




1、安装 pytorch https://pytorch.org/get-started/locally/ 点击进入官网,如图选择自己的环境得到pip安装依赖的命令:
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cpu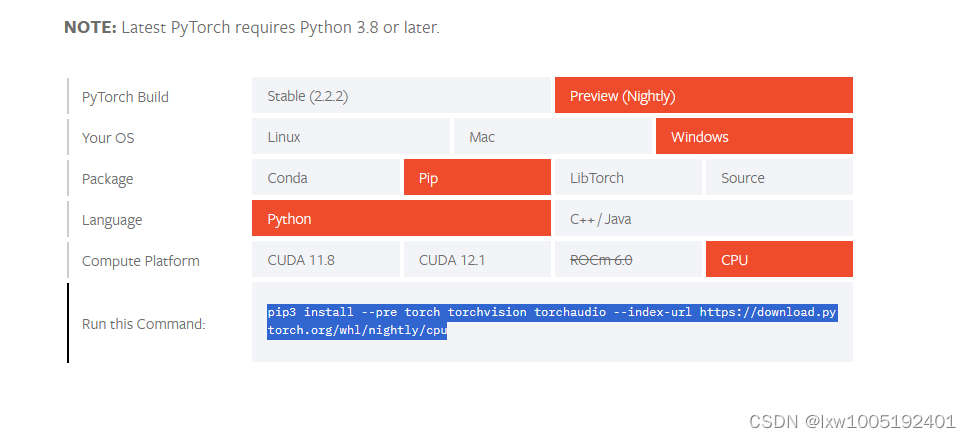
2、拉取代码并安装依赖
# 拉取代码
git clone https://github.com/QwenLM/Qwen-7B.git
# 进入代码目录
cd Qwen-7B
# 安装依赖
pip install -r requirements.txt
# 安装 web_demo 依赖
pip install -r requirements_web_demo.txt检出的项目为启动项目:Qwen-7B,不包含预训练好的模型文件。
3、启动模型
python web_demo.py --server-port 8087 --server-name "0.0.0.0"
不出意外的话,这里要出现意外了。OSError: We couldn't connect to 'https://huggingface.co' t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3930
3930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









