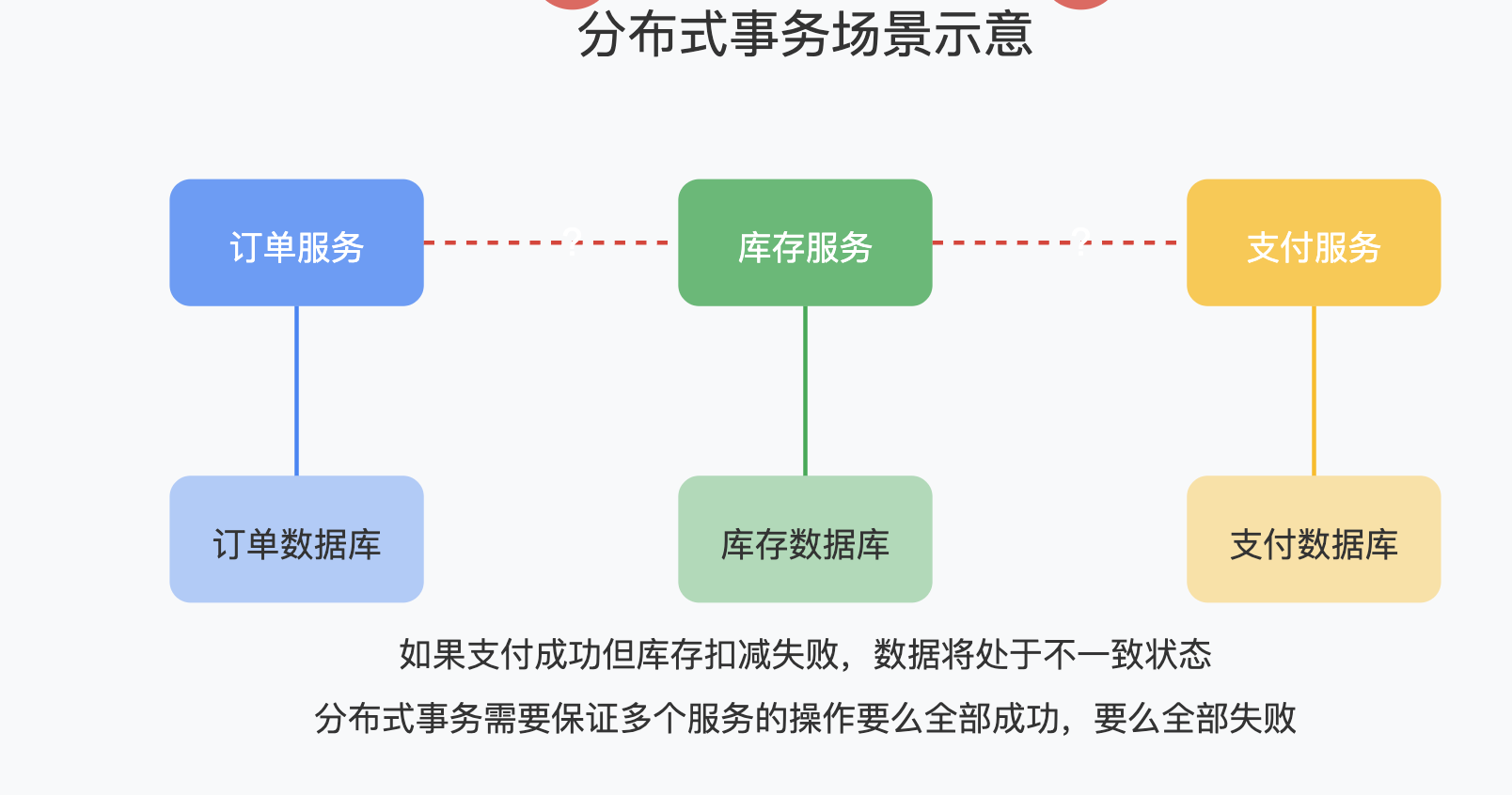
在聊框架选型之前,我们先来理解什么是分布式事务。简单来说,分布式事务就是在分布式系统环境下实现事务一致性的机制。当一个业务流程横跨多个服务,多个数据源时,如何保证这些操作要么全部成功,要么全部失败,就是分布式事务要解决的问题。
传统单机事务大家都很熟悉,遵循ACID原则:
- 原子性(Atomicity):事务是最小的执行单位,不允许分割
- 一致性(Consistency):事务执行前后,数据保持一致
- 隔离性(Isolation):并发访问数据库时,一个事务不应该影响其他事务
- 持久性(Durability):一旦事务提交,修改将永久保存
而分布式事务则面临着更多挑战,比如网络延迟,服务宕机,以及各种不可预见的故障。
分布式事务框架的发展历程
分布式事务框架的演进代表了我们对这个问题认知的不断深入。我记得早期做电商系统时,一个下单操作涉及订单服务,库存服务,支付服务,物流服务,每一次的调整都可能引发连锁反应,那段时间简直痛不欲生。直到我开始系统地研究分布式事务解决方案,才找到了一条明路。
阶段一:传统数据库XA协议
XA协议是最早的分布式事务解决方案,由X/Open组织提出。它的核心是二阶段提交(2PC):
- 准备阶段:协调者向所有参与者发送准备请求,参与者执行事务但不提交,并反馈是否可以提交
- 提交阶段:如果所有参与者都可以提交,则协调者发送提交请求,否则发送回滚请求
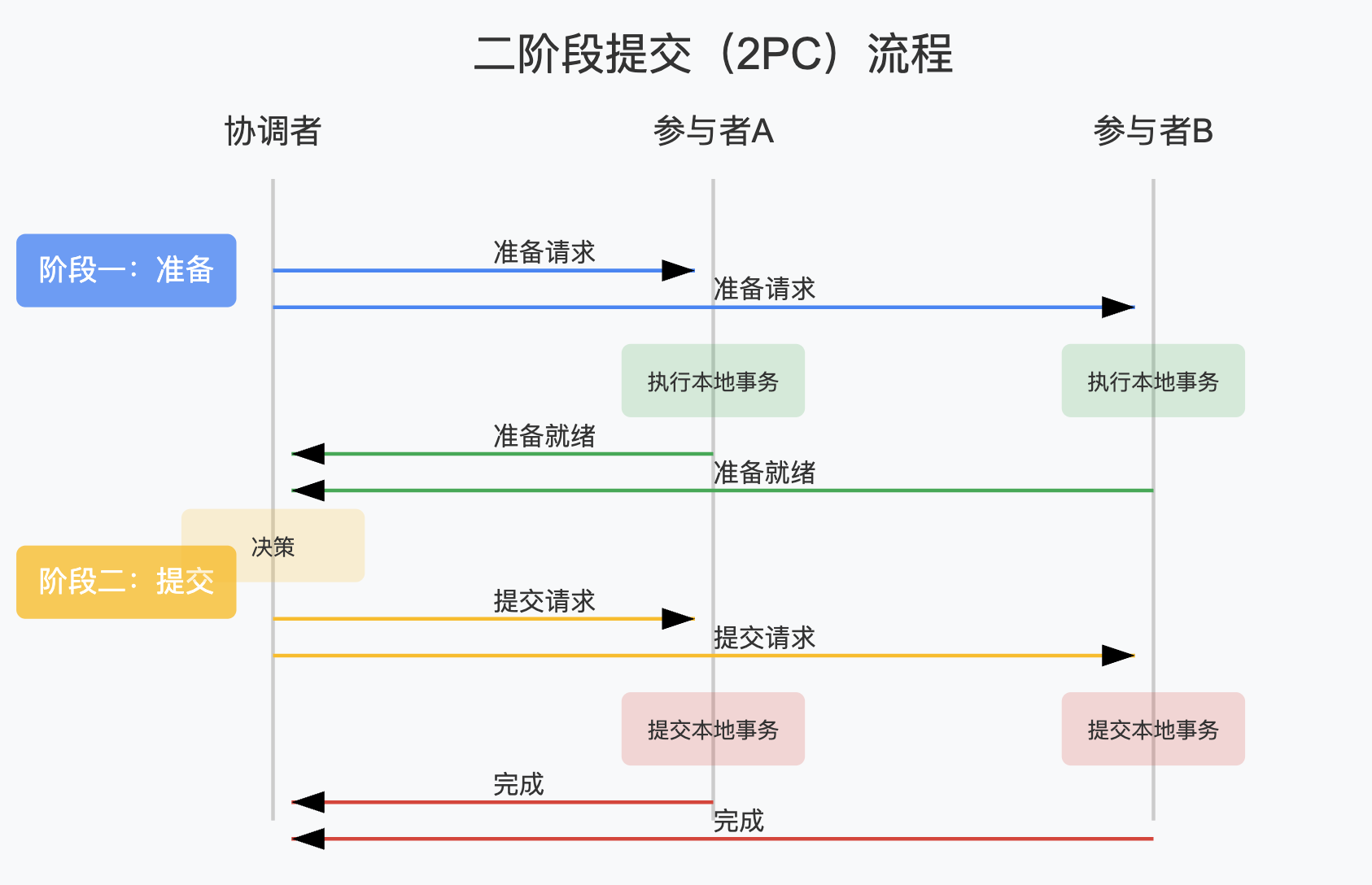
XA的优点是强一致性,符合ACID特性,且对业务侵入小。但它也存在明显缺点:
- 性能问题:同步阻塞,锁定资源时间长
- 单点问题:协调者宕机导致系统不可用
- 数据不一致风险:在特定故障场景下可能出现数据不一致
早期MySQL,Oracle等关系型数据库都支持XA协议,但随着微服务架构的流行,这种方案渐渐无法满足要求。
阶段二:TCC补偿事务
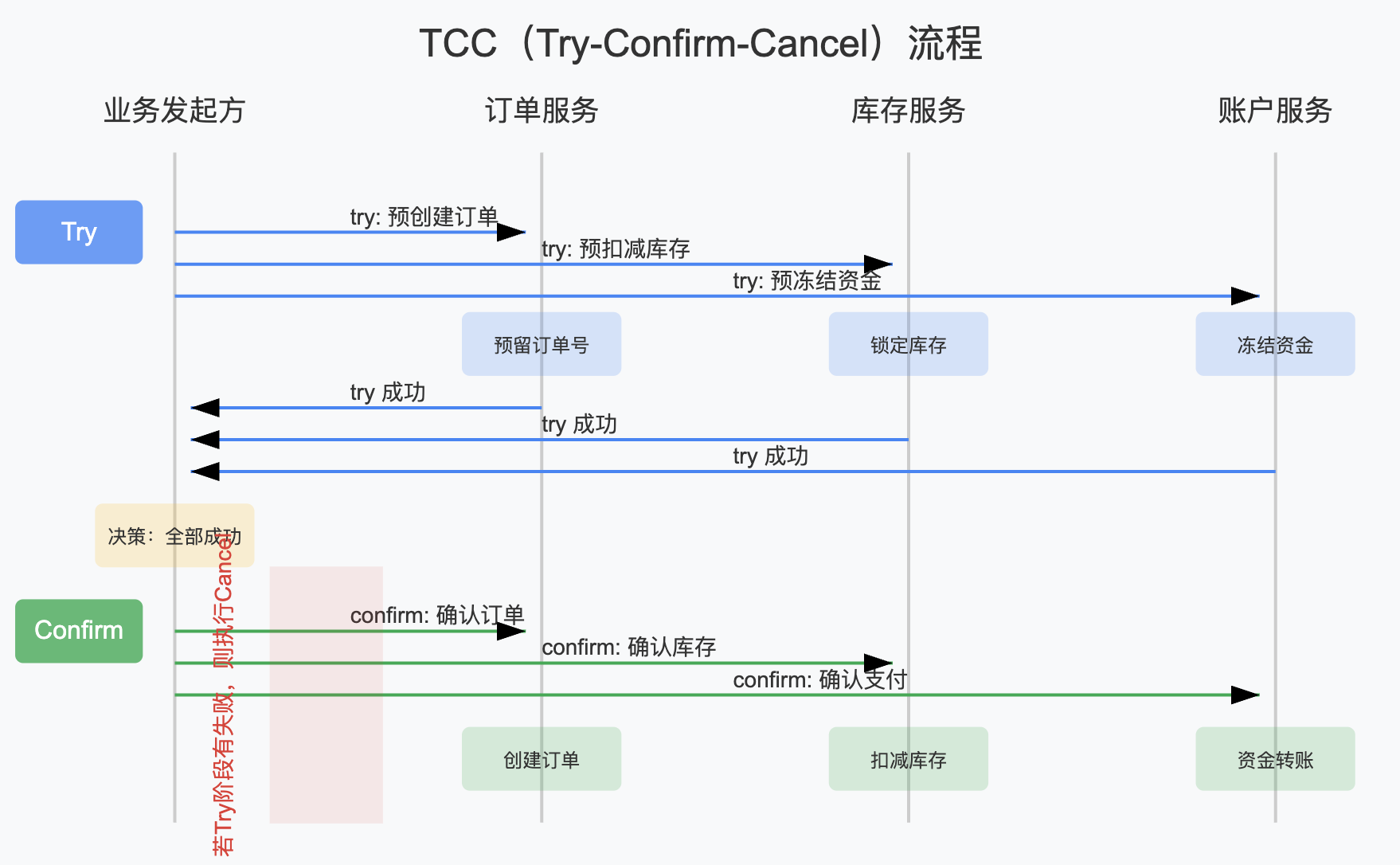
TCC(Try-Confirm-Cancel)是一种柔性事务解决方案,由支付宝团队提出。它将事务拆分为三个阶段:
- Try:资源预留,完成业务检查和预留资源
- Confirm:确认操作,实际执行业务操作
- Cancel:取消操作,释放预留资源
// 订单服务TCC接口定义
public interface OrderTCCService {
/**
* Try阶段:预创建订单
*/
boolean tryCreate(OrderDTO orderDTO);
/**
* Confirm阶段:确认创建订单
*/
boolean confirmCreate(String orderNo);
/**
* Cancel阶段:取消创建订单
*/
boolean cancelCreate(String orderNo);
}
// 库存服务TCC接口定义
public interface InventoryTCCService {
/**
* Try阶段:预扣减库存
*/
boolean tryDeduct(String productId, int count);
/**
* Confirm阶段:确认扣减库存
*/
boolean confirmDeduct(String productId, int count);
/**
* Cancel阶段:取消扣减库存
*/
boolean cancelDeduct(String productId, int count);
}
// 订单服务TCC实现
@Service
public class OrderTCCServiceImpl implements OrderTCCService {
@Autowired
private OrderMapper orderMapper;
@Override
public boolean tryCreate(OrderDTO orderDTO) {
// 1. 生成订单号
String orderNo = generateOrderNo();
// 2. 创建订单,状态为"PENDING"
Order order = new Order();
order.setOrderNo(orderNo);
order.setUserId(orderDTO.getUserId());
order.setProductId(orderDTO.getProductId());
order.setCount(orderDTO.getCount());
order.setAmount(orderDTO.getAmount());
order.setStatus("PENDING"); // 关键点:状态为PENDING,表示未确认
// 3. 保存到数据库
return orderMapper.insert(order) > 0;
}
@Override
public boolean confirmCreate(String orderNo) {
// 1. 查询订单
Order order = orderMapper.selectByOrderNo(orderNo);
if (order == null || !"PENDING".equals(order.getStatus())) {
return false;
}
// 2. 更新订单状态为"CONFIRMED"
order.setStatus("CONFIRMED");
return orderMapper.updateByPrimaryKey(order) > 0;
}
@Override
public boolean cancelCreate(String orderNo) {
// 1. 查询订单
Order order = orderMapper.selectByOrderNo(orderNo);
if (order == null) {
return false;
}
// 2. 如果订单状态为"PENDING",则删除或标记为"CANCELED"
if ("PENDING".equals(order.getStatus())) {
order.setStatus("CANCELED");
return orderMapper.updateByPrimaryKey(order) > 0;
}
return true;
}
}
// 业务服务协调TCC流程
@Service
public class BusinessService {
@Autowired
private OrderTCCService orderTCCService;
@Autowired
private InventoryTCCService inventoryTCCService;
/**
* 下单业务逻辑
*/
@Transactional
public boolean placeOrder(OrderDTO orderDTO) {
// TCC分布式事务
try {
// ==== TRY阶段 ====
// 1. 调用订单服务的try方法
boolean orderResult = orderTCCService.tryCreate(orderDTO);
if (!orderResult) {
throw new RuntimeException("订单预创建失败");
}
// 2. 调用库存服务的try方法
boolean inventoryResult = inventoryTCCService.tryDeduct(
orderDTO.getProductId(), orderDTO.getCount());
if (!inventoryResult) {
throw new RuntimeException("库存预扣减失败");
}
// ==== CONFIRM阶段 ====
// 所有try都成功,执行confirm
orderTCCService.confirmCreate(orderDTO.getOrderNo());
inventoryTCCService.confirmDeduct(orderDTO.getProductId(), orderDTO.getCount());
return true;
} catch (Exception e) {
// ==== CANCEL阶段 ====
// 如果任何一个try失败,执行cancel
orderTCCService.cancelCreate(orderDTO.getOrderNo());
inventoryTCCService.cancelDeduct(orderDTO.getProductId(), orderDTO.getCount());
throw e;
}
}
}
TCC模式的优势在于性能较高,不会长时间锁定资源,且实现了最终一致性。但缺点也很明显:
- 业务侵入性强,需要为每个服务实现try,confirm,cancel三个接口
- 实现复杂度高,需要考虑各种异常情况和幂等性设计
- 对开发人员要求高,容易出错
我曾在一个电商项目中实现TCC模式,开发初期频繁加班,同事们都对我投来同情的目光。当然,一旦踩过所有坑,系统就会运行得非常稳定。
阶段三:可靠消息最终一致性方案
为了降低业务侵入性,可靠消息方案应运而生。它基于消息中间件,通过消息的可靠投递保证事务的最终一致性。
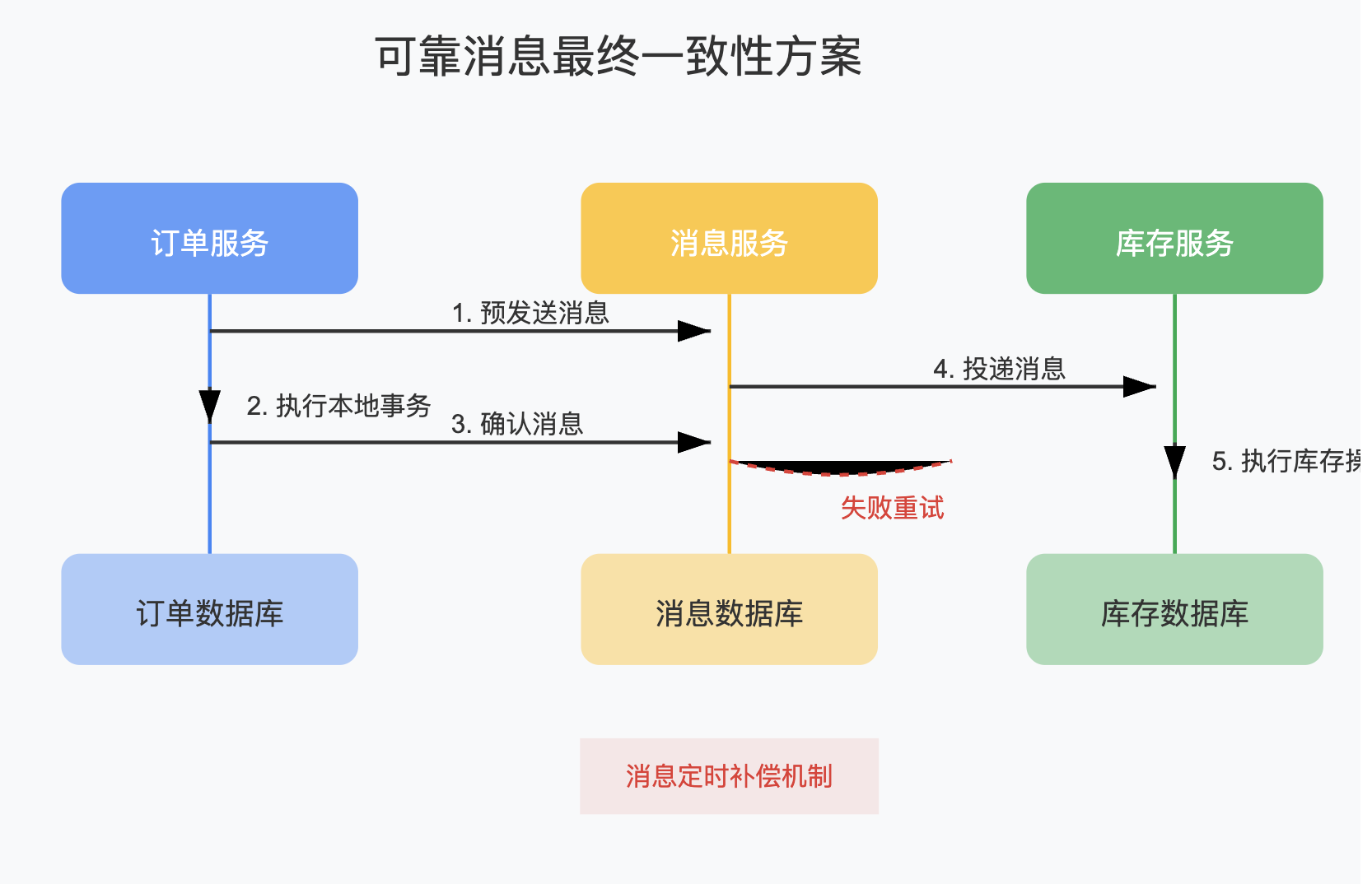
基本流程如下:
- 发送方在本地事务中,将消息保存到消息表,并标记为"待确认"状态
- 发送方执行业务操作
- 如果业务操作成功,则将消息标记为"已确认"状态
- 消息服务定时扫描消息表,投递"已确认"状态的消息到MQ
- 接收方从MQ接收消息,执行本地事务
- 如果接收方执行失败,消息服务会定时重试
优点是降低了业务侵入性,实现了最终一致性。缺点是消息会有延迟,不适合对实时性要求高的场景。我记得有次在双十一活动中使用这个方案,订单确认到库存扣减有近1分钟延迟,客服电话被打爆了。
阶段四:Saga模式
随着微服务的发展,Saga模式逐渐受到关注。它将长事务拆分为多个本地事务,由事件驱动各个子事务的执行。如果某个子事务失败,则通过补偿事务回滚之前的操作。
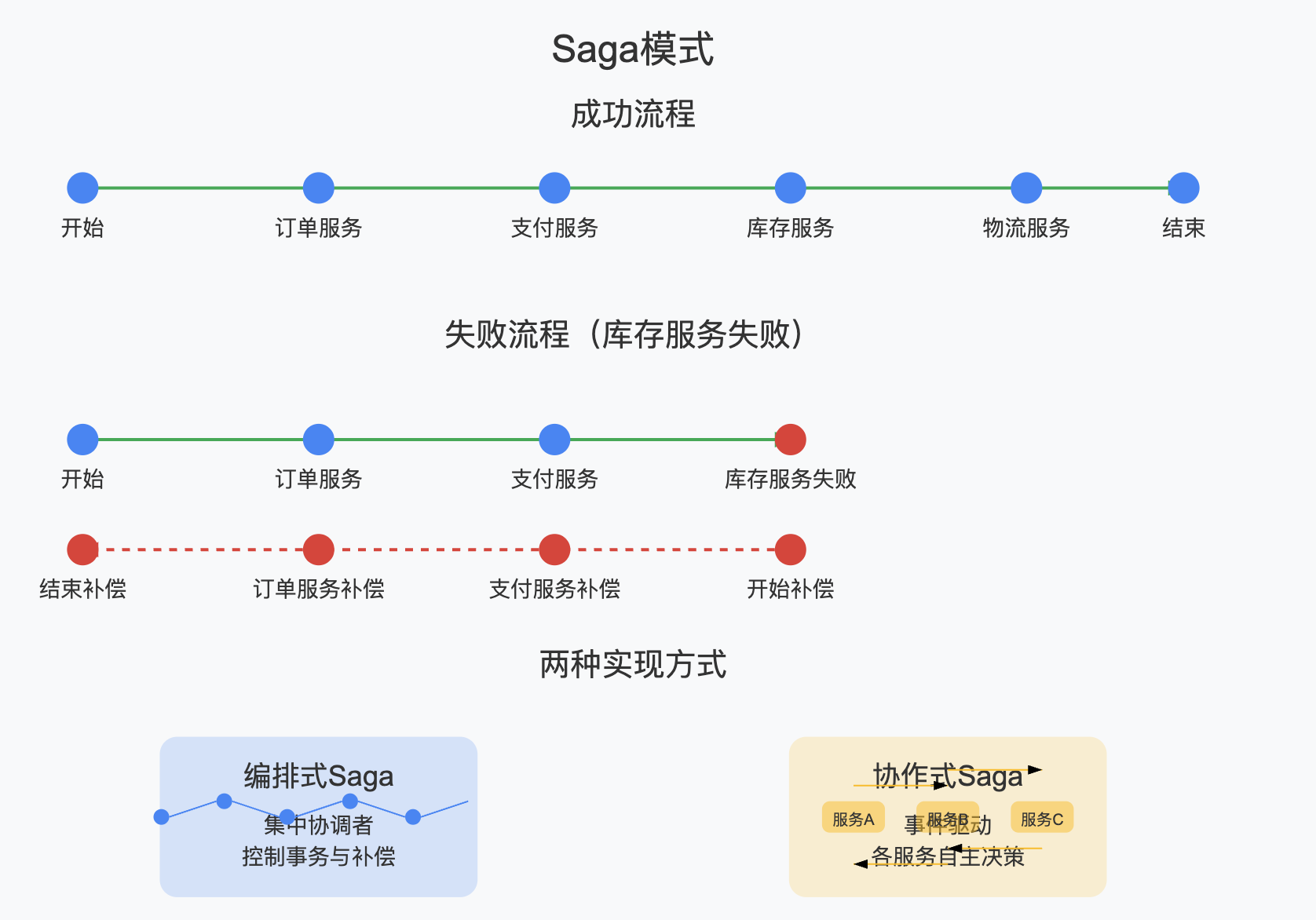
Saga有两种实现方式:
- 编排式Saga:由中央协调者负责编排和指挥各个服务的事务和补偿
- 协作式Saga:没有中央协调者,各个服务通过事件订阅触发下一步操作
代码示例:
// 编排式Saga示例(使用Saga协调者)
// 1. 定义服务接口
public interface OrderService {
// 正向操作
boolean createOrder(OrderDTO orderDTO);
// 补偿操作
boolean cancelOrder(String orderId);
}
public interface PaymentService {
// 正向操作
boolean pay(PaymentDTO paymentDTO);
// 补偿操作
boolean refund(String paymentId);
}
public interface InventoryService {
// 正向操作
boolean deduct(String productId, int count);
// 补偿操作
boolean restore(String productId, int count);
}
// 2. 定义Saga协调者
@Service
public class OrderSagaCoordinator {
@Autowired
private OrderService orderService;
@Autowired
private PaymentService paymentService;
@Autowired
private InventoryService inventoryService;
/**
* 执行下单Saga流程
*/
public boolean executeOrderSaga(OrderRequest request) {
// 保存执行上下文,用于补偿
SagaContext context = new SagaContext();
try {
// 步骤1: 创建订单
OrderDTO orderDTO = buildOrderDTO(request);
boolean orderResult = orderService.createOrder(orderDTO);
if (!orderResult) {
throw new RuntimeException("创建订单失败");
}
context.setOrderId(orderDTO.getOrderId());
// 步骤2: 支付
PaymentDTO paymentDTO = buildPaymentDTO(request, orderDTO);
boolean paymentResult = paymentService.pay(paymentDTO);
if (!paymentResult) {
// 支付失败,补偿订单
orderService.cancelOrder(orderDTO.getOrderId());
throw new RuntimeException("支付失败");
}
context.setPaymentId(paymentDTO.getPaymentId());
// 步骤3: 扣减库存
boolean inventoryResult = inventoryService.deduct(
request.getProductId(), request.getCount());
if (!inventoryResult) {
// 库存扣减失败,补偿订单和支付
paymentService.refund(paymentDTO.getPaymentId());
orderService.cancelOrder(orderDTO.getOrderId());
throw new RuntimeException("库存扣减失败");
}
return true;
} catch (Exception e) {
// 发生异常,执行补偿逻辑
compensate(context);
return false;
}
}
/**
* 执行补偿逻辑
*/
private void compensate(SagaContext context) {
// 按照反向顺序补偿
if (context.getInventoryDeducted()) {
inventoryService.restore(context.getProductId(), context.getCount());
}
if (context.getPaymentId() != null) {
paymentService.refund(context.getPaymentId());
}
if (context.getOrderId() != null) {
orderService.cancelOrder(context.getOrderId());
}
}
// 上下文对象,记录每一步的状态和结果
private static class SagaContext {
private String orderId;
private String paymentId;
private String productId;
private int count;
private boolean inventoryDeducted;
// getter and setter methods
// ...
}
}
// 协作式Saga示例(事件驱动)
// 1. 定义事件
public class OrderCreatedEvent {
private String orderId;
private String userId;
private String productId;
private int count;
private BigDecimal amount;
// getter and setter
}
public class PaymentCompletedEvent {
private String orderId;
private String paymentId;
private BigDecimal amount;
// getter and setter
}
public class PaymentFailedEvent {
private String orderId;
// getter and setter
}
// 2. 订单服务实现
@Service
public class OrderServiceImpl {
@Autowired
private OrderRepository orderRepository;
@Autowired
private EventBus eventBus; // 事件总线,可以是Kafka, RabbitMQ等
public void createOrder(OrderRequest request) {
// 创建订单
Order order = new Order();
order.setUserId(request.getUserId());
order.setProductId(request.getProductId());
order.setCount(request.getCount());
order.setAmount(request.getAmount());
order.setStatus("CREATED");
orderRepository.save(order);
// 发布订单创建事件
OrderCreatedEvent event = new OrderCreatedEvent();
event.setOrderId(order.getId());
event.setUserId(order.getUserId());
event.setProductId(order.getProductId());
event.setCount(order.getCount());
event.setAmount(order.getAmount());
eventBus.publish("order-created", event);
}
@EventListener("payment-failed")
public void handlePaymentFailed(PaymentFailedEvent event) {
// 补偿逻辑:取消订单
Order order = orderRepository.findById(event.getOrderId());
order.setStatus("CANCELED");
orderRepository.save(order);
}
}
// 3. 支付服务实现
@Service
public class PaymentServiceImpl {
@Autowired
private PaymentRepository paymentRepository;
@Autowired
private EventBus eventBus;
@EventListener("order-created")
public void handleOrderCreated(OrderCreatedEvent event) {
try {
// 执行支付
Payment payment = new Payment();
payment.setOrderId(event.getOrderId());
payment.setAmount(event.getAmount());
payment.setStatus("PENDING");
// 调用支付接口
boolean success = doPayment(payment);
if (success) {
payment.setStatus("COMPLETED");
paymentRepository.save(payment);
// 发布支付成功事件
PaymentCompletedEvent completedEvent = new PaymentCompletedEvent();
completedEvent.setOrderId(event.getOrderId());
completedEvent.setPaymentId(payment.getId());
completedEvent.setAmount(payment.getAmount());
eventBus.publish("payment-completed", completedEvent);
} else {
payment.setStatus("FAILED");
paymentRepository.save(payment);
// 发布支付失败事件
PaymentFailedEvent failedEvent = new PaymentFailedEvent();
failedEvent.setOrderId(event.getOrderId());
eventBus.publish("payment-failed", failedEvent);
}
} catch (Exception e) {
// 发布支付失败事件
PaymentFailedEvent failedEvent = new PaymentFailedEvent();
failedEvent.setOrderId(event.getOrderId());
eventBus.publish("payment-failed", failedEvent);
}
}
}
Saga模式适合长事务业务流程,具有事务周期长,多服务协作的特点。优点是可以实现最终一致性,且可以细粒度控制补偿流程。缺点是没有隔离性保证,可能出现脏读问题。
阶段五:Seata框架的AT模式
说到分布式事务框架,不得不提阿里开源的Seata,它提供了几种事务模式,其中AT模式最受欢迎。AT模式基于两阶段提交协议改进,解决了XA协议锁定资源时间长的问题。
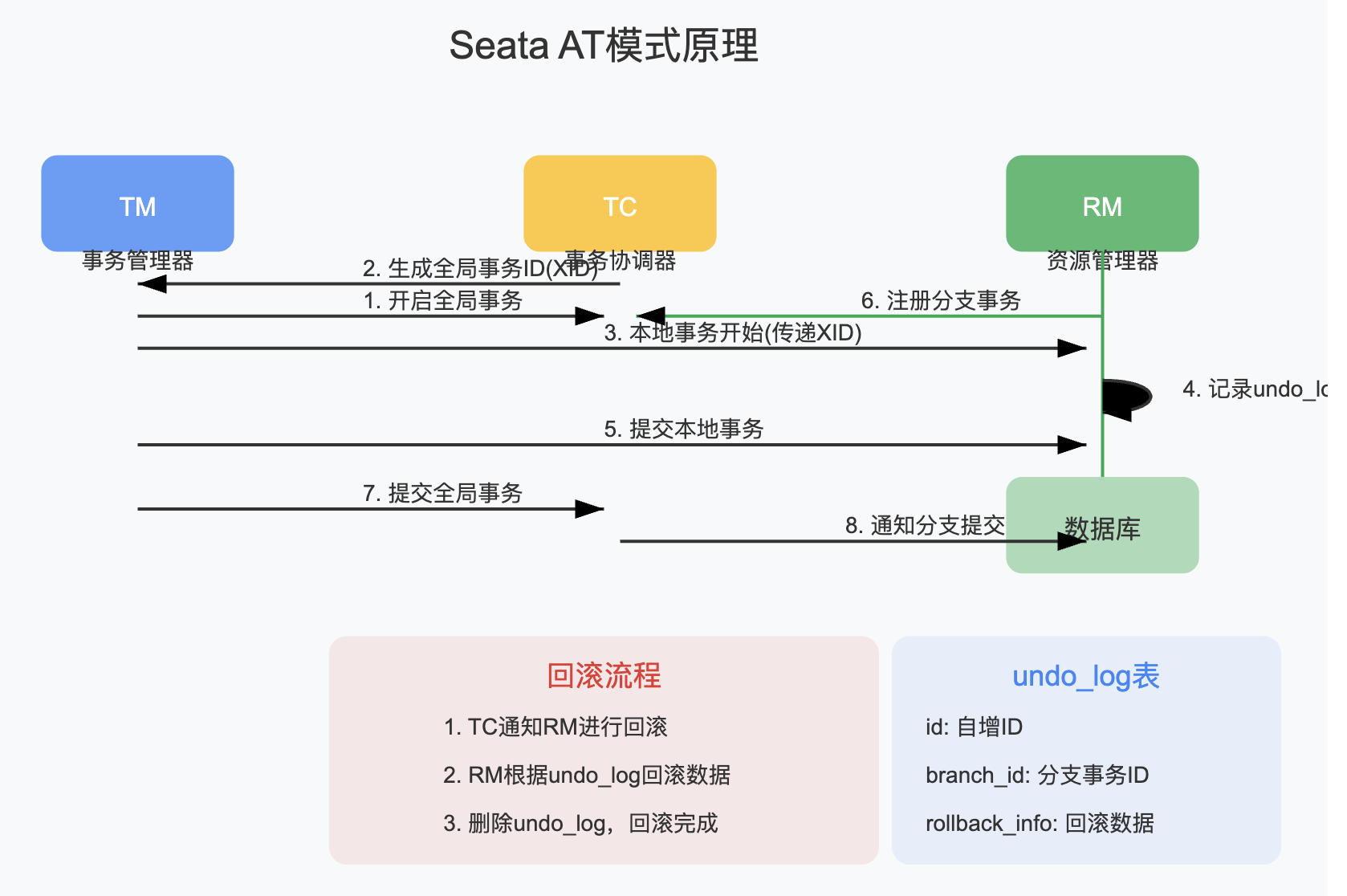
Seata的AT模式工作原理可以简单理解为"自动化的TCC",它通过拦截SQL并自动生成反向SQL来实现回滚,对业务的侵入性极小。该模式中有三个重要角色:
- TM(Transaction Manager):全局事务管理器,负责开启、提交或回滚全局事务
- RM(Resource Manager):资源管理器,负责分支事务的注册、状态汇报,并驱动分支事务的提交或回滚
- TC(Transaction Coordinator):事务协调器,负责协调全局事务的处理流程,负责维护全局事务的状态
AT模式的实现步骤:
// 1. 首先在应用中引入Seata依赖
// pom.xml
/*
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.5.2</version>
</dependency>
*/
// 2. 配置Seata
// application.yml
/*
seata:
enabled: true
application-id: ${spring.application.name}
tx-service-group: my_test_tx_group
service:
vgroup-mapping:
my_test_tx_group: default
grouplist:
default: 127.0.0.1:8091
registry:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
namespace: public
cluster: default
*/
// 3. 在数据库中创建undo_log表
/*
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
*/
// 4. 编写业务代码
// 订单服务
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private AccountFeignClient accountFeignClient;
@Autowired
private ProductFeignClient productFeignClient;
/**
* 创建订单
* @GlobalTransactional 注解开启全局事务,这里是TM的角色
*/
@Override
@GlobalTransactional(name = "create-order-tx", rollbackFor = Exception.class)
public void createOrder(OrderDTO orderDTO) {
// 1. 创建订单
Order order = new Order();
order.setUserId(orderDTO.getUserId());
order.setProductId(orderDTO.getProductId());
order.setCount(orderDTO.getCount());
order.setAmount(orderDTO.getAmount());
order.setStatus("CREATED");
orderMapper.insert(order);
// 2. 扣减账户余额
accountFeignClient.decreaseBalance(orderDTO.getUserId(), orderDTO.getAmount());
// 3. 扣减商品库存
productFeignClient.decreaseStock(orderDTO.getProductId(), orderDTO.getCount());
}
}
// 账户服务
@Service
public class AccountServiceImpl implements AccountService {
@Autowired
private AccountMapper accountMapper;
/**
* 扣减账户余额
* 这里RM的角色由Seata自动代理
*/
@Override
public void decreaseBalance(String userId, BigDecimal amount) {
Account account = accountMapper.selectByUserId(userId);
if (account.getBalance().compareTo(amount) < 0) {
throw new RuntimeException("账户余额不足");
}
// 扣减余额
account.setBalance(account.getBalance().subtract(amount));
accountMapper.updateByPrimaryKey(account);
}
}
// 商品服务
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductMapper productMapper;
/**
* 扣减商品库存
* 这里RM的角色由Seata自动代理
*/
@Override
public void decreaseStock(String productId, int count) {
Product product = productMapper.selectByProductId(productId);
if (product.getStock() < count) {
throw new RuntimeException("商品库存不足");
}
// 扣减库存
product.setStock(product.getStock() - count);
productMapper.updateByPrimaryKey(product);
}
}
// 5. 如何使用Feign进行服务调用
// OrderFeignClient.java
@FeignClient(name = "account-service")
public interface AccountFeignClient {
@PostMapping("/account/decrease")
void decreaseBalance(@RequestParam("userId") String userId,
@RequestParam("amount") BigDecimal amount);
}
@FeignClient(name = "product-service")
public interface ProductFeignClient {
@PostMapping("/product/decrease")
void decreaseStock(@RequestParam("productId") String productId,
@RequestParam("count") int count);
}
Seata AT模式的优势在于对业务代码几乎无侵入,通过简单的注解即可实现分布式事务,对开发者非常友好。当我第一次使用Seata时,简直有种相见恨晚的感觉,之前被TCC折磨的日子仿佛噩梦一般。
不过AT模式也有一些局限性:
- 性能问题:需要额外的表和事务日志
- 隔离级别:默认是读未提交,可能出现脏读
- 对数据库有要求:支持事务的关系型数据库
阶段六:Seata的其他模式
除了AT模式,Seata还提供了其他几种模式:
- TCC模式:就是我们前面提到的Try-Confirm-Cancel模式
- Saga模式:基于状态机的长事务解决方案
- XA模式:对XA协议的封装,提供强一致性
每种模式适用的场景不同,我们需要根据业务特点选择合适的模式。
分布式事务框架选型对比
通过对各种分布式事务方案的了解,我们可以进行一个简单的对比:
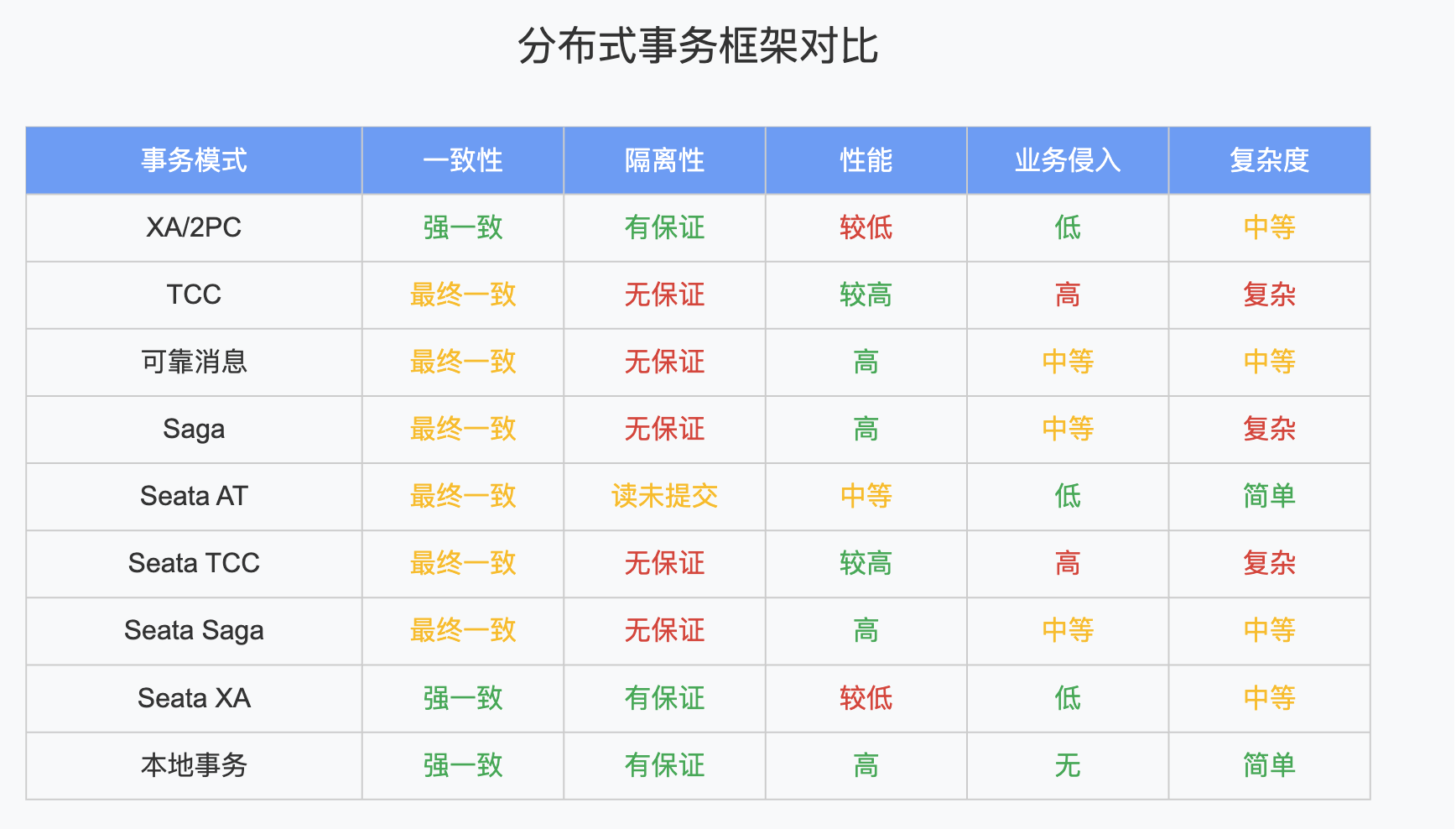
选型指南:如何选择合适的分布式事务框架
基于上面的对比,我们可以得出一些选型建议:
-
首先考虑是否可以避免分布式事务
- 数据分区:每个服务管理自己的数据,避免跨服务事务
- 单体退化:核心流程保持在单体应用中
- 最终一致性:接受数据短暂不一致,通过异步方式最终达到一致
-
如果必须使用分布式事务,可以按照以下思路选择:
- 强一致性要求高,性能要求不高:选择XA或Seata XA
- 对业务侵入性要求低:选择Seata AT
- 性能要求高,可接受最终一致性:TCC或Saga
- 需要长事务支持:Saga模式
- 跨异构系统:消息最终一致性方案
-
在微服务架构中,我个人建议:
- 新项目或重构项目建议使用Seata AT模式,开发成本低
- 如果系统对性能要求极高,可以考虑TCC模式,但要做好应对复杂性的准备
- 对于涉及金融交易的核心系统,建议使用强一致性的XA模式
- 对于业务流程长,涉及人工操作的场景,推荐使用Saga模式
我在实战中经历了从XA到TCC,再到Seata AT的转变过程。当年被TCC那三个接口折磨到头秃,现在回想起来仍心有余悸。特别是在业务复杂的系统中,每个服务都要实现三个接口,代码量翻了三倍不说,测试还特别复杂。后来发现Seata,真是相见恨晚。
常见分布式事务框架对比
除了前面讲的Seata,还有一些常用的分布式事务框架值得了解:
- Hmily:一个高性能的TCC框架,侧重于TCC模式的实现,支持多种RPC框架
- ByteTCC:一个简单的TCC框架,支持Spring Cloud,Dubbo等
- EasyTransaction:支持多种事务模式,包括TCC,最大努力通知等
- TX-LCN:基于代理的分布式事务框架,通过拦截本地事务的提交来实现全局事务
这些框架各有特点,但就生态和社区活跃度来说,Seata无疑是当前最好的选择。我曾经尝试过Hmily,虽然性能不错,但文档和社区支持相对薄弱,遇到问题时很难找到解决方案。
分布式事务的最佳实践
在实际项目中,我总结了一些分布式事务的最佳实践:
-
尽量避免分布式事务
- 服务设计时遵循领域边界,减少跨服务调用
- 可以考虑将强相关的微服务合并,减少分布式事务的需求
-
保证幂等性
- 所有参与分布式事务的接口必须实现幂等,防止重复执行
- 可以使用业务ID或唯一标识符来检查操作是否已执行
-
合理设置超时时间
- 避免事务长时间挂起,占用系统资源
- 设置合理的超时重试机制
-
做好异常处理
- 捕获并记录事务执行过程中的所有异常
- 实现完善的监控和告警机制
-
数据一致性检查
- 实现定时任务,检查数据一致性
- 提供手动修复数据的工具和流程
-
灰度发布
- 新引入分布式事务框架时,先小范围测试
- 逐步扩大应用范围,确保系统稳定
面试热点:关于分布式事务的高频问题
作为一名技术面试官,我经常会问候选人一些关于分布式事务的问题。这里分享一些高频问题及参考答案:
-
CAP定理是什么,分布式事务框架在CAP中如何取舍?
- CAP定理指的是在分布式系统中,一致性(Consistency),可用性(Availability),分区容错性(Partition tolerance)三者不可能同时满足,最多只能满足其中两者
- XA协议追求CP,牺牲了A(可用性)
- BASE理论(TCC,Saga等)追求AP,牺牲了C(强一致性)
-
分布式事务的隔离级别如何保证?
- 大多数分布式事务框架默认隔离级别较低,如读未提交
- 要实现更高的隔离级别,通常需要引入分布式锁或版本控制机制
- Seata AT通过全局锁来提高隔离级别,但会牺牲一部分性能
-
如何处理分布式事务超时?
- 超时处理策略:定时任务检查长时间未完成的事务
- 默认回滚:超时自动触发回滚操作
- 人工干预:对于特殊场景,提供人工处理接口
-
TCC与Saga模式的主要区别?
- TCC是两阶段提交的应用层实现,需要显式定义Try,Confirm,Cancel三个接口
- Saga是长事务解决方案,通过补偿事务实现回滚
- TCC实现复杂但性能较好,Saga实现相对简单但事务执行时间长
-
如何保证分布式事务的性能?
- 减少锁冲突:合理设计业务逻辑,避免热点数据
- 缩短事务执行时间:将非关键操作移出事务
- 批量处理:合并多个小事务为一个大事务
- 异步化:非关键流程采用异步处理
结语
分布式事务是分布式系统中不可避免的挑战,随着微服务架构的普及,掌握分布式事务的原理和实践变得越来越重要。从最早的XA协议到现在的Seata框架,分布式事务解决方案已经发展了很多年,每种方案都有其适用场景和局限性。
作为架构师,我们需要根据业务特点选择合适的事务模式,并不断优化系统设计,减少分布式事务的使用。
正如那句老话:“最好的分布式事务是不需要分布式事务”。
希望这篇文章能帮助大家更好地理解分布式事务,在实际工作中做出正确的技术选型。


















 2670
2670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











