



前言
前几天突发奇想想自建一个聊天服务器,早在2022年朋友就有使用PHP写过一个在线聊天室,因为太久远,程序代码我也没有进行备份,在网上找了好几个开源项目也没看到适合自己的,最后在DuckChat(鸭信),Synology Chat(群晖官方聊天套件),以及VoceChat这三个选项中,因为简洁使用方便选择了VoceChat。
系统选择
DuckChat(鸭信)
第一次听说这名字是在Bilibili某博主的评论区,随后我进行了相关搜索,看到他的安装界面挺戳我审美的,并且拥有多个平台的客户端,生态比较完善,但是不知道因为啥原因导致该项目在4年前(Github最后一次提交)就停止了维护,官网以及文档目前都是处于无法访问状态,于是就放弃了部署该项目。
Synology Chat
群晖官方自带的聊天套件,不知道什么原因在国内被下架了(大差不差能猜到一点),可以通过将群晖官网的下载中心切换到香港根据你的群晖型号可以手动下载并安装
因为我没有安卓设备测试,iOS端则需要切换到外区下载使用,功能很完善,对于界面我个人还是不太喜欢,如果只有群晖NAS很推荐安装使用。
VoceChat
在放弃了前面两款程序后,在偶然间,看到了这款程序,起初没有抱有太大器期望,但是在使用了一周左右,不得不说这仅有15MB大小的程序,给了我很多意外惊喜,生态也比较完整,满足了我目前使用的所有场景,以至于还可以将VoceChat的挂件SDK内嵌到网页,实现 类似于“在线客服”的功能。
部署教程
因为个人原因相对于使用Docker相对于命令行,更喜欢编写编排文件,首先后续备份快捷,其次修改方便。
第一步
在你的群晖Docker容器目录下新建一个文件夹随意,自己清楚其用途即可。
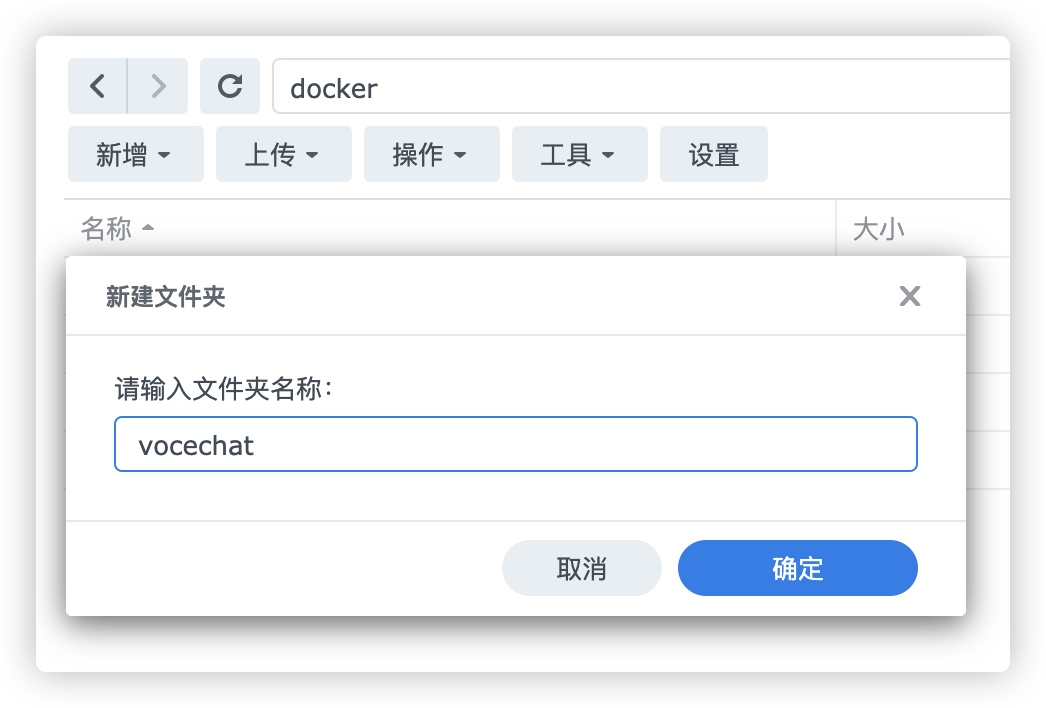
第二步
创建后点击目录再新建一个data文件夹用于后续映射容器数据到本地。
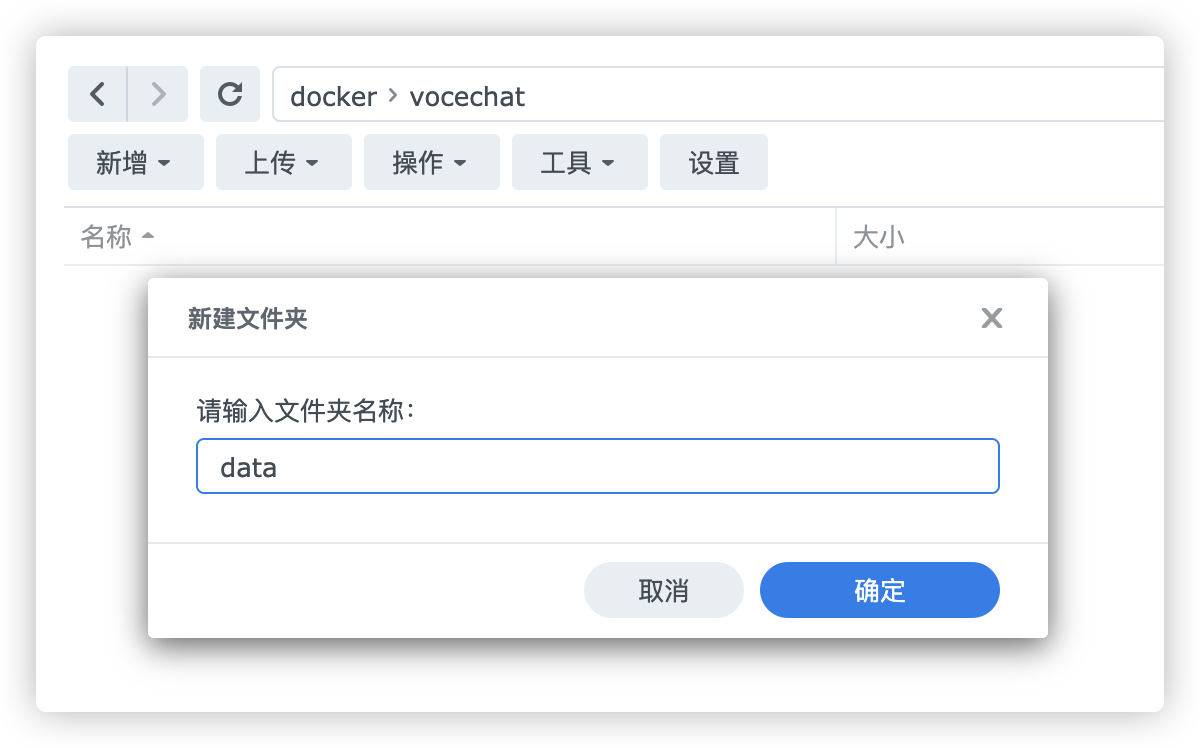
第三步
创建编排项目,按照我图上的配置即可,贴上我的配置
version: '3.0'
services:
vocechat-server:
image: privoce/vocechat-server:latest
container_name: vocechat-server
ports:
- "3009:3000"
restart: always
volumes:
- ./data:/home/vocechat-server/data
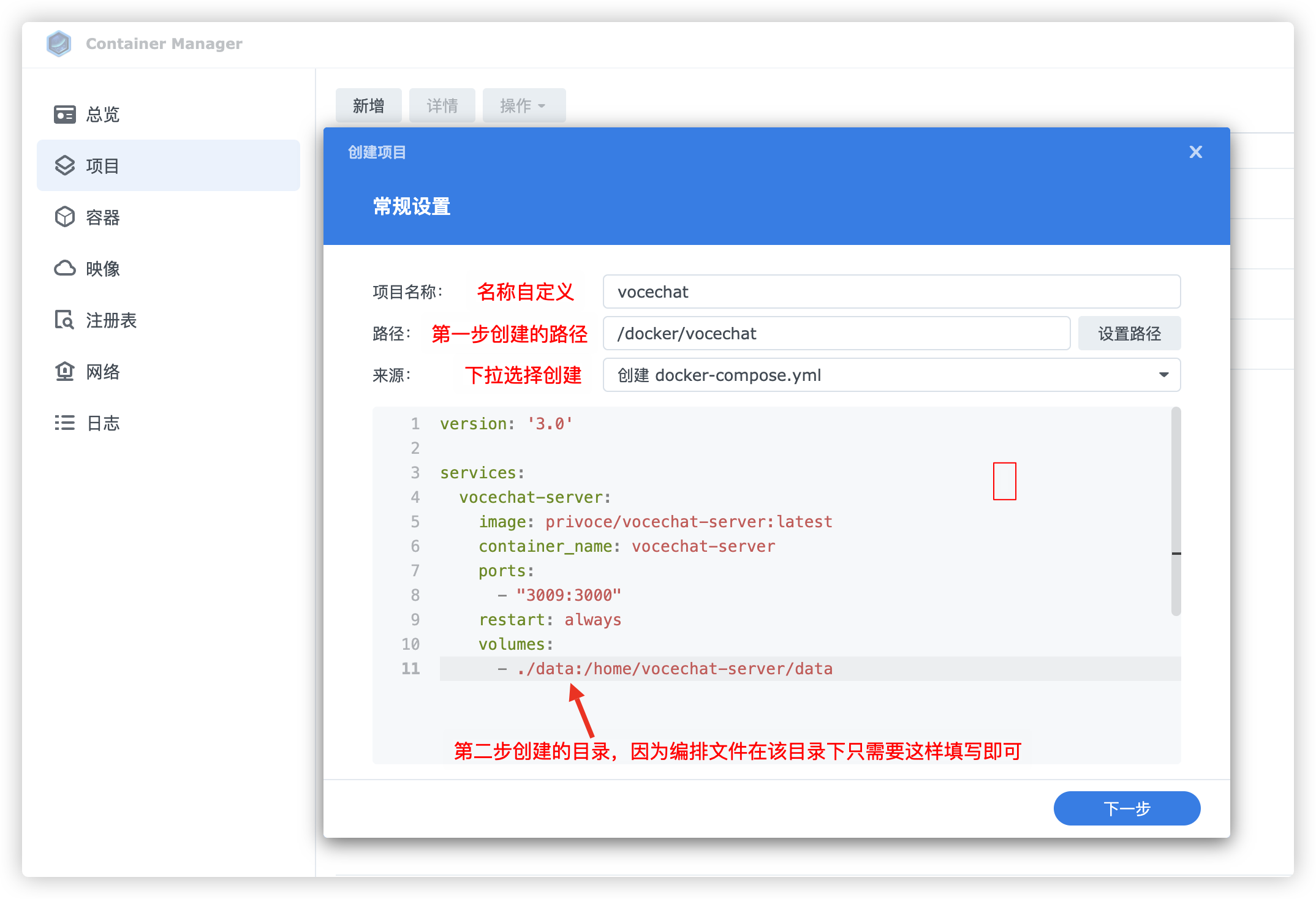
配置填写好以后点击下一步,等待镜像拉取成功即可。
初始化
部署好后通过浏览器访问你的IP:3009即可进行程序初始化。
根据你的实际情况完成初始化化后即可使用。
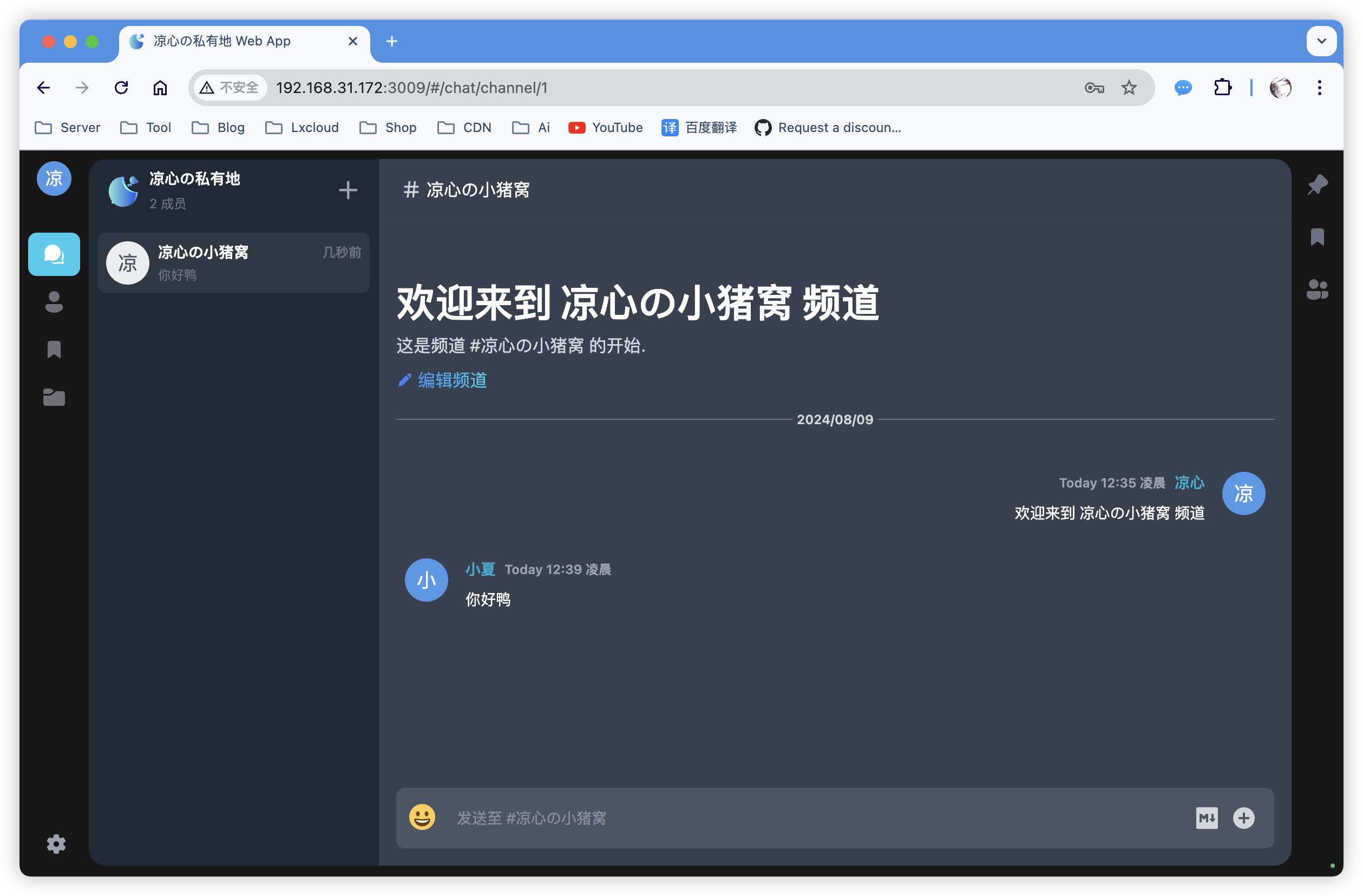
一些使用建议
- 目前
VoceChat的消息推送需要借助Google相关服务,由于众所周知的原因,所以,借助软路由或旁路由,请确保你群晖内的网络能够访问谷歌。以保证能收到推送信息服务。

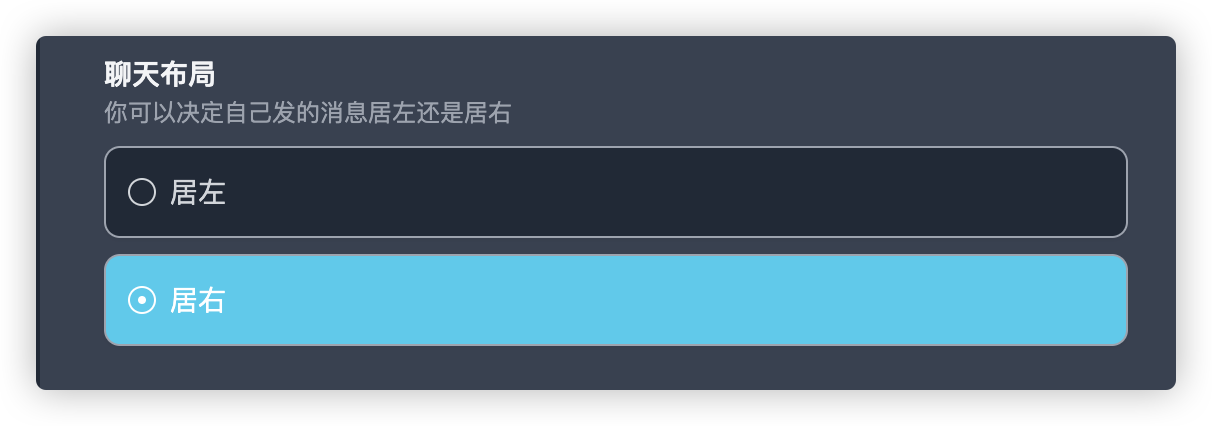
- 因使用习惯而异,个人建议在概况中将聊天布局改为居右,更符合国内通讯使用习惯。
最后
VoceChat 的功能远不止于文中介绍这点,相关功能可以自己部署后进行折腾,官方的文档也写得非常详细,以上教程包括但不限于群晖,编排文件可以根据自己实际情况部署及修改。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









