




文章目录
一、待解决问题
1.1 问题描述
为了在自建环境上使用mappo算法,偶然发现了大佬使用的mappo框架,对其学习理解并复现。
1.2 解决方法
(1)搭建基础环境
(2)代码复现及结果展示
(3)Combat环境介绍
(4)代码框架理解
二、方法详述
2.1 必要说明
此处mappo应用框架的来源为,名为simple_mappo:
【史上最简】300行代码搞定 MAPPO算法原理+代码讲解
Github的源码分享为:
https://github.com/Guowei-Zou/simple_mappo.git
✅非常感谢大佬的分享!!!
2.2 应用步骤
2.2.1 搭建基础环境
基于conda创建虚拟环境,安装torch,并安装框架中实例应用的多智能体环境ma-gym。
具体而言,ma-gym的源码为:
https://github.com/koulanurag/ma-gym
其中,对于gym版本和pip、setuptools、wheel版本有要求。
conda create -n simple_mappo python=3.11
conda activate simple_mappo
pip install pip==24.0
pip install setuptools==65.5.0
pip install wheel==0.38.4
pip3 install torch torchvision torchaudio
pip install tqdm
conda install matplotlib
将ma-gym源码下载到本地后
cd ma-gym-master/
pip install -e .
conda list | grep gym
conda list | grep ma-gym
conda install spyder
查询gym和ma-gym的版本分别为:0.20.0,0.0.14
2.2.2 代码复现及结果展示
打开python 的IDE(这里选用spyder),将simple_mappo 的源码运行。
import os
import shutil
from time import sleep
import torch
import torch.nn.functional as F
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import sys
#sys.path.append("./ma-gym-master")
from ma_gym.envs.combat.combat import Combat
# 清空日志文件和绘图文件夹
log_file = "training_log_metrics_weight.txt"
plot_dir = "plots_metrics_weight"
if os.path.exists(log_file):
open(log_file, "w").close()
if os.path.exists(plot_dir):
shutil.rmtree(plot_dir)
os.makedirs(plot_dir)
# 日志记录函数
def log_message(message):
with open(log_file, "a") as f:
f.write(message + "\n")
def plot_all_metrics(metrics_dict, episode):
"""
将所有指标绘制到一个包含多个子图的图表中
- 对曲线进行平滑处理
- 添加误差带显示
参数:
metrics_dict: 包含所有指标数据的字典,格式为 {metric_name: values_list}
episode: 当前的episode数
"""
# 创建一个2x3的子图布局
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
fig.suptitle(f'Training Metrics (Up to Episode {episode})', fontsize=16)
# 压平axes数组以便迭代
axes = axes.flatten()
# 为每个指标获取x轴值
any_metric = list(metrics_dict.values())[0]
x_values = [50 * (i + 1) for i in range(len(any_metric))]
# 平滑参数 - 窗口大小
window_size = min(5, len(x_values)) if len(x_values) > 0 else 1
# 在每个子图中绘制一个指标
for i, (metric_name, values) in enumerate(metrics_dict.items()):
if i >= 5: # 我们只有5个指标
break
ax = axes[i]
values_array = np.array(values)
# 应用平滑处理
if len(values) > window_size:
# 创建平滑曲线
smoothed = np.convolve(values_array, np.ones(window_size)/window_size, mode='valid')
# 计算滚动标准差用于误差带
std_values = []
for j in range(len(values) - window_size + 1):
std_values.append(np.std(values_array[j:j+window_size]))
std_values = np.array(std_values)
# 调整x轴以匹配平滑后的数据长度
smoothed_x = x_values[window_size-1:]
# 绘制平滑曲线和原始散点
ax.plot(smoothed_x, smoothed, '-', linewidth=2, label='Smoothed')
ax.scatter(x_values, values, alpha=0.3, label='Original')
# 添加误差带
ax.fill_between(smoothed_x, smoothed-std_values, smoothed+std_values,
alpha=0.2, label='±1 StdDev')
else:
# 如果数据点太少,只绘制原始数据
ax.plot(x_values, values, 'o-', label='Data')
ax.set_title(metric_name.replace('_', ' '))
ax.set_xlabel('Episodes')
ax.set_ylabel(metric_name.replace('_', ' '))
ax.grid(True, alpha=0.3)
ax.legend()
# 删除未使用的子图
if len(metrics_dict) < 6:
fig.delaxes(axes[5])
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.savefig(os.path.join(plot_dir, f'training_metrics.png'))
plt.close(fig)
def compute_entropy(probs):
dist = torch.distributions.Categorical(probs)
return dist.entropy().mean().item()
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().cpu().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
# 策略网络(Actor)
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return F.softmax(self.fc3(x), dim=1)
# 全局价值网络(CentralValueNet)
# 输入: 所有智能体的状态拼接 (team_size * state_dim)
# 输出: 对每个智能体的价值估计 (team_size维向量)
class CentralValueNet(torch.nn.Module):
def __init__(self, total_state_dim, hidden_dim, team_size):
super(CentralValueNet, self).__init__()
self.fc1 = torch.nn.Linear(total_state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, team_size) # 输出为每个智能体一个价值
def forward(self, x):
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return self.fc3(x) # [batch, team_size]
class MAPPO:
def __init__(self, team_size, state_dim, hidden_dim, action_dim,
actor_lr, critic_lr, lmbda, eps, gamma, device):
self.team_size = team_size
self.gamma = gamma
self.lmbda = lmbda
self.eps = eps
self.device = device
# 为每个智能体一个独立的actor
self.actors = [PolicyNet(state_dim, hidden_dim, action_dim).to(device)
for _ in range(team_size)]
# 一个全局critic,输入为所有智能体状态拼接
self.critic = CentralValueNet(team_size * state_dim, hidden_dim, team_size).to(device)
self.actor_optimizers = [torch.optim.Adam(actor.parameters(), actor_lr)
for actor in self.actors]
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), critic_lr)
def save_model(self, path="mappo_weights"):
if not os.path.exists(path):
os.makedirs(path)
for i, actor in enumerate(self.actors):
torch.save(actor.state_dict(), os.path.join(path, f"actor_{i}.pth"))
torch.save(self.critic.state_dict(), os.path.join(path, "critic.pth"))
def load_model(self, path="mappo_weights"):
for i, actor in enumerate(self.actors):
actor_path = os.path.join(path, f"actor_{i}.pth")
if os.path.exists(actor_path):
actor.load_state_dict(torch.load(actor_path))
critic_path = os.path.join(path, "critic.pth")
if os.path.exists(critic_path):
self.critic.load_state_dict(torch.load(critic_path))
def take_action(self, state_per_agent):
# state_per_agent: list of shape [team_size, state_dim]
actions = []
action_probs = []
for i, actor in enumerate(self.actors):
s = torch.tensor([state_per_agent[i]], dtype=torch.float).to(self.device)
probs = actor(s)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
actions.append(action.item())
action_probs.append(probs.detach().cpu().numpy()[0])
return actions, action_probs
def update(self, transition_dicts, state_dim):
# 拼接所有智能体的数据,用于全局critic
# 首先统一长度T,假设所有智能体长度相同(因为同步环境步)
T = len(transition_dicts[0]['states'])
# print(f"T: {T}")
# 将所有智能体在同一时间步的state拼接起来,得到 [T, team_size*state_dim]
states_all = []
next_states_all = []
for t in range(T):
concat_state = []
concat_next_state = []
for i in range(self.team_size):
concat_state.append(transition_dicts[i]['states'][t])
concat_next_state.append(transition_dicts[i]['next_states'][t])
states_all.append(np.concatenate(concat_state))
next_states_all.append(np.concatenate(concat_next_state))
states_all = torch.tensor(states_all, dtype=torch.float).to(self.device) # [T, team_size*state_dim]
next_states_all = torch.tensor(next_states_all, dtype=torch.float).to(self.device) # [T, team_size*state_dim]
rewards_all = torch.tensor([ [transition_dicts[i]['rewards'][t] for i in range(self.team_size)]
for t in range(T)], dtype=torch.float).to(self.device) # [T, team_size]
dones_all = torch.tensor([ [transition_dicts[i]['dones'][t] for i in range(self.team_size)]
for t in range(T)], dtype=torch.float).to(self.device) # [T, team_size]
# 从critic计算价值和TD-target
values = self.critic(states_all) # [T, team_size]
next_values = self.critic(next_states_all) # [T, team_size]
td_target = rewards_all + self.gamma * next_values * (1 - dones_all) # [T, team_size]
td_delta = td_target - values # [T, team_size]
# 为每个智能体计算其优势
advantages = []
for i in range(self.team_size):
adv_i = compute_advantage(self.gamma, self.lmbda, td_delta[:, i])
advantages.append(adv_i.to(self.device)) # [T]
# 更新critic
# critic的loss是所有智能体的均方误差平均
critic_loss = F.mse_loss(values, td_target.detach())
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 更新每个智能体的actor
action_losses = []
entropies = []
for i in range(self.team_size):
states = torch.tensor(transition_dicts[i]['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dicts[i]['actions']).view(-1, 1).to(self.device)
old_probs = torch.tensor(transition_dicts[i]['action_probs'], dtype=torch.float).to(self.device)
current_probs = self.actors[i](states) # [T, action_dim]
log_probs = torch.log(current_probs.gather(1, actions))
old_log_probs = torch.log(old_probs.gather(1, actions)).detach()
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantages[i].unsqueeze(-1)
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantages[i].unsqueeze(-1)
action_loss = torch.mean(-torch.min(surr1, surr2))
entropy_val = compute_entropy(current_probs)
self.actor_optimizers[i].zero_grad()
action_loss.backward()
self.actor_optimizers[i].step()
action_losses.append(action_loss.item())
entropies.append(entropy_val)
return np.mean(action_losses), critic_loss.item(), np.mean(entropies)
# 参数设置
actor_lr = 3e-4
critic_lr = 1e-3
total_episodes = 1000
hidden_dim = 64
gamma = 0.99
lmbda = 0.97
eps = 0.3
team_size = 2
grid_size = (20, 20)
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
# 创建环境
env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)
state_dim = env.observation_space[0].shape[0]
action_dim = env.action_space[0].n
# 创建MAPPO智能体(共有team_size个actor, 一个共享critic)
mappo = MAPPO(team_size, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda, eps, gamma, device)
# 用于统计指标的列表
total_rewards_per_episode = []
episode_lengths = []
policy_losses = []
value_losses = []
entropies = []
# 每50个episode的平均值列表
avg_total_rewards_per_50 = []
avg_episode_length_per_50 = []
avg_policy_loss_per_50 = []
avg_value_loss_per_50 = []
avg_entropy_per_50 = []
with tqdm(total=total_episodes, desc="Training") as pbar:
for episode in range(1, total_episodes + 1):
# 初始化Trajectory buffer
buffers = [{
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': [],
'action_probs': []
} for _ in range(team_size)]
s = env.reset()
terminal = False
episode_reward = 0.0
steps = 0
while not terminal:
steps += 1
# MAPPO中,每个智能体仍独立选择动作,但critic共享
actions, prob_dists = mappo.take_action(s)
next_s, r, done, info = env.step(actions)
# 累计总奖励
step_reward = sum(r)
episode_reward += step_reward
# 存储transition
for i in range(team_size):
buffers[i]['states'].append(np.array(s[i]))
buffers[i]['actions'].append(actions[i])
buffers[i]['next_states'].append(np.array(next_s[i]))
buffers[i]['rewards'].append(r[i])
buffers[i]['dones'].append(float(done[i]))
buffers[i]['action_probs'].append(prob_dists[i])
s = next_s
terminal = all(done)
# 使用MAPPO更新参数
a_loss, c_loss, ent = mappo.update(buffers, state_dim)
# 记录指标
total_rewards_per_episode.append(episode_reward)
episode_lengths.append(steps)
policy_losses.append(a_loss)
value_losses.append(c_loss)
entropies.append(ent)
# 保存模型的权重参数
if episode % 500 == 0:
mappo.save_model()
log_message(f"Model saved at episode {episode}")
# 每50个episode统计一次平均值并记录日志、绘图
if episode % 50 == 0:
avg_reward_50 = np.mean(total_rewards_per_episode[-50:])
avg_length_50 = np.mean(episode_lengths[-50:])
avg_policy_loss_50 = np.mean(policy_losses[-50:])
avg_value_loss_50 = np.mean(value_losses[-50:])
avg_entropy_50 = np.mean(entropies[-50:])
avg_total_rewards_per_50.append(avg_reward_50)
avg_episode_length_per_50.append(avg_length_50)
avg_policy_loss_per_50.append(avg_policy_loss_50)
avg_value_loss_per_50.append(avg_value_loss_50)
avg_entropy_per_50.append(avg_entropy_50)
log_message(f"Episode {episode}: "
f"AvgTotalReward(last50)={avg_reward_50:.3f}, "
f"AvgEpisodeLength(last50)={avg_length_50:.3f}, "
f"AvgPolicyLoss(last50)={avg_policy_loss_50:.3f}, "
f"AvgValueLoss(last50)={avg_value_loss_50:.3f}, "
f"AvgEntropy(last50)={avg_entropy_50:.3f}")
# 创建指标字典
metrics_dict = {
"Average_Total_Reward": avg_total_rewards_per_50,
"Average_Episode_Length": avg_episode_length_per_50,
"Average_Policy_Loss": avg_policy_loss_per_50,
"Average_Value_Loss": avg_value_loss_per_50,
"Average_Entropy": avg_entropy_per_50
}
# 调用新的绘图函数
plot_all_metrics(metrics_dict, episode)
pbar.update(1)
最终绘制的结果图如下:
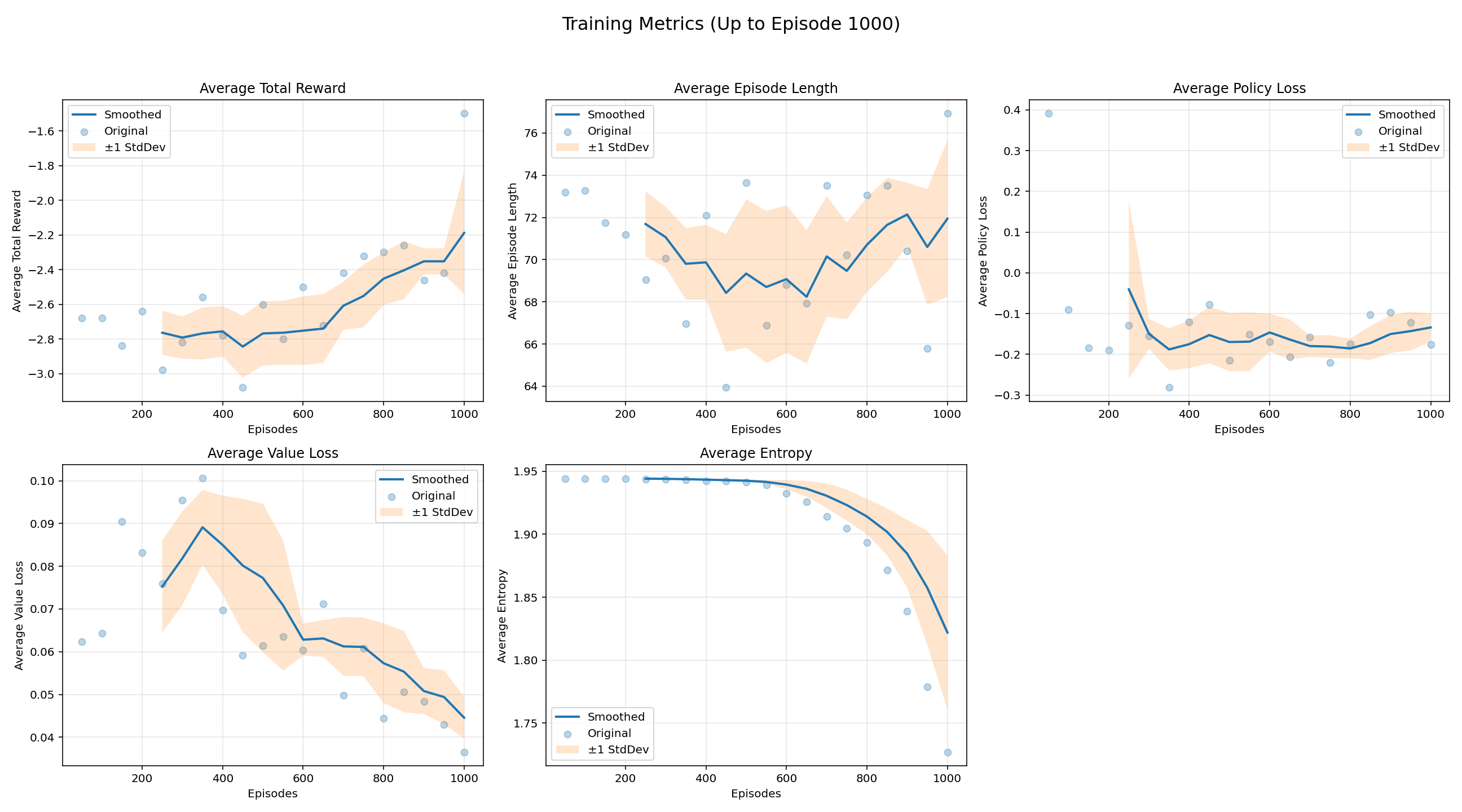
(2025.04.24补充更新)
为了与IPPO算法做比较,做了以下更新:
(1)在Combat环境中,env.step()函数里加入了胜率的计算,并丰富了返回值info字典;
(2)训练过程中,reward计算方式更新;
(3)训练超参数保持一致;
(4)在源码中统计胜率并绘制图像;
(5)可视化对抗过程。
,并且在reward的计算之中,将赢一局的奖励设置为+100,并在添加了可视化的窗口。
在源码上改动四处,即:
(1)胜率计算
# 判断是否获胜
win = False
if all(self._agent_dones):
if sum([v for k, v in self.opp_health.items()]) == 0:
win = True
elif sum([v for k, v in self.agent_health.items()]) == 0:
win = False
else:
win = None # 平局
# 将获胜信息添加到 info 中
info = {'health': self.agent_health, 'win': win, 'opp_health': self.opp_health, 'step_count': self._step_count}
return self.get_agent_obs(), rewards, self._agent_dones, info
(2)reward更新公式
buffers[i]['rewards'].append(r[i] + 100 if info['win'] else r[0] - 0.1)
(3)训练超参数
# 参数设置
actor_lr = 3e-4
critic_lr = 1e-3
epochs = 10
episode_per_epoch = 1000
hidden_dim = 64
gamma = 0.99
lmbda = 0.97
eps = 0.2
team_size = 2 # 每个team里agent的数量
grid_size = (15, 15) # 环境二维空间的大小
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
(4)统计胜率
# 统计胜率
win_list.append(1 if info['win'] else 0)
if (episode + 1) % 100 == 0:
pbar.set_postfix({
'episode': '%d' % (episode_per_epoch * e + episode + 1),
'winner prob': '%.3f' % np.mean(win_list[-100:]),
'win count': '%d' % win_list[-100:].count(1)
})
pbar.update(1)
win_array = np.array(win_list)
# 每100条轨迹取一次平均
win_array = np.mean(win_array.reshape(-1, 100), axis=1)
# 创建 episode_list,每组 100 个回合的累计回合数
episode_list = np.arange(1, len(win_array) + 1) * 100
plt.plot(episode_list, win_array)
plt.xlabel('Episodes')
plt.ylabel('win rate')
plt.title('MAPPO on Combat(separated policy)')
plt.show()
(5)可视化
while not terminal:
# =============================================================================
# #用于可视化
# env.render("human")
# time.sleep(0.01)
# =============================================================================
steps += 1
补充后的源码:
import time
import os
import shutil
from time import sleep
import torch
import torch.nn.functional as F
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import sys
#sys.path.append("./ma-gym-master")
from ma_gym.envs.combat.combat import Combat
# 清空日志文件和绘图文件夹
log_file = "training_log_metrics_weight.txt"
plot_dir = "plots_metrics_weight"
if os.path.exists(log_file):
open(log_file, "w").close()
if os.path.exists(plot_dir):
shutil.rmtree(plot_dir)
os.makedirs(plot_dir)
# 日志记录函数
def log_message(message):
with open(log_file, "a") as f:
f.write(message + "\n")
def plot_all_metrics(metrics_dict, episode):
"""
将所有指标绘制到一个包含多个子图的图表中
- 对曲线进行平滑处理
- 添加误差带显示
参数:
metrics_dict: 包含所有指标数据的字典,格式为 {metric_name: values_list}
episode: 当前的episode数
"""
# 创建一个2x3的子图布局
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
fig.suptitle(f'Training Metrics (Up to Episode {episode})', fontsize=16)
# 压平axes数组以便迭代
axes = axes.flatten()
# 为每个指标获取x轴值
any_metric = list(metrics_dict.values())[0]
x_values = [50 * (i + 1) for i in range(len(any_metric))]
# 平滑参数 - 窗口大小
window_size = min(5, len(x_values)) if len(x_values) > 0 else 1
# 在每个子图中绘制一个指标
for i, (metric_name, values) in enumerate(metrics_dict.items()):
if i >= 5: # 我们只有5个指标
break
ax = axes[i]
values_array = np.array(values)
# 应用平滑处理
if len(values) > window_size:
# 创建平滑曲线
smoothed = np.convolve(values_array, np.ones(window_size)/window_size, mode='valid')
# 计算滚动标准差用于误差带
std_values = []
for j in range(len(values) - window_size + 1):
std_values.append(np.std(values_array[j:j+window_size]))
std_values = np.array(std_values)
# 调整x轴以匹配平滑后的数据长度
smoothed_x = x_values[window_size-1:]
# 绘制平滑曲线和原始散点
ax.plot(smoothed_x, smoothed, '-', linewidth=2, label='Smoothed')
ax.scatter(x_values, values, alpha=0.3, label='Original')
# 添加误差带
ax.fill_between(smoothed_x, smoothed-std_values, smoothed+std_values,
alpha=0.2, label='±1 StdDev')
else:
# 如果数据点太少,只绘制原始数据
ax.plot(x_values, values, 'o-', label='Data')
ax.set_title(metric_name.replace('_', ' '))
ax.set_xlabel('Episodes')
ax.set_ylabel(metric_name.replace('_', ' '))
ax.grid(True, alpha=0.3)
ax.legend()
# 删除未使用的子图
if len(metrics_dict) < 6:
fig.delaxes(axes[5])
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.savefig(os.path.join(plot_dir, f'training_metrics.png'))
plt.close(fig)
def compute_entropy(probs):
dist = torch.distributions.Categorical(probs)
return dist.entropy().mean().item()
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().cpu().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
# =============================================================================
# # 策略网络(Actor)
# class PolicyNet(torch.nn.Module):
# def __init__(self, state_dim, hidden_dim, action_dim):
# super(PolicyNet, self).__init__()
# self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
# self.fc3 = torch.nn.Linear(hidden_dim, action_dim)
#
# def forward(self, x):
# x = F.relu(F.relu(self.fc1(x)))
# return F.softmax(self.fc3(x), dim=1)
#
# # 全局价值网络(CentralValueNet)
# # 输入: 所有智能体的状态拼接 (team_size * state_dim)
# # 输出: 对每个智能体的价值估计 (team_size维向量)
# class CentralValueNet(torch.nn.Module):
# def __init__(self, total_state_dim, hidden_dim, team_size):
# super(CentralValueNet, self).__init__()
# self.fc1 = torch.nn.Linear(total_state_dim, hidden_dim)
# self.fc3 = torch.nn.Linear(hidden_dim, team_size) # 输出为每个智能体一个价值
#
# def forward(self, x):
# x = F.relu(F.relu(self.fc1(x)))
# return self.fc3(x) # [batch, team_size]
# =============================================================================
# 策略网络(Actor)
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return F.softmax(self.fc3(x), dim=1)
# 全局价值网络(CentralValueNet)
# 输入: 所有智能体的状态拼接 (team_size * state_dim)
# 输出: 对每个智能体的价值估计 (team_size维向量)
class CentralValueNet(torch.nn.Module):
def __init__(self, total_state_dim, hidden_dim, team_size):
super(CentralValueNet, self).__init__()
self.fc1 = torch.nn.Linear(total_state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, team_size) # 输出为每个智能体一个价值
def forward(self, x):
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return self.fc3(x) # [batch, team_size]
class MAPPO:
def __init__(self, team_size, state_dim, hidden_dim, action_dim,
actor_lr, critic_lr, lmbda, eps, gamma, device):
self.team_size = team_size
self.gamma = gamma
self.lmbda = lmbda
self.eps = eps
self.device = device
# 为每个智能体一个独立的actor
self.actors = [PolicyNet(state_dim, hidden_dim, action_dim).to(device)
for _ in range(team_size)]
# 一个全局critic,输入为所有智能体状态拼接
self.critic = CentralValueNet(team_size * state_dim, hidden_dim, team_size).to(device)
self.actor_optimizers = [torch.optim.Adam(actor.parameters(), actor_lr)
for actor in self.actors]
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), critic_lr)
def save_model(self, path="mappo_weights"):
if not os.path.exists(path):
os.makedirs(path)
for i, actor in enumerate(self.actors):
torch.save(actor.state_dict(), os.path.join(path, f"actor_{i}.pth"))
torch.save(self.critic.state_dict(), os.path.join(path, "critic.pth"))
def load_model(self, path="mappo_weights"):
for i, actor in enumerate(self.actors):
actor_path = os.path.join(path, f"actor_{i}.pth")
if os.path.exists(actor_path):
actor.load_state_dict(torch.load(actor_path))
critic_path = os.path.join(path, "critic.pth")
if os.path.exists(critic_path):
self.critic.load_state_dict(torch.load(critic_path))
def take_action(self, state_per_agent):
# state_per_agent: list of shape [team_size, state_dim]
actions = []
action_probs = []
for i, actor in enumerate(self.actors):
s = torch.tensor([state_per_agent[i]], dtype=torch.float).to(self.device)
probs = actor(s)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
actions.append(action.item())
action_probs.append(probs.detach().cpu().numpy()[0])
return actions, action_probs
def update(self, transition_dicts, state_dim):
# 拼接所有智能体的数据,用于全局critic
# 首先统一长度T,假设所有智能体长度相同(因为同步环境步)
T = len(transition_dicts[0]['states'])
# print(f"T: {T}")
# 将所有智能体在同一时间步的state拼接起来,得到 [T, team_size*state_dim]
states_all = []
next_states_all = []
for t in range(T):
concat_state = []
concat_next_state = []
for i in range(self.team_size):
concat_state.append(transition_dicts[i]['states'][t])
concat_next_state.append(transition_dicts[i]['next_states'][t])
states_all.append(np.concatenate(concat_state))
next_states_all.append(np.concatenate(concat_next_state))
states_all_np = np.array(states_all)
next_states_all_np = np.array(next_states_all)
states_all = torch.tensor(states_all_np, dtype=torch.float).to(self.device) # [T, team_size*state_dim]
next_states_all = torch.tensor(next_states_all_np, dtype=torch.float).to(self.device) # [T, team_size*state_dim]
rewards_all = torch.tensor([ [transition_dicts[i]['rewards'][t] for i in range(self.team_size)]
for t in range(T)], dtype=torch.float).to(self.device) # [T, team_size]
dones_all = torch.tensor([ [transition_dicts[i]['dones'][t] for i in range(self.team_size)]
for t in range(T)], dtype=torch.float).to(self.device) # [T, team_size]
# 从critic计算价值和TD-target
values = self.critic(states_all) # [T, team_size]
next_values = self.critic(next_states_all) # [T, team_size]
td_target = rewards_all + self.gamma * next_values * (1 - dones_all) # [T, team_size]
td_delta = td_target - values # [T, team_size]
# 为每个智能体计算其优势
advantages = []
for i in range(self.team_size):
adv_i = compute_advantage(self.gamma, self.lmbda, td_delta[:, i])
advantages.append(adv_i.to(self.device)) # [T]
# 更新critic
# critic的loss是所有智能体的均方误差平均
critic_loss = F.mse_loss(values, td_target.detach())
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 更新每个智能体的actor
action_losses = []
entropies = []
for i in range(self.team_size):
states_np = np.array(transition_dicts[i]['states'])
states = torch.tensor(states_np, dtype=torch.float).to(self.device)
actions_np = np.array(transition_dicts[i]['actions'])
actions = torch.tensor(actions_np).view(-1, 1).to(self.device)
old_probs_np = np.array(transition_dicts[i]['action_probs'])
old_probs = torch.tensor(old_probs_np, dtype=torch.float).to(self.device)
current_probs = self.actors[i](states) # [T, action_dim]
log_probs = torch.log(current_probs.gather(1, actions))
old_log_probs = torch.log(old_probs.gather(1, actions)).detach()
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantages[i].unsqueeze(-1)
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantages[i].unsqueeze(-1)
action_loss = torch.mean(-torch.min(surr1, surr2))
entropy_val = compute_entropy(current_probs)
self.actor_optimizers[i].zero_grad()
action_loss.backward()
self.actor_optimizers[i].step()
action_losses.append(action_loss.item())
entropies.append(entropy_val)
return np.mean(action_losses), critic_loss.item(), np.mean(entropies)
# 参数设置
actor_lr = 3e-4
critic_lr = 1e-3
epochs = 10
episode_per_epoch = 1000
hidden_dim = 64
gamma = 0.99
lmbda = 0.97
eps = 0.2
team_size = 2 # 每个team里agent的数量
grid_size = (15, 15) # 环境二维空间的大小
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
# 创建环境
env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)
state_dim = env.observation_space[0].shape[0]
action_dim = env.action_space[0].n
# 创建MAPPO智能体(共有team_size个actor, 一个共享critic)
mappo = MAPPO(team_size, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda, eps, gamma, device)
# 用于统计指标的列表
total_rewards_per_episode = []
episode_lengths = []
policy_losses = []
value_losses = []
entropies = []
# 每50个episode的平均值列表
avg_total_rewards_per_50 = []
avg_episode_length_per_50 = []
avg_policy_loss_per_50 = []
avg_value_loss_per_50 = []
avg_entropy_per_50 = []
win_list = []
for e in range(epochs):
with tqdm(total=episode_per_epoch, desc="Training") as pbar:
for episode in range(episode_per_epoch):
# 初始化Trajectory buffer
buffers = [{
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': [],
'action_probs': []
} for _ in range(team_size)]
s = env.reset()
terminal = False
episode_reward = 0.0
steps = 0
while not terminal:
# =============================================================================
# #用于可视化
# env.render("human")
# time.sleep(0.01)
# =============================================================================
steps += 1
# MAPPO中,每个智能体仍独立选择动作,但critic共享
actions, prob_dists = mappo.take_action(s)
next_s, r, done, info = env.step(actions)
# 累计总奖励
step_reward = sum(r)
episode_reward += step_reward
# 存储transition
for i in range(team_size):
buffers[i]['states'].append(np.array(s[i]))
buffers[i]['actions'].append(actions[i])
buffers[i]['next_states'].append(np.array(next_s[i]))
buffers[i]['rewards'].append(r[i] + 100 if info['win'] else r[0] - 0.1)
buffers[i]['dones'].append(float(done[i]))
buffers[i]['action_probs'].append(prob_dists[i])
s = next_s
terminal = all(done)
# 使用MAPPO更新参数
a_loss, c_loss, ent = mappo.update(buffers, state_dim)
# 记录指标
total_rewards_per_episode.append(episode_reward)
episode_lengths.append(steps)
policy_losses.append(a_loss)
value_losses.append(c_loss)
entropies.append(ent)
# 保存模型的权重参数
if episode % 500 == 0:
mappo.save_model()
log_message(f"Model saved at episode {episode}")
# 每50个episode统计一次平均值并记录日志、绘图
if episode % 50 == 0:
avg_reward_50 = np.mean(total_rewards_per_episode[-50:])
avg_length_50 = np.mean(episode_lengths[-50:])
avg_policy_loss_50 = np.mean(policy_losses[-50:])
avg_value_loss_50 = np.mean(value_losses[-50:])
avg_entropy_50 = np.mean(entropies[-50:])
avg_total_rewards_per_50.append(avg_reward_50)
avg_episode_length_per_50.append(avg_length_50)
avg_policy_loss_per_50.append(avg_policy_loss_50)
avg_value_loss_per_50.append(avg_value_loss_50)
avg_entropy_per_50.append(avg_entropy_50)
log_message(f"Episode {episode}: "
f"AvgTotalReward(last50)={avg_reward_50:.3f}, "
f"AvgEpisodeLength(last50)={avg_length_50:.3f}, "
f"AvgPolicyLoss(last50)={avg_policy_loss_50:.3f}, "
f"AvgValueLoss(last50)={avg_value_loss_50:.3f}, "
f"AvgEntropy(last50)={avg_entropy_50:.3f}")
# 创建指标字典
metrics_dict = {
"Average_Total_Reward": avg_total_rewards_per_50,
"Average_Episode_Length": avg_episode_length_per_50,
"Average_Policy_Loss": avg_policy_loss_per_50,
"Average_Value_Loss": avg_value_loss_per_50,
"Average_Entropy": avg_entropy_per_50
}
# 调用新的绘图函数
plot_all_metrics(metrics_dict, episode)
# 统计胜率
win_list.append(1 if info['win'] else 0)
if (episode + 1) % 100 == 0:
pbar.set_postfix({
'episode': '%d' % (episode_per_epoch * e + episode + 1),
'winner prob': '%.3f' % np.mean(win_list[-100:]),
'win count': '%d' % win_list[-100:].count(1)
})
pbar.update(1)
win_array = np.array(win_list)
# 每100条轨迹取一次平均
win_array = np.mean(win_array.reshape(-1, 100), axis=1)
# 创建 episode_list,每组 100 个回合的累计回合数
episode_list = np.arange(1, len(win_array) + 1) * 100
plt.plot(episode_list, win_array)
plt.xlabel('Episodes')
plt.ylabel('win rate')
plt.title('MAPPO on Combat(separated policy)')
plt.show()
最终得到的结果,如下所示:

与IPPO算法对比而言,MAPPO算法需要更多的数据才能得到比较好的结果。
2.2.3 Combat环境介绍
在ma-gym的Combat环境中,目标是模拟两个队伍在15×15的网格上进行对抗。每个队伍由5个智能体组成,智能体的初始位置在队伍中心附近的5×5区域内随机分布。智能体可以通过移动、攻击或不行动来与敌方互动。
(在RL领域中,环境仿真都是基于MDP而言的,包含状态空间、动作空间、状态转移函数、奖励函数四项重要内容,因此理解一个RL环境就可以从以下4个方面出发)
(1)动作空间
每个智能体有以下动作选项:
- 移动:在四个方向(上、下、左、右)中选择一个方向移动一格。
- 攻击:攻击范围内的敌方智能体(3×3的区域)。
- 不行动:不执行任何操作。
补充说明:
- 攻击action是指定agent ID来执行的。
- agent无法攻击视野范围外的agent,agent视野范围为以自身为中心的5x5的范围。
- 一个队伍的agent是共享视野的。(默认有通信机制)
(2)状态空间
每个智能体的状态由以下信息组成:
- 唯一ID
- 队伍ID
- 位置
- 生命值(初始为3点)
- 攻击冷却状态
补充说明:
- 一个队伍有5个agent,初始位置以一个agent为中心,周围的5×5正方形区域内均匀采样。
- 攻击冷却的含义为:执行攻击action后,下一个time step需“不行动”。
(3)奖励机制
- 如果队伍输掉或平局,模型会获得-1的奖励。
- 此外,模型还会根据敌方队伍的生命值总和获得-0.1倍的奖励,这鼓励模型积极攻击敌方。
补充说明:
- 模型可以控制己方agent的策略。
- 敌方agent都采用“既定规则”策略:如果最近的敌方智能体在其射程范围内,则攻击它;如果不是,则接近视觉范围内的最近可见敌方智能体。
(4)终止条件
- 一方队伍的所有智能体死亡。
- 在40个时间步内未分出胜负(平局)。
2.2.4 代码框架理解
(1)超参设置
actor_lr = 3e-4
critic_lr = 1e-3
total_episodes = 10000
hidden_dim = 64
gamma = 0.99
lmbda = 0.97
eps = 0.3
team_size = 2
grid_size = (20, 20)
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
从上至下,分别表示:
- actor_net学习率
- critic_net学习率
- episodes总数
- 两个net隐藏曾维度
- 奖励折扣率
- 优势函数计算超参数
- PPO截断超参数
- 队伍数量=2
- 环境大小?
- 运算设备选择
(2)创建环境
env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)
state_dim = env.observation_space[0].shape[0]
action_dim = env.action_space[0].n
基于ma-gym内函数创建Combat环境:场地20x20,我队agent数量=2,敌队agent数量=2
state_dim=150
action_dim=7
两项用于配置actor_net、critic_net
(3)创建MAPPO智能体
mappo = MAPPO(team_size, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda, eps, gamma, device)
...
class MAPPO:
def __init__(self, team_size, state_dim, hidden_dim, action_dim,
actor_lr, critic_lr, lmbda, eps, gamma, device):
self.team_size = team_size
self.gamma = gamma
self.lmbda = lmbda
self.eps = eps
self.device = device
# 为每个智能体一个独立的actor
self.actors = [PolicyNet(state_dim, hidden_dim, action_dim).to(device)
for _ in range(team_size)]
# 一个全局critic,输入为所有智能体状态拼接
self.critic = CentralValueNet(team_size * state_dim, hidden_dim, team_size).to(device)
self.actor_optimizers = [torch.optim.Adam(actor.parameters(), actor_lr)
for actor in self.actors]
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), critic_lr)
def save_model(self, path="mappo_weights"):
...
def load_model(self, path="mappo_weights"):
...
def take_action(self, state_per_agent):
...
return actions, action_probs
def update(self, transition_dicts, state_dim):
# 拼接所有智能体的数据,用于全局critic
...
return np.mean(action_losses), critic_loss.item(), np.mean(entropies)
创建MAPPO智能体(共有team_size个actor, 一个共享critic),即采用的是CTDE(Centralized Training with Decentralized Execution)集中训练分布式执行的模式。
# 策略网络(Actor)
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return F.softmax(self.fc3(x), dim=1)
其中,actor_net就是PolicyNet,采用的是多层感知机(Multilayer Perceptron, MLP),即层与层之间是全连接的,网络结构可表示为:
输入层:x=state_dim=150
隐藏层1:h1=relu(fc1(x))=64
隐藏曾2:h2=relu(fc2(h1))=64
输出层:y=softmax(fc3(h2))=action_dim=7
# 全局价值网络(CentralValueNet)
# 输入: 所有智能体的状态拼接 (team_size * state_dim)
# 输出: 对每个智能体的价值估计 (team_size维向量)
class CentralValueNet(torch.nn.Module):
def __init__(self, total_state_dim, hidden_dim, team_size):
super(CentralValueNet, self).__init__()
self.fc1 = torch.nn.Linear(total_state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, team_size) # 输出为每个智能体一个价值
def forward(self, x):
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return self.fc3(x) # [batch, team_size]
其中,critic_net就是CentralValueNet,其中网络结构为:
输入层:x=total_state_dim=state_dim * n_agents=300
隐藏层1:h1=relu(fc1(x))=64
隐藏曾2:h2=relu(fc2(h1))=64
输出层:y=fc3(h2)=n_agents=2
这里需要说明的是,隐藏层设置为2层,不见得比设置为1层效果更好,网络结构越复杂可能会带来额外的计算开销
其中MAPPO类中,还包含几个函数:
save_model用于保存网络参数到本地,即critic.pth+actor_{i}.pthload_model加载本地模型take_action根据actor_net选择动作update更新网络
(4)采样episodes
for episode in range(1, total_episodes + 1):
# 初始化Trajectory buffer
buffers = [{
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': [],
'action_probs': []
} for _ in range(team_size)]
s = env.reset()
terminal = False
episode_reward = 0.0
steps = 0
while not terminal:
steps += 1
# MAPPO中,每个智能体仍独立选择动作,但critic共享
actions, prob_dists = mappo.take_action(s)
next_s, r, done, info = env.step(actions)
# 累计总奖励
step_reward = sum(r)
episode_reward += step_reward
# 存储transition
for i in range(team_size):
buffers[i]['states'].append(np.array(s[i]))
buffers[i]['actions'].append(actions[i])
buffers[i]['next_states'].append(np.array(next_s[i]))
buffers[i]['rewards'].append(r[i])
buffers[i]['dones'].append(float(done[i]))
buffers[i]['action_probs'].append(prob_dists[i])
s = next_s
terminal = all(done)
大致流程解释如下:
- 根据己方队伍agent数量创建buffers
回放经验池; - 重置环境env;
- agent根据各自的state与actor_net选择action,action基于prob进行随机采样;
- env 基于action执行一个时间步,获得next_s、r、done、info(info用于记录将agent health信息);
- 将{states、actions、next_states、rewards、dones、action_probs}存入buffers,直至terminal状态为True,至此生成一条轨迹
episode。
(5)更新actor、critic网络
# 使用MAPPO更新参数
a_loss, c_loss, ent = mappo.update(buffers, state_dim)
...
def update(self, transition_dicts, state_dim):
# 拼接所有智能体的数据,用于全局critic
# 首先统一长度T,假设所有智能体长度相同(因为同步环境步)
T = len(transition_dicts[0]['states'])
# print(f"T: {T}")
# 将所有智能体在同一时间步的state拼接起来,得到 [T, team_size*state_dim]
states_all = []
next_states_all = []
for t in range(T):
concat_state = []
concat_next_state = []
for i in range(self.team_size):
concat_state.append(transition_dicts[i]['states'][t])
concat_next_state.append(transition_dicts[i]['next_states'][t])
states_all.append(np.concatenate(concat_state))
next_states_all.append(np.concatenate(concat_next_state))
states_all_np = np.array(states_all)
next_states_all_np = np.array(next_states_all)
states_all = torch.tensor(states_all_np, dtype=torch.float).to(self.device) # [T, team_size*state_dim]
next_states_all = torch.tensor(next_states_all_np, dtype=torch.float).to(self.device) # [T, team_size*state_dim]
rewards_all = torch.tensor([ [transition_dicts[i]['rewards'][t] for i in range(self.team_size)]
for t in range(T)], dtype=torch.float).to(self.device) # [T, team_size]
dones_all = torch.tensor([ [transition_dicts[i]['dones'][t] for i in range(self.team_size)]
for t in range(T)], dtype=torch.float).to(self.device) # [T, team_size]
拼接参数
- 将所有states、next_states的信息拼接起来。
- 将states、next_states、rewards、dones 转换为tensor变量。
# 从critic计算价值和TD-target
values = self.critic(states_all) # [T, team_size]
next_values = self.critic(next_states_all) # [T, team_size]
td_target = rewards_all + self.gamma * next_values * (1 - dones_all) # [T, team_size]
td_delta = td_target - values # [T, team_size]
计算TD误差项
对应公式如下:
T
D
t
a
r
g
e
t
=
r
t
+
1
+
γ
⋅
v
(
s
t
+
1
)
⋅
(
1
−
d
o
n
e
)
TD_{target}=r_{t+1}+\gamma\cdot v(s_{t+1})\cdot(1-done)
TDtarget=rt+1+γ⋅v(st+1)⋅(1−done)
T
D
d
e
l
t
a
=
T
D
t
a
r
g
e
t
−
v
(
s
t
)
TD_{delta}=TD_{target}-v(s_t)
TDdelta=TDtarget−v(st)
# 更新critic
# critic的loss是所有智能体的均方误差平均
critic_loss = F.mse_loss(values, td_target.detach())
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
计算Critic损失函数,更新Critic网络
- 计算values与td_target的均方误差
L o s s c r i t i c = 1 N ∑ i = 1 N ( V ( s t ) − T D t a r g e t ) 2 \mathrm{Loss}_{\mathrm{critic}}=\frac{1}{N}\sum_{i=1}^{N}(V(s_t)-TD_{target})^2 Losscritic=N1i=1∑N(V(st)−TDtarget)2
- 梯度清零
- 反向传播
- 参数更新
# 为每个智能体计算其优势
advantages = []
for i in range(self.team_size):
adv_i = compute_advantage(self.gamma, self.lmbda, td_delta[:, i])
advantages.append(adv_i.to(self.device)) # [T]
...
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().cpu().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
基于GAE计算优势函数
A
t
=
∑
l
=
0
n
−
1
(
γ
λ
)
l
δ
t
+
l
A_t=\sum_{l=0}^{n-1}(\gamma\lambda)^l\delta_{t+l}
At=l=0∑n−1(γλ)lδt+l
γ 是折扣因子。
λ 是GAE的缩放因子,控制了优势函数的时间范围。
for i in range(self.team_size):
states_np = np.array(transition_dicts[i]['states'])
states = torch.tensor(states_np, dtype=torch.float).to(self.device)
actions_np = np.array(transition_dicts[i]['actions'])
actions = torch.tensor(actions_np).view(-1, 1).to(self.device)
old_probs_np = np.array(transition_dicts[i]['action_probs'])
old_probs = torch.tensor(old_probs_np, dtype=torch.float).to(self.device)
current_probs = self.actors[i](states) # [T, action_dim]
log_probs = torch.log(current_probs.gather(1, actions))
old_log_probs = torch.log(old_probs.gather(1, actions)).detach()
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantages[i].unsqueeze(-1)
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantages[i].unsqueeze(-1)
action_loss = torch.mean(-torch.min(surr1, surr2))
entropy_val = compute_entropy(current_probs)
计算Actor损失函数
- 将states、actions、action_probs 转换为tensor变量;
- 计算比值
r a t i o = π n e w ( a t ∣ s t ) π o l d ( a t ∣ s t ) = exp ( log π n e w ( a t ∣ s t ) − log π o l d ( a t ∣ s t ) ) ratio=\frac{\pi_{new}(a_t|s_t)}{\pi_{old}(a_t|s_t)}=\exp(\log\pi_{new}(a_t|s_t)-\log\pi_{old}(a_t|s_t)) ratio=πold(at∣st)πnew(at∣st)=exp(logπnew(at∣st)−logπold(at∣st)) - 计算未截断目标函数
L 1 C l i p = r t ⋅ A t = π n e w ( a t ∣ s t ) π o l d ( a t ∣ s t ) ⋅ A t L_1^{Clip}=r_t\cdot A_t=\frac{\pi_{new}(a_t|s_t)}{\pi_{old}(a_t|s_t)}\cdot A_t L1Clip=rt⋅At=πold(at∣st)πnew(at∣st)⋅At - 计算截断目标函数
L 2 C l i p = c l i p ( r t , 1 − ε , 1 + ε ) ⋅ A t = c l i p ( π n e w ( a t ∣ s t ) π o l d ( a t ∣ s t ) , 1 − ε , 1 + ε ) ⋅ A t L_2^{Clip}=clip(r_t,1-\varepsilon,1+\varepsilon)\cdot A_t=clip(\frac{\pi_{new}(a_t|s_t)}{\pi_{old}(a_t|s_t)},1-\varepsilon,1+\varepsilon)\cdot A_t L2Clip=clip(rt,1−ε,1+ε)⋅At=clip(πold(at∣st)πnew(at∣st),1−ε,1+ε)⋅At - 计算actor网络损失函数
L C L I P = − E [ m i n ( L 1 C L I P , L 2 C L I P ) ] = − E [ m i n ( π n e w ( a t ∣ s t ) π o l d ( a t ∣ s t ) ⋅ A t , c l i p ( π n e w ( a t ∣ s t ) π o l d ( a t ∣ s t ) , 1 − ε , 1 + ε ) ⋅ A t ) ] L^{CLIP}=-\mathbb{E}[min(L_1^{CLIP},L_2^{CLIP})]=-\mathbb{E}\left[min\left(\frac{\pi_{new}(a_t|s_t)}{\pi_{old}(a_t|s_t)}\cdot A_t,clip(\frac{\pi_{new}(a_t|s_t)}{\pi_{old}(a_t|s_t)},1-\varepsilon,1+\varepsilon)\cdot A_t\right)\right] LCLIP=−E[min(L1CLIP,L2CLIP)]=−E[min(πold(at∣st)πnew(at∣st)⋅At,clip(πold(at∣st)πnew(at∣st),1−ε,1+ε)⋅At)]
负号表示我们要最小化损失,即最大化目标函数。这里损失函数的设置与PPO-clip的优化目标一致!
具体原理可参考:【动手学强化学习】part8-PPO(Proximal Policy Optimization)近端策略优化算法
- 计算熵(大概率是用于事后验证策略好坏的)
H ( p ) = − ∑ i = 1 n p i log p i H(p)=-\sum_{i=1}^np_i\log p_i H(p)=−i=1∑npilogpi
self.actor_optimizers[i].zero_grad()
action_loss.backward()
self.actor_optimizers[i].step()
action_losses.append(action_loss.item())
entropies.append(entropy_val)
更新actor网络参数
- 梯度清零
- 反向传播
- 参数更新
- 损失值、熵值记录
三、疑问
- actor_net、critic_net中隐藏层层数和维度应该如何选择?
这个最好根据自身环境仿真效果来尝试,可以改变层数和维度,已发掘最好的算法性能与计算开销的
效费比。
- 在更新actor网络中,为什么old_probs和log_probs会不一致?
(待补充)
- 在actor网络更新中为什么需要计算熵?
在强化学习中,熵可以作为
探索和利用之间的平衡指标:
高熵:表示策略分布较均匀,智能体倾向于探索不同的动作。
低熵:表示策略分布较集中,智能体倾向于选择某些特定的动作。
通过最大化熵,可以鼓励智能体进行更多的探索,从而避免过早收敛到次优策略。
四、总结
- 如果使用自建环境可能需要修改的地方:
- actor、critic网络隐藏层层数、维度;
- 注意take_action()函数的return项;
- 注意env.step()函数的input、return项;


















 3368
3368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









