







简单数据类型:
| 数据类型 | 示例 |
|---|---|
| TINEYINT | 10Y |
| SMALLINT | 10S |
| INT | 10 |
| BIGINT | 10L |
| FLOAT | 1.342 |
| DOUBLE | 1.234 |
| DECIMAL | 3.14 |
| BINARY | 1010 |
| BOOLEAN | TRUE |
| STRING | “BOOK” |
| CHAR | ‘YES’ |
| VARCHAR | ‘BOOK’ |
| DATE | ‘2013-03-11’ |
| TIMESTAMP | ‘2019-06-08 00:13:49’ |
复合数据类型:
| 类型 | 格式 | 定义 | 示例 |
|---|---|---|---|
| ARRAY | [‘APPLE’,‘ORANGE’,‘MONGO’] | ARRAY<STRING> | a[0]=‘APPLE’ |
| MAP | {‘A’:‘APPLE’,‘O’:‘ORANGE’} | MAP<STRING,STRING> | b[‘A’]=‘APPLE’ |
| STRUCT | {‘APPLE’,2} | STRUCT<FRUITE:STRING,WEIGHT:INT> | c.weight=2 |
案例:
数据信息
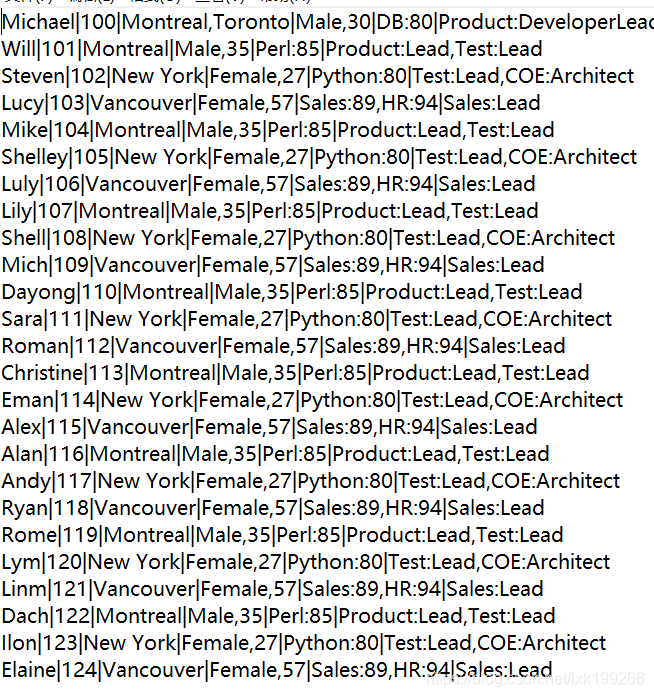
根据以上数据得出:
字段分段字符是|
部分字段的部分行含有多个关键词,应该使用符合数据类型保存
建表语句:
create external table employee_id(
name string,
id int,
address array<string>,
genderandage struct<gender:string,age:int>,
score map<string,string>,
job map<string,string>
)row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
location '/test/data/employee_id';
说明:
- 建表前将源数据文件上传至指定路径
- 语句中指定位置不能指定到文件,要指定到文件上一级目录,添加数据时会添加指定目录下的全部文件
- 行分割字符一般都是取’\n’
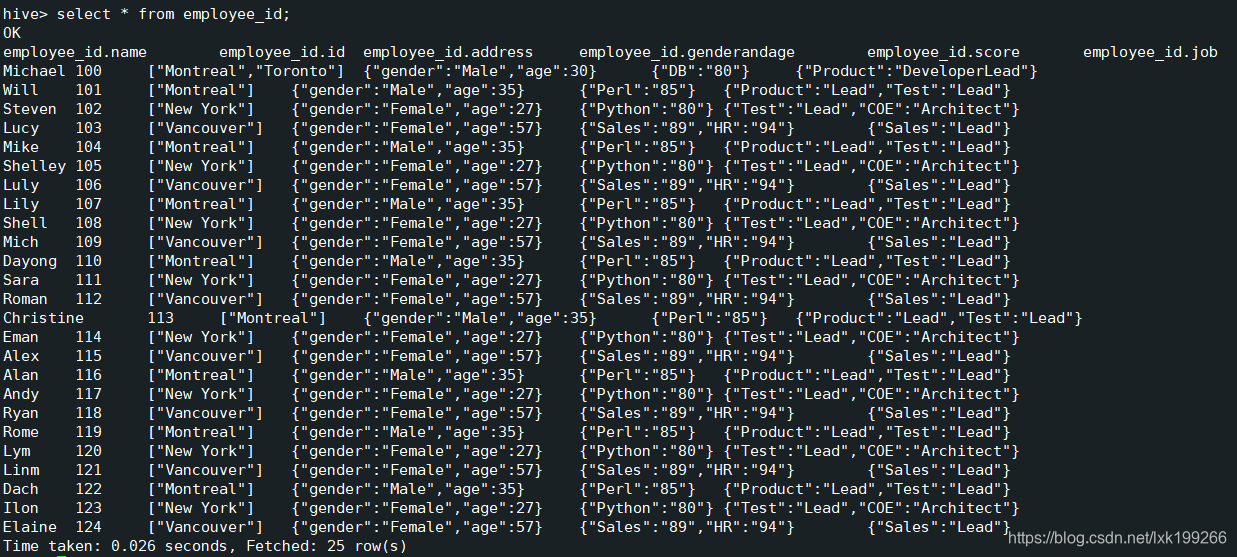
查看建成表的数据:
查询集合中的数据:select address[0] from employee_id;
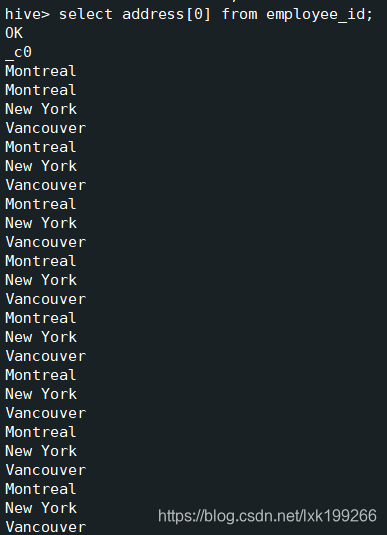
集合数据查询的下标也是从0开始的,但是这个下标不会越界,无数据时显示Null;
查询map中的数据:select score['DB'] from employee_id;
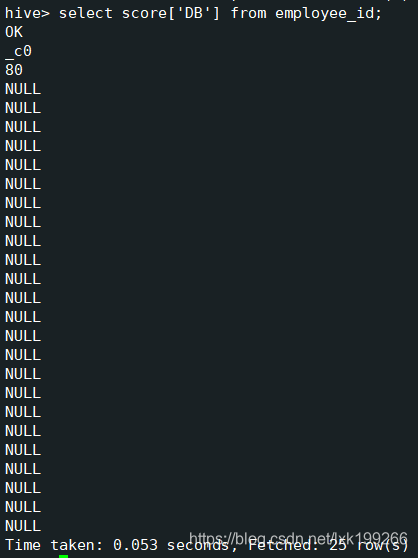
对应列只有包含指定键的会显示对应值,其余行会显示null;
查询struct中的数据:select genderandage.gender from employee_id;
高阶建表语句
create table tab_name as select * from tab_sample;
作用:将对tab_sample查询的结果形成一个新的表格
注意:这种建表方式不能创建partition,extermal,bucket table
create table tab_name as
with
t1 as (select * from t2),
t2 as (select * from tab_sample1),
t3 as (select * from tab_sample2)
select * from t1 union all select * from t3;
作用:将查询结果再次作为被查询表,供最后一条的查询语句查询,查询结果作为新表;
create table tab_name like tab_sample;
作用:创建与样表结构完全相同的表格,只是不含数据;
create temporary table ......
作用:创建临时表
临时表只对当前session有效,session退出就会被自动删除;
临时表默认会保存在/tmp/user_name目录下
SerDe
SerDe:Serializer and Deserializer
Hive支持的SerDe
- LazySimpleSerDe:TextFile
- BinarySerializerDeserializer:SEQUENCEFILE
- ColumnerSerDe:ORC,RCFILE
- ParquetHiveSerDe:PARQUET
- AvroSerDe:AVRO
- OpenCSVSerDe:for CST/TSV
- JSONSerDe
- RegExSerDe
- HBaseSerDe
案例:
create table test(a string,b string,...)
row format
serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties(
"separatorChar"="\t",
"quoteChar"="",
"escapeChar"="\\"
) stored as textfile;
create table test(
id string,
name string,
sex string,
age string
) row format serde 'org.apache.hadoop.hive.hbase.HBaseSerDe'
stored by
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties(
"hbase.columns.mapping"=':key,info:name,info:sex,info:age'
) tblproperties('hbase.table.name'='test_serde');


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









